Vision-Language Models for Vision Tasks: A Survey
https://arxiv.org/pdf/2304.00685
Contents
- Abstract
- (1) Introduction
- Visual recognition tasks
- VLM training paradigm
- Two line of research
- Contributions
- (2) Background
- Training Paradigms for Visual Recognition
- Development of VLMs for Visual Recognition
Abstract
Vision-Language Models (VLMs)
- Goal: Learn rich “vision-language” correlation
- Dataset: Web-scale “image-text” pairs
- Results: Enables zero-shot predictions (on various visual recognition tasks)
This paper:
Review of VLMs for various visual recognition tasks
- (1) Background of visual recognition
- (2) Foundations of VLM
- Network architectures
- Pre-training objectives
- Downstream tasks
- (3) Datasets in VLM pre-training and evaluations
- (4) Review & Categorization of existing ….
- VLM “pre-training” methods
- VLM “transfer learning” methods
- VLM “knowledge distillation” methods
- (5) Benchmark
- (6) Research challenges & Future works
1. Introduction
P1) Visual recognition
Visual recognition tasks (IOS)
- (1) Image classification
- (2) Object detection
- (3) Semantic segmentation
Challenges? (Traditional ML \(\rightarrow\) E2E DL)
- (1) Slow convergence of DNN training (under learning from scratch)
- (2) Laborious collection of datasets
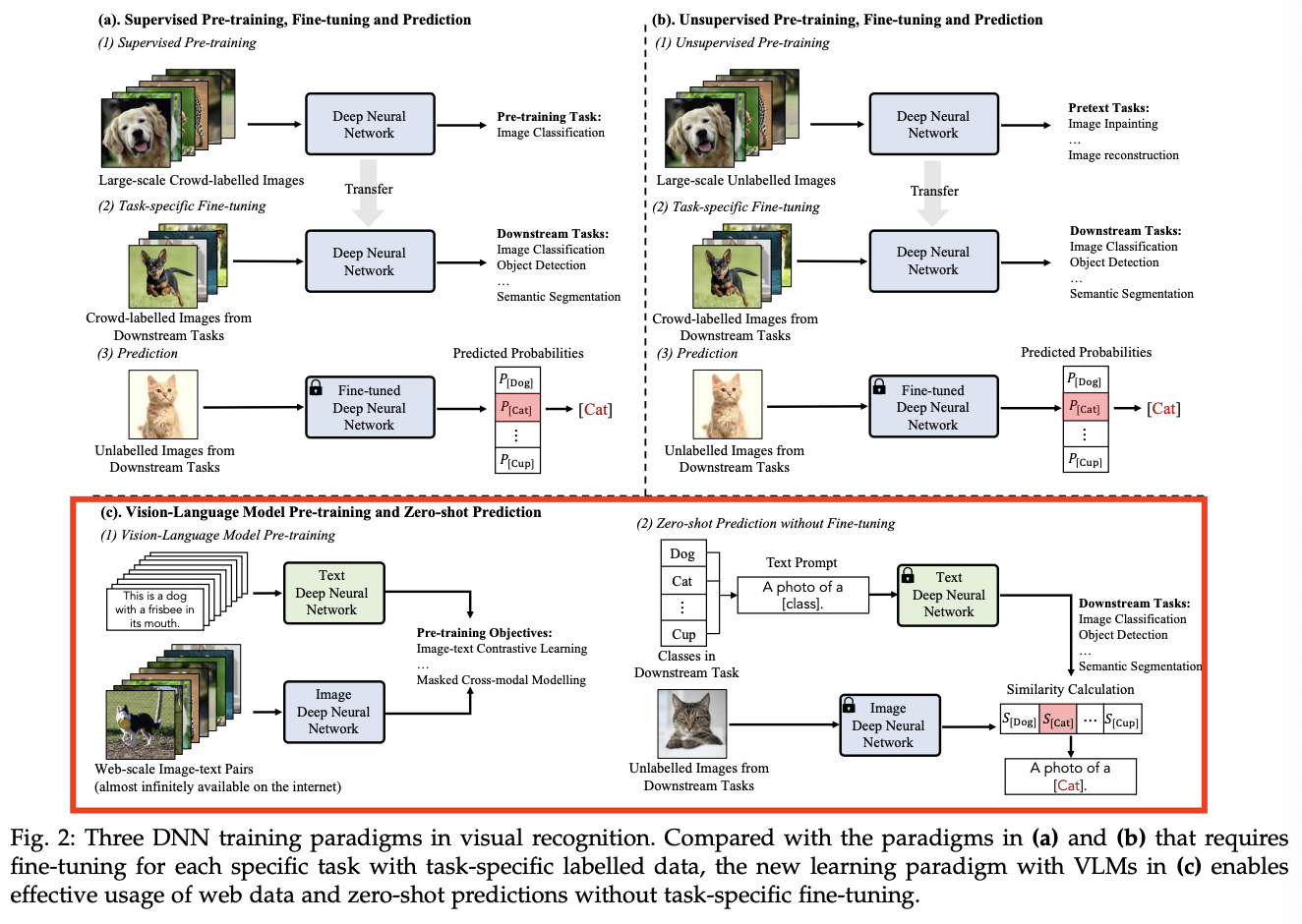
P2–3) VLM training paradigm
- Previous) Pretraining - Finetuning - Prediction
- Recent) Pretraining - “Zero-shot” Prediction
- Step 1) VLM is pre-trained with large-scale image-text pairs
- Step 2) Pretrained VLM can be applied to downstream tasks w/o fine-tuning
VLM Pre-training
-
By vision-language objectives
\(\rightarrow\) Enable to learn image-text correspondences
-
e.g., CLIP: Employs contrastive learning
-
Pretrained CLIP: Superior “zero-shot” performance (on 36 visual recognition tasks)
P4) Two line of research
-
VLMs with “Transfer learning”
-
Effective adaptation of pre-trained VLMs towards various tasks!
-
e.g., prompt tuning, visual adaptation
-
-
VLMs with “Knowledge distillation”
- Explores on how to distill knowledge from VLMs to tasks
P6) Main contributions of this work
- Systematic review of VLMs (for visual recognition tasks)
- Up-to-date progress of VLMs
- Research challenges & Potential research directions
2. Background
- Training paradigm of visual recognition
- VLM Pre-training & Zero-shot Prediction
- Development of the VLMs for visual recognition.
(1) Training Paradigms for Visual Recognition
P1) Traditional Machine Learning and Prediction
Rely heavily on feature engineering (with hand-crafted features)
\(\rightarrow\) Requires domain experts
P2) Deep Learning from Scratch and Prediction
Enables end-to-end trainable DNNs
Two new challenges:
- (1) Slow convergence of DNN training (under from scratch)
- (2) Laborious collection of large-scale, task-specific, and crowd-labelled data
P3-6) Change in paradigms
Paradigm 1) Scratch + Prediction
Paradigm 2) Supervised Pre-training + Fine-tuning + Prediction
Paradigm 3) Unsupervised Pre-training + Fine-tuning + Prediction
Paradigm 4) Unsupervised Pre-training + Zero-shot Prediction
- Enables effective use of large-scale web data for pretraining
- Zero-shot predictions w/o fine-tuning
Improve VLMs from 3 perspectives
- (1) Collecting (image-text) data
- (2) Designing high-capacity models
- (3) Designing new pre-training objectives
(2) Development of VLMs for Visual Recognition
Great progresses since CLIP
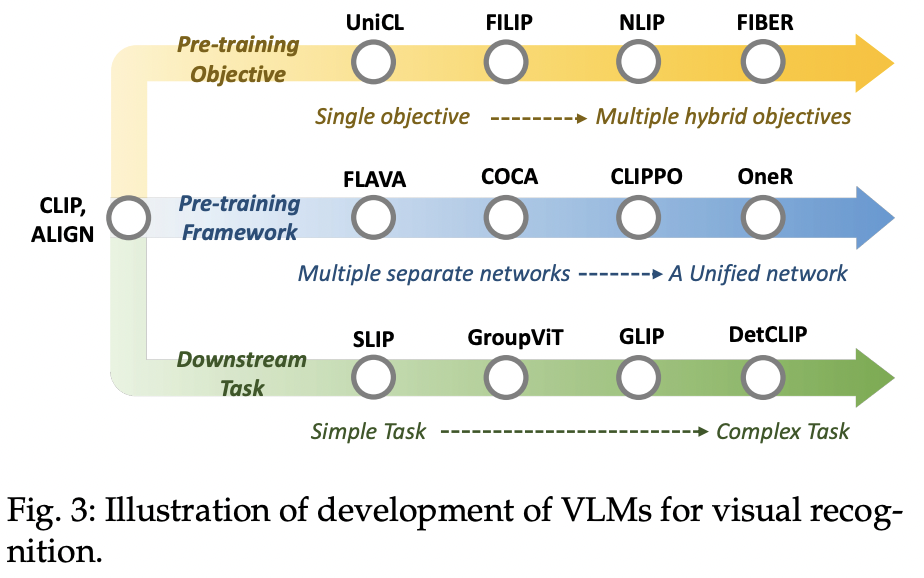
P1) Pre-training Objectives
“single objective” \(\rightarrow\) “multiple hybrid objectives”
- Early VLMs: single objective
- Recent VLMs: multiple objectives
- e.g., contrastive, alignment and generative objectives
P2) Pre-training Frameworks
“multiple separate” networks \(\rightarrow\)“unified” network
-
Early VLMs: Two-tower pre-training frameworks
-
Recent VLMs: One-tower pretraining framework
\(\rightarrow\) Encodes images and texts with a unified network
( with less GPU memory & more efficient communications across modalities )
P3) Downstream tasks
“simple” tasks \(\rightarrow\) “complex” tasks
-
Early VLMs: Image-level visual recognition tasks
-
Recent VLMs: General-purpose
-
Also work for dense prediction tasks
( that are complex and require localization related knowledge )
-
3. VLM Foundations
VLM pre-training
- Aims to pretrain a VLM to learn image-text correlation
- For effective zero-shot predictions
Procedure
- Step 1) Text encoder & Image encoder
- To extract image and text features
- Step 2) Pre-training objectives
- Learns the vision-language correlation
- Step 3) Evaluation
- On unseen data in a zero-shot manner
This section: Foundations of VLM pre-training
- a) Network architectures
- For extracting image and text features
- b) Pre-training objectives
- For modelling vision-language correlation
- c) Frameworks
- For VLM pre-training
- d) Downstream tasks
- For VLM evaluations
(1) Network Architectures
Notation
- Dataset \(\mathcal{D}=\left\{x_n^I, x_n^T\right\}_{n=1}^N\),
- Image encoder \(f_{\theta}\) ,
- Image embedding \(z_{\mathrm{n}}^I=f_\theta\left(x_n^I\right)\)
- Text encoder \(f_{\phi}\),
- Text embedding \(z_n^T=f_\phi\left(x_n^T\right)\),
P1) For Image
-
(1) CNN-based (e.g., ResNet)
-
(2) Transformer-based (e.g., ViT)
P2) For Text
Most VLM studies (e.g., CLIP):
- Employs Transformer ( + with minor modifications )
(2) Pretraining Objectives
Three categories:
- (1) Contrastive objectives
- (2) Generative objectives
- (3) Alignment objectives
P1) Contrastive Objectives
a) Image CL
- InfoNCE and its variants
- \(\mathcal{L}_I^{\text{InfoNCE}}=-\frac{1}{B} \sum_{i=1}^B \log \frac{\exp \left(z_i^I \cdot z_{+}^I / \tau\right)}{\sum_{j=1, j \neq i}^{B+1} \exp \left(z_i^I \cdot z_j^I / \tau\right)}\).
- \(z_i^I\) : Query embedding
- \(\left\{z_j^I\right\}_{j=1, j \neq 1}^{B+1}\) : Key embeddings
- \(z_{+}^I\): \(z_i^I\) ‘s positive key ( rest: negative keys )
b) Image-Text CL
-
Symmetrical image-text InfoNCE loss
( i.e., \(\mathcal{L}_{\text {InfoNCE }}^{\prime }=\) \(\mathcal{L}_{I \rightarrow T}+\mathcal{L}_{T \rightarrow I}\) )
- \(\mathcal{L}_{I \rightarrow T}\) : Contrasts the (query image & text keys)
- \(\mathcal{L}_{T \rightarrow I}\): Contrasts the (query text & image keys)
-
\(\begin{aligned} & \mathcal{L}_{I \rightarrow T}=-\frac{1}{B} \sum_{i=1}^B \log \frac{\exp \left(z_i^I \cdot z_i^T / \tau\right)}{\sum_{j=1}^B \exp \left(z_i^I \cdot z_j^T / \tau\right)}, \\ & \mathcal{L}_{T \rightarrow I}=-\frac{1}{B} \sum_{i=1}^B \log \frac{\exp \left(z_i^T \cdot z_i^I / \tau\right)}{\sum_{j=1}^B \exp \left(z_i^T \cdot z_j^I / \tau\right)} . \end{aligned}\).
c) Image-Text-Label CL
-
SupCon + Image-text CL
(i.e., \(\mathcal{L}_{\text {infoNCE }}^{I T L}=\mathcal{L}_{I \rightarrow T}^{I T L}+\mathcal{L}_{T \rightarrow I}^{I T L}\) )
-
\(\begin{aligned} & \mathcal{L}_{I \rightarrow T}^{I T L}=-\sum_{i=1}^B \frac{1}{ \mid \mathcal{P}(i) \mid } \sum_{k \in \mathcal{P}(i)} \log \frac{\exp \left(z_i^I \cdot z_k^T / \tau\right)}{\sum_{j=1}^B \exp \left(z_i^I \cdot z_j^T / \tau\right)}, \\ & \mathcal{L}_{T \rightarrow I}^{I T L}=-\sum_{i=1}^B \frac{1}{ \mid \mathcal{P}(i) \mid } \sum_{k \in \mathcal{P}(i)} \log \frac{\exp \left(z_i^T \cdot z_k^I / \tau\right)}{\sum_{j=1}^B \exp \left(z_i^T \cdot z_j^I / \tau\right)}, \end{aligned}\).
- where \(k \in \mathcal{P}(i)=\left\{k \mid k \in B, y_k=y_i\right\}\)
P2) Generative Objectives
a) Masked Image Modeling
- \(\mathcal{L}_{M I M}=-\frac{1}{B} \sum_{i=1}^B \log f_\theta\left(\bar{x}_i^I \mid \hat{x}_i^I\right)\).
b) Masked Language Modeling
- \(\mathcal{L}_{M L M}=-\frac{1}{B} \sum_{i=1}^B \log f_o\left(\vec{x}_i^T \mid \hat{x}_i^T\right)\).
c) Masked Cross-Modal Modeling
- MCM = MIM + MLM
- \(\mathcal{L}_{M C M}=-\frac{1}{B} \sum_{i=1}^B\left[\log f_\theta\left(\bar{x}_i^I \mid \hat{x}_i^I, \hat{x}_i^T\right)+\log f_\phi\left(\bar{x}_i^T \mid \hat{x}_i^I, \hat{x}_i^T\right)\right]\).
- Details)
- Step 1) Given an “image-text pair”
- Step 2) Randomly masks
- a subset of “image” patches
- a subset of “text” tokens
- Step 3) Learns to reconstruct them conditioned on ..
- unmasked “image” patches
- unmasked “text” tokens
d) Image-to-Text Generation
- Aims to predict text \(x^T\) autoregressively
- based on the image paired with \(x^T\)
- \(\mathcal{L}_{I T G}=-\sum_{l=1}^L \log f_\theta\left(x^T \mid x_{<l,}^T z^I\right)\).
- \(L\) : # of tokens to be predicted
P3) Alignment Objectives
Align the image-text pair via ..
- (1) (Global) Image-text matching
- (2) (Local) Region-word matching
on the embedding space.
a) Image-Text Matching
- Models global correlation
- (between “images” and “texts”)
- \(\mathcal{L}_{I T}=p \log \mathcal{S}\left(z^I, z^T\right)+(1-p) \log \left(1-\mathcal{S}\left(z^I, z^T\right)\right)\).
- Score function \(\mathcal{S}(\cdot)\) : Measures the alignment probability between the image and text
- \(p=1\) if paired and 0 otherwise
b) Region-Word Matching
- Model local cross-modal correlation
- (between “image regions” and “words”)
- For dense visual recognition tasks
- e.g., Object detection
- \(\mathcal{L}_{R W}=p \log \mathcal{S}^r\left(r^I, w^T\right)+(1-p) \log \left(1-\mathcal{S}^r\left(r^I, w^T\right)\right)\).
- \(\left(r^I, w^T\right)\) : Region-word pair
- \(p=1\) if paired and 0 otherwise
(3) VLM Pretraining Frameworks
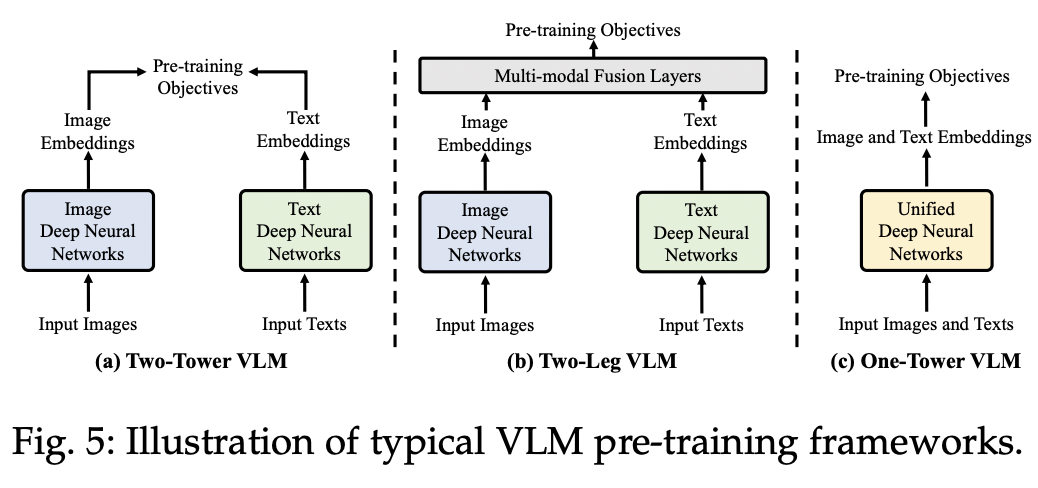
-
Two-tower framework
- Encoded with two separate encoders
-
Two-leg framework
- Introduces additional multi-modal fusion layers
-
One-tower VLMs
-
Unify vision and language learning in a single encoder
\(\rightarrow\) Aming to facilitate efficient communications across data modalities
-
(4) Evaluation Setups and Downstream Tasks
P1) Zero-shot Prediction
Common way of evaluating VLMs’ generalization capability
a) Image Classification
- What? Aims to classify Image
- How? By comparing the embeddings of images and texts
- where “prompt engineering” is often employed to generate task-related prompts like “a photo of a [label].”
b) Semantic Segmentation
- What? Assign a category label to each pixel in images
- How? By comparing the embeddings of the given image pixels and texts
c) Object Detection
- What? Localize and classify objects in images
- How? By comparing the embeddings of the given object proposals and texts
d) Image-Text Retrieval
- What? Retrieve the demanded samples from one modality given the cues from another modality
- Text-to-image retrieval & Image-to-text retrieval
P2) Linear Probing
pass
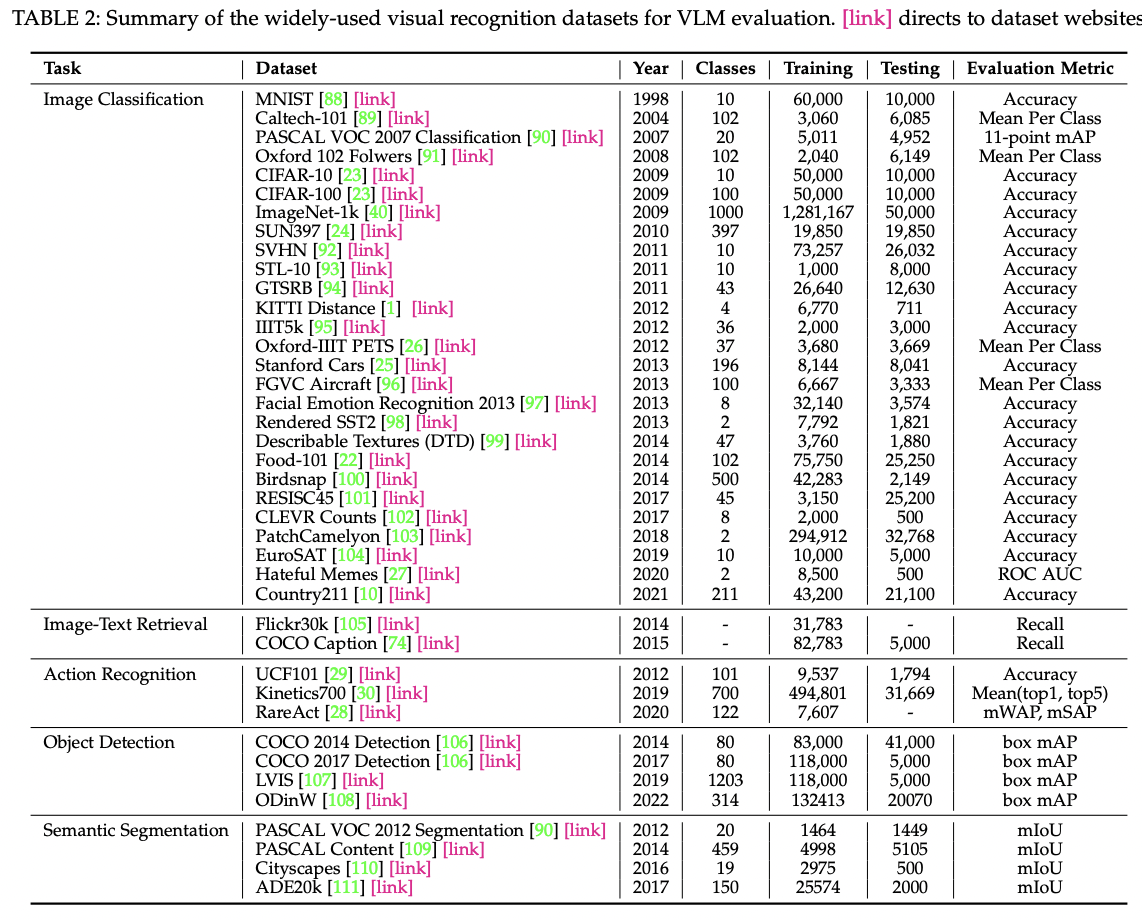
4. Datasets
(1) Pretraining
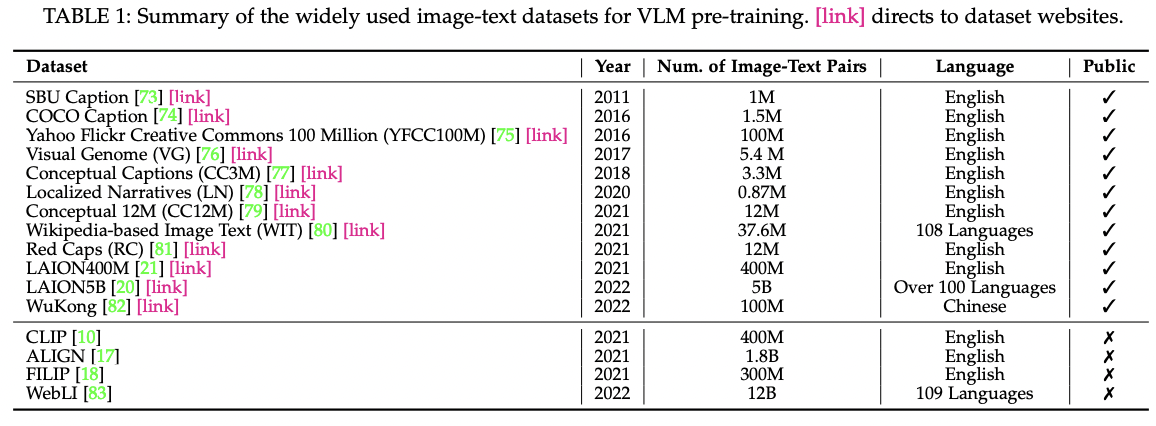
(2) Evaluation