
VLM Downstream Tasks
https://www.youtube.com/watch?v=8ofFVYPS8vA
Contents
- Introduction
- VQA and Visual Reasoning
- VQA v1
- VQA v2
- OK-VQA
- visDial
- GQA
- VCR
- NVLR
- Visual Entailment
- SNLI-VE
- Image Captioning
- COCO caption
- noCap
- Visual Grounding
- Flickr30k
- RefCOCO
- Multi-lingual VQA/Captioning
- Multi30K
- XTD10
- XM-3600
- WiT
- xGQA
Introduction
VLM downstream task의 종류들
- VQA and Visual Reasoning
- Visual Entailment
- Image Captioning
- Visual Grounding
- Multi-lingual VQA/Captioning
1. VQA and Visual Reasoning
한 줄 요약: 주어진 이미지 관련 질문에 대답하기
- Q) 이미지 + 질문
- A) 단답형 정답 (brief answer phrase)

(1) VQA v1 (2015)
-
최초의 VQA benchmark (2015)
-
[1] 종류: 2종류의 task
- (1) 주관식: Open-ended task
- (2) 객관식: Multiple-choice task (18 choices / question)
-
[2] Real 데이터셋: MS-COCO
- Train/Val/Test = 82783/40504/81434
- 10 questions per image
-
[3] Abstract 데이터셋
( 정제된 image로만 구성 )
- Train/Val/Test = 10k/20k/20k
- 3 questions per image

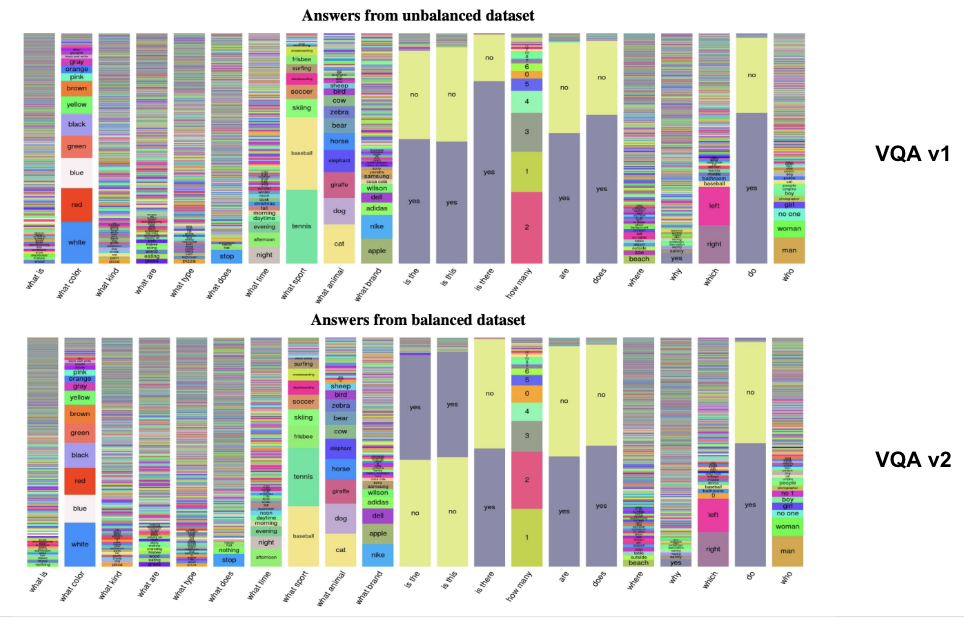
(2) VQA v2
VQA v1의 한계점을 극복하기 위해 등장
- 한계점: Language prior (bias)
특징
-
265,016 images
- 5.4 questions per image
-
10 GT per question
( + 3 plausible answers (but wrong) per question )
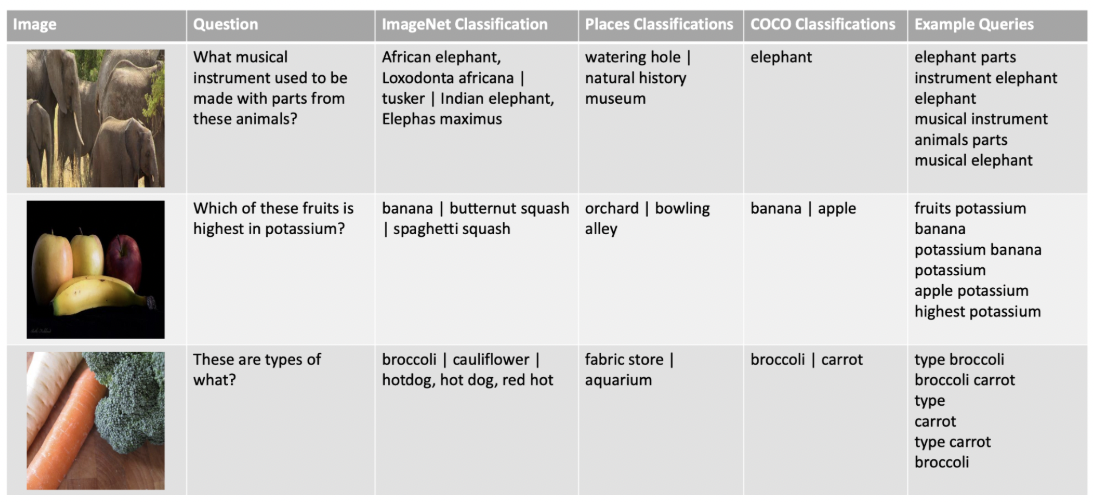
(3) OK-VQA
Visual reasoning with Open Knowledge
- OK = Open Knowledge
\(\rightarrow\) 정답을 내기 위해서, 외부 지식 (open knowledge)가 필요하다!
특징
- Image + Question + External knowledge \(\rightarrow\) Answer
- Train/Test: 9099/5046
- 5 GT per question
- 10 categories

절차
- Step 1) Search query 만들기
- (방법 1) Question에서 non-stop word를 전부 추출
- (방법 2) Image에서 (모델을 이용하여) visual entities 추출
- Step 2) Wikipedia search API 통한 retrieval
- Step 3) Select most relevant sentences
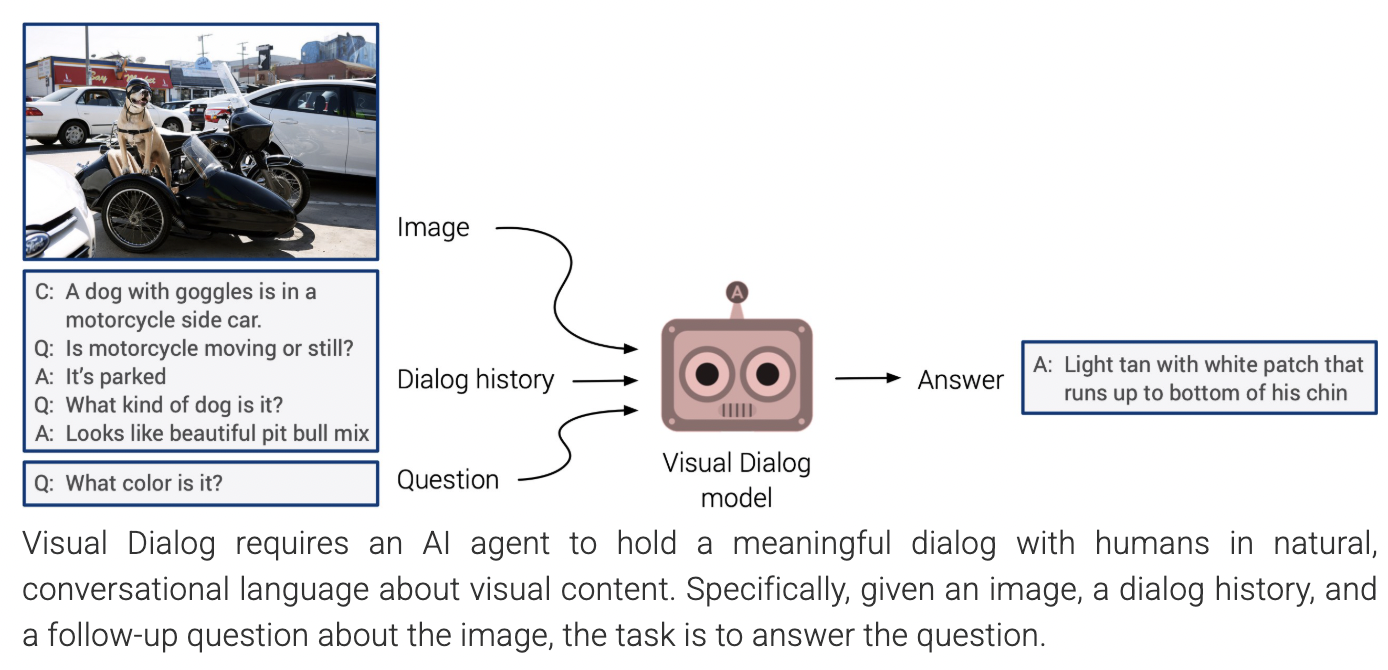
(4) visDial
Conversation (image + caption)용
- Image + Caption + Dialog history + Question \(\rightarrow\) Answer
120K from COCO
- 1 image = 1 dialog
- 1 dialog = 10 rounds (20 turns) of Q&A

(5) GQA
그래프 구조를 띈 GQA
- Image + “정교한” Question \(\rightarrow\) Answer
- “정교한” Question = 이미지 내의 object, attributes, relation 관련 질문들

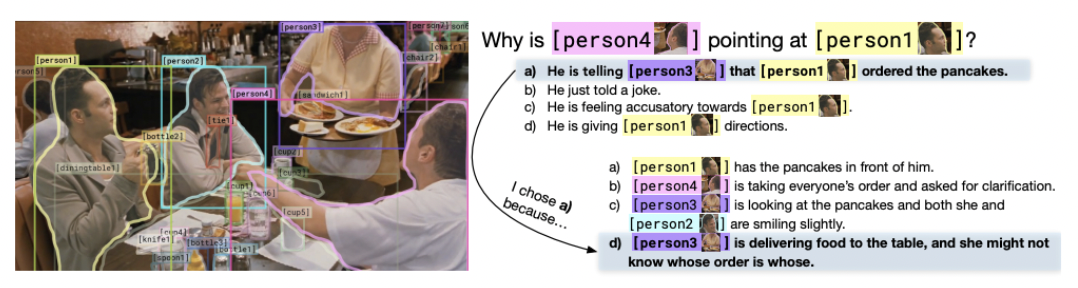
(6) VCR (Visual Common sense Reasoning)
이미지에 대한 상식 (common sense) 등의 고차원적인 답변을 요구
- (1) 질문에 대한 답변 ( = VQA )
- Q \(\rightarrow\) A (Answer)
- (2) 위의 (1)에 대한 rationale을 선택 ( = VCR )
- Q, A \(\rightarrow\) R (rationale)
특징
-
image2text retrieval 모델링이 기본
(QA by multiple choice)
-
VQA 보다 어렵다!
(7) NVLR (Natural Language Visual Reasoning)
한 쌍의 (두 개의) 이미지를 대상으로 질문!
- (상세) 한 쌍의 이미지에 대한 description이 True/False 맞추기!

2. Visual Entailment
(1) SNLI-VE
(NLP에서의) NLI task와 유사
- Q) Premise (image) + Hypotheseis
- A) Entailment / Neutral / Contradiction 중!
데이터셋: Flick30k (image captioning 데이터셋)
- 구성: (image, caption text)

Visual Reasoning (NVLR2) 과 Visual Entailment (SNLI-VE)의 차이점은?
- VR: image + question에 대한 대답을 T/F로 답변
- VE: image에 대한 text를 Entailment / Neutral / Contradiction 중 하나로 대답.
즉, 주어지는 text가 “hypotheseis (VE)”인지, “question (VR)”인지 차이가 있다!
3. Image Captioning
이미지를 묘사하는 caption을 생성하기 (image2text)
- 입력: Image
- 출력: Caption
(1) COCO caption
두 종류
- COCO2014: Train/Val/Text = 83k/50.5k/81k
- COCO2017: Train/Val/Text = 118k/5k/41k
Hierarchical Category
- 11 super-categories
- 91 categories
- 1000 images per category

(2) noCap (Novel Object Captioning)
특징
- MS-COCO의 확장된 version의 image caption
- Train 없음 ( only Valid/Text = 4.5k:10.6k )
- 셋으로 구성됨
- IND (In-domain)
- NIND (Near in-domain)
- OOD (Out of domain)

4. Visual Grounding
Visual Grounding vs. Image Captioning
- Image Captioning: 이미지에 대한 거시적 설명
- Visual Grounding: 이미지에 대한 특정 부분을 “indicate”하고 있음!
- Bounding box가 존재함
(1) Flickr30k
- 1개의 image = 5개의 caption sentence
- 1개의 caption sentence: 각 문장의 entity(phrase)에 대한 “Bounding box”이 달려있음

(2) RefCOCO
Visual Grounding을 “더 상세하게” 한 benchmark!
\(\rightarrow\) Referring expression comprehension (보다 자세히 묘사함)
세 종류의 데이터셋 (평균 답변 길이 & image 당 카테고리 수)
- RefCOCOg (8.43 & 1.63)
- RefCOCO (3.61 & 3.9)
- RefCOCO+ (3.53 & 3.9)

Phase grounding (Flickr30)과 Referring expression comprehension (RefCOCO)의 차이점

5. Multi-lingual VQA/Captioning
(1) Multi30K
Flickr30k의 multilingual version (영어+독일어+프랑스어)
- 전문 번역가를 통해 번역함

(2) XTD10
Multilingual image captioning dataset
특징
-
Train 없음 ( only Valid/Text from COCO2014 )
-
8개 언어 지원: Italian, Spanish, Korean, Russian, Polish, Turkish, Chinese Simplified
(3) CrossModel-3600 (XM-3600)
Multilingual image captioning dataset
특징
- Human-generated caption
-
Test set만 있음
- Open image datset로부터 3600개의 이미지를 샘플링함
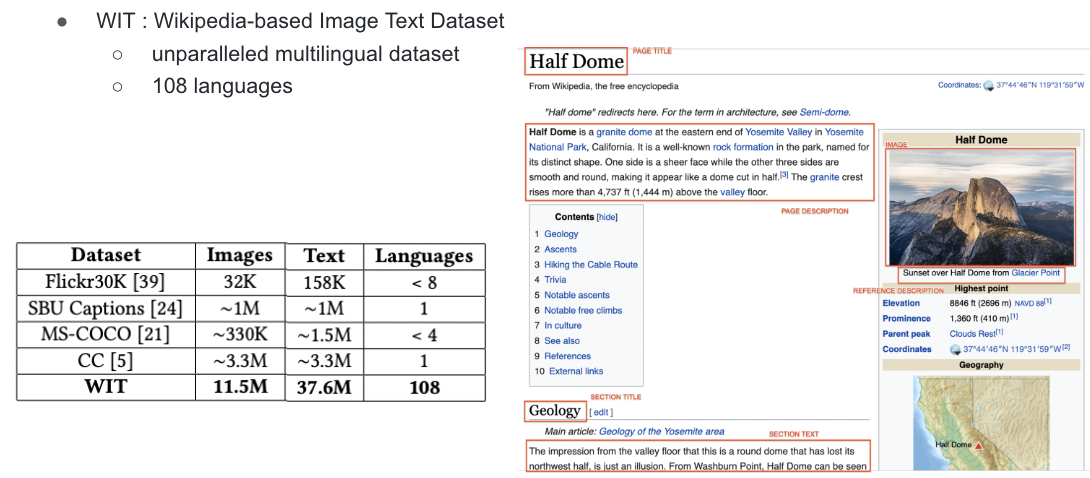
(4) WiT
Wikpedia-based Image Text dataset
특징
- 규모가 매우 큼
- 108개의 언어 지원
- Unparalleled (언어 쌍 존재 X)
(5) xGQA
GQA의 multilingual version
특징
- 앞선 (1)~(4)는 전부 captioning 데이터셋
- (5) xGQA는 VQA 데이터셋