
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
https://arxiv.org/pdf/1908.06066
Unicoder-VL
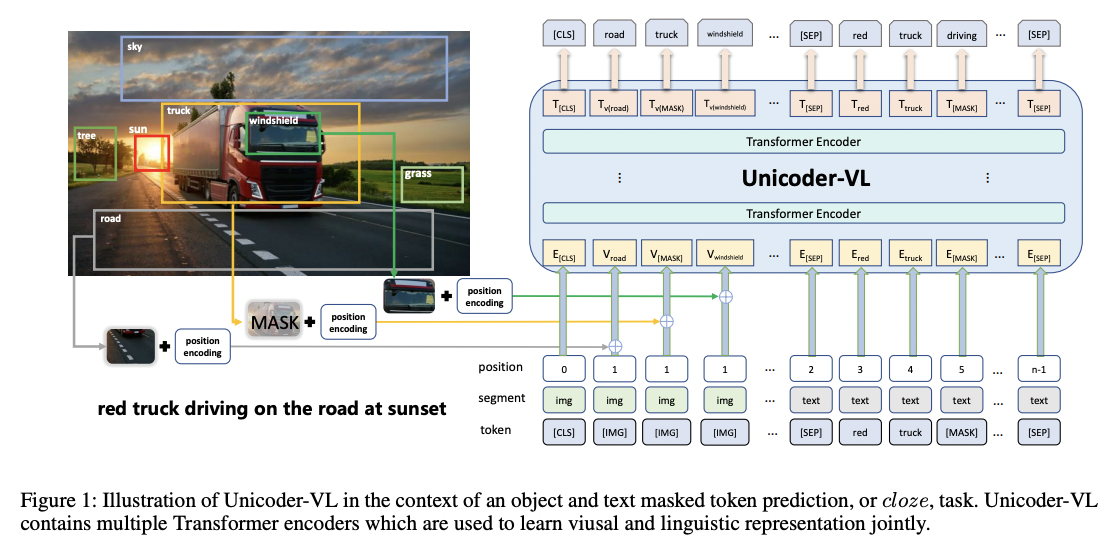
-
(1) Universal encoder
- Aims to learn joint representations of vision and language
- Both visual and linguistic contents are fed into a Transformer for the cross-modal pre-training
-
(2) Three pre-trained tasks
- Masked Language Modeling (MLM)
- Masked Object Classification (MOC)
- Visual-linguistic Matching (VLM)
-
(3) Transfer Unicoder-VL to …
- Caption-based image-text retrieval
- Visual commonsense reasoning
( with just one additional output layer )
Masked Object Classification (MOC)
- Step 1) Sample image regions
- Step 2) Mask their visual features with a probability of 15%
- Step 3) Replace the object feature vector with a zero-initialized vector
- Prediction & GT
- [Prediction] Output of the masked region
- [GT] Object category with the highest confidence score predicted by the same detection model