Flamingo: a Visual Language Model for Few-Shot Learning
https://arxiv.org/pdf/2204.14198
1. Abstract
Flamingo
- A family of VLMs
- Rapid adapted to novel tasks using only a handful of annotated examples
- Key architectural innovations
- (1) Bridge powerful pretrained vision & language models
- (2) Handle sequences of arbitrarily interleaved visual and textual data
- (3) Ingest images or videos as inputs
- Trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images
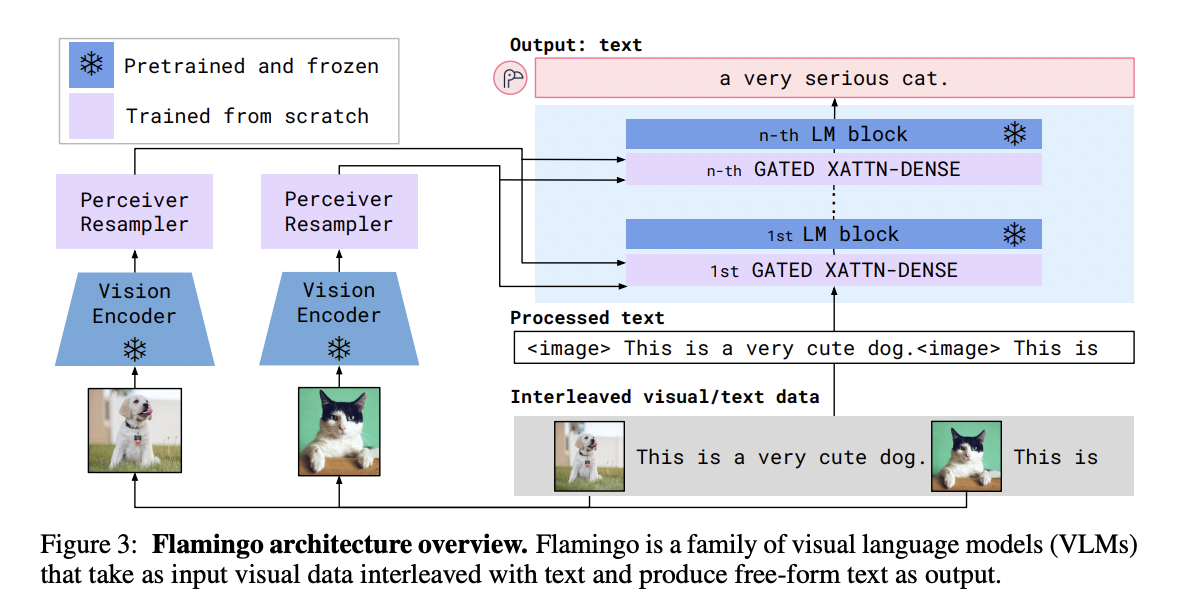
2. Approach
Flamingo = VLM with…
- Input: Text interleaved with images/videos
- Output: Free-form text
Key architectural components
- To leverage pretrained vision and language models and bridge them effectively
- (1) Perceiver Resampler
- Input: Receives spatio-temporal features from the Vision Encoder
- Output: Fixed number of visual tokens
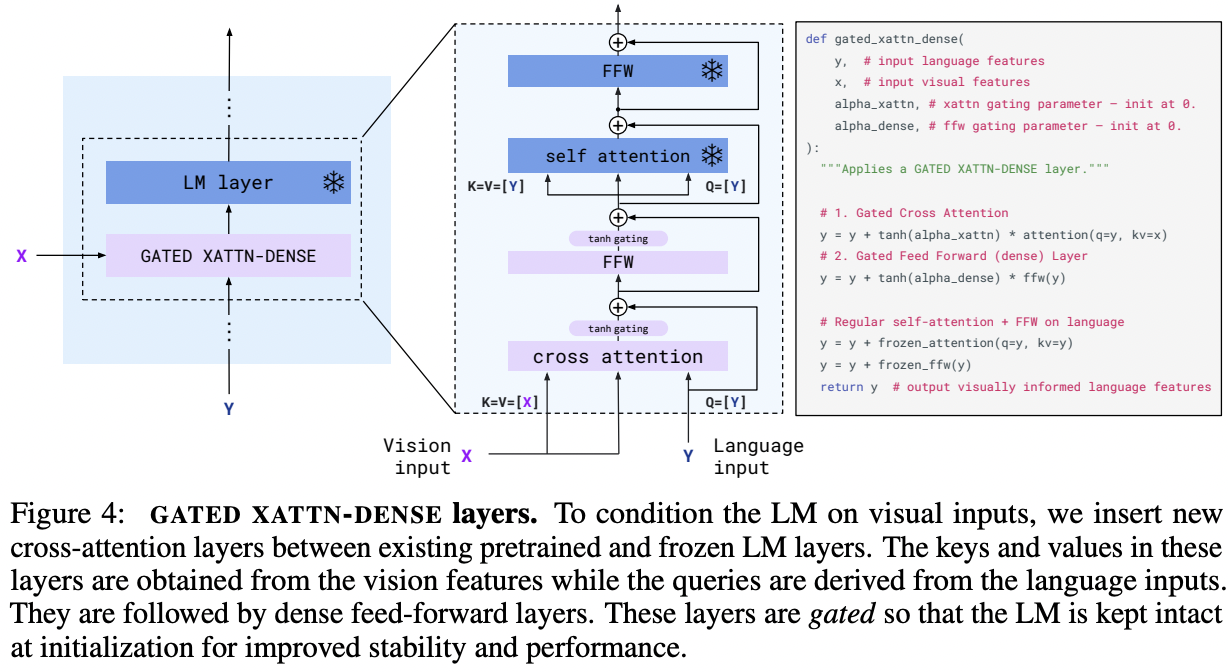
- (2) Cross-attention layers
- Visual tokens are used to condition the frozen LM!
- Offer an expressive way for the LM to incorporate visual information for the next-token prediction task!
- \(p(y \mid x)=\prod_{\ell=1}^L p\left(y_{\ell} \mid y_{<\ell}, x_{\leq \ell}\right)\).