
UNIT: Unifying Image and Text Recognition in One Vision Encoder
https://arxiv.org/pdf/2409.04095
Contents
- Abstract
- Language & Vision Decoder
- “Text Recognition” Ability Enhancement
- “Image Recognition” Ability Preservation
- Two stages of Training
- Intra-scale pretraining
- Inter-scale fine-tuning
1. Abstract
Vision Transformers (ViTs)
- Excel at image recognition tasks
\(\rightarrow\) But cannot simulataneously support text recognition!
Solution: UNIT
- Novel training framework aimed at “UNifying Image and Text recognition” within a “single model”
Details
- Start with a vision encoder (pre-trained with image recognition tasks)
- Introduce two components
- [1] Lightweight “language” decoder: For predicting text outputs
- [2] Lightweight “vision” decoder: To prevent catastrophic forgetting of the original image encoding capabilities.
- Two stages of training
- (1) Intra-scale pretraining
- (2) Inter-scale fine-tuning
2. Language & Vision Decoder
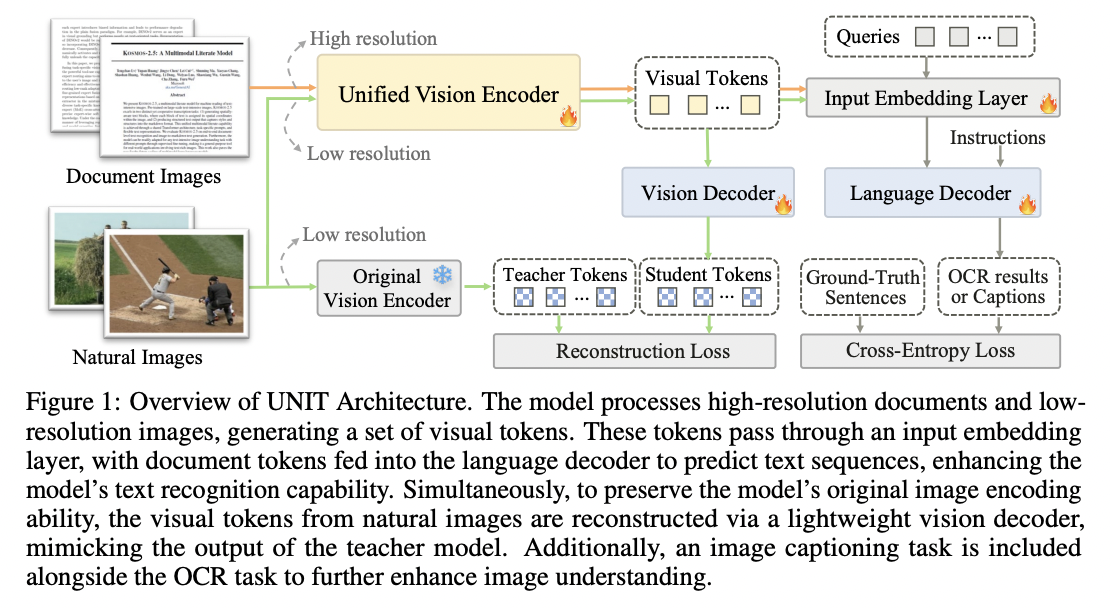
(a) “Text Recognition” Ability Enhancement
Predict language sequence in the form of text tokens
\(\mathcal{L}_{\operatorname{lan}}(\mathbf{y}, \hat{\mathbf{y}})=-\sum_{t=1}^T \log P\left(\hat{y}_t=y_t \mid \mathbf{y}_{1: t-1}, \mathbf{z}_t^L\right)\).
(b) “Image Recognition” Ability Preservation
Reconstruction task on natural image datasets,
\(\mathcal{L}_{\mathrm{vis}}(\mathbf{X}, \hat{\mathbf{X}})=\sum_{i \in \mathcal{C}} L_{\mathrm{cos}}\left(f_\pi\left(\mathbf{x}_i\right), \hat{\mathbf{x}}_i\right)+\mu L_{11}\left(f_\pi\left(\mathbf{x}_i\right), \hat{\mathbf{x}}_i\right)\).
3. Two stages of Training
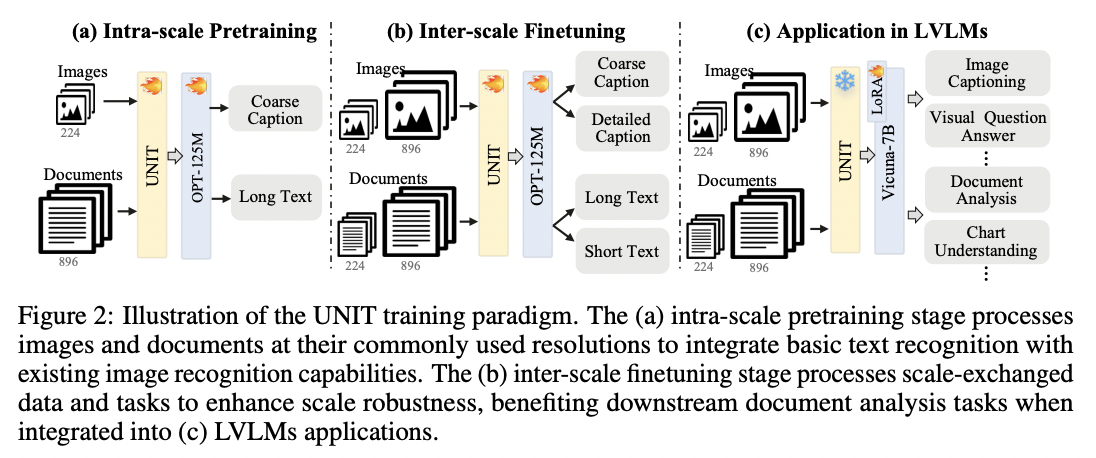
(a) Intra-scale pretraining
- Learns unified representations from multi-scale inputs
- How? Images and documents are at their commonly used resolution
- Why? To enable fundamental recognition capability.
(b) Inter-scale fine-tuning
- Introduces “scale-exchanged” data
- How? Images and documents at resolutions different from the most commonly used ones
- Why? To enhance its scale robustness
(c) Loss functions
Intra-scale pretraining
- \(\theta=\arg \min _\theta \mathcal{L}_{\mathrm{lan}}\left(\left\{\mathcal{D}_{\times 1}^I \cup \mathcal{D}_{\times 4}^T\right\}\right)+\lambda \mathcal{L}_{\mathrm{vis}}\left(\left\{\mathcal{D}_{\times 1}^t\right\}\right)\).
Inter-scale fine-tuning
- \(\theta=\arg \min _\theta \mathcal{L}_{\operatorname{lan}}\left(\left\{\mathcal{D}_{\times 4}^I \cup \mathcal{D}_{\times 1}^T \cup \frac{1}{2} \mathcal{D}_{\times 1}^I \cup \frac{1}{2} \mathcal{D}_{\times 4}^T\right\}\right)+\lambda \mathcal{L}_{\mathrm{vis}}\left(\left\{\frac{1}{2} \mathcal{D}_{\times 1}^I \cup \mathcal{D}_{\times 4}^l\right\}\right)\).