
Unveiling Encoder-Free Vision-Language Models
https://arxiv.org/pdf/2406.11832
Contents
-
Abstract
- Introduction
- Drawbacks of Encoder-based VLMs
- Research Question
- EVE-7B
- Related Work
- Encoder-based VLM
- Encoder-free VLM
- Methodology
- Model Architecture
- Training Procedure
- Experiments
1. Abstract
a) Limitation of existing VLMs
Rely on “vision encoders”
\(\rightarrow\) Set a strong inductive bias in abstracting visual representation
- e.g., resolution, aspect ratio
\(\rightarrow\) Could impede the flexibility and efficiency of the VLMs.
b) Pure VLMs
Accept the seamless V&L inputs (w/o vision encoders)
\(\rightarrow\) Challenging & underexplored!
Previous works) Direct training “without encoders” (feat. Fuyu-8B)
\(\rightarrow\) Slow convergence & Large performance gaps
c) Proposal
-
Bridge the gap between encoder-based & encoder-free models
- Simple yet effective training towards pure VLMs
- Key aspects of training encoder-free VLMs efficiently via …
- (1) Bridging V-L representation inside “UNIFIED” decoder
- (2) Enhancing visual recognition capability via extra SUPERVISION
d) EVE (encoder-free vision-language model)
- Only 35M publicly accessible data
- Rival the encoder-based VLMs across multiple VL benchmarks.
- v.s. encoder-freen VLMs:
- Significantly outperforms Fuyu-8B
- Fuyu-8B: Mysterious training procedures and undisclosed training data
- Significantly outperforms Fuyu-8B
1. Introduction
(1) Drawbacks of Encoder-based VLMs
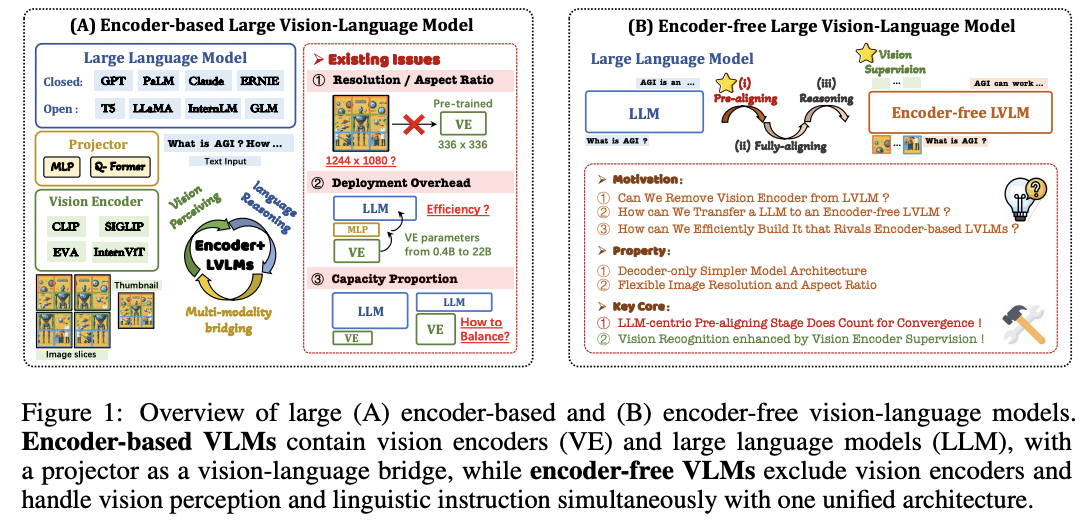
a) Image Resolution / Aspect Ratio
(Existing LVMs) Pre-trained with square and “FIXED-size” images
\(\rightarrow\) Forces VLMs to resize, pad, or partition images of varying shapes
\(\rightarrow\) Large layout distortion!
b) Deployment Overhead
Undermines computational efficiency (in real-world deployment)
- Especially when high-resolution images are divided
c) Model Capacity btw LVMs & LLMs
Scale of LLMs: From 1.3B to more than 540B
\(\rightarrow\) How to strike corresponding vision encoders to maximize their respective abilities?
(2) Research Question
Is it possible to bypass the constraints of vision encoders and integrate perception and reasoning capabilities into a SINGLE UNIFIED architecture?
Previous work in “encoder-free” VLM
- Suffer from greatly “slow convergence” & “large performance gaps”! ( vs. Encoder-based VLMs )
- e.g., Fuyu-8B vs. LLaVA-1.5
Essential problems of constructing encoder-free VLMs from scratch?
-
(1) Representation Unity and Emergent Ability
-
Lack of high-quality image-text data!
-
But plenty of language data
\(\rightarrow\) \(\therefore\) Position LLMs as a central pivot
+ Compel LLMs per se to develop visual perception
( while preserving original linguistic proficiency )
-
Findings: Before scaling up pre-trained data…
\(\rightarrow\) VL pre-aligning from an LLM-centric perspective is important!
( Prevents model collapse and optimization interference )
-
-
(2) Visual Recognition Capability
-
CL, MIM, NTP tasks:
- Pros) Attempt to prompt visual backbones to produce highly compressed holistic semantics
- Cons) But frequently neglect fine-grained visual clues!
-
Proposal: Transmit visual signals almost losslessly into encoder-free VLMs!
\(\rightarrow\) Allow VLMs to autonomously acquire the necessary visual-semantic information
+ Also sidesteps the expensive re-training process of visual encoders for arbitrary image shapes inside encoder-based VLMs!
-
(3) EVE-7B
Encoder-free VLM (Decoder-only VLM)
- Arch: Vicuna-7B
- Trained with two 8-A100 (40G) nodes in ~9 days
Properties
- (1) Naturally supports high-resolution images with arbitrary aspect ratios
- (2) 35M publicly accessible data
- (3) Rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks
- Significantly outperforms the counterpart Fuyu-8B
2. Related Work
(1) Encoder-based VLM
In terms of open-source VLMs, existing methods
- BLIP series [42, 43, 12]
- LLaVA series [50, 49, 51]
- Emu series [72, 70]
- Intern-VL [8, 9]
\(\rightarrow\) Employ simple intermediate layers to bridge the gap between LVMs and LLMs.
Recent studies [48, 49, 20, 28]
-
Recognized the significance of input image resolution & aspect ratio
- For visual perception and cognition,
- e.g, Document, chart, table, and infographic data.
- For visual perception and cognition,
-
However, limited by pre-trained resolution, vision encoders are …
- Compelled to partition images into multiple slices
- Explore a dual-path architecture for low-resolution and high-resolution images respectively
\(\rightarrow\) Resulting in significant image distortion, fragmented relationship between image slices, and additional computational consumption.
+ As the capacity of vision encoders scales up..
\(\rightarrow\) Deployment efficiency of vision models \(\downarrow\)
No definitive conclusion! (1) vs. (2)
- (1) Some studies [49, 51] highlight the notable benefits via substituting CLIP-ViT-B with stronger CLIP-ViT-L-336px in enhancing multimodal models alongside Vicuna-7B [10].
- (2) Other findings [65] indicate that larger vision encoders may not be necessary, as features of multi-scale smaller ones can approximate their performance.
This paper:
Explore a pure decoder-only VLM excluding vision encoders
+ Integrate VL understanding and reasoning capabilities into one unified architecture
Effect: Bypass the inherent problems inside encoder-based VLMs
- ex 1) Input constraints of pre-trained vision encoders
- ex 2) Inefficiency issues of application deployment
- ex 3) Tricky capacity trade-offs between LVMs and LLMs
(2) Encoder-free VLM
Fuyu-8B
-
(1) Decoder-only network
- Processes image inputs without relying on an image encoder
-
(2) Handles high-resolution images with arbitrary aspect ratios
( \(\because\) Image patches are fed directly into the model through a simple linear projection layer )
Limitation of Fuyu-8B
- Only average performance across VL benchmarks
- Lacks transparency in training strategies and data sources
Effect of Fuyu-8B
This straightforward architecture has inspired further research
- which focuses on developing powerful supervised instruction datasets to further enhance application capabilities.
Proposal
Developing pure VLMs
+ Breaking the obstacles between encoder-based and encoder-free VLMs.
Two crucial lessons
- (1) Before scaling up pre-trained data, it is essential to prioritize VL pre-alignment from an LLM-centric perspective.
- Stabilizes the training process
- Alleviates optimization interference for integrating visual and linguistic information
- (2) Enhancing image recognition capability via visual representation supervision and language conceptual alignment generates stronger visual representations
3. Methodology
(1) Model Architecture
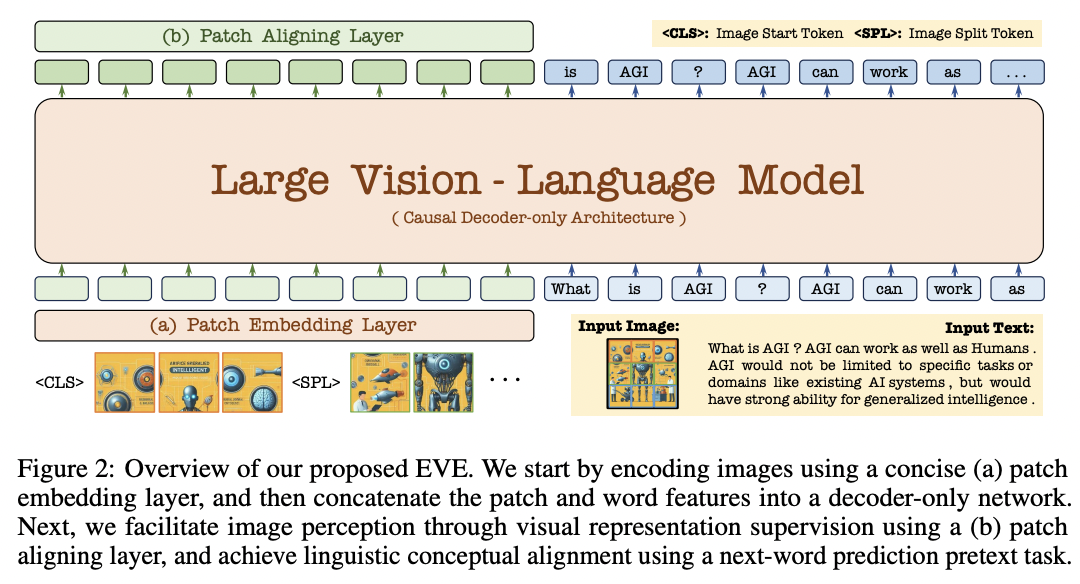
- (1) Decoder-only EVE: by Vicuna-7B
- (2) Lightweight patch embedding layer
Two losses
- (1) Attempt to align patch features with pair-wise ones from the vision encoder (VE)
- Through a hierarchical patch aligning layer.
- (2) EVE predicts next-word labels
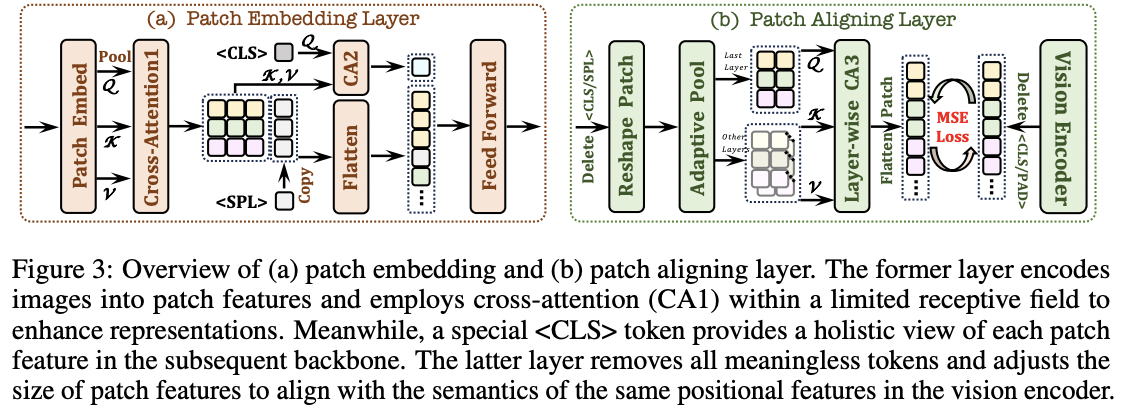
a) Patch Embedding Layer (PEL)
[Goal] To transmit images almost losslessly
- Rather than using deep encoders or tokenizers
[Input] Image with (H, W) resolution
[Procedure]
- Step 1) Convolution layer
- To obtain a 2-D feature map with (h, w)
- Step 2) Average pooling layer
- Step 3) Cross-Attention (CA1) layer
- **Step 4) Cross-Attention (CA2) layer **
- Btw a special token and all patch features
- Output: Serves as the starting symbol of the image & provides holistic information for patch features
- Step 5) Learnable newline token
- Considering the varying aspect ratios of image inputs, we insert a learnable newline token at the end of each row of patch features.
- Helps the network understand the 2-D spatial structure and dependencies of the image.
- Step 6) Flatten & NN
- Flatten these features
- Pass them through a two-layer NN
- Step 7) Concat with text
- Concatenate with text embeddings into one unified decoder-only architecture.
b) Patch Aligning Layer (PAL)
[Goal] To facilitate finegrained representations
(2) Training Procedure
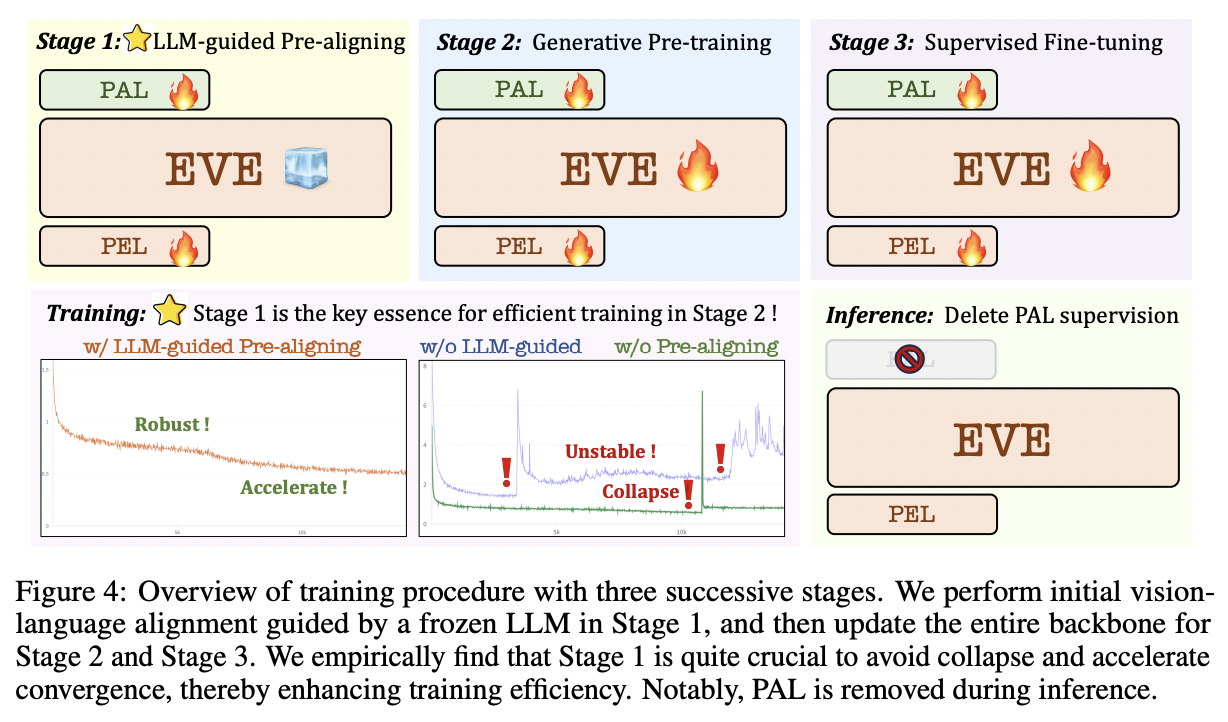
Three successive stages: Train EVE with …
- (1) Publicly available image data captioned by existing VLMs
- (2) Diverse QA data
- (3) Multi-modality dialogue datasets
(Remove PAL supervision during inference)
Step 1) LLM-guided Pre-training
[Goal] Initial connection between V&L modalities
[Dataset] Publicly available web-scale data (EVE-cap33M)
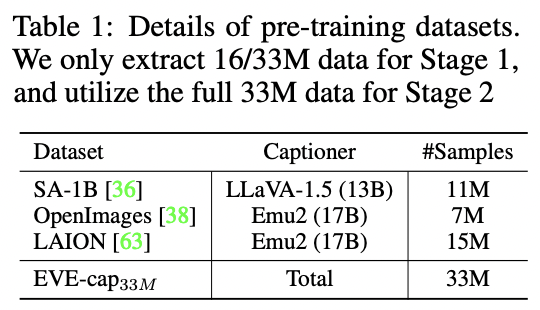
EVE-cap33M: Remove noisy text captions
\(\rightarrow\) Reproduce 33M high-quality descriptions
- via Emu2 (17B) and LLaVA-1.5 (13B)
[Trainable layers]
- Patch Embedding Layer
- Patch Aligning Layer
- (LLM: Vicuna-7B is frozen)
Details:
- Only adopt 16M of 33M image-text data (EVE-cap16/33M) in this stage.
- Use both (text) CE loss and (image) MSE loss
Findings:
-
Stage 1 does count for efficient training!!
( \(\because\) Prevents collapse and accelerates convergence throughout the entire process )
Step 2) Generative Pre-training
[Goal] Train all modules!
Details:
- Use of all 33M image-text pairs (EVE-cap33M)
- Keep both (text) CE loss and (image) MSE loss
Findings:
- Although multi-modality performance gradually increases
- Language capability suffers from a significant downtrend
Step 3) SFT
pass
4. Experiments
Public visual-language benchmarks
- (1) Academic-task-oriented benchmarks (VQA-v2 [25], GQA [29], VizWiz [26], and TextVQA [67])
- (2) Hallucination benchmarks (POPE [47])
- (3) Open-world multi-modal understanding benchmarks (MME [23], MMBench [52], SEED-Bench [41], and MM-Vet [89])
- (4) Scientific problem benchmarks (ScienceQA-IMG [54]).