BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
https://arxiv.org/pdf/2201.12086
1. Abstract
Vision-Language Pre-training (VLP)
- Improve performance for many vision-language tasks
Limitation of VLP
-
(1) Only excel in either ..
-
a) Understanding-based tasks
-
b) Generation-based tasks
-
-
(2) Improvement has been largely achieved by scaling up the dataset with noisy image-text pairs
\(\rightarrow\) Suboptimal source of supervision
Proposal: BLIP
- (New VLP framework) Transfers flexibly to both a) vision-language understanding & b) generation tasks
- How? Effectively utilizes the noisy web data by bootstrapping the captions!
- Captioner & Filter
- [Captioner] Generates synthetic captions
- [Filter] Removes the noisy ones
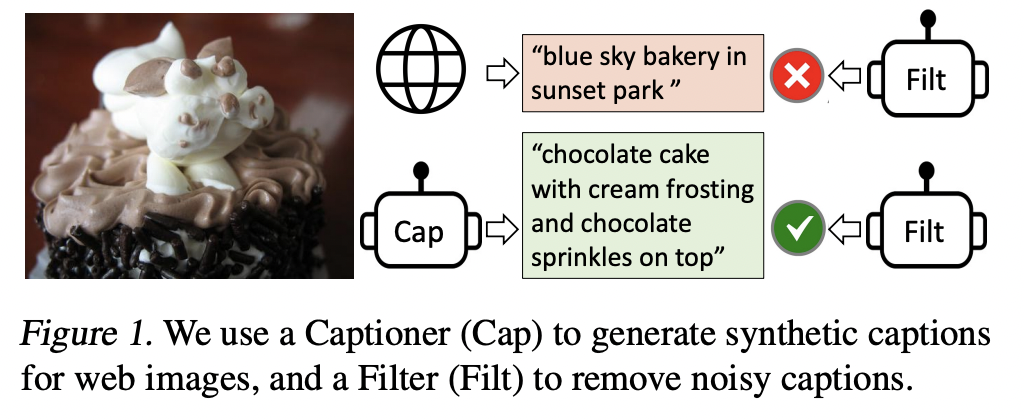
1. Introduction
BLIP: Bootstrapping Language Image Pre-training for unified vision-language understanding and generation.
Enables a wider range of downstream tasks!
Two contributions from the model and data perspective!
(1. Model) Multimodal mixture of Encoder-Decoder (MED)
- For effective multi-task pre-training and flexible transfer learning
- Can operate either as …
- a) Unimodal encoder
- b) Image-grounded text encoder
- c) Image-grounded text decoder
- Jointly pre-trained with three vision-language objectives
- (1) Image-text contrastive learning
- (2) Image-text matching
- (3) Image-conditioned language modeling
(2. Data) Captioning and Filtering (CapFilt)
- New dataset boostrapping method for learning from noisy image-text pairs
- Fnetune a pre-trained MED into two modules:
- (1) Captioner: To produce synthetic captions given web images
- (2) Filter: To remove noisy captions from both the original web texts and the synthetic texts.
3. Method
Unified VLP framework to learn from noisy image-text pairs
- Model architecture (MED )
- Pre-training objectives
- CapFilt for dataset bootstrapping.
(1) Model Architecture
Image Encoder: ViT
- Additional [CLS] token to represent the global image feature
Multimodal mixture of encoder-decoder (MED)
- To pre-train a unified model with both (1) understanding & (2) generation capabilities
- Multi-task model which can operate in one of the three functionalities:
- (1) Unimodal encoder
- (2) Image-grounded text encoder
- (3) Image-grounded text decoder
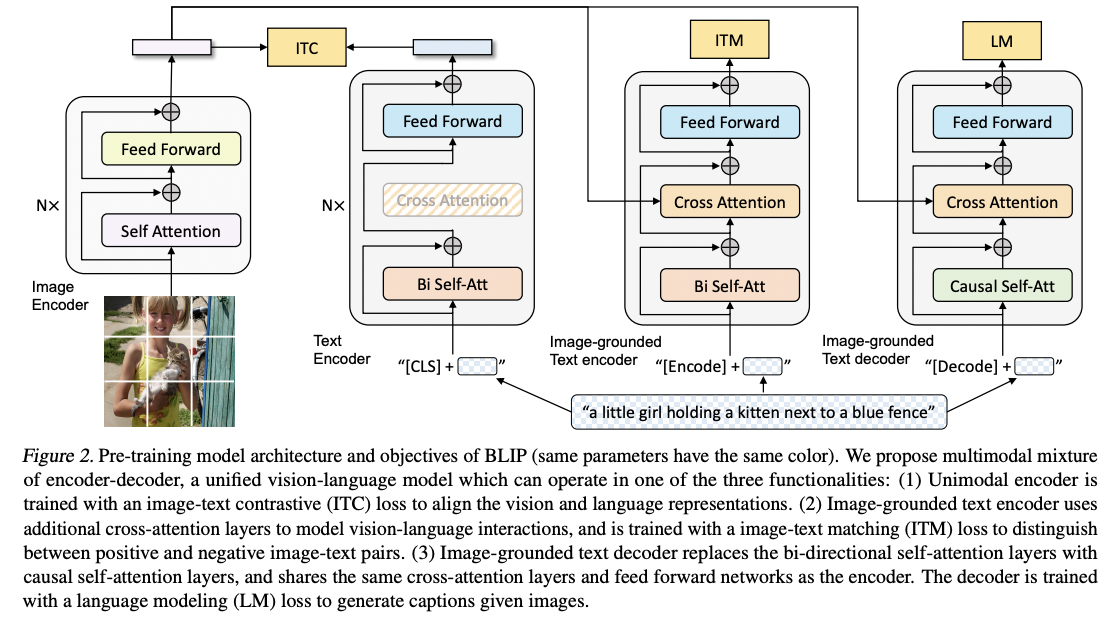
a) Unimodal encoder
- Separately encodes image and text
- Text encoder: BERT ( with [CLS] token )
b) Image-grounded text encoder
- Injects visual information by inserting one additional cross-attention (CA) layer between the self-attention (SA) layer and the FFN for each transformer block of the text encoder.
- Input & Output
- Input: A task-specific [Encode] token is appended to the text
- Output: Embedding of [Encode] is used as the multimodal representation of the image-text pair
c) Image-grounded text decoder
- Replaces the bidirectional self-attention layers in the image-grounded text encoder with causal self-attention layers
- Input: A [Decode] token is appended to the text
(2) Pretraining Objectives
- (1) Image-Text Contrastive Loss (ITC): CL loss
- (2) Image-Text Matching Loss (ITM): Binary CLS loss
- (3) Language Modeling Loss (LM): Cross entropy
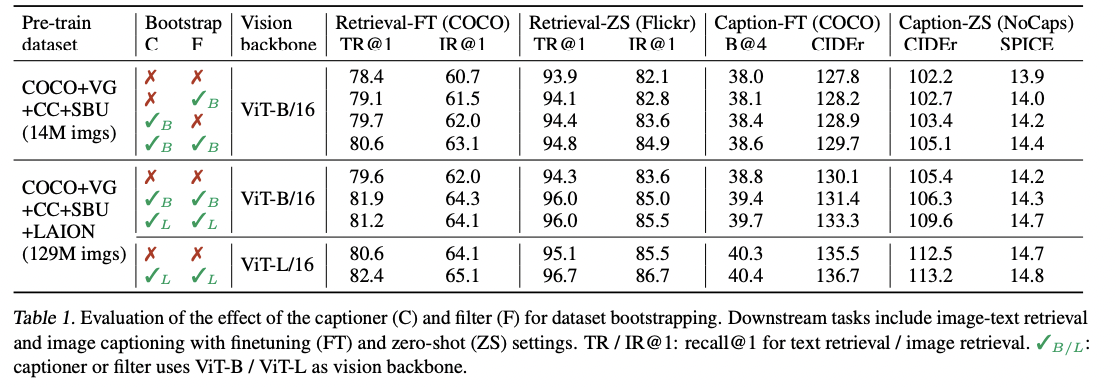
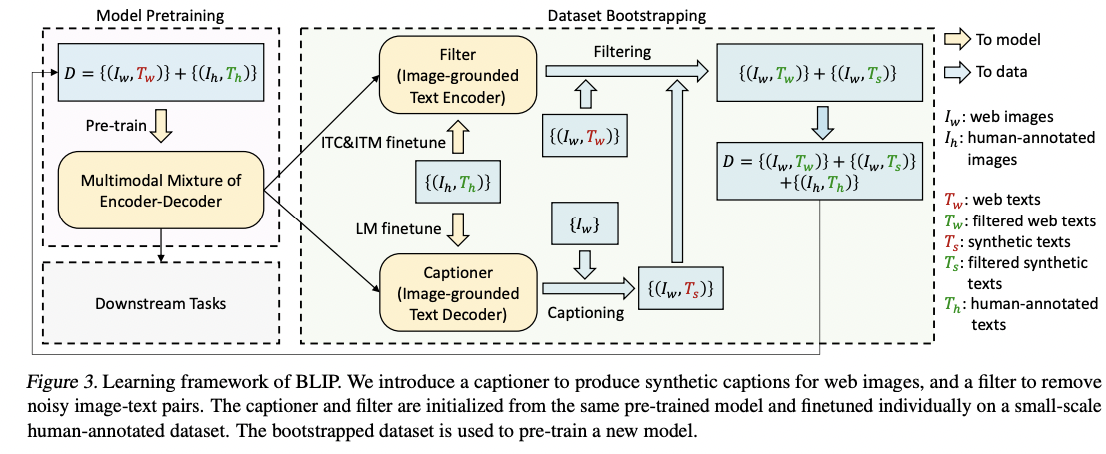
(3) CapFilt
Limited number of high-quality human-annotated image-text pairs \(\left\{\left(I_h, T_h\right)\right\}\)
- e.g., COCO (Lin et al., 2014)
Recent work utilizes a much larger number of image and alt-text pairs \(\left\{\left(I_w, T_w\right)\right\}\)
- Automatically collected from the web
- Limitation: Noisy signal
Captioning and Filtering (CapFilt)
New method to improve the quality of the text corpus!
Two modules
- (1) Captioner: To generate captions given web images
- (2) Filter: To remove noisy image-text pairs
\(\rightarrow\) Both are initialized from the same pre-trained MED model
\(\rightarrow\) Finetuned individually on the COCO dataset
Details
- (1) Captioner = Image-grounded text decoder
- Finetuned with the LM
- Process:
- Input: Web images \(I_w\).
- Output: Synthetic captions \(T\) (with one caption per image)
- (2) Filter= Image-grounded text encoder
- Finetuned with the ITC & ITM
- Learn whether a text matches an image.
- Removes noisy texts in both the original web texts \(T_w\) & the synthetic texts \(T_s\),
- Noisy if the ITM head predicts it as unmatched to the image.
\(\rightarrow\) Combine the (a) filtered image-text pairs & (b) human-annotated pairs!
# 4. Experiments