
DeepSeek
참고: https://www.youtube.com/watch?v=l7fn8gEUjG4
Contents
- Introduction
- What is DeepSeek?
- DeepSeek-V3
- DeepSeek-R1
- DeepSeek-V3
- MLA (Multi-head Latent Attention)
- DeepSeekMoE
- Multi-Token Prediction Objective
- DualPipe
- DeepSeek-R1 & R1-zero 개요
- Pre-Training & Post-Training of LLM
- RL
- LM vs. RL
- RL 수식 개요
- RL 수식 vs. LM 수식
- DeepSeek R1-Zero
- PPO
- PPO vs. GRPO
- Rule-based Reward Modeling
- Result
- DeepSeek R1
- Summary
1. Introduction
(1) What is DeepSeek?
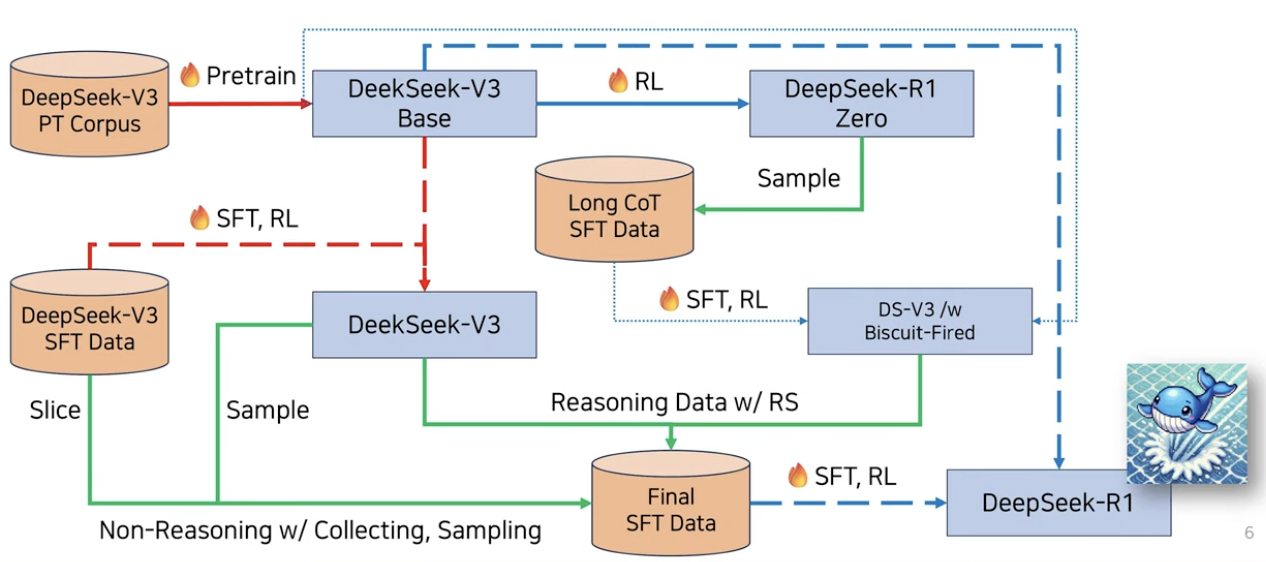
DeepSeek-R1
- GPT4-o1에 맞먹는 성능을 내는 모델
- DeepSeek-V3-Base에 추가적인 학습을 통해서 생성됨
DeepSeek-V3 & DeepSeek-V3-Base
- 아주 적은 computing resource로 학습한 LLM
- 방법: Pretrain + SFT + RL
- DeepSeek-R1을 만들기 위해 둘 다 사용됨
(2) DeepSeek-V3
핵심: 계산 효율화
-
DeepSeek-V2의 효율적인 구조를 차용함
-
MLA (Multi-head Latent Attention)
-
DeekSeekMoE (w/o Auxiliary loss)
-
-
다단계 학습 & 추가적인 Task
-
Pretrain -> Length-Extension -> Post-Train
-
추가적인 Task
- Multi-Token Prediction
- Fill in the Middle
-
-
Computing Resource 최적화
(3) DeepSeek-R1
핵심: Reasoning model을 RL로만 학습하겠다!
- DeepSeek-V3-Base 기반의 Reasoning (추론) 모델
- Test-time scaling
- Reasoning capability 향상을 위해 “RL”을 사용
- PPO 대신 GRPO 사용
2. DeepSeek-V3
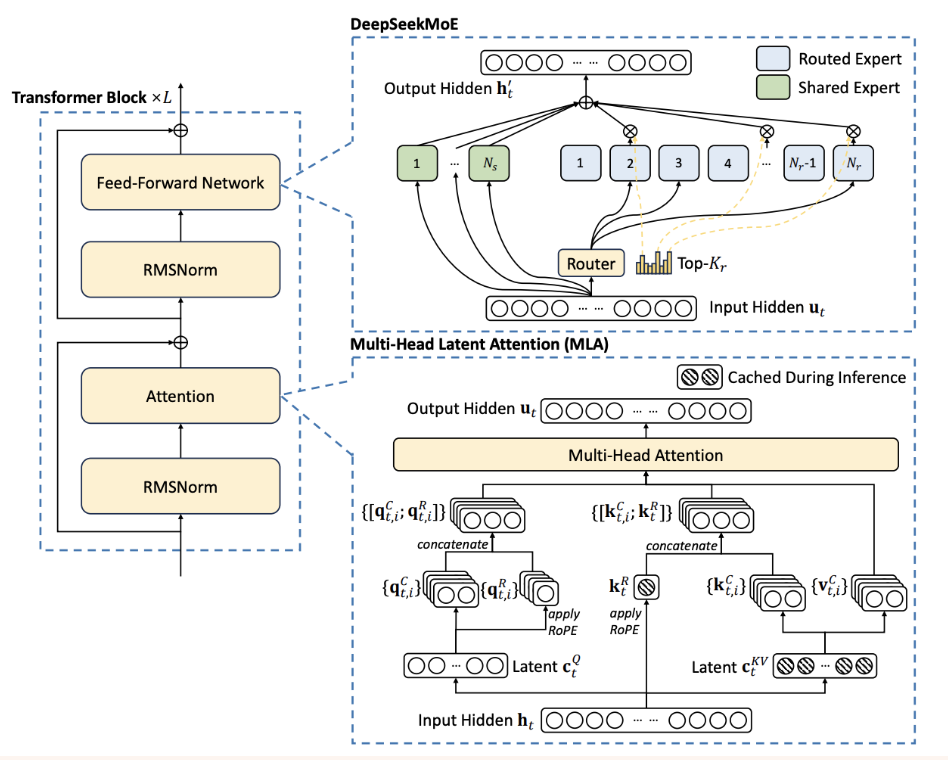
핵심: 효율적 학습
- 사용한 resource: H800 x 2048
- 파라미터: 671B (37B-Active)
DeepSeek-V2의 효율적인 구조를 차용함
( DeepSeek-V3에서 처음 사용한 것이 아님! )
-
MLA (Multi-head Latent Attention)
-
DeekSeekMoE (w/o Auxiliary loss)
(1) MLA (Multi-head Latent Attention)
a) Motivation
(1) LLM inference (serving) 시 문제점:
- 중복 연산 발생!
- 앞서서 계산했던 token에 대한 재계산 필요!
(2) 솔루션: KV Cache
- Further extension: KV Cache compression, MQA, GQA, MLA
b) 선행 연구들 (+ MLA) 개요
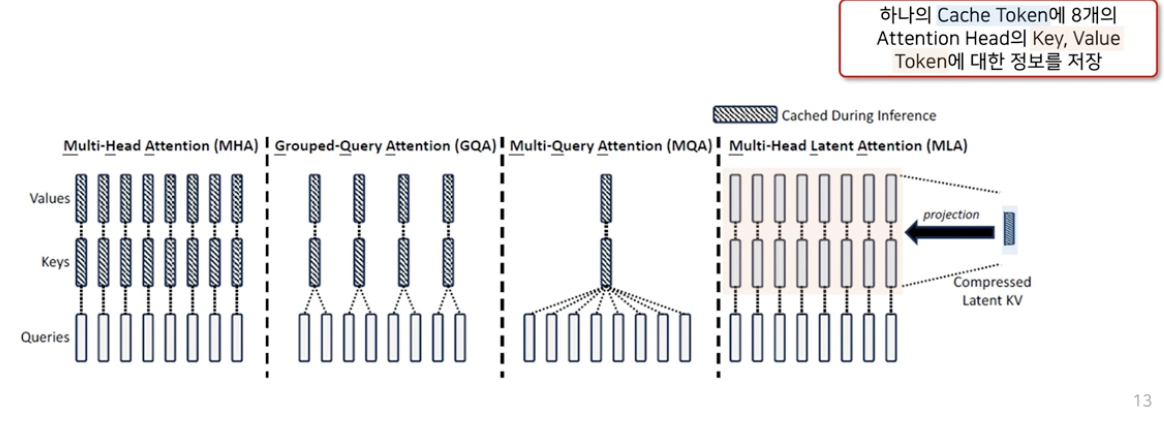
기본 Idea:
- 하나의 cache token ( = compressed latent KV )에,
- 모든 attention head의 K,V token 정보를 저장해두고
- 사용할 때 projection으로 생성하자!
c) MLA 수식 이해 - 기존의 MHA
Step 1) Q,K,V 생성
\(\begin{aligned} & {\left[\mathbf{q}_{t, 1} ; \mathbf{q}_{t, 2} ; \ldots ; \mathbf{q}_{t, n_h}\right]=\mathbf{q}_t} \\ & {\left[\mathbf{k}_{t, 1} ; \mathbf{k}_{t, 2} ; \ldots ; \mathbf{k}_{t, n_h}\right]=\mathbf{k}_t} \\ & {\left[\mathbf{v}_{t, 1} ; \mathbf{v}_{t, 2} ; \ldots ; \mathbf{v}_{t, n_h}\right]=\mathbf{v}_t} \end{aligned}\).
- \(t\)번째 시점의 token
- \(n_h\): head의 개수
Step 2) Attention
\(\mathbf{o}_{t, i}=\sum_{j=1}^t \operatorname{Softmax}\left(\frac{\mathbf{q}_{j, i}^T \mathbf{k}_{j, i}}{\sqrt{d_b}}\right) \mathbf{v}_{j, i}\).
- \(t\)번째 시점 + \(i\)번째 head에 대한 output token
Step 3) 모든 head에 대해 attention 후 concat & linear projection
\(\mathbf{u}_t=W^O\left[\mathbf{o}_{t, 1} ; \mathbf{o}_{t, 2} ; \ldots ; \mathbf{o}_{t, n_h}\right]\).
- 위의 \(\mathbf{o}_{t, i}\)를 \(n_h\) (헤드 개수)만큼 생성한 뒤
- linear projection을 시킨다.
d) MLA 수식 이해 - MLA
(Positional Encoding를 RoPE를 통해 벡터 concat!)
Step 1) compressed latent vector를 생성
\(c_t^Q=W^{D Q} \mathbf{h}_t\)….. Query 용
\(c_t^{KV}=W^{D KV} \mathbf{h}_t\)…… Key & Value 용
Step 2) 위 vector를 사용하여 (Q+) K,V 생성
(Query)
\(\begin{aligned} {\left[\mathbf{q}_{t, 1}^C ; \mathbf{q}_{t, 2}^C ; \ldots ; \mathbf{q}_{t, n_h}^C\right]=\mathbf{q}_t^C } & =W^{U Q} \mathbf{c}_t^Q, \\ {\left[\mathbf{q}_{t, 1}^R ; \mathbf{q}_{t, 2}^R ; \ldots ; \mathbf{q}_{t, n_h}^R\right]=\mathbf{q}_t^R } & =\operatorname{RoPE}\left(W^{Q R} \mathbf{c}_t^Q\right), \\ \mathbf{q}_{t, i} & =\left[\mathbf{q}_{t, i}^C ; \mathbf{q}_{t, i}^R\right], \end{aligned}\).
(Key)
\(\begin{aligned} {\left[\mathbf{k}_{t, 1}^C, \mathbf{k}_{t, 2}^C ; \ldots ; \mathbf{k}_{t, n_h}^C\right]=\mathbf{k}_t^C } & =W^{U K} \mathbf{c}_t^{K V}, \\ \mathbf{k}_t^R & =\operatorname{RoPE}\left(W^{K R} \mathbf{h}_t\right) \\ \mathbf{k}_{t, i} & =\left[\mathbf{k}_{t, i}^C \mathbf{k}_t^R\right], \end{aligned}\).
(Value)
\(\left[\mathbf{v}_{t, 1}^C ; \mathbf{v}_{t, 2}^C ; \ldots ; \mathbf{v}_{t, n_h}^C\right]=\mathbf{v}_t^C=W^{U V} \mathbf{c}_t^{K V}\).
Step 3) Attention (거의 동일)
\(\mathbf{o}_{t, i}=\sum_{j=1}^t \operatorname{Softmax}_j\left(\frac{\mathbf{q}_{t, i}^T \mathbf{k}_{j, i}}{\sqrt{d_h+d_h^R}}\right) \mathbf{v}_{j, i}^C\).
Step 4) 모든 head에 대해 attention 후 concat & linear projection (동일)
\(\mathbf{u}_t=W^O\left[\mathbf{o}_{t, 1} ; \mathbf{o}_{t, 2} ; \ldots ; \mathbf{o}_{t, n_h}\right]\).
e) 요약
- (MHA) 하나의 token 당, \(n_h\)개의 \(k\) & \(v\)를 저장
- (MLA) 하나의 token 당, 1개의 \(c\) 저장
(2) DeepSeepMoE
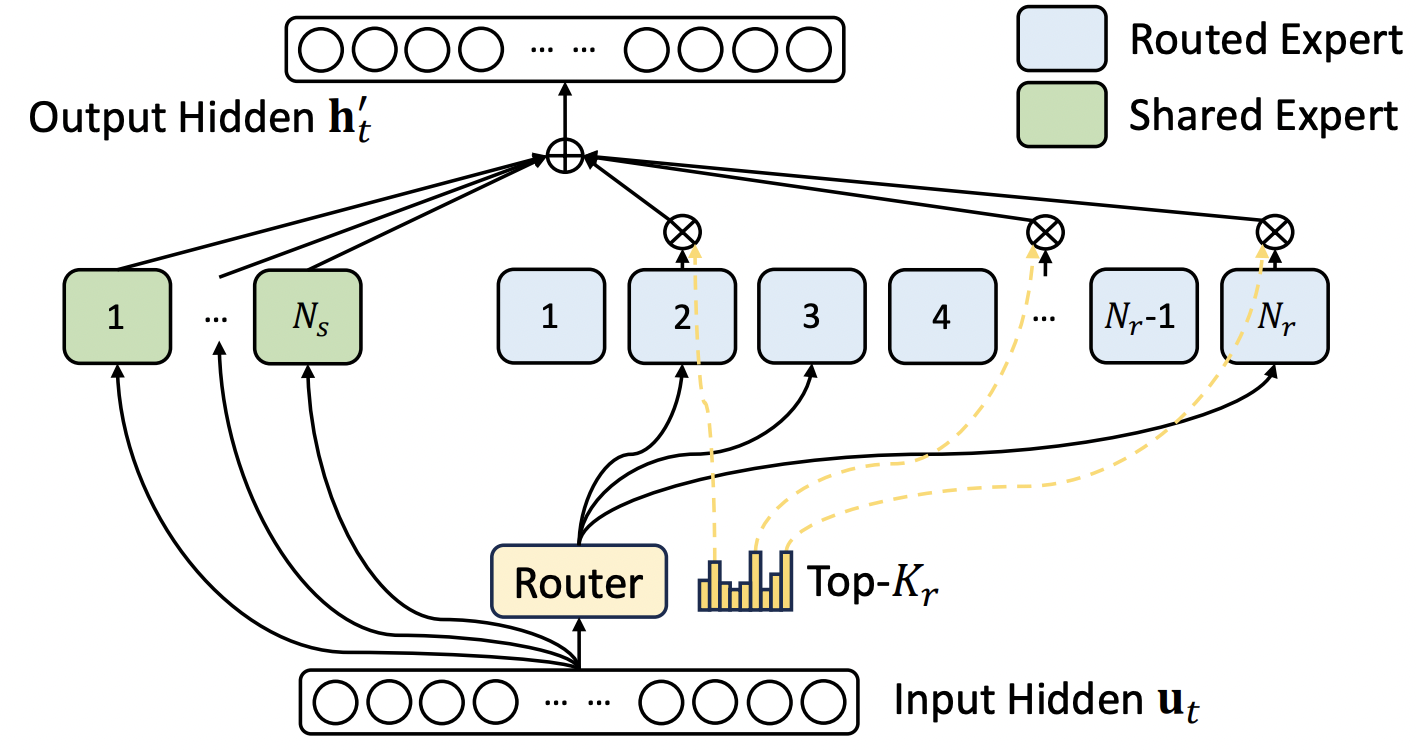
핵심: (1) 고정적 + (2) 유동적
- (1) 고정적: \(N_s\) 개의 FNN
- (2) 유동적: \(N_r\) 개의 FNN (조건적 활성화)
\(\mathbf{h}_t^{\prime}=\mathbf{u}_t+\sum_{i=1}^{N_s} \mathrm{FFN}_i^{(s)}\left(\mathbf{u}_t\right)+\sum_{i=1}^{N_t} g_{i, t} \mathrm{FFN}_i^{(r)}\left(\mathbf{u}_t\right)\).
- Router 역할을 하는 \(g\)
(3) Multi-Token Prediction Objective
(V2를 기반으로) V3를 pretrain시 수행한 추가적인 objective
- \(N\)번째 뒤의 next token도 예측하도록!
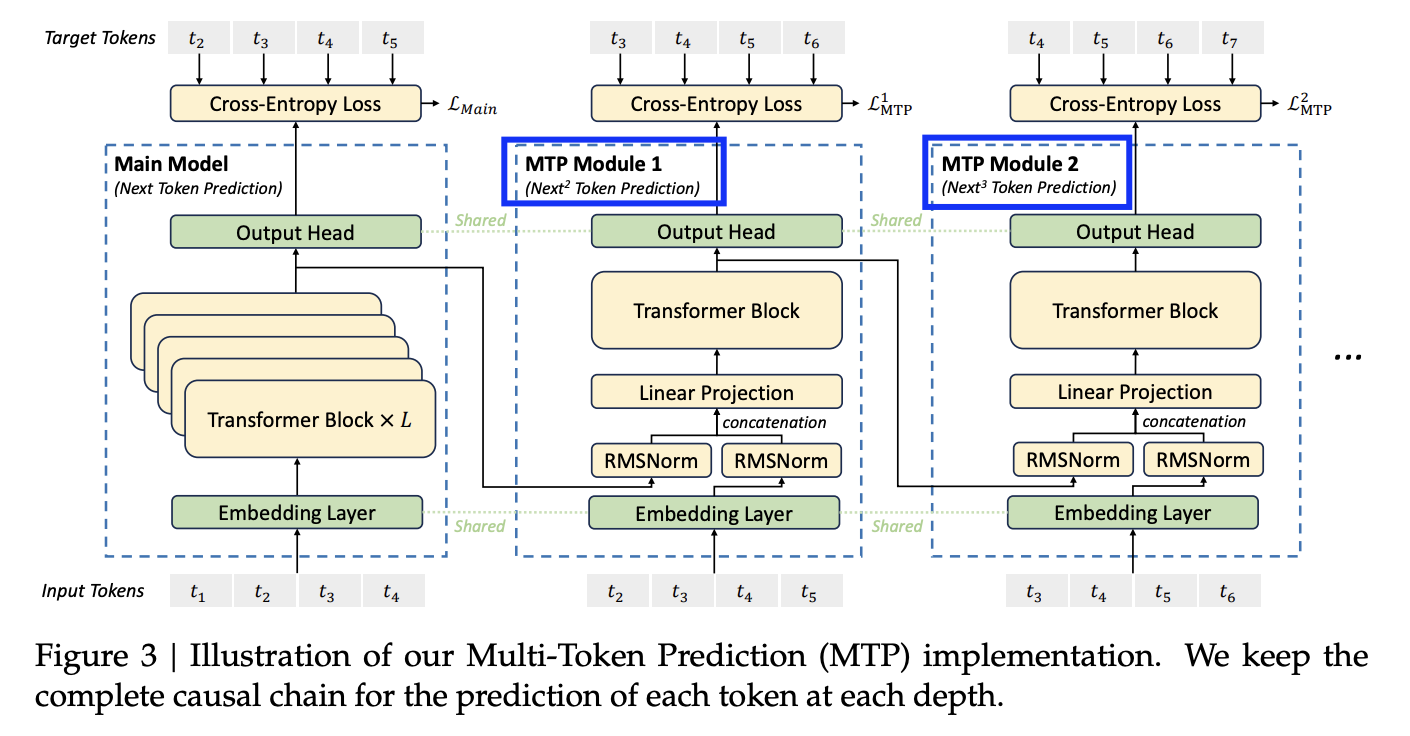
- 1번째 그림: (기존의) NTP
- 2,3번째 그림: (제안한) NNTP & NNNTP
- 2번째는 1번째 block에서 나온 벡터를 받음
- 3번째는 2번째 block에서 나온 벡터를 받음
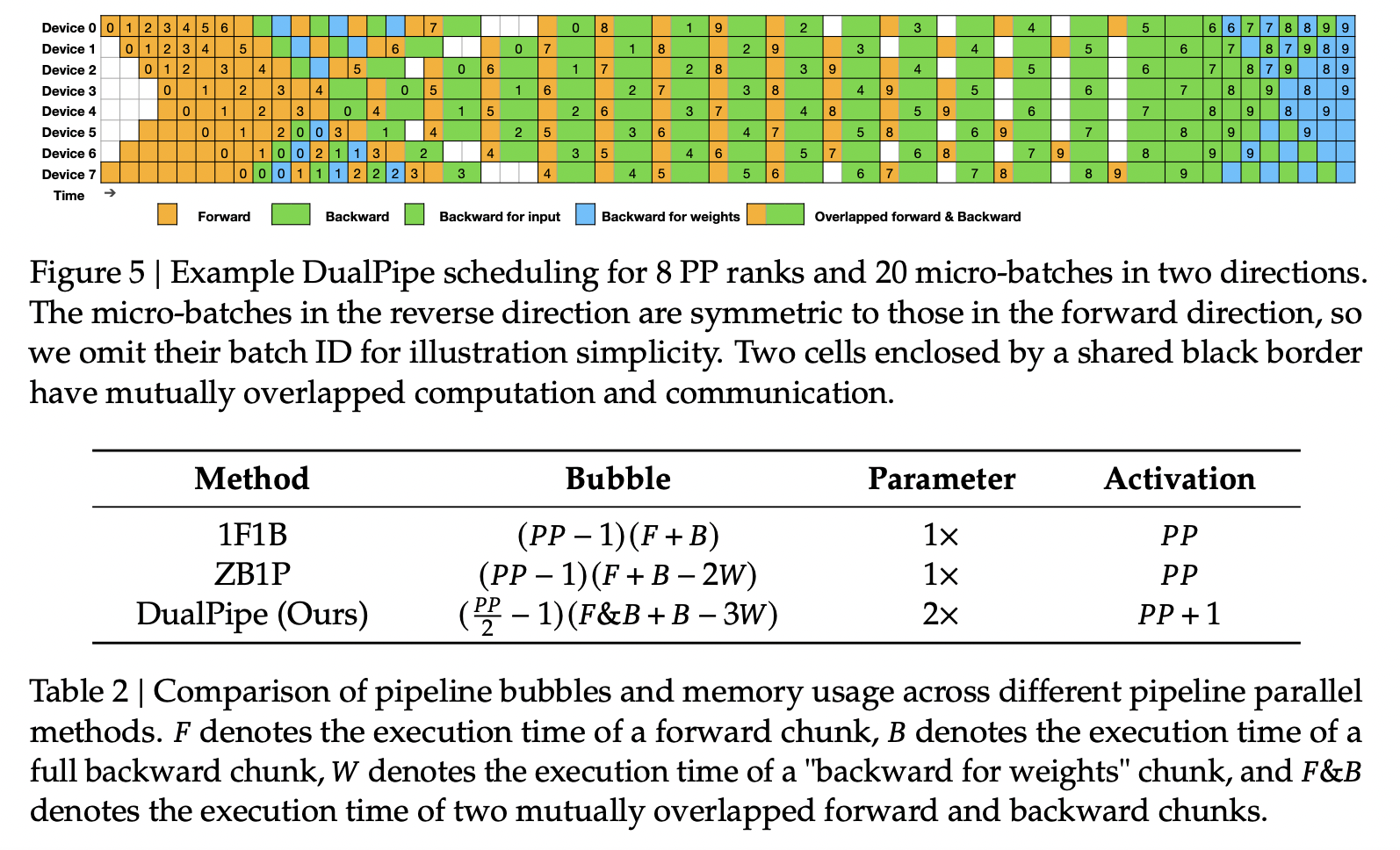
(4) DualPipe
(V2를 기반으로) V3를 pretrain를 효율적으로 학습하기 위해!
- 하나의 GPU에 2개의 layer를 할당
- forward & backward를 동시에 진행!
3. DeepSeek-R1 & R1-zero 개요
구성
- (1) DeepSeek-R1-Zero: (SFT 없이) 오직 RL만으로 Reasoning model을 만듬
- (2) DeepSeek-R1: (Closed-source) Reasoning model. GPT-4o와 비등
학술적 Contribution은 R1-Zero, 성능 좋은 것은 R1!
Reasoning Model이란?
Background
- 기존 연구 방향: Train-time scaling
- 더 많은 데이터를, 더 큰 자원으로!
- 새로운 연구 방향: Inference-time scaling
- Inference 시의 시간을 늘림으로써 성능 향상
- Reasoning model을 얻는 가장 간단한 방법은 CoT
- Answer 이전에 양질의 Thinking/Reasoning을 생성하도록!
4. Pre-Training & Post-Training of LLM
a) Pre-Training
- General knowledge 습득
- 쉽게 얻을 수 있는 데이터 (세상의 지식)
b) Post-Training
- Specific knowledge 습득
- Task-specific: 데이터에 “입력”과 “출력”이 구분됨
- e.g., summarization, sentiment analysis
c) Post-Training 시의 어려운 점
일부 task의 경우, 입력&출력 supervision을 주는 것이 어려울 수 있음!
- e.g., Input에 대해 하나의 정답만이 존재하는 것이 아닐 경우!
해결책:
- (1) SFT: 어떻게서든 (Q,A) pair를 만들어서 학습시키자!
- (2) RL: Q에 대해 A를 만들면, 이에 대한 상/벌을 주자!
\(\rightarrow\) Complementary approach!
5. RL
(1) LM vs. RL
Objective function의 차이
-
[LLM] \(\max _\theta \sum_{t=1}^T \log P\left(x_t \mid x_{<t} ; \theta\right)\).
-
[RL] \(J(\theta)=\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)]\).
- 차이점 1) 미분 불가능
- 차이점 2) 정답 (Target distn)이 없음
- 차이점 3) Reward를 통해서! (Loss가 아님)
(2) RL 수식 개요
Agent / Environment / State / Policy / Action / Reward
- (1) Agent: LLM (\(\theta\))
- (2) Environment: Q에 대한 A에 대해 얻을 수 있는 점수 환경
- (3) State: 입력 (prompt + question) = \(s_t\) (\(t\) 이전까지의 정보들)
- (4) Policy: 최선의 단어 선택 방법 = \(\pi_{\theta}(a \mid s)\)
- (5) Action: 단어 출력하기 = \(a_t\)
- (6) Reward: 단어 출력에 대한 보상 = \(r(s_t,a_t)\)
Trajectory
- \(\tau = (s_0,a_0,s_1,a_1, \cdots, s_T, a_T)\).
- LLM의 \(T+1\) 회 forward에 따른 답변
(3) RL 수식 vs. LM 수식
(1) Objective function
-
[RL] \(J\left(\pi_\theta\right)=\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)]\).
-
[LM] \(F(\theta)=\sum_{t=1}^T \log P\left(x_t \mid x_k ; \theta\right)\).
(2) Gradient ascent
-
[RL] \(\theta \leftarrow \theta+\alpha \nabla_\theta J\left(\pi_\theta\right)\).
-
[LM] \(\theta \leftarrow \theta+\alpha \nabla_\theta F(\theta)\).
(3) \(\theta\)에 대한 미분
- [RL] \(\nabla_\theta J\left(\pi_\theta\right)=\mathbb{E}_{r \sim \pi_\theta}\left[\sum_{t=0}^T R_t(\tau) \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right)\right]\).
- \(R_i(\tau)=\sum_{k=1}^T \gamma^{k-1} r\left(s_k, a_k\right)\).
- [LM] \(\nabla_\theta F(\theta)=\sum_{t=1}^T \nabla_\theta \log P\left(x_t \mid x_{<t} ; \theta\right)=\sum_{t=1}^T \frac{1}{P\left(x_t \mid x_{<t} ; \theta\right)} \nabla_\theta P\left(x_t \mid x_{<t} ; \theta\right)\).
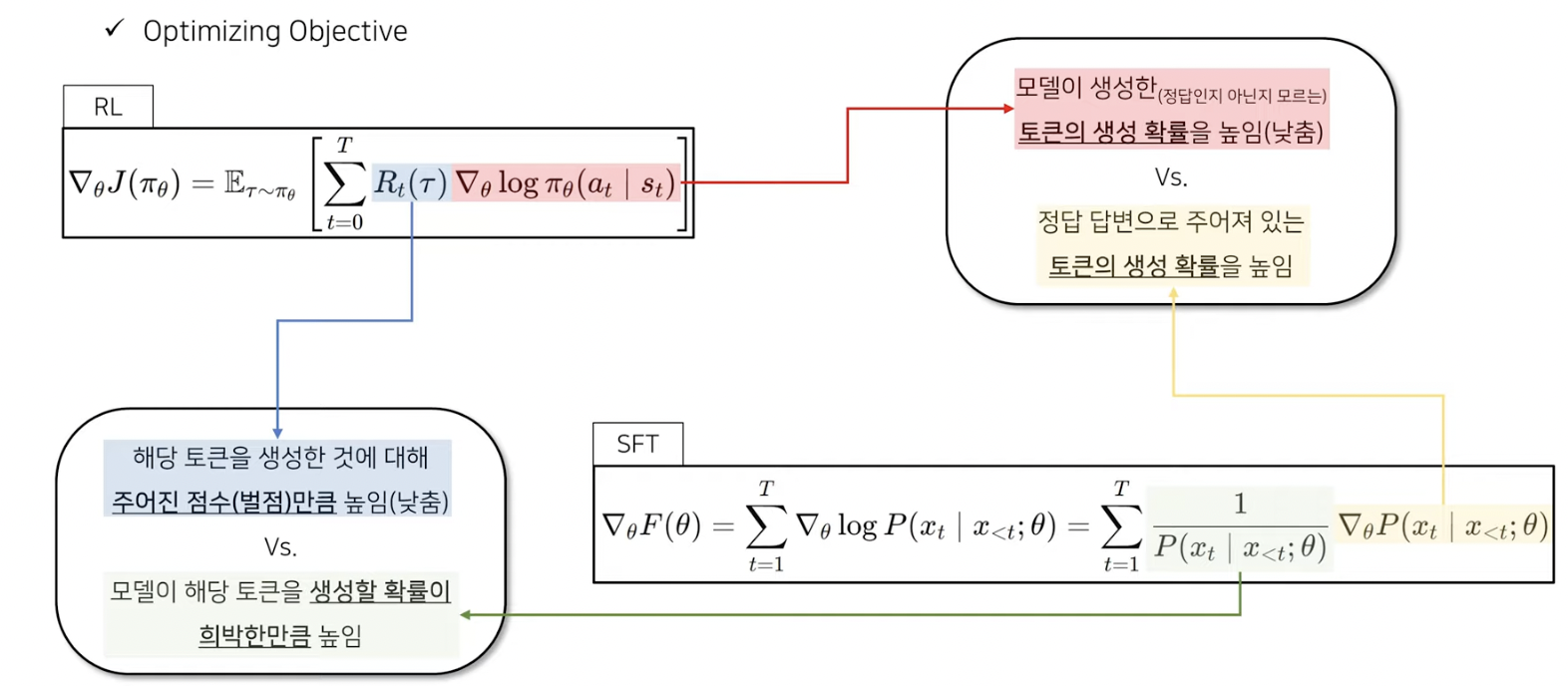
SFT vs. RL의 목적 (의미 해석)
6. DeepSeek R1-Zero
(1) PPO
목적 함수: \(\nabla_\theta J\left(\pi_\theta\right)=\mathbb{E}_{r \sim \pi_\theta}\left[\sum_{t=0}^T R_t(\tau) \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right)\right]\).
PPO는 위 목적함수를 근사한다!
-
(1) 이득 함수: \(A_t=R_t(\tau)-V\left(s_t\right)\).
- (총 보상 - 기대 보상)의 관점으로 보기
- \(R_t(r)=\sum_{k=t}^T \gamma^{k-t} r\left(s_k, a_k\right)\).
- \(V^{\pi}(s)=\mathbb{E}_{\pi}\left[\sum_{t=0}^{\infty} \gamma^t r_t \mid s_0=s\right]\).
-
(2) 이득 함수 대입
-
\(\nabla_\theta J\left(\pi_\theta\right) \approx \mathbb{E}_{\tau \sim \pi_{\theta_\text { old}}}\left[\sum_{t=0}^T \frac{\pi_\theta\left(a_t \mid s_t\right)}{\pi_{\theta_{\text{old}}}\left(a_t \mid s_t\right)} A_t \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right)\right]\).
-
다만, \(V(s_t)\)는 inaccesible!
\(\rightarrow\) \(V_\psi\left(s_t\right)\)로 parameterize해서 추정하자
( 목적함수: \(s_t+ \gamma V\left(s_{t+1}\right)-V\left(s_t\right)\))
-
[PPO 식 요약]
\(\nabla_\theta J\left(\pi_\theta\right) \approx \mathbb{E}_{\tau \sim \pi_{\theta_\text { old}}}\left[\sum_{t=0}^T \frac{\pi_\theta\left(a_t \mid s_t\right)}{\pi_{\theta_{\text{old}}}\left(a_t \mid s_t\right)} A_t \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right)\right]\).
-
\(A_t=R_t(\tau)-V_\psi\left(s_t\right)\).
-
\(r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log \frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{r e f}\left(o_t \mid q, o_{<t}\right)}\).
(2) PPO vs. GRPO
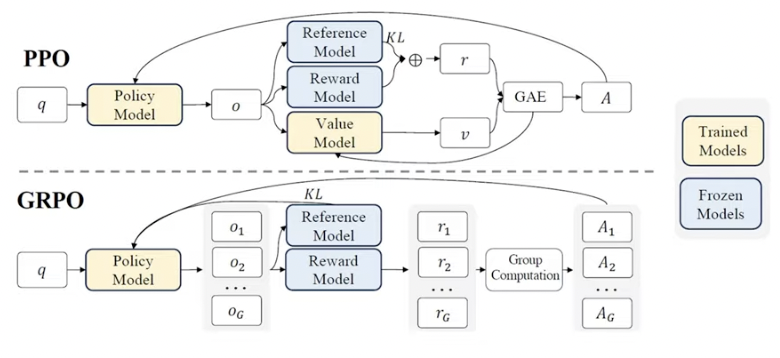
-
PPO (Proximal Policy Optimization)
-
GRPO (Group Relative Policy Optimization)
PPO에서 필요한 모델
- \(\pi_{\theta}\): LLM
- \(V_\psi\): 평균 Reward (=Value) 모델
- \(r_\phi\): Reward 모델
- \(\pi_{\text{ref}}\): (Reward hacking 방지용) checkpoint 모델
GRPO: 위에서 \(V_\psi\)를 없애자!
- Value 모델 없이, 평균 이득을 계산하도록 우회하자!
- How?
- Step 1) 하나의 질문에 대해 여러 답변 생성
- 하나의 q에 대해 \(G\)개의 \(o_i\) 생성
- Step 2) 이를 평균낸 것을, Value로써!
- Step 1) 하나의 질문에 대해 여러 답변 생성
(3) Rule-based Reward Modeling
GRPO를 활용한 Modeling
두 종류의 reward
- Accuracy rewards
- 수학 문제 \(q\) \(\rightarrow\) \(o\)의 마지막에 최종 정답을 맞게 도출 시 reward
- 코딩 문제 \(q\) \(\rightarrow\) \(o\)의 생성 코드가 compiler 통해 실행 후 정답 시 reward
- Format rewards
- 임의 문제 \(q\) \(\rightarrow\) 정해진 format 따르면 reward

Example
https://medium.com/@sahin.samia/the-math-behind-deepseek-a-deep-dive-into-group-relative-policy-optimization-grpo-8a75007491ba


(4) Result
a) Self-evolution (on test-time axis scaling)
현상: 학습 진행 시, 정확도 & thinking 길이 상승!
- 길게 생성하라고 명시적으로 Reward (X)
- (문제를 잘 풀었을때) 받는 Reward를 높이기 위해 길이가 길어짐 (O)
b) Aha Moment

7. DeepSeek R1
DeepSeek R1-Zero의 문제점
- (1) 가독성 부족
- (2) 언어 혼합
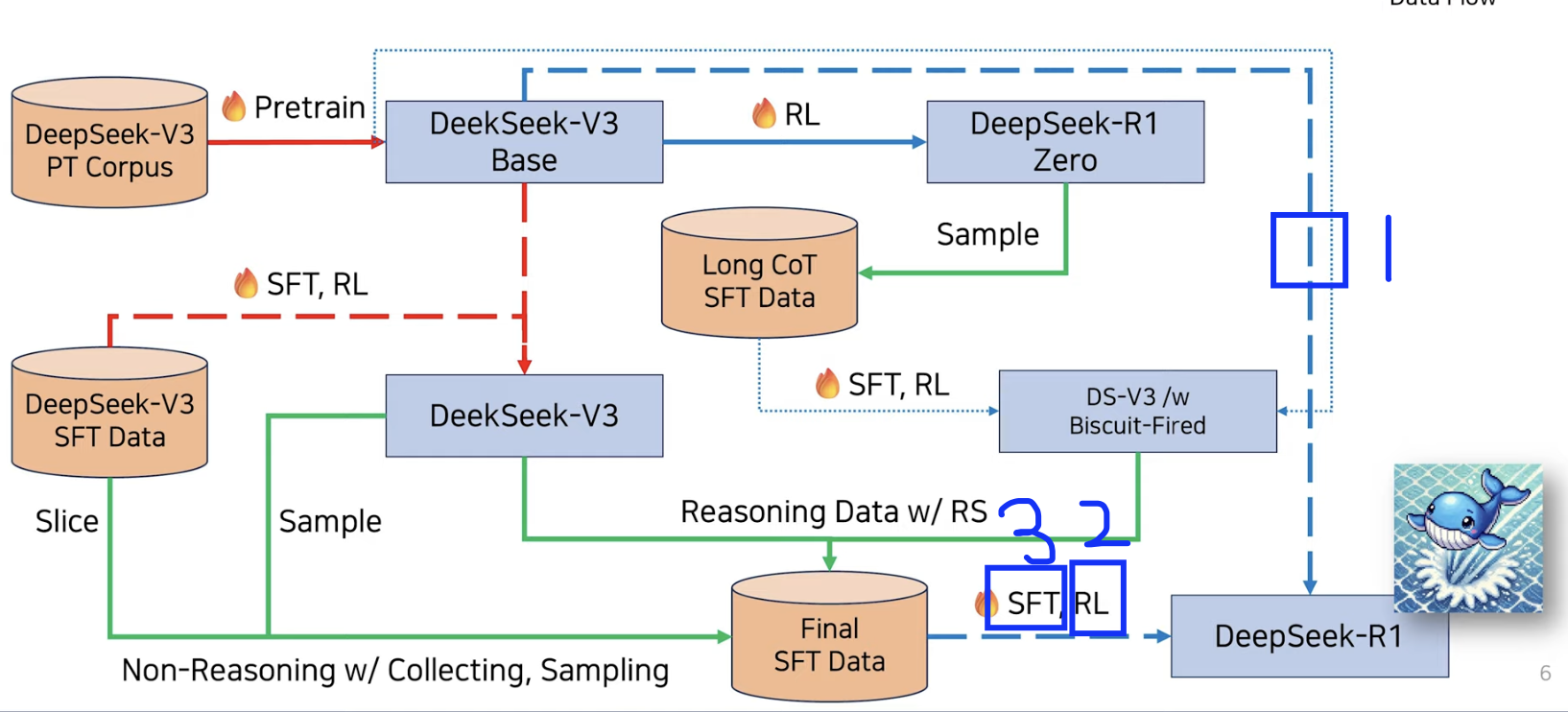
(1) Stage 1: Cold Start
핵심: (소량의) 고품질 데이터를 cold start(초기 학습)하자!
(일반적인 LLM의 post-training과 마찬가지로)
Stage1 = DeepSeek-V3-Base에 SFT
- (1) Long CoT 데이터셋을 통해서!
- Thinking과정이 포함된 Long CoT이다
- (2) 가독성(Readability) 향상 위한 Formatting & Filtering
(2) Stage 2: Reasoning-oriented RL
- 생략
(3) Stage 3: Rejection Sampling & SFT
- 생략
(4) Stage 4: RL for all scenarios
- 생략
8. Summary
DeepSeek
- V3: 적은 computing으로 좋은 성능
- feat. MLA, DeepSeekMoE, Multi-token Prediction Objective, DualPipe
- R1-Zero: SFT 없이 RL만으로 reasoning 능력 \(\uparrow\)
- feat. GRPO
- R1: open-source & GPT4-o 맞먹는 성능