
Vision-Language Models for Vision Tasks: A Survey
https://arxiv.org/pdf/2304.00685
Contents
- (5) VLM Pretraining
- Contrastive Objectives
- Generative Objectives
- Alignment Objectives
- Summary & Discussion
5. VLM Pretraining
- (1) Contrastive Objectives
- (2) Generative Objectives
- (3) Alignment Objectives

(1) Contrastive Objectives
- a) Image CL
- b) Image-Text CL
- c) Image-Text-Label CL
P1) Image CL
Pass
P2) Image-Text CL
-
Contrasting “(image-text) pairs”
-
CLIP (https://arxiv.org/pdf/2103.00020) (arxiv 2021)
-
Symmetrical image-text InfoNCE loss
-
Pre-trained VLMs: Allows zero-shot predictions
-
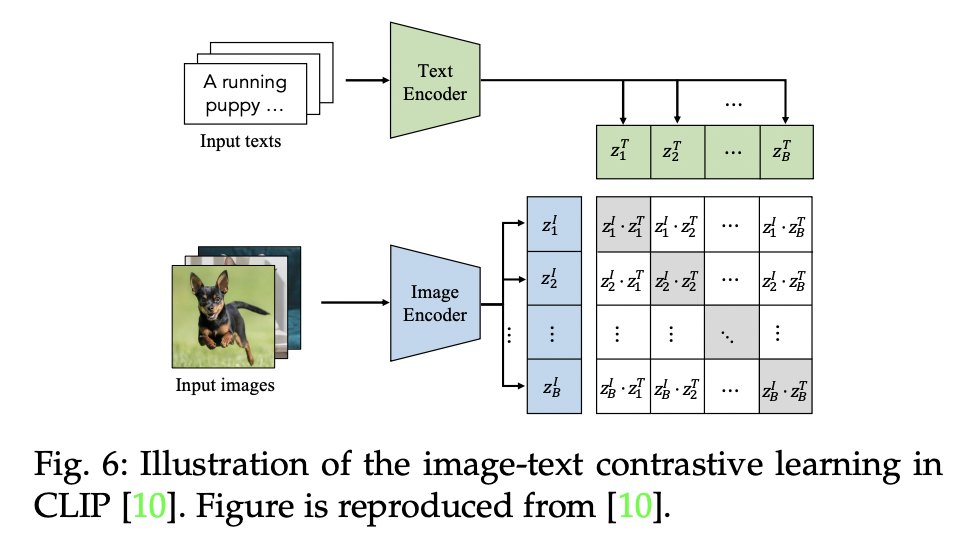
(Inspired by CLIP)
Many studies improve the symmetrical image-text infoNCE loss
- (1) Large-scale datasets
- (2) Small-scale datasets
- (3) Across various semantic levels
- (4) Augmenting image-text pairs
- (5) Unified vision & language encoder
(1) Large-scale datasets
- ALIGN (https://arxiv.org/pdf/2102.05918) (ICML 2021)
- Title: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
- Scales up the VLM pre-training with large-scale (i.e., 1.8 billions)
- Conceptual Captions dataset: noisy image-text pairs
- w/o expensive filtering or post-processing steps
(2) Small-scale datasets
-
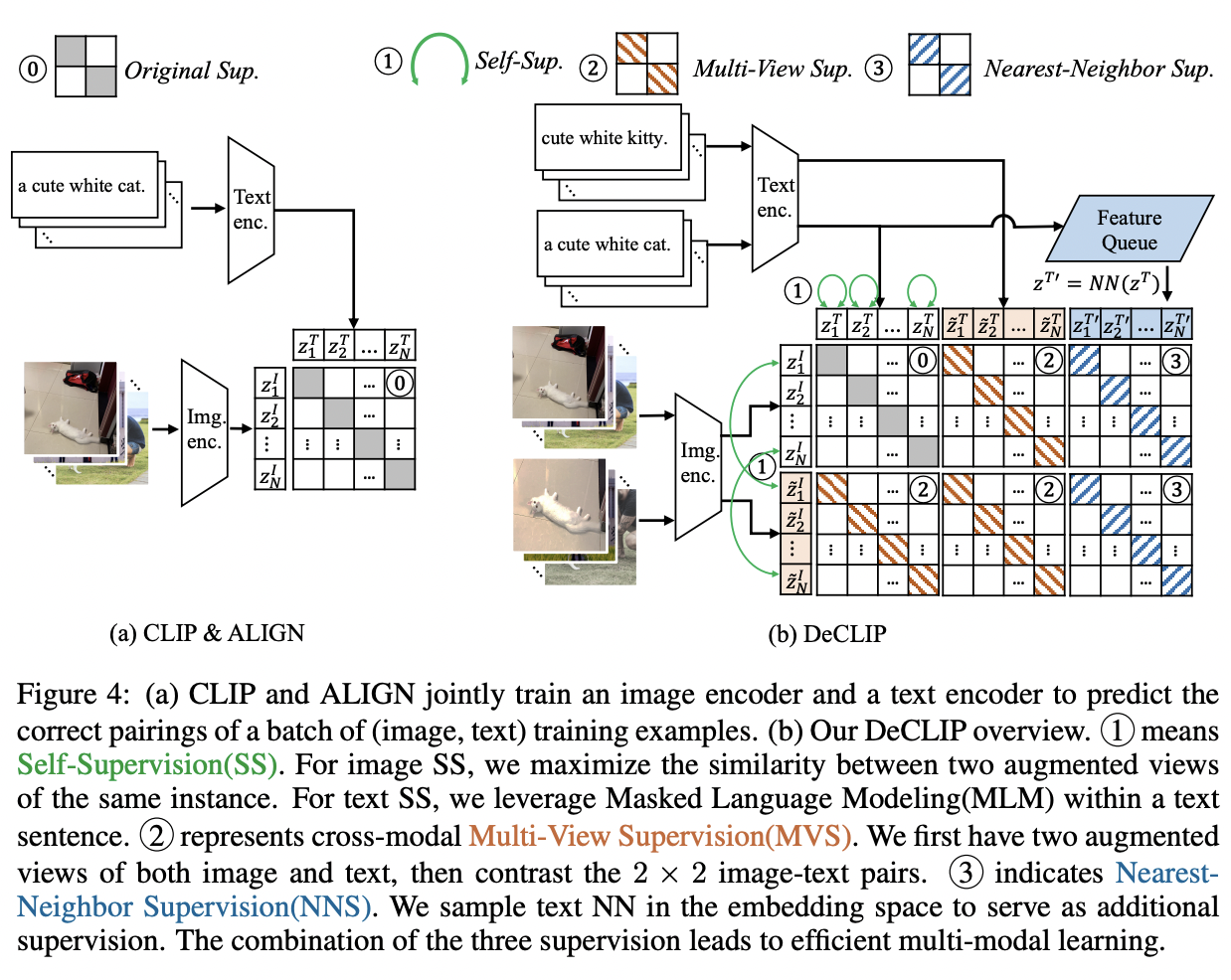
DeCLIP (https://arxiv.org/pdf/2110.05208) (ICLR 2022)
-
Title: Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
-
Limitation of CLIP = Data-hungry & requires 400M image-text pairs
\(\rightarrow\) DeCLIP (Data efficient CLIP) solves this issue!
-
Key Idea:
- Effective pre-training on limited data
- Utilize the supervision among the image-text pair
-
Instead of using the single image-text contrastive supervision…
- (1) Self-supervision within each modality
- (2) Multi-view supervision across modalities
- (3) Nearest-neighbor supervision from other similar pairs
-
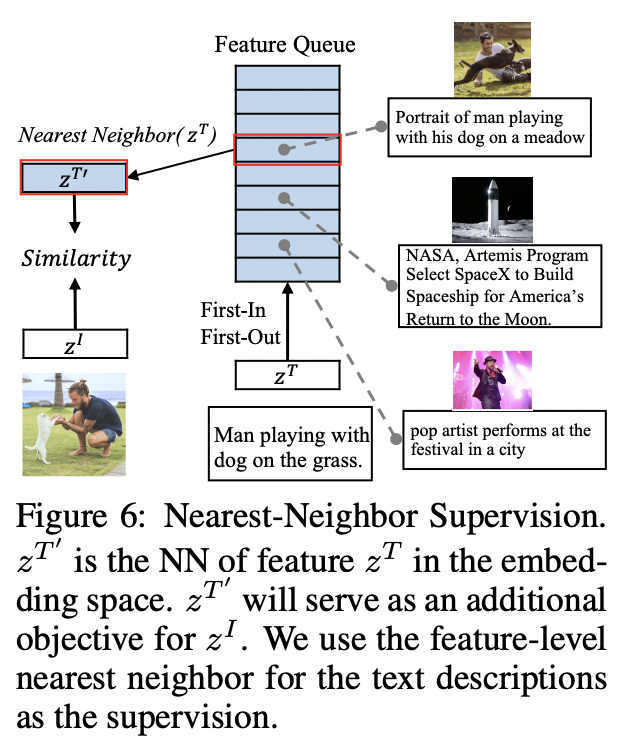
-
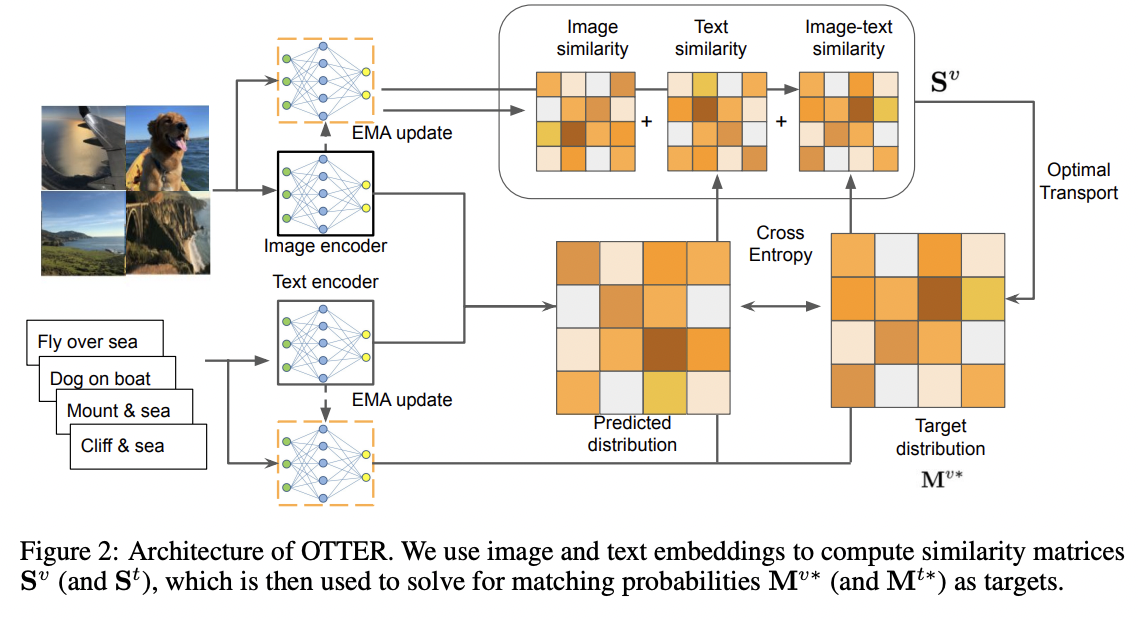
OTTER (https://arxiv.org/pdf/2112.09445) (ICLR 2022)
-
Title: Data Efficient Language-supervised Zero-shot Recognition with Optimal Transport Distillation
-
Limitation of CLIP = Data-hungry & requires 400M image-text pairs
\(\rightarrow\) Due to the fact that the image-text pairs are noisy!
-
Solution: OTTER (Optimal TransporT distillation for Efficient zero-shot Recognition)
-
How?
- Optimal transport to pseudo-pair images and texts
- Trained with only 3M
-
- ZeroVL (https://arxiv.org/pdf/2112.09331) (ECCV 2022)
- Title: Contrastive Vision-Language Pre-training with Limited Resources
- Limited data resource via debiased data sampling & data augmentation
(3) Across various semantic levels
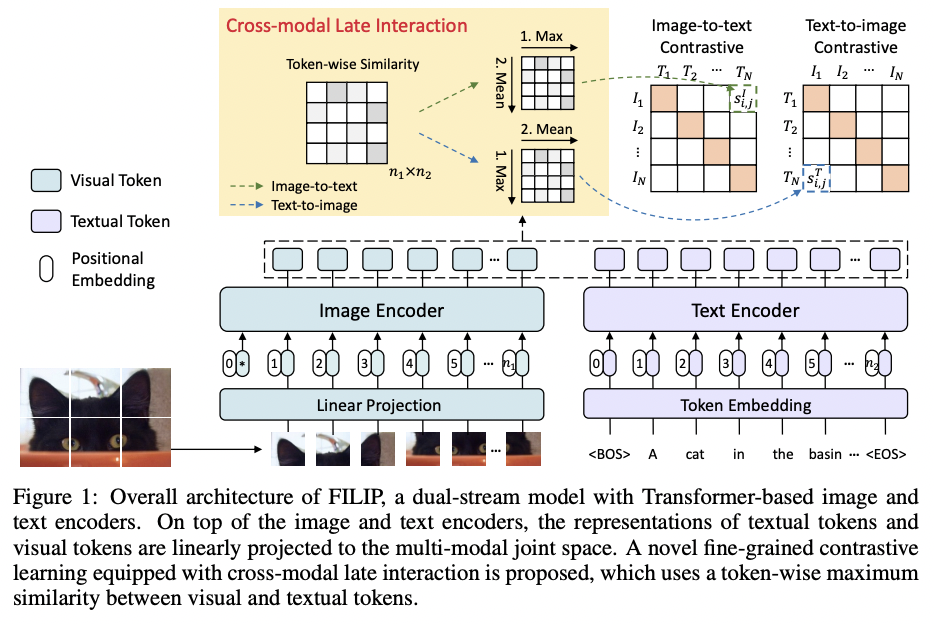
- FILIP (https://arxiv.org/pdf/2111.07783) (ICLR 2022)
- Title: FILIP: Fine-grained Interactive Language-Image Pre-Training
- (Local) Region-word alignment into CL \(\rightarrow\) Fine-grained!!
- Token-wise maximum similarity
-
Average token-wise maximum similarity
(\(n_1\): # of image tokens & \(n_2\): # of text tokens)
-
Similarity of the \(i\)-th image to the \(j\)-th text: \(s_{i, j}^I\left(\boldsymbol{x}_i^I, \boldsymbol{x}_j^T\right)\)
-
\(s_{i, j}^I\left(\boldsymbol{x}_i^I, \boldsymbol{x}_j^T\right)=\frac{1}{n_1} \sum_{k=1}^{n_1}\left[f_\theta\left(\boldsymbol{x}_i^I\right)\right]_k^{\top}\left[g_\phi\left(\boldsymbol{x}_j^T\right)\right]_{m_k^I}\).
where \(m_k^I=\arg \max _{0 \leq r<n_2}\left[f_\theta\left(\boldsymbol{x}_i^I\right)\right]_k^{\top}\left[g_\phi\left(\boldsymbol{x}_j^T\right)\right]_r\).
-
-
Similarity of the \(j\)-th text to the \(i\)-th image: \(s_{i, j}^T\left(\boldsymbol{x}_i^I, \boldsymbol{x}_j^T\right)\)
-
\(s_{i, j}^T\left(\boldsymbol{x}_i^I, \boldsymbol{x}_j^T\right)=\frac{1}{n_2} \sum_{k=1}^{n_2}\left[f_\theta\left(\boldsymbol{x}_i^I\right)\right]_{m_k^T}^{\top}\left[g_\phi\left(\boldsymbol{x}_j^T\right)\right]_k\).
where \(m_k^T=\arg \max _{0 \leq r<n_1}\left[f_\theta\left(\boldsymbol{x}_i^I\right)\right]_r^{\top}\left[g_\phi\left(\boldsymbol{x}_j^T\right)\right]_k\).
-
-
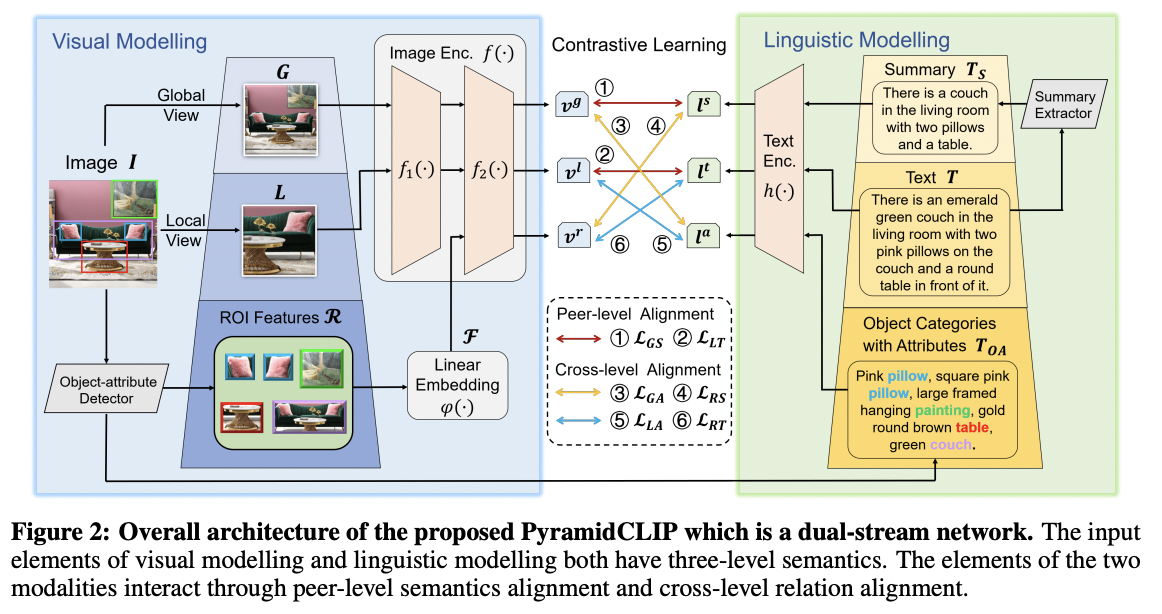
- PyramidCLIP (https://arxiv.org/pdf/2204.14095) (NeurIPS 2022)
- (Real world) Text description = suffer from the semantic mismatch and the mutual compatibility.
- Key point: Multiple semantic levels
- Solution: Performs both “cross-level” and “peer-level” CL
- Input pyramid with different semantic levels for each modality
- Aligns visual elements and linguistic elements via ..
- (1) Peer-level semantics alignment
- (2) Cross-level relation alignment.
(4) Augmenting image-text pairs
-
LaCLIP (https://arxiv.org/pdf/2305.20088) (NeurIPS 2023)
-
Title: Improving CLIP Training with Language Rewrites
-
LaCIP = Language augmented CLIP
-
Employ LLM to augment synthetic captions for given images
\(\rightarrow\) Rewritten texts = Exhibit diversity!
(while preserving the original key concepts)
- Generate \(M\) different rewrites!
- \(L_I=-\sum_{i=1}^N \log \frac{\exp \left(\operatorname{sim}\left(f_I\left(\operatorname{aug}_I\left(x_I^i\right)\right), f_T\left(\operatorname{aug}_T\left(x_T^i\right)\right)\right) / \tau\right)}{\sum_{k=1}^N \exp \left(\operatorname{sim}\left(f_I\left(\operatorname{aug}_I\left(x_I^i\right)\right), f_T\left(\operatorname{aug}_T\left(x_T^k\right)\right)\right) / \tau\right)}\).
- \(\operatorname{aug}_T\left(x_T\right) \sim \text { Uniform }\left(\left[x_{T 0}, x_{T 1} \ldots, x_{T M}\right]\right)\).
-

-
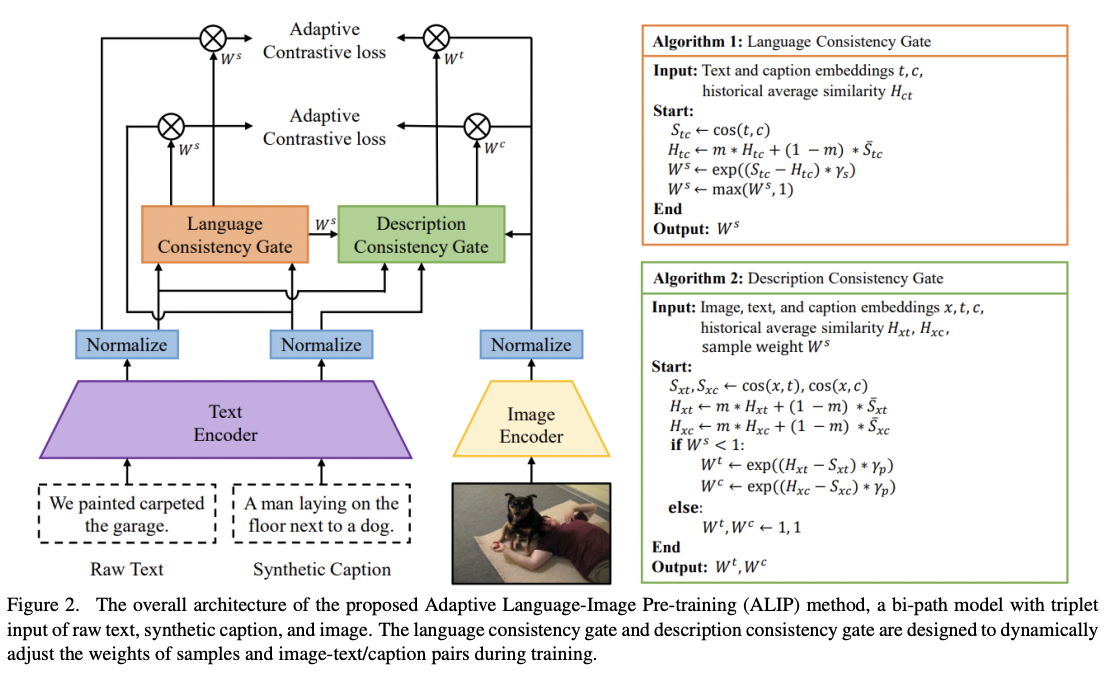
ALIP (https://arxiv.org/pdf/2308.08428) (ICCV 2023)
-
Title: ALIP: Adaptive Language-Image Pre-training with Synthetic Caption
-
ALIP = Adaptive Language-Image Pre-training
-
Limitation of previous works:
\(\rightarrow\) Intrinsic noise & unmatched image-text pairs
-
Solution
-
(1) Generate synthetic captions (feat. LLM)
-
(2) ALIP = Bi-path model that integrates supervision from both (1) raw text & (2) synthetic caption
- a) Language Consistency Gate (LCG)
-
b) Description Consistency Gate (DCG)
- Dynamically adjust the weights of samples and image-text/caption pairs
-
(3) Adaptive contrastive loss (\(L_{x t}\) and \(L_{x c}\))
-
To reduce the impact of noise data
-
\(L_{A L I P}= L_{x t}+L_{x c}\).
-
Between the image-text pair & image-caption pair
- \(L_{\mathrm{xt}}=-\sum_{i=1}^N W_i^s W_i^t\left[\log \frac{e^{x_i^{\top} t_i / \tau}}{\sum_j e^{x_i^{\top} t_j / \tau}}+\log \frac{e^{x_i^{\top} t_i / \tau}}{\sum_j e^{x_j^{\top} t_i / \tau}}\right]\).
- \(L_{\mathrm{xc}}=-\sum_{i=1}^N W_i^s W_i^c\left[\log \frac{e^{x_i^{\top} c_i / \tau}}{\sum_j e^{x_i^{\top} c_j / \tau}}+\log \frac{e^{x_i^{\top} c_i / \tau}}{\sum_j e^{x_j^{\top} c_i / \tau}}\right]\).
- \(W_i^s\) : calculated by the language consistency gate
- \(W_i^t\) and \(W_i^c\) : computed by the description consistency gate.
-
-
-
-

-
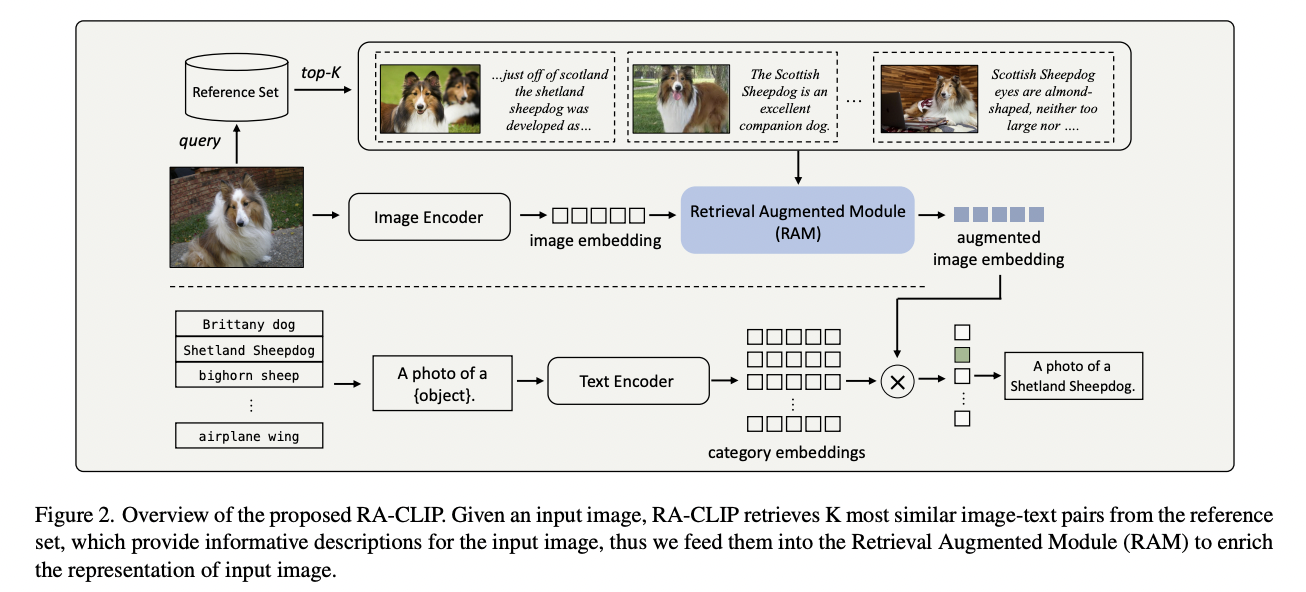
RA-CLIP (CVPR 2023)
-
Title: RA-CLIP: Retrieval Augmented Contrastive Language-Image Pre-training
-
Limitation of CLIP = data hungry
-
Proposal: RA-CLIP (Retrieval Augmented CLIP)
-
Key point: Retrieves relevant image-text pairs for image-text pair augmentation.
-
Novel and efficient framework to augment embeddings by online retrieval.
-
-
Procedure
-
Step 1) Sample part of (image-text) data as a “hold-out” reference set
-
Step 2) Given an input image, relevant pairs are retrieved (from the reference set)
\(\rightarrow\) Can be considered as an open-book exam, where reference set = cheat sheet
-
-
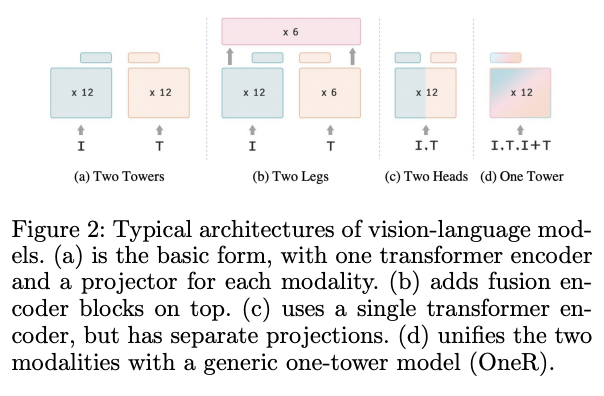
(5) Unified vision & language encoder
-
To facilitate efficient communications across data modalities
-
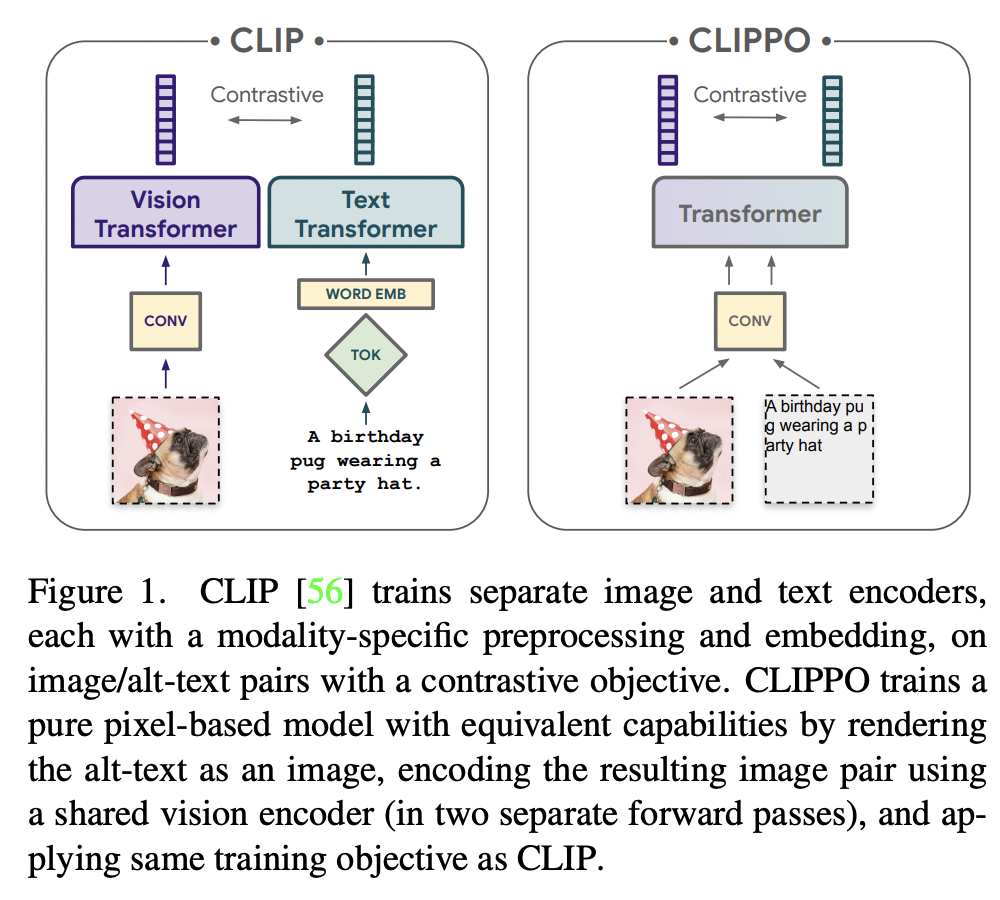
CLIPPO (https://arxiv.org/pdf/2212.08045) (CVPR 2023)
-
Title: CLIPPO: Image-and-Language Understanding from Pixels Only
-
Limitaiton of CLIP = Independent text and image towers
-
CLIP-Pixels Only (CLIPPO) = Unification
-
How?
-
Pure pixel-based model to perform image, text, and multimodal tasks
-
(Feat. Previous works) Image and text encoder can be can be realized with a single shared transformer model
\(\rightarrow\) All model parameters are shared for the two modalities.
-
-
Single encoder to processes both “image” and “text”
- image = regular images
- text = rendered on blank images
-
-
-
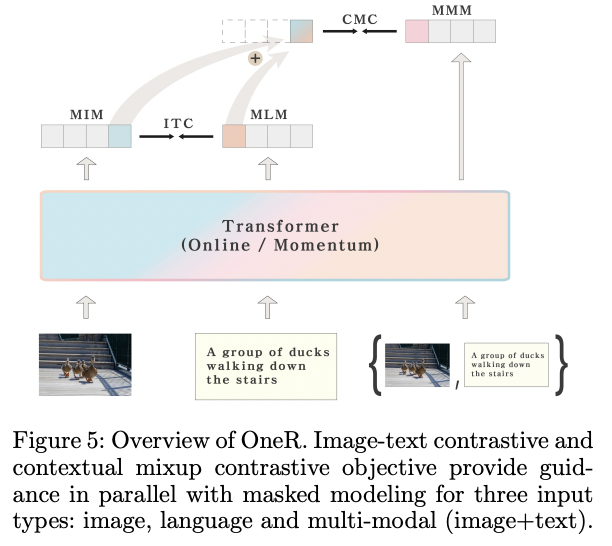
- OneR (https://arxiv.org/pdf/2211.11153) (AAAI 2023)
- Title: Unifying Vision-Language Representation Space with Single-tower Transformer
- Proposal: One-tower Model (OneR)
- Hypothesis: Image and its caption can be simply regarded as two different views of the underlying mutual information
- Notation
- Image text contrastive (ITC)
- Cross-modal mixup constrastive (XMC)
- Contextual Invariance Contrastive (CIC)
- Contextual Mixup Contrast (CMC)

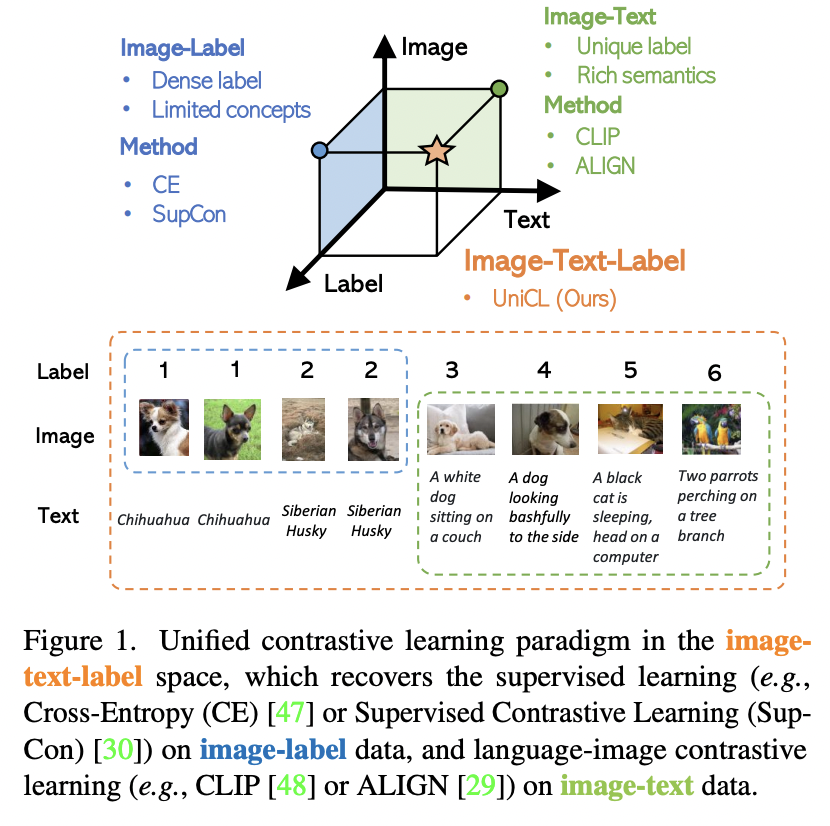
P3) Image-Text-Label Contrastive Learning
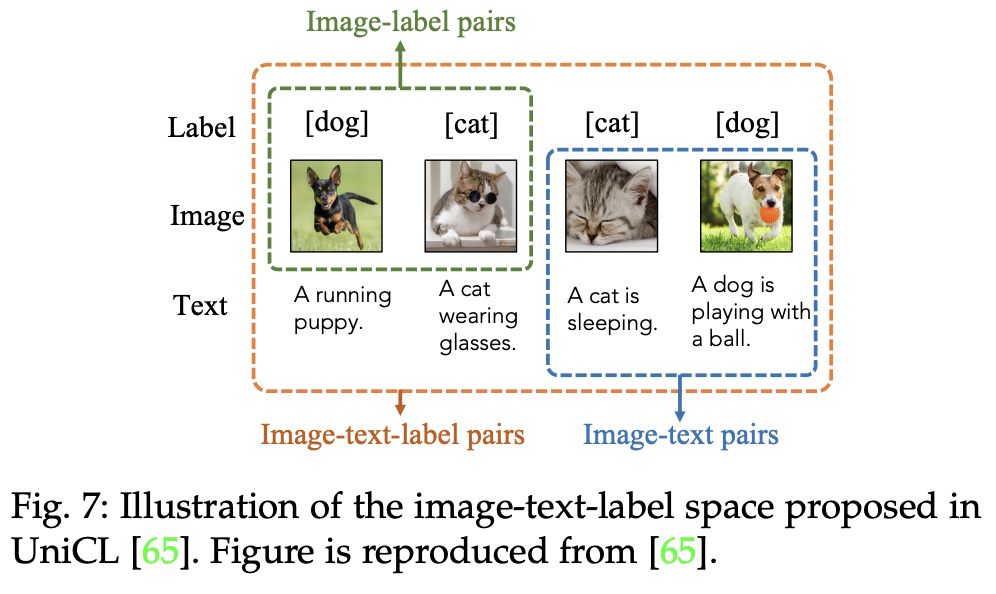
- Encodes “image”, “text” and (classification) “labels” into a shared space
- Employs both …
- (1) Supervised pre-training (with image labels)
- (2) Unsupervised VLM pretraining (with image-text pairs)
UniCL (https://arxiv.org/pdf/2204.03610) (CVPR 2022)
- Title: Unified Contrastive Learning in Image-Text-Label Space
- Proposal: Unified Contrastive Learning (UniCL)

P4) Discussion
Two limitations:
- (1) Joint optimizing positive and negative pairs is challenging
- (2) Involves a heuristic temperature hyper-parameter
(2) Generative Objectives
- a) Masked image modeling (MIM)
- b) Masked language modeling (MLM)
- c) Masked cross-modal modeling (MCM)
- d) Image-to-text generation
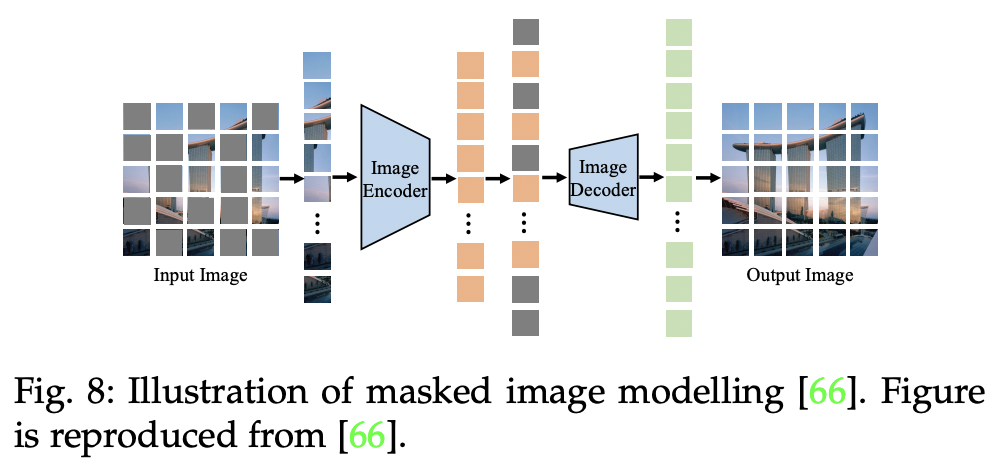
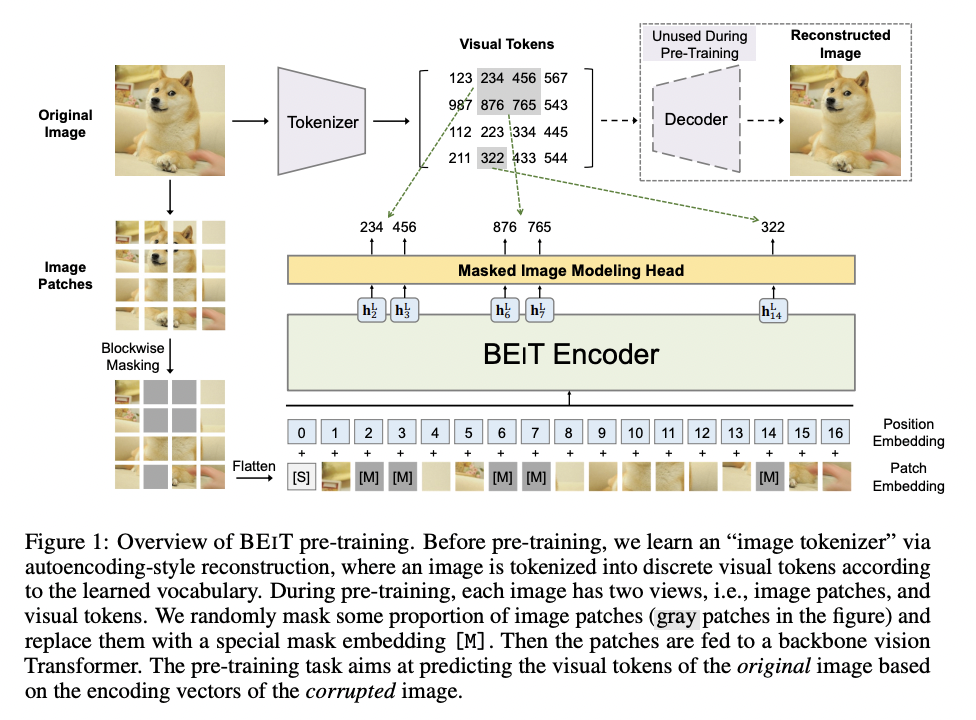
P1) Masked Image Modeling (MIM)
MAE [41] and BeiT [70]
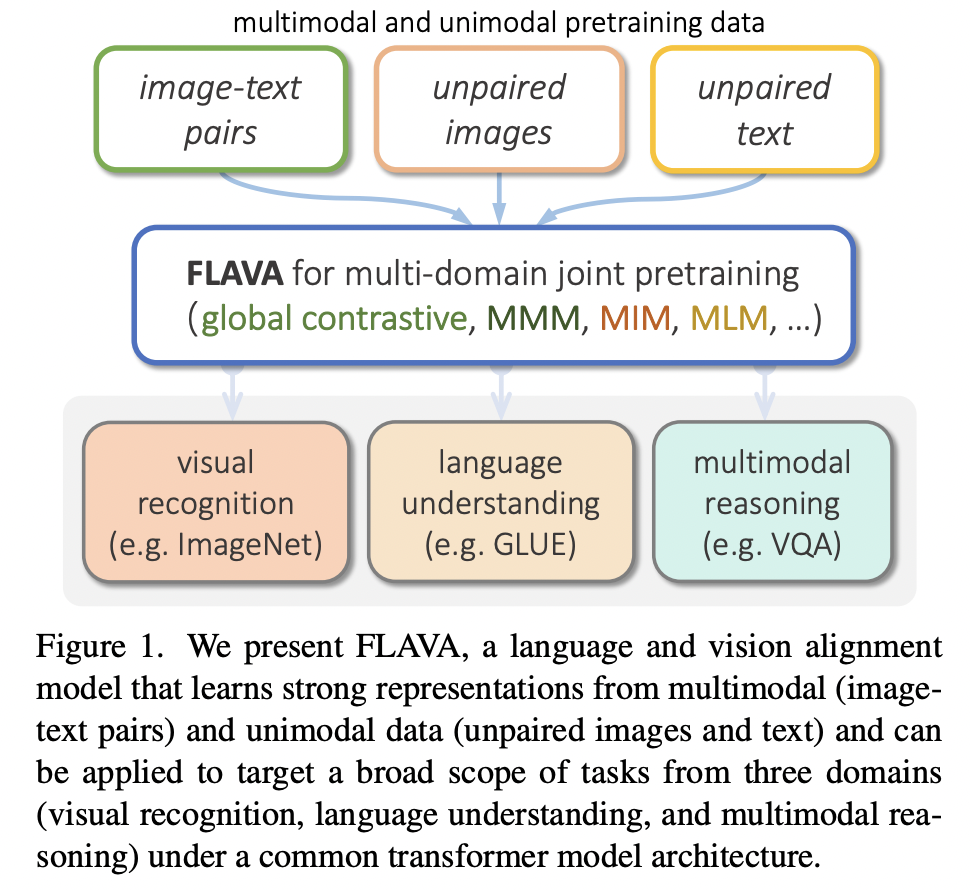
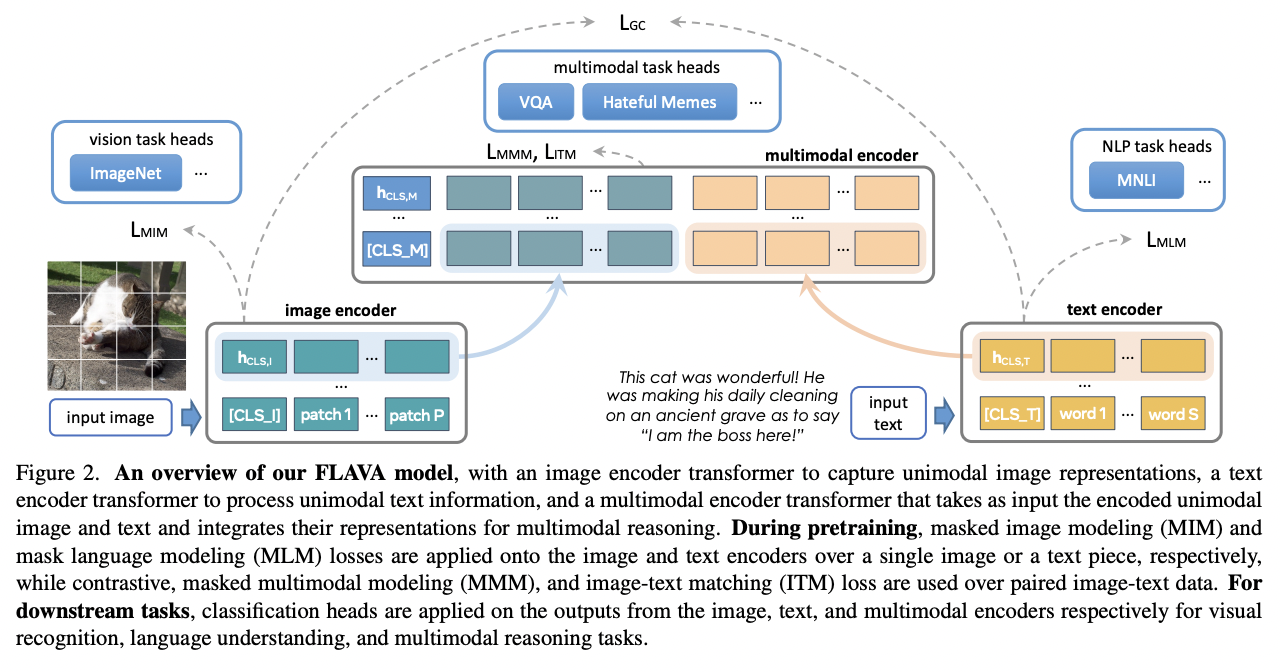
FLAVA (https://arxiv.org/pdf/2112.04482) (CVPR 2022)
-
Title: Flava: A foundational language and vision alignment model
-
Previous VLMs: Either cross-modal (contrastive) or multi-modal (with earlier fusion)
- FLAVA: Employs both!
- Universal model \(\rightarrow\) Targets all modalities at once
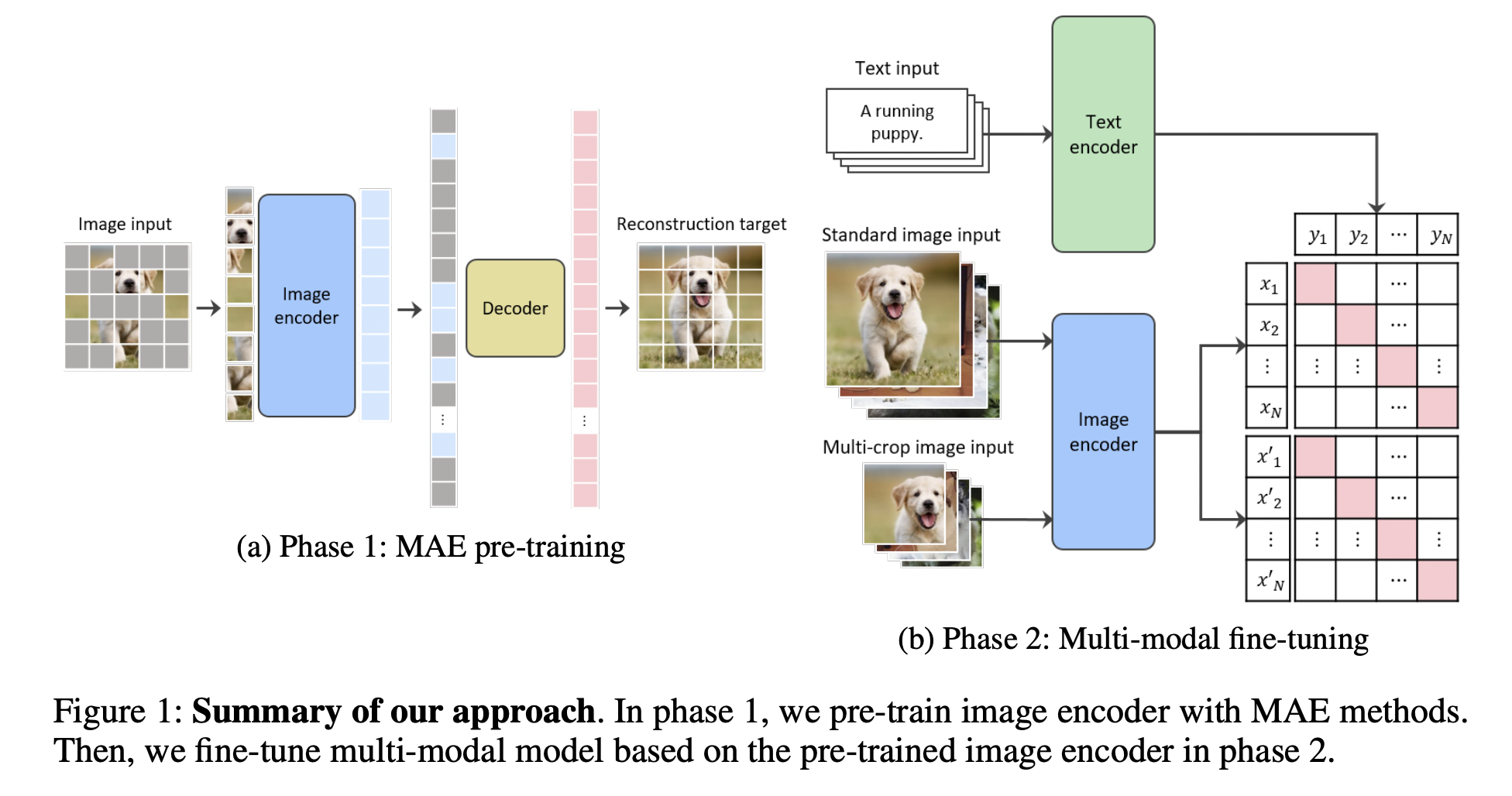
KELIP (https://arxiv.org/pdf/2203.14463) (arxiv 2022)
- Title: Large-scale Bilingual Language-Image Contrastive Learning
- Korean and English bilingual multimodal model
- 1.B image-text pairs (708 million Korean and 476 million English)
- MAE pre-training and multi-crop augmentation.
- MAE: Mask out a large portion of patches (i.e., 75 %)
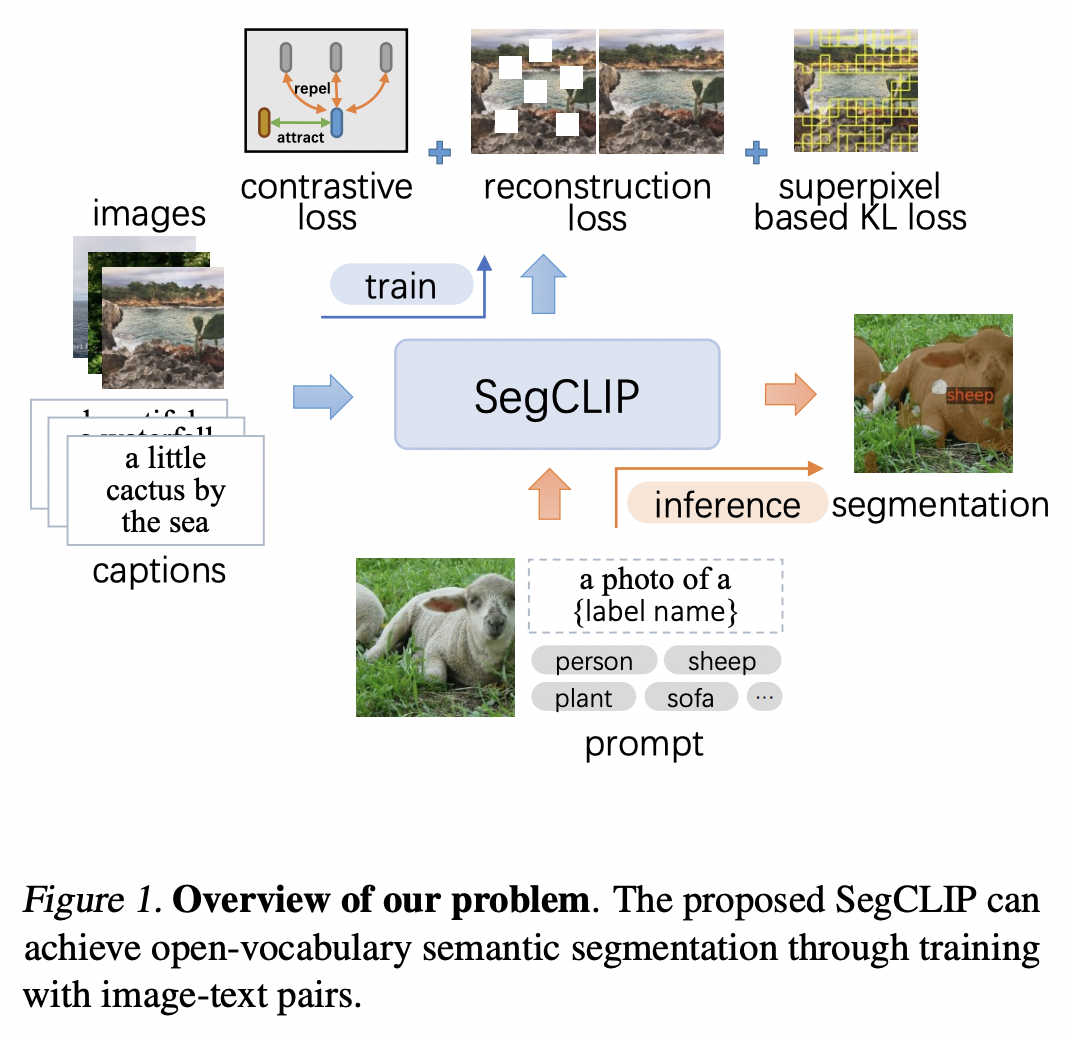
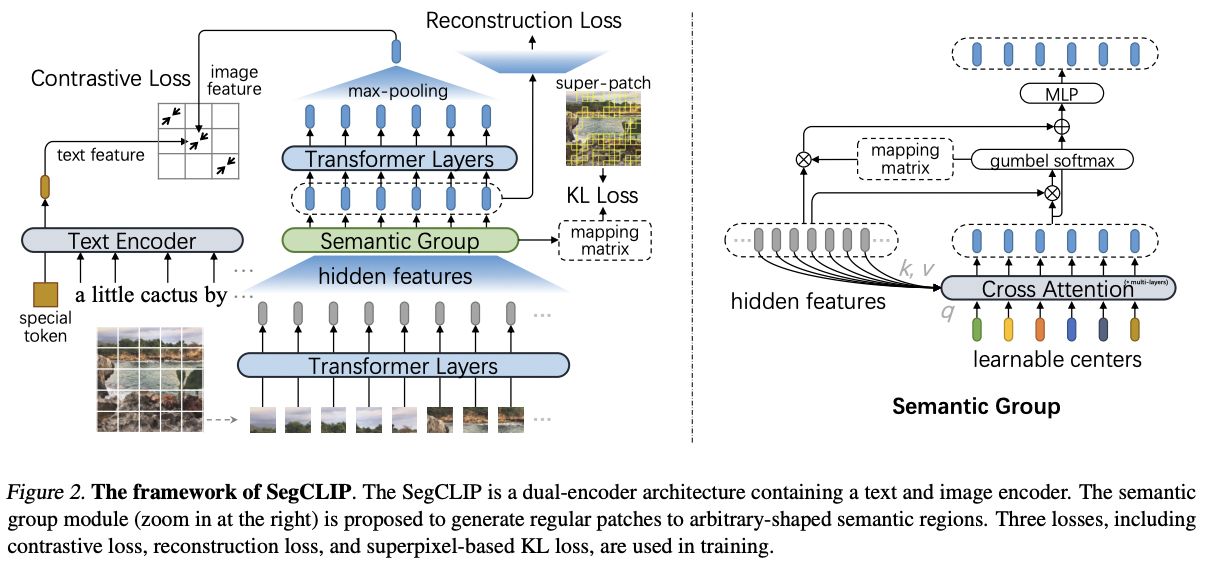
SegCLIP (https://arxiv.org/pdf/2211.14813) (ICML 2023)
- Title: SegCLIP: Patch Aggregation with Learnable Centers for Open-Vocabulary Semantic Segmentation
- Motivation: Tansferring the learned visual knowledge to open-vocabulary semantic segmentation is still under-explored.
- Proposal: SegCLIP = Segmentation + CLIP
- Segmentation based on ViT
- Gather patches with learnable centers to semantic regions through training on text-image pairs
P2) Masked Language Modeling (MLM)
FLAVA
- Masks out 15% text tokens
- Reconstructs them from the rest tokens for modeling cross-word correlation.
FIBER (https://arxiv.org/pdf/2206.07643) (NeurIPS 2022)
- Title: Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
- FIBER (Fusion-In-the-Backbone-based transformER)
- Architecture
- (Previous) Fusion after each unimodal backbones
- (FIBER) Pushes multimodal fusion deep into the model
- By inserting “cross-attention” into the image and text backbones
- Task
- (Previous) Pre-trained either on image-text data or on fine-grained data
- (FIBER) Two-stage pre-training strategy
- Step 1) Coarse-grained pre-training based on “image-text” data
- Step 2) Fine-grained pre-training based on “image-text-box” data
- Architecture
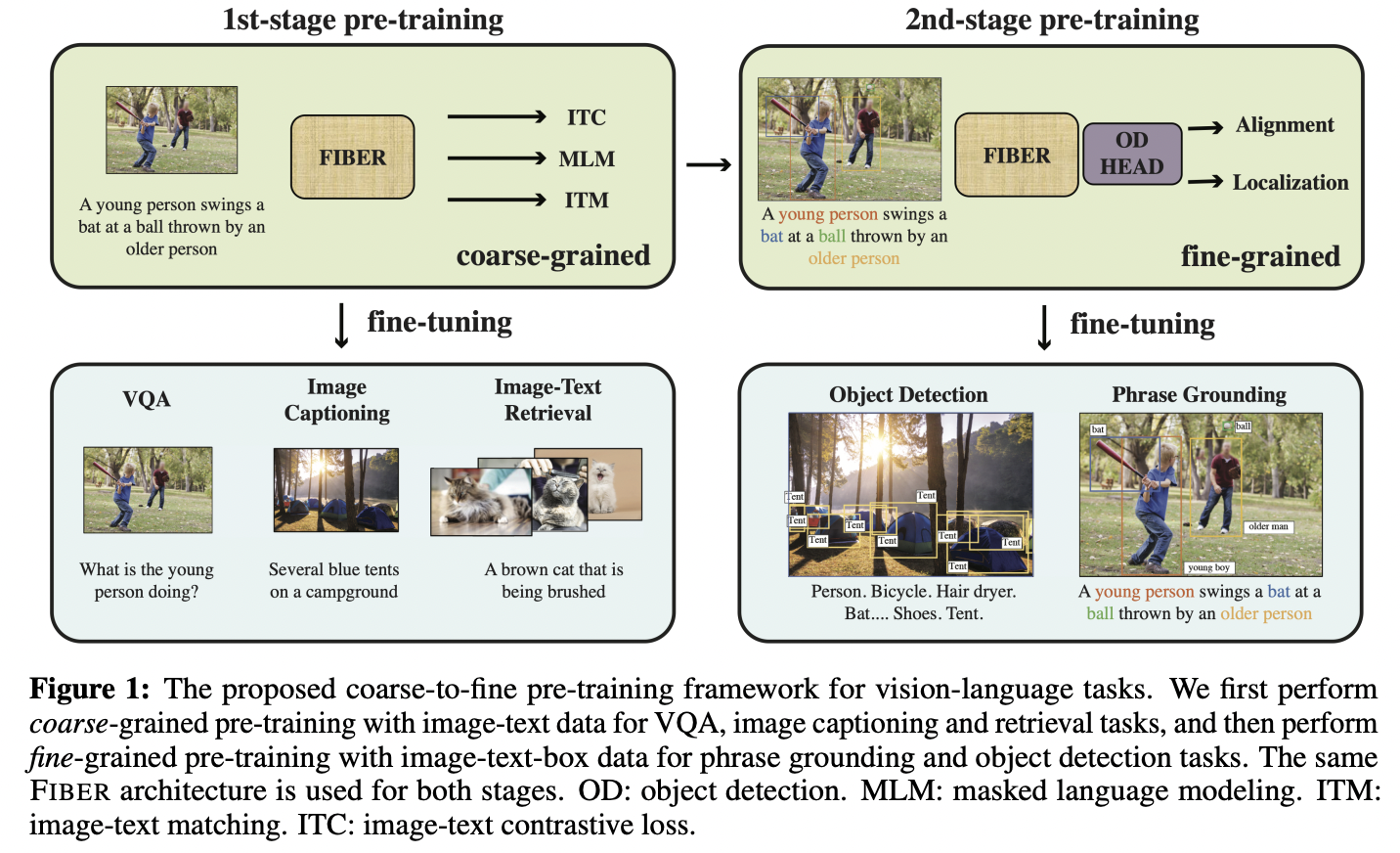
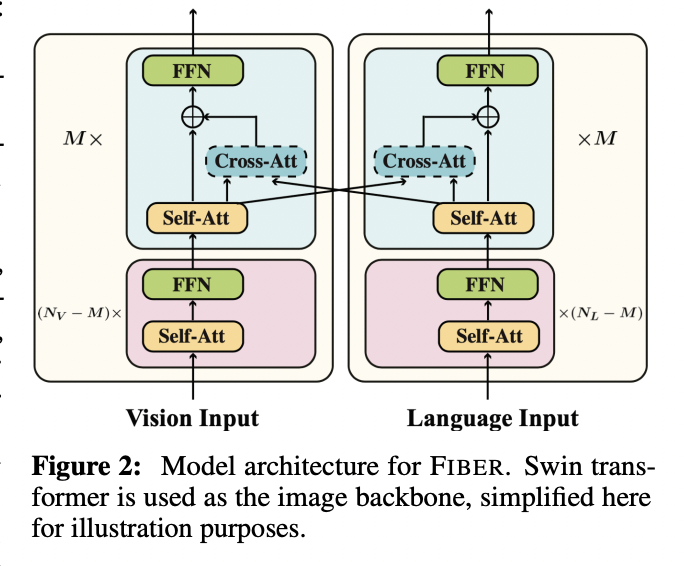
P3) Masked Cross-Modal Modeling (MCM)
Masks and reconstructs both (1) image patches and (2) text tokens
FLAVA [42]
- Masks ∼40% image patches
- Masks 15% text tokens
P4) Image-to-Text Generation
Procedure
- Step 1) Encodes an input image into embeddings
- Step 2) Decodes them into texts
COCA (https://arxiv.org/pdf/2205.01917) (arxiv 2022)
- Title: CoCa: Contrastive Captioners are Image-Text Foundation Models
- Contrastive Captioner (CoCa)
- Architecture: Minimalist design
- Image-text encoder-decoder foundation model
- Loss: Joint loss ( Contrastive loss + Captioning loss )
- Contrastive approaches: CLIP
- Generative methods: SimVLM
- Architecture: Minimalist design
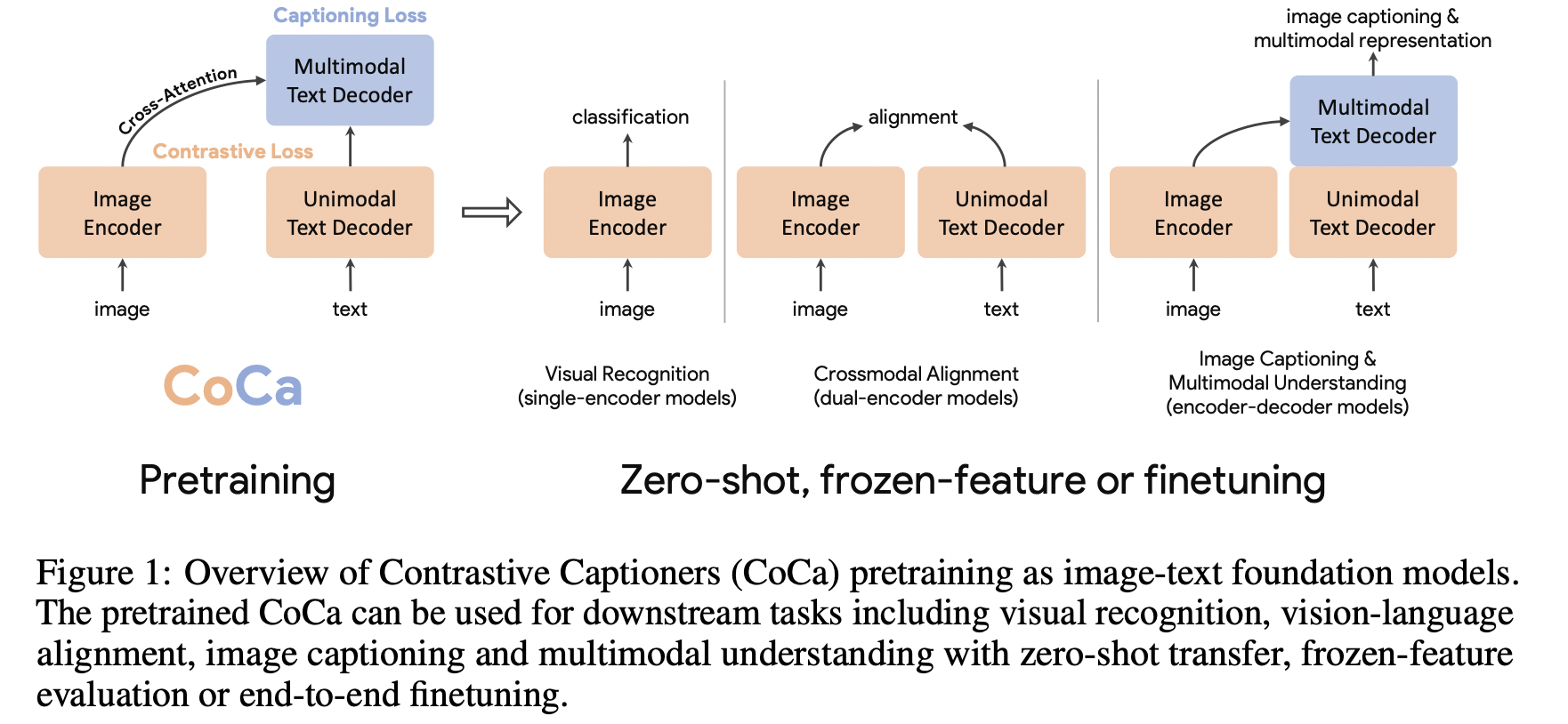
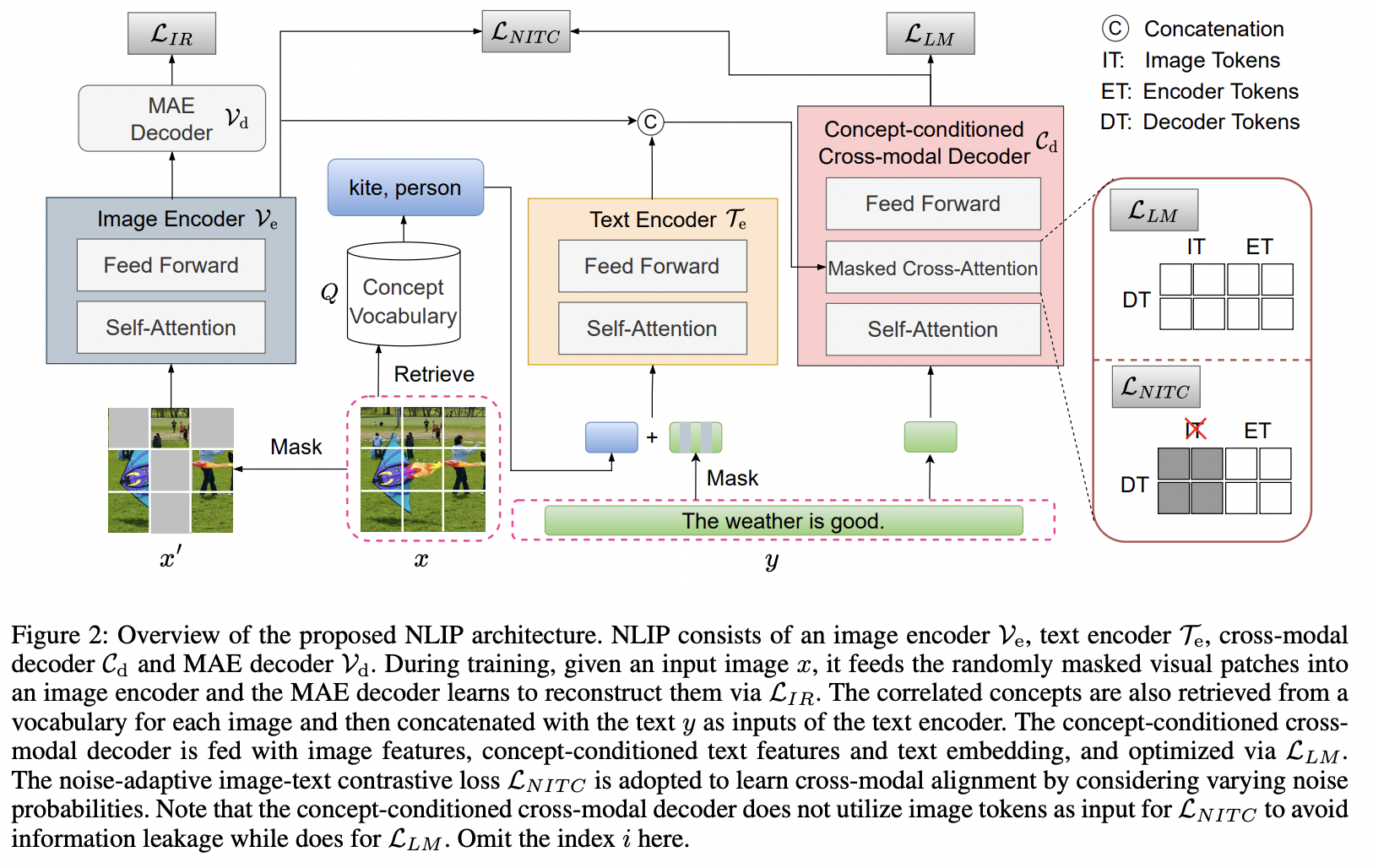
NLIP (https://arxiv.org/pdf/2212.07086) (AAAI 2023)
-
Title: NLIP: Noise-robust Language-Image Pre-training
-
Motivation: Existing works either ..
- design manual rules to clean data
- generate pseudo-targets as auxiliary signals
for reducing noise impact
-
Proposal: Noise robust Language-Image Pre-training framework (NLIP)
- To automatically mitigate the impact of noise by solely mining over existing data
-
Stabilize pre-training via two schemes:
- (1) Noise-harmonization
- Estimates the noise probability of each pair
- Adopts **noise-adaptive regularization **
- (2) Noise-completion
- Injects a concept-conditioned crossmodal decoder to obtain semantic-consistent synthetic captions to complete noisy ones
- (1) Noise-harmonization
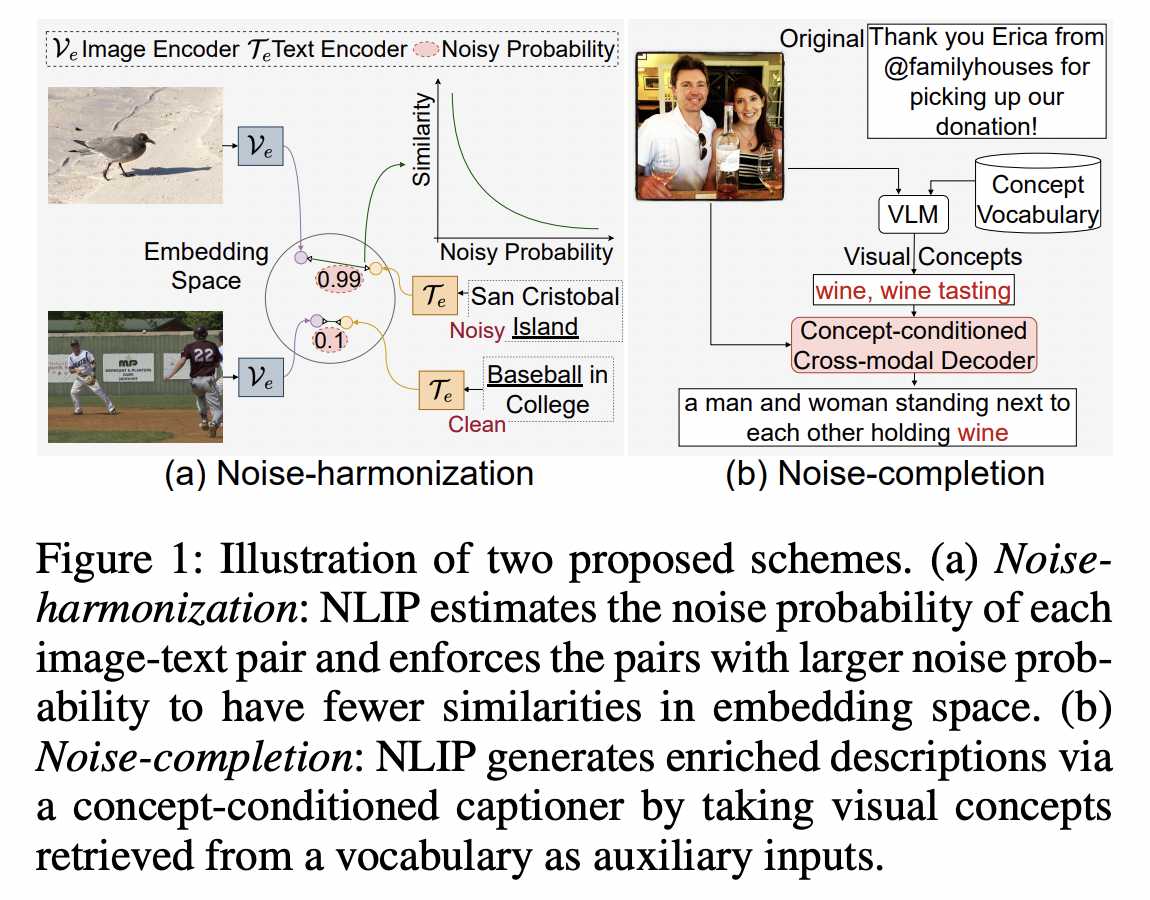
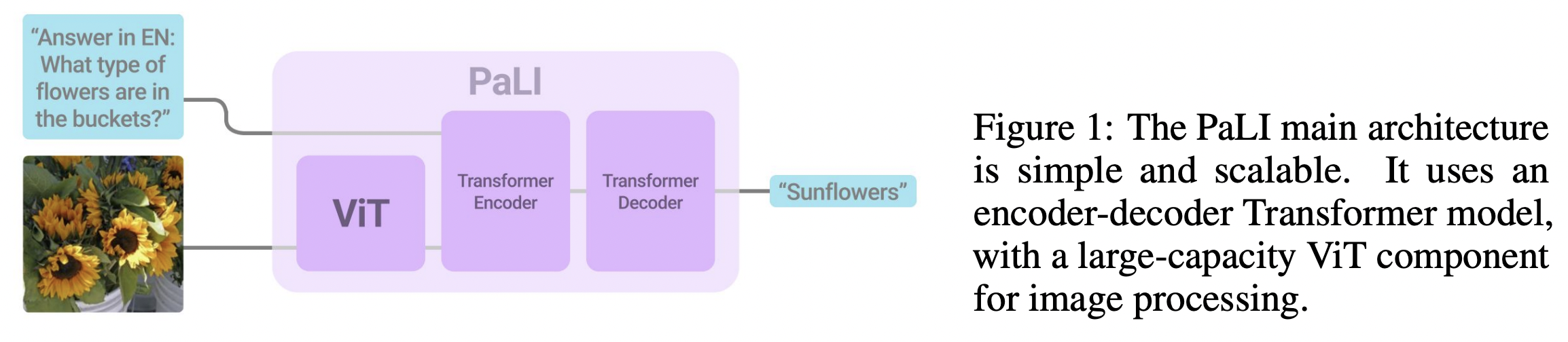
PaLI (https://arxiv.org/pdf/2209.06794) (ICLR 2023)
- Title: PaLI: A Jointly-Scaled Multilingual Language-Image Model
- PaLI (Pathways Language and Image model)
- Joint modeling of language and vision
- Generates text based on visual and textual inputs
P5) Discussion
Generally adopted as additional objectives above other VLM pre-training objectives for learning rich context information
(3) Alignment Objectives
Enforce VLMs to align paired images and texts by learning to predict whether the given text describes the given image correctly
- a) (Global) image-text matching
- b) (Local) region-word matching
P1) (Global) Image-Text Matching
Goal: Directly aligning paired images and texts
Examples
- FLAVA: Matches the given image with its paired text via a classifier (feat. BCE loss)
- FIBER: Mine hard negatives with pair-wise similarities
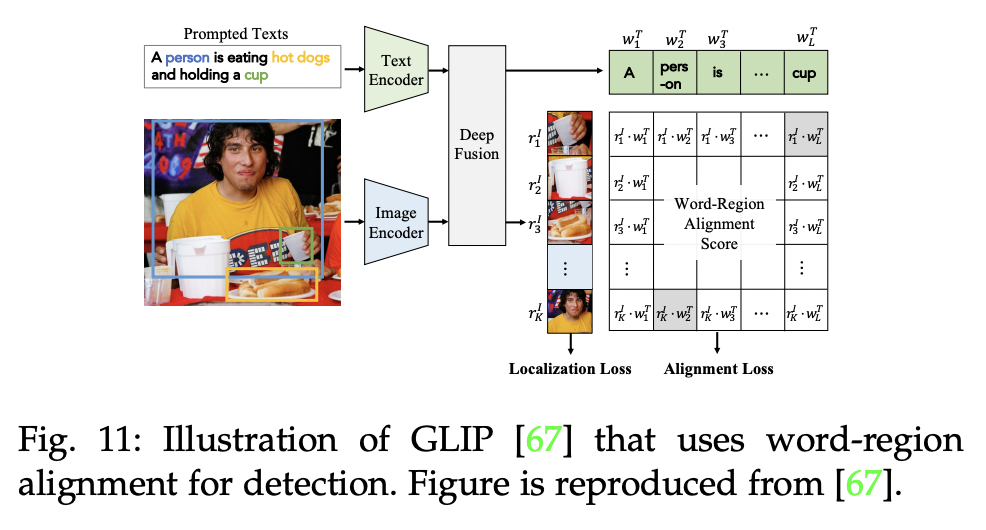
P2) Region-Word Matching
Goal: Models local fine-grained vision-language correlation
How? By aligning paired image “regions” and word “tokens”
\(\rightarrow\) Benefit zero-shot dense predictions
- e.g., Object detection, Semantic segmentation.
Examples
- E.g., GLIP, FIBER, DetCLIP:
- Replace “object classification” logits by “region-word alignment” scores
- i.e., Similarity between “regional” visual features and “token-wise” features
P3) Discussion
Alignment objectives
\(\rightarrow\) Learn to predict weather the given image and text data are “matched”
Pros & Cons
- Pros
- Simple and easy-to-optimize
- Can be easily extended to model “fine-grained” vision-language correlation
-
Cons
-
Often learn little correlation information within vision or language modality
\(\rightarrow\) \(\therefore\) Often adopted as auxiliary losses to other VLM pre-training objectives
-
(4) Summary & Discussion
Pretraining with
- (1) Contrastive Objectives
- 1-1) Image CL
- 1-2) Image-Text CL
- 1-3) Image-Text-Label CL
- (2) Generative Objectives
- 2-1) MIM
- 2-2) MLM
- 2-3) MCMM
- 2-4) Image-to-Text Generation
- (3) Alignment Objectives
- 3-1) Image-Text Matching
- 3-2) Region-Word Matching