
CLIPS: An Enhanced CLIP Framework for Learning with Synthetic Captions
https://arxiv.org/pdf/2411.16828
Contents
- Abstract
- Introduction
- Related Works
- Methodology
- Preliminaries
- Inverse Effect with Synthetic Captions
- Encoder: Learning with Short Captions
- Decoder: Predicting Full Synthetic Captions
- Experiments
Abstract
Noisy, web-crawled image-text pairs
\(\rightarrow\) Limit vision-language pretraining like CLIP
\(\rightarrow\) Solution: Learning with synthetic captions
Proposal: CLIPS
Two simple designs for synthetic captions
- (1) Short synthetic captions \(\rightarrow\) Higher performance gain
- Feed only partial synthetic captions to the text encoder
- (2) Autoregressive captioner to mimic the recaptioning process
- Data = (image, web-crawed text)
- Target = full-length synthetic caption
Experiments
- Zero-shot performance in cross-modal retrieval tasks
- Dataset: MSCOCO, Flickr30K
- Enhance the visual capability of LLaVA
1. Introduction
Large-scale image-text datasets
- e.g., LAION, DataComp [17]
\(\rightarrow\) Key driver of the rapid development of VLMs
Limitation: Web-crawled datasets are generally noisy
- e.g., image-text pairs could be mismatched
\(\rightarrow\) Limit further performance improvements!
Solution: Improve the dataset “quality”
- e.g., Re-generating paired textual descriptions using MLLM (synthetic captions)
Synthetic captions
-
A straightforward approach
-
Replace the raw, web-crawled captions!
-
e.g., VeCLIP, Recap-DataComp-1B: (Partially) substitute the original captions with generated ones
\(\rightarrow\) Enhance the models’ capabilities (especially in cross-modal retrieval tasks)
-
Proposal: CLIPS
-
Synthetic captions = Typically highly descriptive
- Longer & more detailed than (original) web-crawled captions
-
Two simple yet effective designs
-
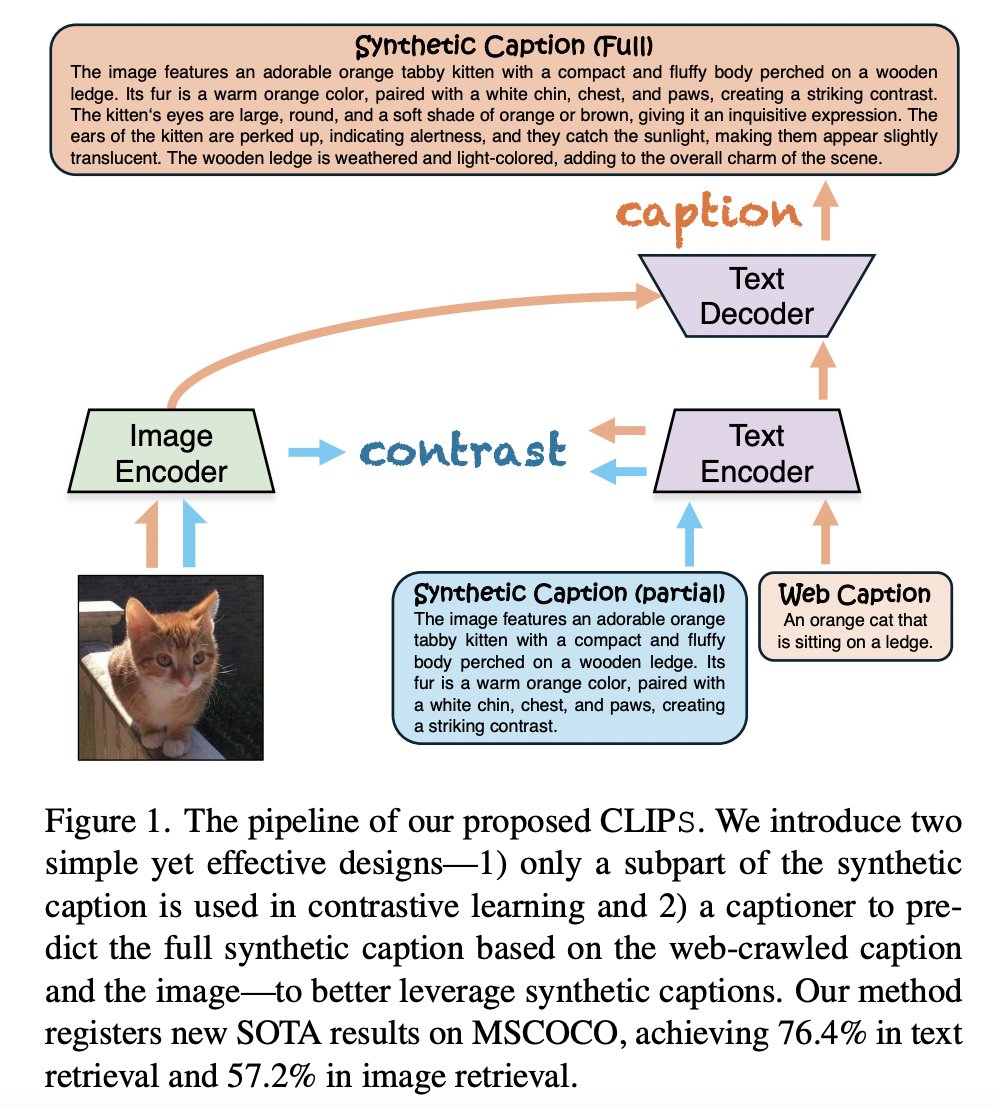
(1) Randomly sampling a portion of the synthetic caption to serve as input to the text encoder.
- Also lead to reduction in computation
-
(2) Predict full synthetic caption
-
Synthetic caption is only partially used in CL
\(\rightarrow\) Why not use their full use in an auxiliary task?
-
Follow CoCa by incorporating an autoregressive decoder to predict captions. Difference?
- a) CoCa: symmetric design
- Input text = Output text (i.e., the web-crawled caption)
- b) CLIPS: asymmetric design
- Input = web-crawled cpation
- Target = full-length synthetic caption
- a) CoCa: symmetric design
-
-
Experiments
-
Significantly enhances zero-shot performance in cross-modal retrieval
-
Results (ViT-L backbone)
- Substantially outperforms SigLip
- by 4.7 (from 70.8 to 75.5) on MSCOCO’s R@1 text retrieval
- by 3.3 (from 52.3 to 55.6) on MSCOCO’s R@1 image retrieval
- With increased computational resources and scaling, bet model achieves..
- 76.4% R@1 text retrieval performance on MSCOCO
- 96.6% R@1 text retrieval performance on Flickr30K
- Substantially outperforms SigLip
-
CLIPS framework contributes to building stronger MLLMs!
-
Replacing the visual encoder from OpenAI-CLIP with our CLIPS in LLaVA:
\(\rightarrow\) Leads to strong performance gains across a range of MLLM benchmarks!
-
2. Related Works
(1) VL Pretraining
Existing frameworks predominantly adopt either…
- (1) Single-stream architecture
- Jointly represents different modalities using a shared encoder
- (2) Two-stream architectures
- Employ two independent encoders to process visual and textual inputs separately.
- Proposed CLIPS = two-stream
Further enhancements to CLIP: Two main directions
-
(1) Extending CLIP’s capabilities into generative tasks
( e.g., Image captioning, visual question answering, and image grounding )
- CoCa and BLIP: Enables the unification of imagetext understanding and generation tasks by transitioning from an encoder-only architecture to an encoder-decoder architecture.
-
(2) Optimizing vision-language CL
- FILIP: Mitigates the fine-grained alignment issue in CLIP by modifying the contrastive loss.
- SigLip: Replaces contrastive loss with sigmoid loss
- Llip: Models captions diversity
- By associating multiple captions with a single image representation
- CLOC: Region-text contrastive loss
- Enhance ability to focus on specific image regions
\(\rightarrow\) Proposed CLIPS = Aims to improve CLIP but focuses on enhancing the leverage of richly described synthetic captions in training
(2) Learning from Synthetic Captions
Web-crawled image-text datasets are often noisy!!
Solution: Synthetic caption!
- (1) ALip: Uses the OFA model to generate synthetic captions & Introduces a bipath model to integrate supervision from two types of text.
- (2) LaCLIP: Rewrites captions using LLMs and randomly selects one of these
- (3) Nguyen et al: Use BLIP-2 to rewrite captions for image-text pairs with low matching degrees in the original dataset.
- (4) VeCLIP: Uses LLaVA to generate synthetic captions with rich visual details, then uses an LLM to fuse the raw and synthetic captions
- (5) Liu et al.: Use multiple MLLMs to rewrite captions & Apply text shearing to improve caption diversity
- (6) ShareGPT4V: Feeds carefully designed prompts and images to GPT-4V to create a high-quality dataset
- (7) Li et al.: Rewrites captions using a more advanced LLaMA-3-based LLaVA in the much larger-scale DataComp-1B dataset
- (8) SynthCLIP: Trains entirely on synthetic datasets by generating image-text pairs using text-to-image models and LLMs.
- (9) DreamLip: Builds a short caption set for each image & computes multi-positive contrastive loss and sub-caption specific grouping loss
3. Methodology
(1) Preliminaries
a) CLIP
Image-text CL
-
\(L_I=-\frac{1}{N} \sum_{i=1}^N \log \frac{\exp \left(\operatorname{sim}\left(f\left(x_i\right), g\left(y_i\right)\right) / \tau\right)}{\sum_{j=1}^N \exp \left(\operatorname{sim}\left(f\left(x_i\right), g\left(y_j\right)\right) / \tau\right)}\).
-
\(L_{\text {contrast }}=\frac{1}{2}\left(L_{\text {imape }}+L_{\text {text }}\right)\).
b) CoCa
Generative loss
- By autoregressively predicting the next token
- Conditioned on image features and previously generated tokens
- \(L_{g \mathrm{en}}=-\sum_{t=1}^T \log P\left(y_t \mid y_{<t}, E(x)\right)\).
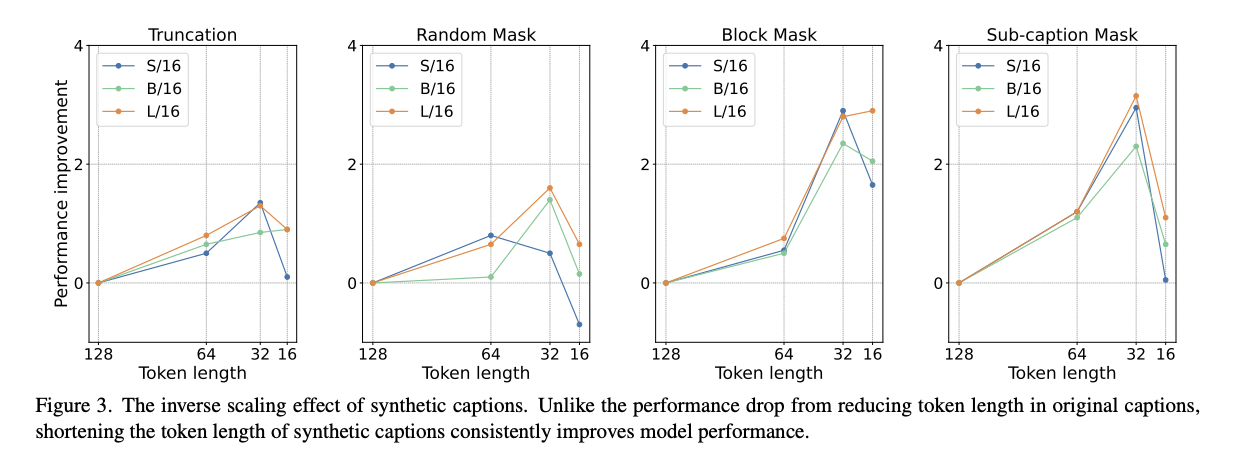
(2) Inverse Effect with Synthetic Captions

How CLIP models behave when learning with shorter synthetic captions?
- Four strategies (Figure 2)
Notation
- Synthetic caption sequence of length \(K\)
- Target token length \(L\),
a) Trunctation
- Directly selects the first \(L\) tokens
b) Random mask
- Obtains \(L\) tokens through random sampling
c) Block mask
- Randomly selects a starting point in the original sequence and take the subsequent \(L\) tokens.
d) Sub-caption mask
-
Step 1) Split the synthetic caption at periods \(\rightarrow\) Segments \(\left\{S_1, S_2, \ldots, S_n\right\}\),
- \(n\) = Number of sub-captions
-
Step 2) Randomly select a sub-caption
-
Step 3) Check its length
- If the length meets and exceeds the predefined limit: Truncate
- Otherwise: Randomly select another sub-caption from the remaining ones, concatenate it with the previous segment, and then check the length again
\(\operatorname{Subcaption}(S, L)= \begin{cases}\operatorname{Truncate}\left(S_i\right), & \text { if } \mid S_i \mid >L \\ \operatorname{Concat}\left(\left\{S_i, S_j, \ldots\right\}\right), & \text { if } \mid S_i \mid <L\end{cases}\).
(3) Encoder: Learning with Short Captions
\(L_{\text {contrast }}=-\frac{1}{2 N} \sum_{i=1}^N\left(L_{\text {erig }}^i+L_{\text {syn-short }}^i\right)\).
- \(L_{\text {orig }}^i =\log \frac{\exp \left(S_{i, \text { orig }}^i\right)}{\sum_{k=1}^N \exp \left(S_{i, \text { orig }}^k\right)}\).
- \(L_{\text {sya-short }}^i =\log \frac{\exp \left(S_{i, \text { sya-short }}^i\right)}{\sum_{k=1}^N \exp \left(S_{i, \text { syp-short }}^k\right)}\).
(4) Decoder: Predicting Full Synthetic Captions
a) Naive version
\(L_{\text {pen }}=-\sum_{t=1}^T \log P\left(y_t \mid \mathbf{I}_{\text {mags }}, \mathbf{C}_{\text {web }}, \mathbf{L}_{\text {leamable },<t}\right)\).
b) w/ Self-attention
Experiments show that (a) > (b)
- (a) Simply concatenating information from different modalities
- (b) Employing modality fusion with cross-attention mechanisms
\(\rightarrow\) Therefore, utilizes a self-attention mechanism ( + combination mask )
- Combination mask \(M\): To ensure that tokens within the condition can attend to each other,
\(L_{g \mathrm{gec}}=-\sum_{t=1}^T \log P_\theta\left(y_t \mid \mathbf{I}_{\text {lump }} \oplus \mathbf{C}_{\text {wch }} \oplus \mathbf{L}_{\text {learable },<t}, M\right)\).
\(M[i, j]= \begin{cases}1 & \text { if } i, j \leq L_{\text {cond }} \\ 1 & \text { if } i>L_{\text {cond }} \text { and } j \leq L_{\text {cond }} \\ 1 & \text { if } i, j>L_{\text {cond }} \text { and } i \geq j \\ 0 & \text { otherwise }\end{cases}\).
Final Loss: \(L_{\text {total }}=\alpha \cdot L_{\text {coemast }}+\beta \cdot L_{g e n}\).
4. Experiments
(1) Pretraining Details
(Pretraining dataset) Recap-DataCompIB dataset
(PT Epochs) 2,000 ImageNet-equivalent epochs
- ~ 2.6B samples seen
- Images at a low resolution (e.g., resizing to \(112 \times 112\) by default)
(FT Epochs) 100 ImageNet-equivalent epochs
- Resolution of \(224 \times 224\).
(Text branch)
-
Iinput token length = 80
-
Output token length = 128
( = Matching the number of learnable tokens in the decoder )
(Batch size)
- PT: 32768
- FT: 16384
To further enhance training …. (for comparison with SOTA)
- (PT Epochs) 10,000 ImageNet-equivalent epochs
- ~ 13B samples seen
- (FT Epochs) 400 ImageNet-equivalent epochs
- Resolution
- PT: 84 (for accelerating training)
- FT: 224
(2) Evaluation
a) Zero-shot cross-modal retrieval
-
Varying model size
-
Varying datasets: MSCOCO & Flickr30K
- Baseline: CLIPA and CoCa
- Train with a mixture of web-crawled captions (80%) and synthetic captions (20%).
Result
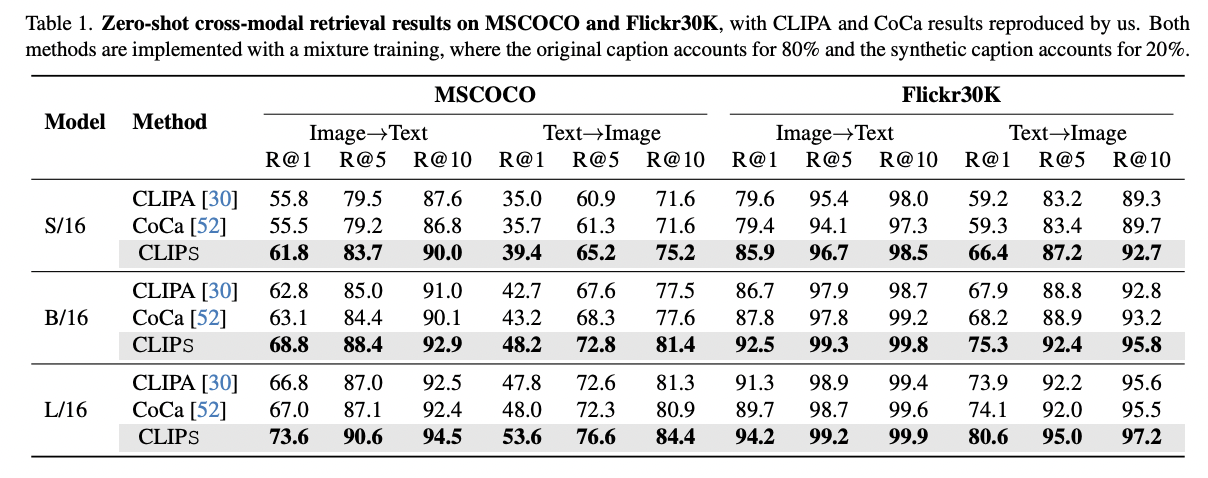
- Consistently achieves superior performance across all benchmarks and model sizes
- Enable our smaller models to match or even surpass the performance of larger models
b) Comparision with SOTA methods
Metric:
- ImageNet-1K: Top-1 accuracy
- MSCOCO, Flickr30K: Zero-shot recall rates (for image and text retrieval tasks)
Result
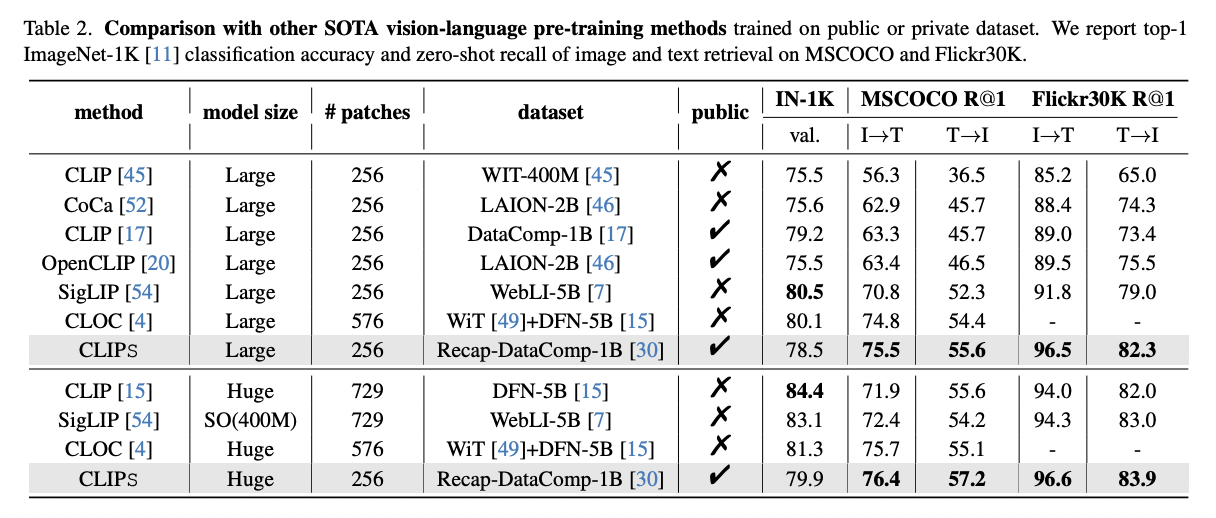
- Despite the strong cross-modal retrieval performance,
- CLIPS is less competitive on ImageNet zero-shot classification accuracy
c) CLIPS in LLaVA
Integrate the CLIPS visual encoder into LLaVA-1.5 for evaluation
Details
- (1) Visual encoder
- Original) OpenAI-CLIP-L/14 visual encoder
- Replacement) CLIPS-L/14
- (2) Text Encoder: LLaMA-3
- Finetune CLIPS-L/14 at a resolution of \(336 \times 336\) to match the configuration of OpenAI-CLIP-L/14.
We then evaluate LLaVA’s performance on multiple MLLM benchmarks
- MME [16]. MMMU [53], GQA [19]. ChartQA [39], POPE [32], NoCaps [2], and TextVQA [47].
