
Vision-Language Models for Vision Tasks: A Survey
https://arxiv.org/pdf/2304.00685
Contents
- (6) VLM Transfer Learning
- Motivation of Transfer Learning
- Common Setup of Transfer Learning
- Common Transfer Learning Methods
- Text PT
- Visual PT
- Text-Visual PT
- Summary & Discussion
6. VLM Transfer Learning
(Beyond zero-shot prediction) Transfer learning has also been studied!
\(\rightarrow\) Adapts VLMs to fit downstream tasks via…
- (1) Prompt tuning
- (2) Feature adapter
Sections
- (1) Motivation of TL for pre-trained VLMs
- (2) Common TL setup
- (3) Three TL approaches
- 3-1) Prompt tuning methods
- 3-2) Feature adapter methods
- 3-3) Etc.
(1) Motivation of Transfer Learning
Two types of gaps while applied to various downstream tasks:
- (1) Gaps in “image and text distributions”
- (2) Gaps in “training objectives”
(1) Gaps in “image and text distributions”
- Downstream dataset may have “task-specific image styles and text formats”
(2) Gaps in “training objectives”
- VLMs are generally ….
- [Pretrain] Pretrained with “task-agnostic objectives”
- e.g., Learn general concepts
- [Finetune] Downstream tasks often involve “task-specific objectives”
- e.g., Coarse or fine-grained classification, region or pixel-level recognition, etc…
- [Pretrain] Pretrained with “task-agnostic objectives”
(2) Common Setup of Transfer Learning
Three TL setups (to mitigate the domain gaps)
- (1) Supervised TL
- (2) Few-shot supervised TL
- (3) Unsupervised TL
(3) Common Transfer Learning Methods
- (1) Prompt tuning approaches
- (2) Feature adapter approaches
- (3) Etc..
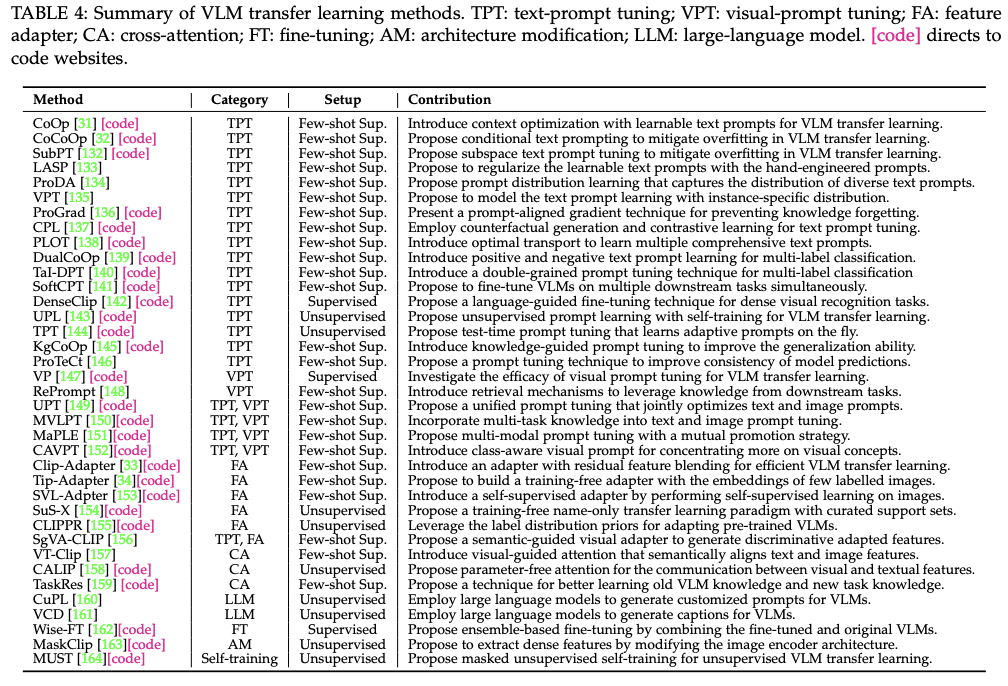
P1) via Prompt Tuning (PT)
(Previous works)
- Prompt engineering: “Manually” designs text prompts for each task
By finding optimal prompts, without fine-tuning the entire VLM
- a) Text PT
- b) Visual PT
- c) Text-visual PT
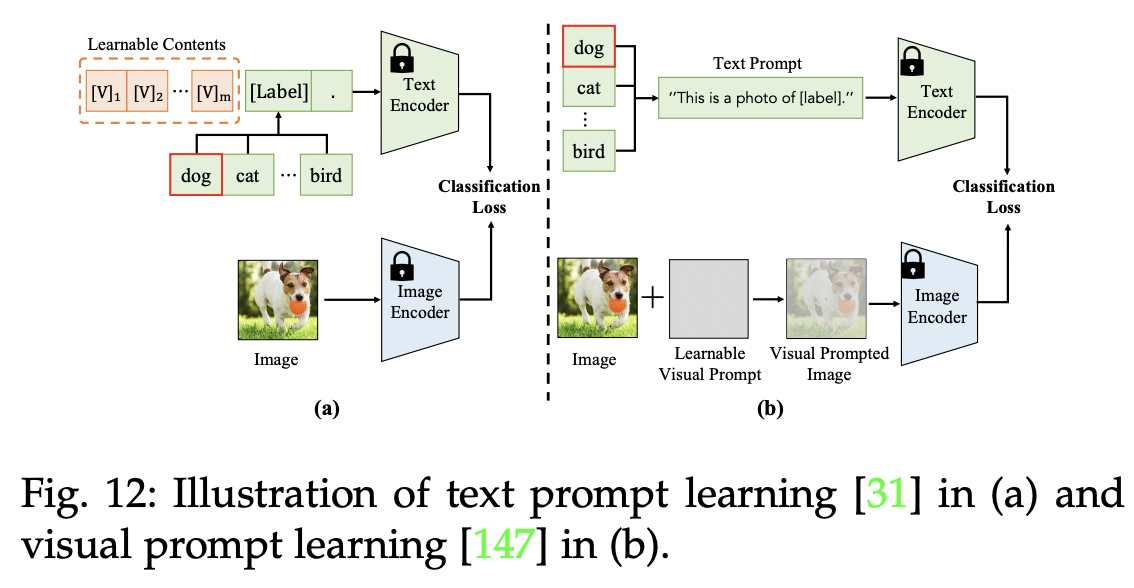
P1-1) Text PT
Goal: Explores more effective “learnable” text prompts
- With several labelled samples
Example)
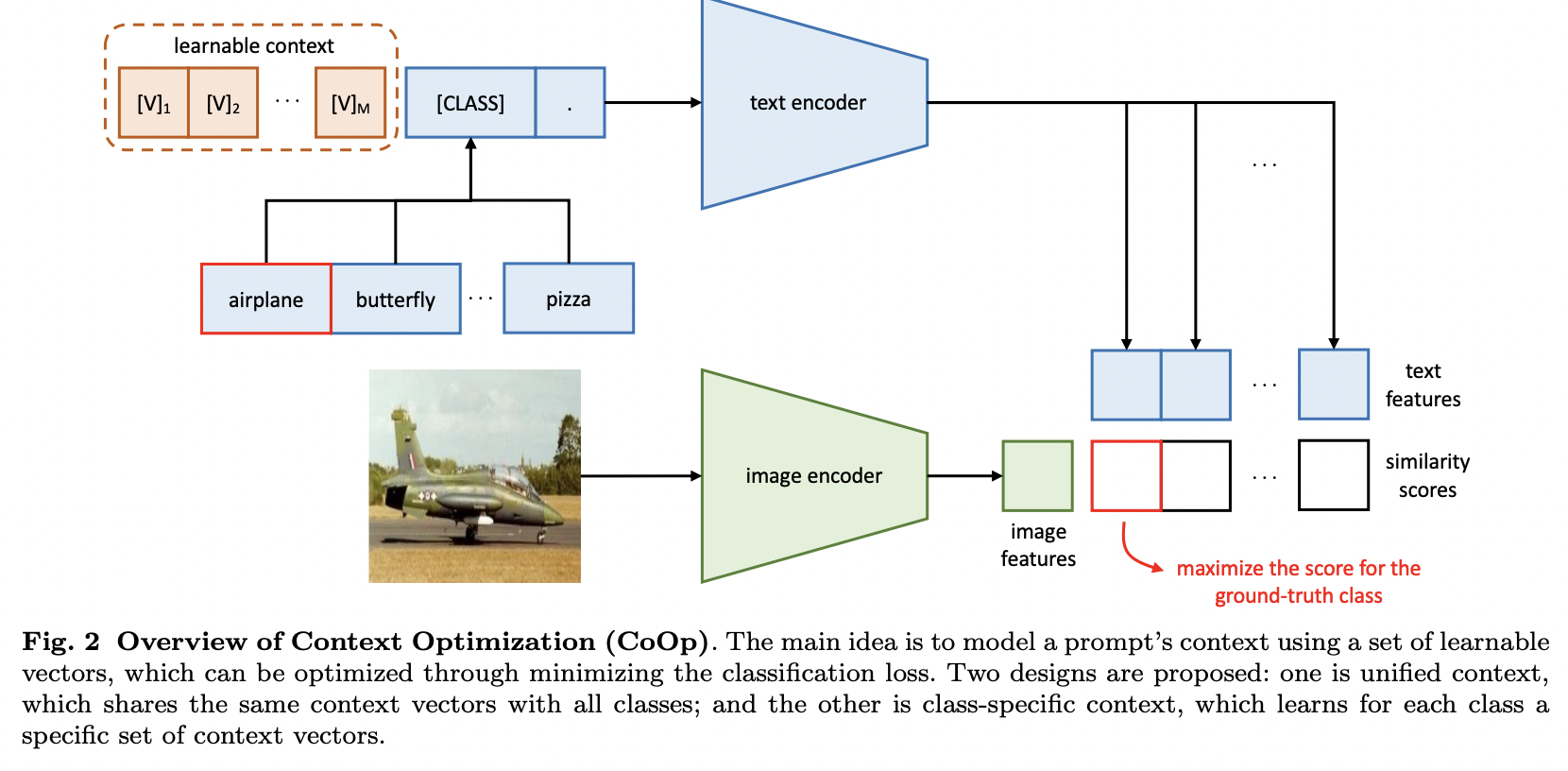
- CoOp (https://arxiv.org/pdf/2109.01134) (IJCV 2022)
- Title: Learning to Prompt for Vision-Language Models
- Proposal: Context Optimization (CoOp)
- Key point: Expands a category word [label] into a sentence ‘[V]1, [V]2, …, [V]m [label]’
- [V] = Learnable word vectors

-
CoCoOp (https://arxiv.org/pdf/2203.05557) (CVPR 2022)
-
Title: Conditional Prompt Learning for Vision-Language Models
-
Motivaiton: To mitigate the overfitting of CoOP
-
Proposal: Conditional Context Optimization (CoCoOp)
-
Conditional context optimization
\(\rightarrow\) Generates a specific prompt “for each image”
-

- SubPT (https://arxiv.org/pdf/2211.02219) (arxiv 2023)
- Title: Understanding and Mitigating Overfitting in Prompt Tuning for Vision-Language Models
- SubPT = Subspace Prompt Tuning
-
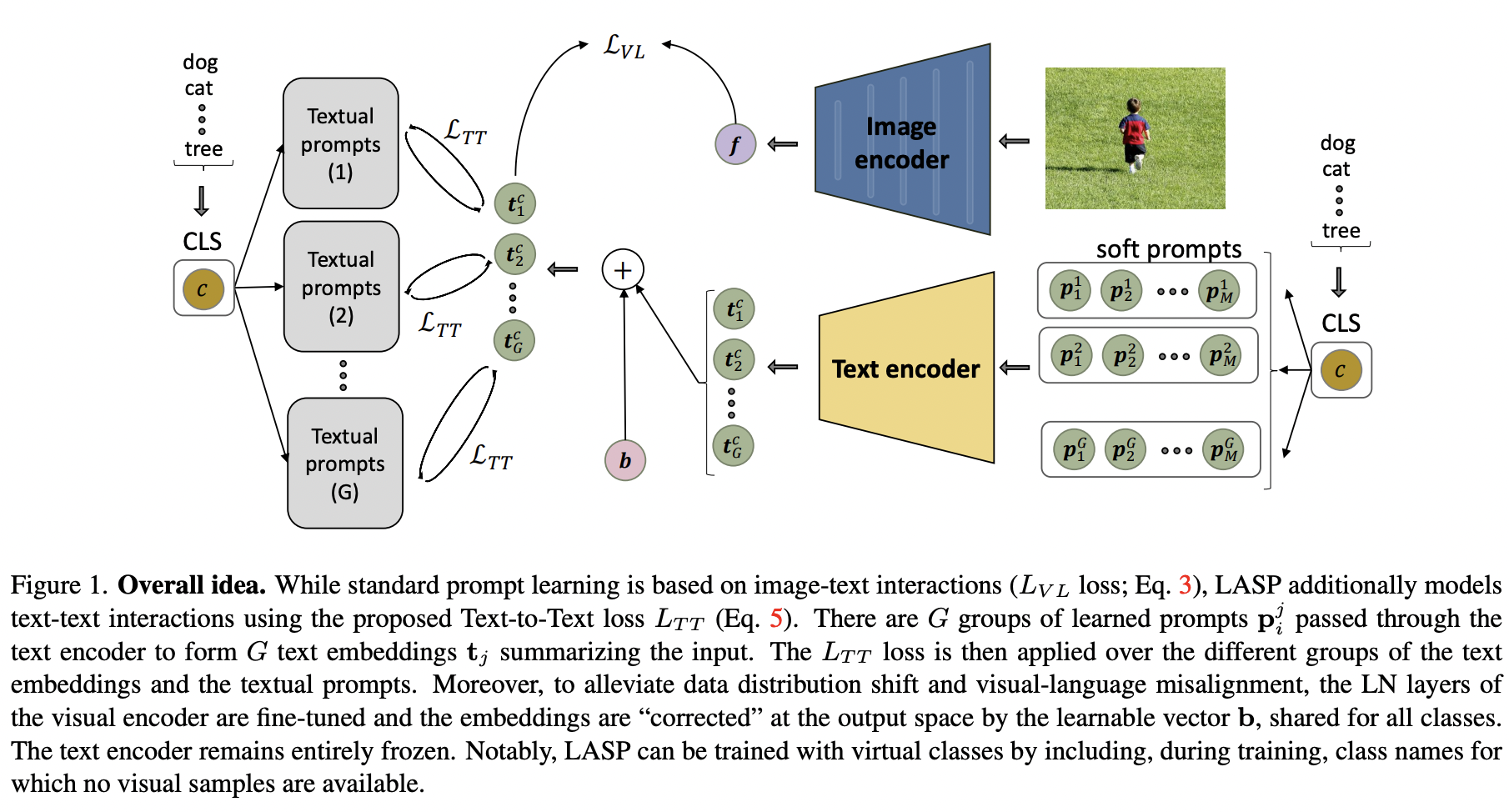
LASP (https://arxiv.org/pdf/2210.01115) (CVPR 2023)
-
Title: LASP: Text-to-Text Optimization for Language-Aware Soft Prompting of Vision & Language Models
-
Recent trend: Soft prompt learning
\(\rightarrow\) Nonetheless, recent method overfit to the training data!
-
Proposal: LASP = Language-Aware Soft PT
- Key point: Regularizes learnable prompts with hand-engineered prompts
- (Text-to-text) Cross-entropy loss ( (a) vs. (b) )
- (a) Learned prompts
- (b) Hand-crafted textual prompts
-

-
-
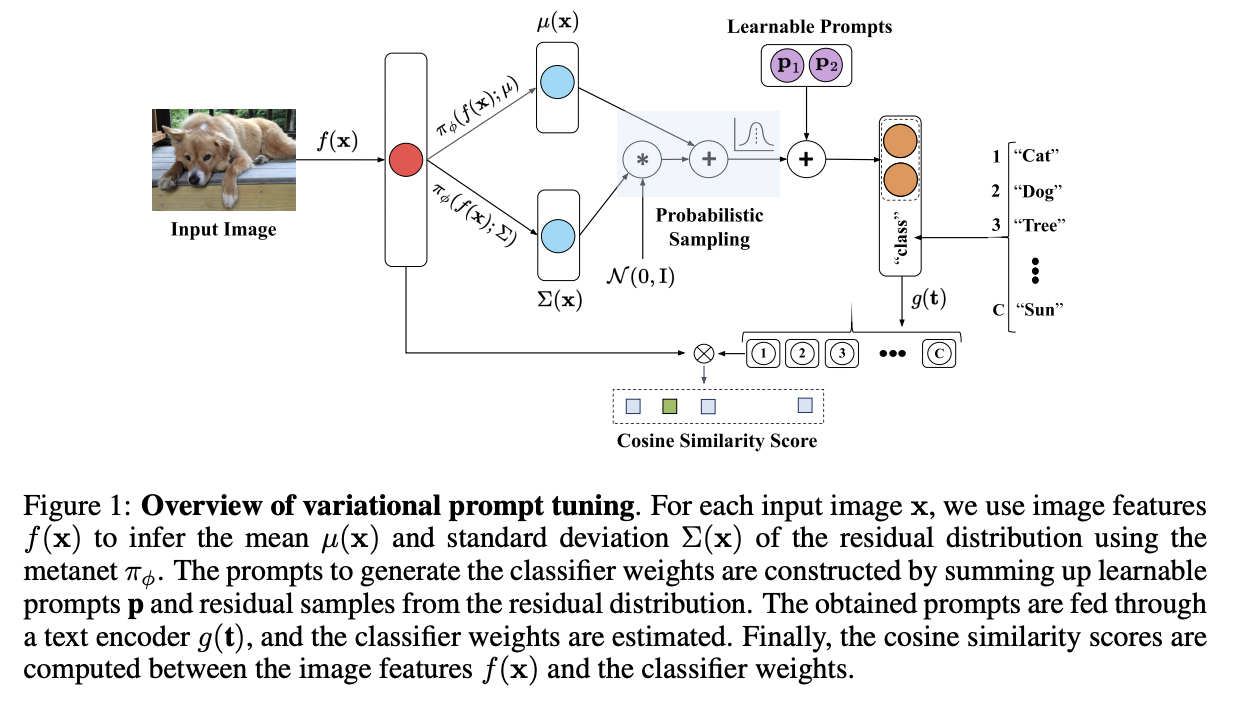
VPT (https://openreview.net/pdf?id=t2qu5Hotedi) (ICLRW 2023)
-
Title: Variational prompt tuning improves generalization of vision-language models
-
Proposal: VPT = Variational prompt tuning
- Key point: Models text prompts with instance-specific distribution
-
\(\mathbf{p}_\gamma(\mathbf{x})=\left[\mathbf{p}_1+\mathbf{r}_\gamma, \mathbf{p}_2+\mathbf{r}_\gamma, \cdots, \mathbf{p}_L+\mathbf{r}_\gamma\right], \mathbf{r}_\gamma \sim p_\gamma(\mathbf{x})\).
- \(\mathbf{r}(\mathbf{x}) \sim \mathcal{N}(\mu(\mathbf{x}), \Sigma(\mathbf{x}))\).
-
-
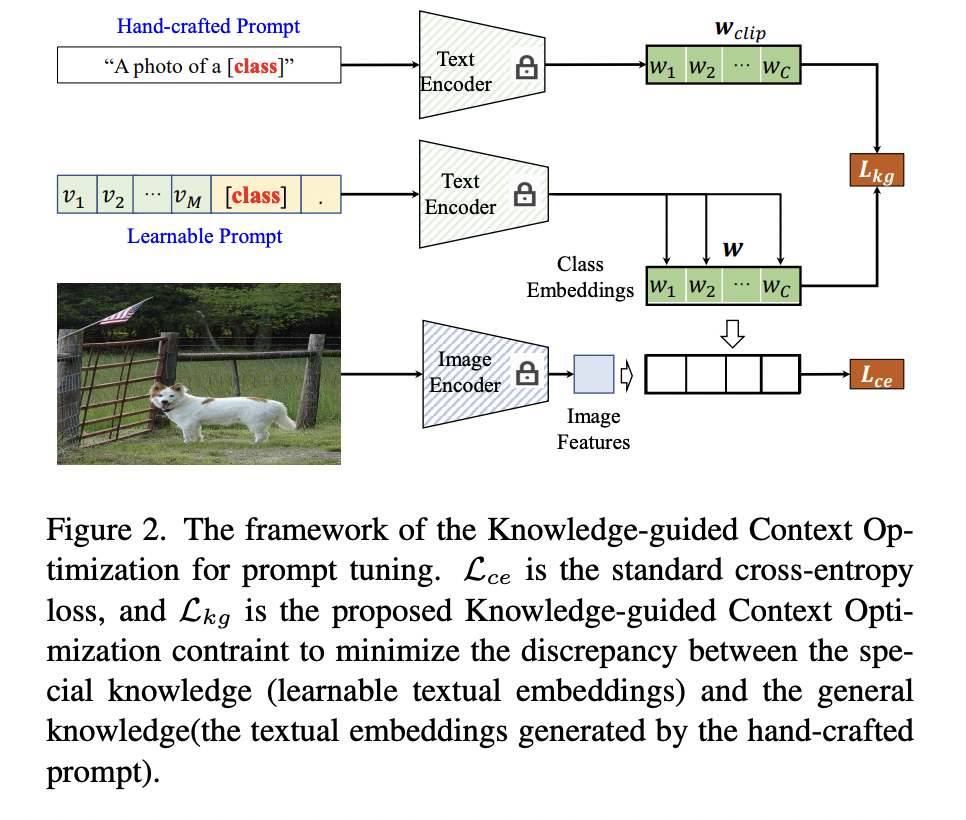
KgCoOp (https://arxiv.org/pdf/2303.13283) (CVPR 2023)
-
Title: Knowledge-guided Context Optimization for prompt tuning
- Proposal: KgCoOP= Knowledge-guided CoOP
- Key point: Enhances the generalization of unseen class by mitigating the forgetting of textual knowledge
- How? By reducing the discrepancy between the ..
- (1) Learnable prompt
- (2) Hand-crafted prompt
-
As a regularization loss!
( Add the KgCoOp loss upon the contrastive loss! )
- \(\mathcal{L}=\mathcal{L}_{c e}+\lambda \mathcal{L}_{k g}\).
- \(\mathcal{L}_{k g}=\frac{1}{N_c} \sum_{i=1}^{N_c} \mid \mid \mathbf{w}_i-\mathbf{w}_i^{c l i p} \mid \mid _2^2\).
- \(\mathcal{L}=\mathcal{L}_{c e}+\lambda \mathcal{L}_{k g}\).
-
-
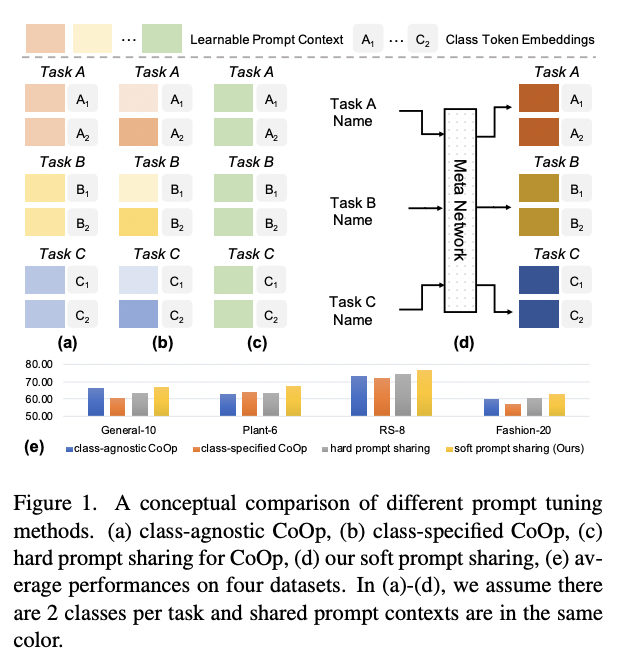
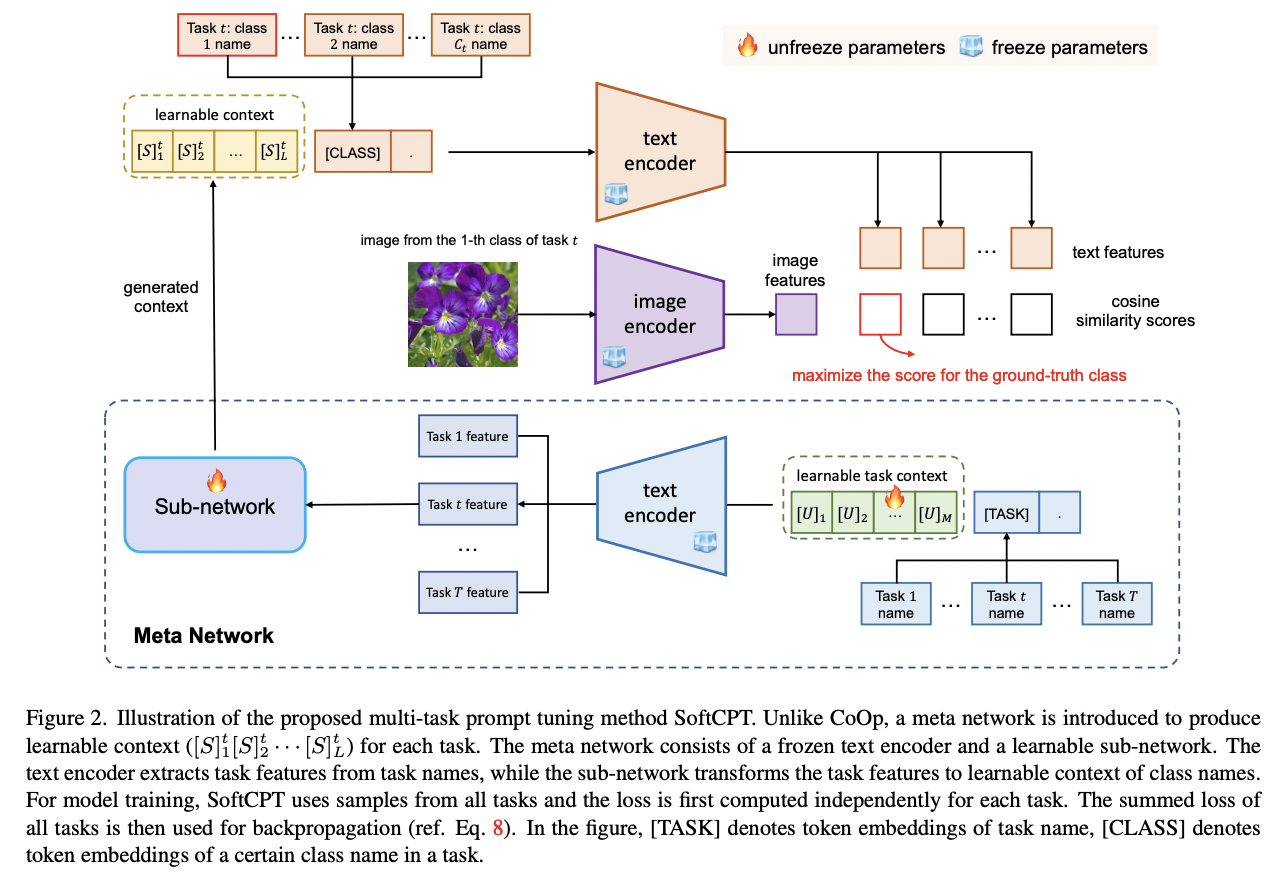
SoftCPT (https://arxiv.org/abs/2208.13474) (arxiv 2022)
-
Title: Prompt Tuning with Soft Context Sharing for Vision-Language Models
-
Motivation: Many few-shot tasks are inherently correlated!
-
Proposal: SoftCPT = Soft Context Sharing for Prompt Tuning
- How?
- (1) Fine-tune pre-trained VLMs on multiple tasks jointly
-
(2) Design a “task-shared” meta network
\(\rightarrow\) To generate prompt context for each task with…
- a) Task name + b) Learnable task context
-
-
-
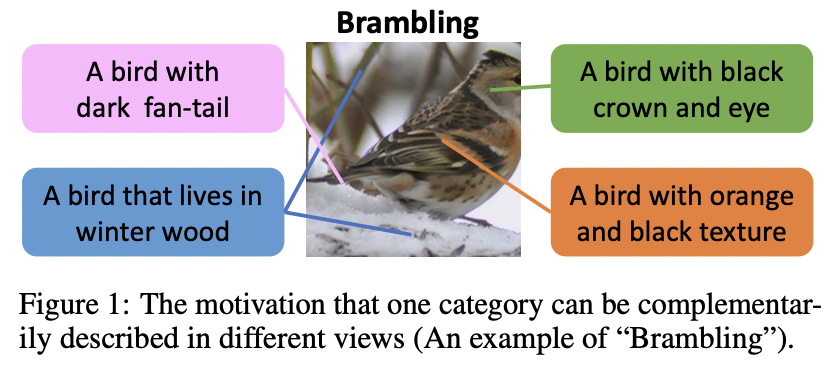
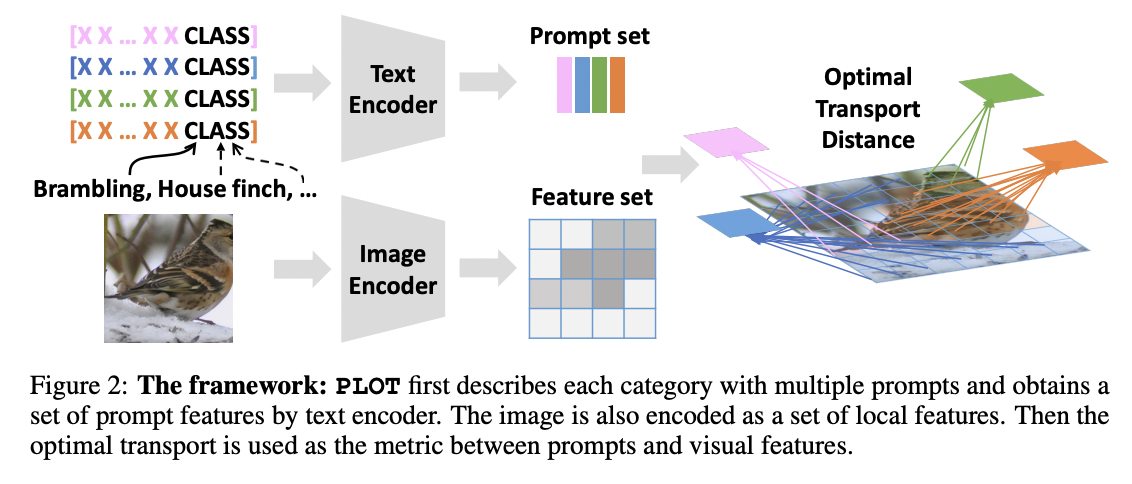
PLOT (https://arxiv.org/pdf/2210.01253) (ICLR 2023)
-
Title: PLOT: Prompt Learning with Optimal Transport for Vision-Language Models
-
Conventional vs. PLOT
-
Conventional: Learn one prompt
-
Proposal: Learn multiple prompts
\(\rightarrow\) To describe diverse characteristics of categories
-
-
Convergence into a single point issue?
\(\rightarrow\) Apply optimal transport to match the vision and text modalities.
-
Procedure
- Step 1) Encode visual & textual feature sets
- Step 2) Two-stage optimization strategy
- (Inner loop) Optimize the optimal transport distance
- To align visual features and prompts by the Sinkhorn algorithm,
- (Outer loop) Learn the prompts by this distance from the supervised data
- (Inner loop) Optimize the optimal transport distance
-
-
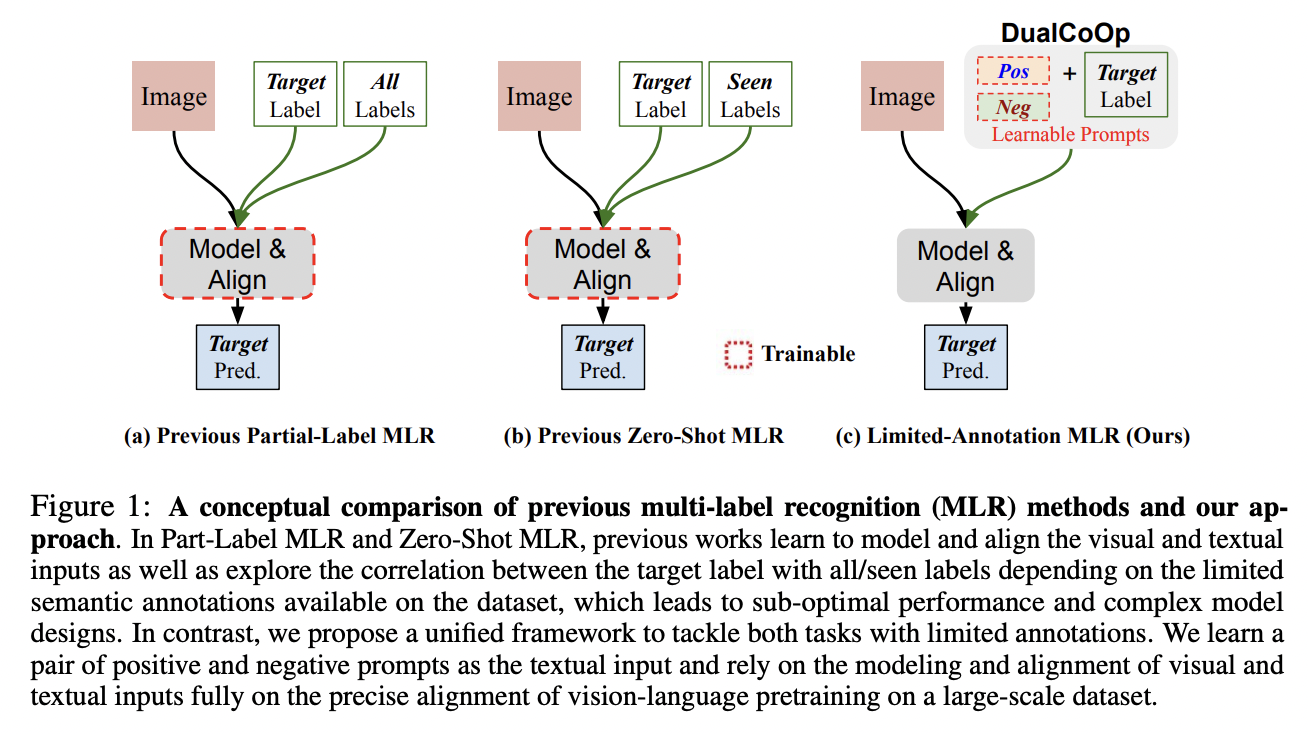
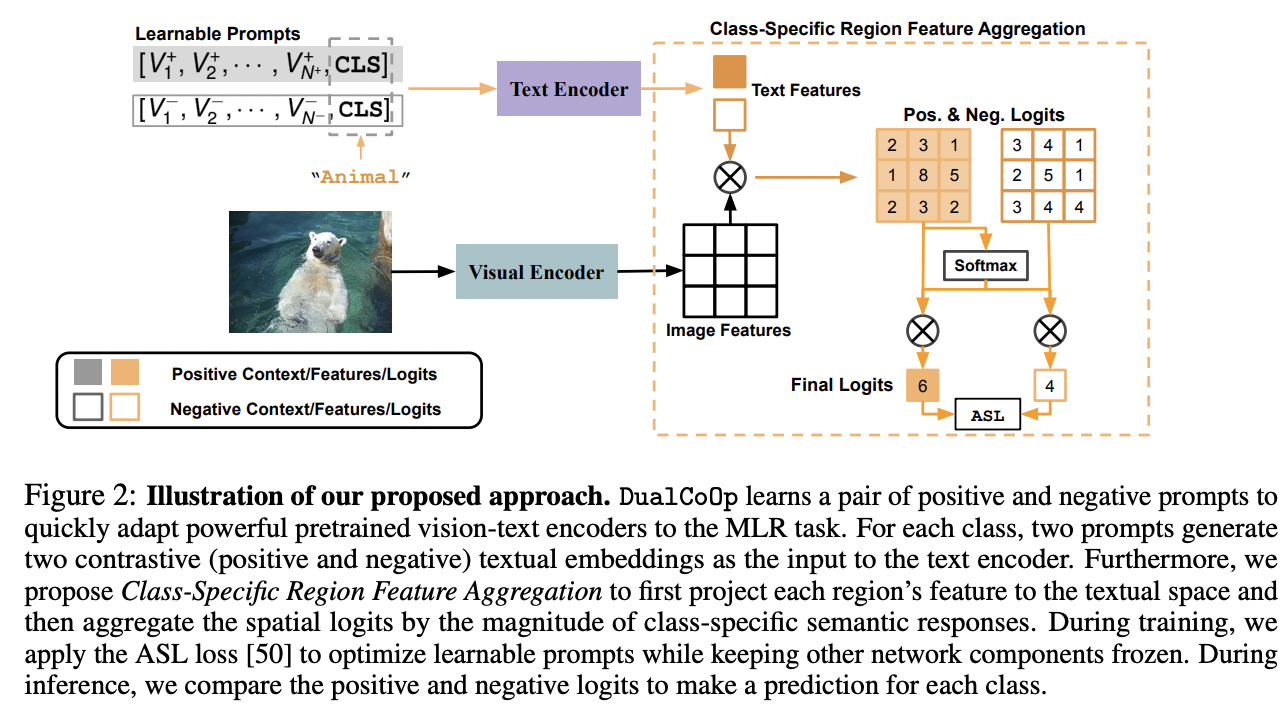
DualCoOp (https://arxiv.org/pdf/2206.09541) (NeurIPS 2022)
-
Title: DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations
-
Task: multi-label recognition (MLR)
-
Challengies in MLR: Insufficient image labels
\(\rightarrow\) Recent works in MLR: Learns an alignment between textual and visual spaces
-
Proposal: DualCoOp = Dual Context Optimization
- Pretrained with millions of auxiliary image-text pairs
- Solve partial-label MLR and zero-shot MLR
How? Encodes positive & negative contexts with class names (i.e., prompts)
-
-
TaI-DP (https://arxiv.org/pdf/2211.12739) (CVPR 2023)
-
Title: Texts as Images in Prompt Tuning for Multi-Label Image Recognition
-
Task: multi-label recognition (MLR)
-
Key point: Treat “texts as images” for prompt tuning!
-
Motivation: In contrast to the visual data, text descriptions are easy to collect
( + class labels can be directly derived )
-
Double-grained prompt tuning (TaI-DPT)
- Introduces double-grained prompt tuning for capturing both coarse-grained and fine-grained embeddings.
- To enhance the multi-label recognition performance.
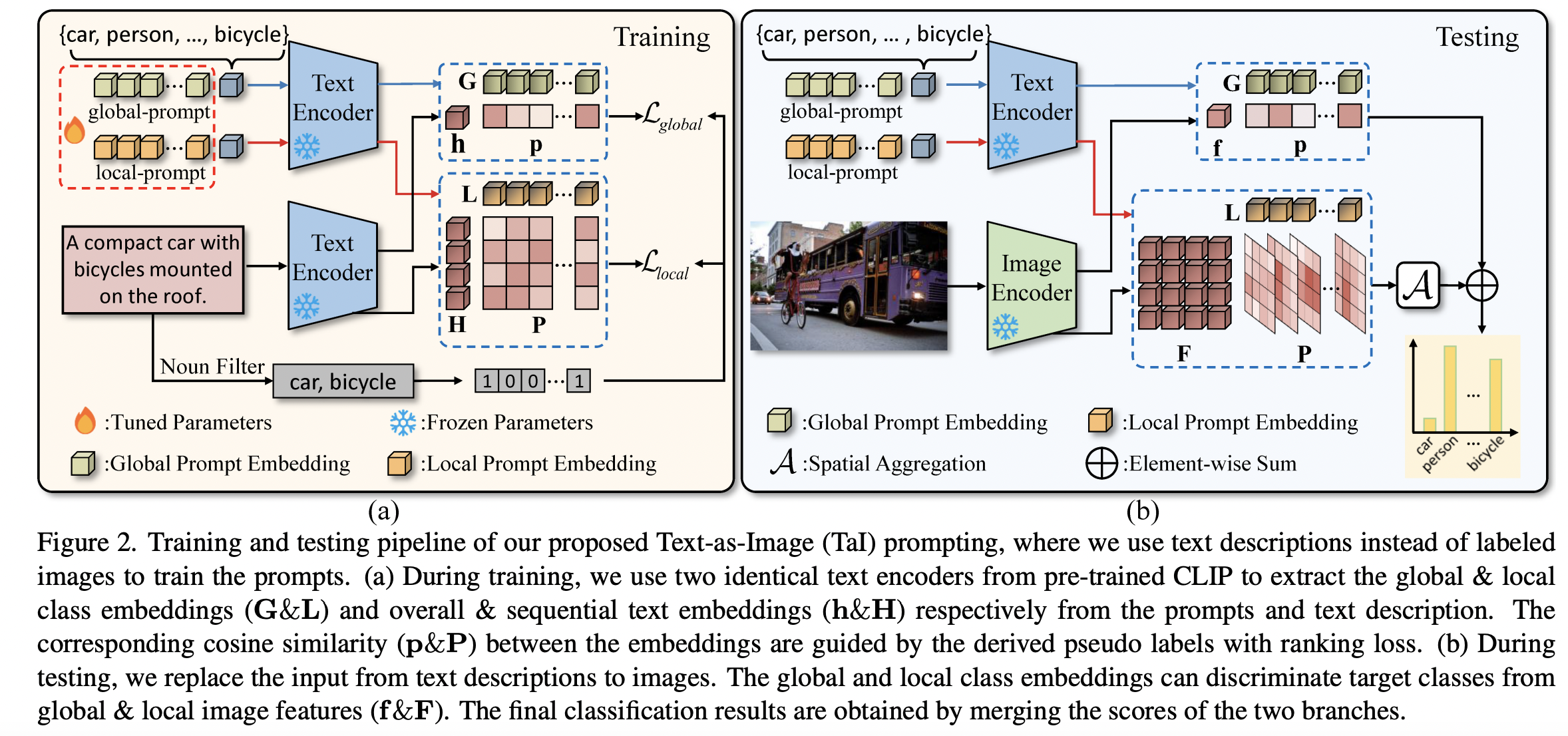
-
-
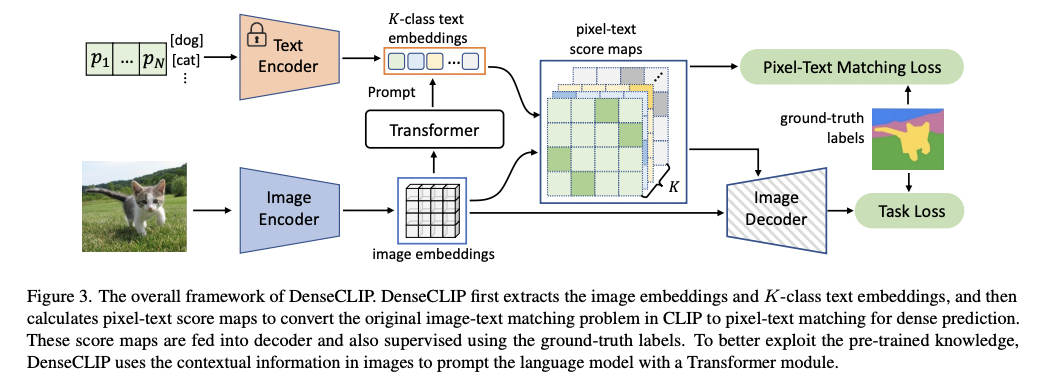
DenseCLIP (https://arxiv.org/abs/2112.01518) (CVPR 2022)
- Title: DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
- Explores language guided fine-tuning that employs visual features to tune text prompts for dense prediction
- New framework for dense prediction by knowledge of pre-trained knowledge from CLIP
- Convert (a) \(\rightarrow\) (b)
- (a) Image-text matching problem (in CLIP)
- (b) Pixel-text matching problem
- Use the pixel-text score maps to guide the learning of dense prediction models!
- ProTeCt (https://arxiv.org/pdf/2306.02240v2) (CVPR 2024)
- Title: ProTeCt: Prompt Tuning for Taxonomic Open Set Classification
- Improves the consistency of model predictions for hierarchical classification task
-
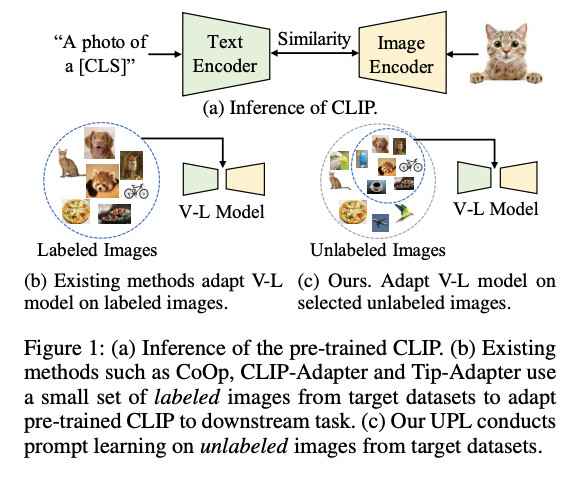
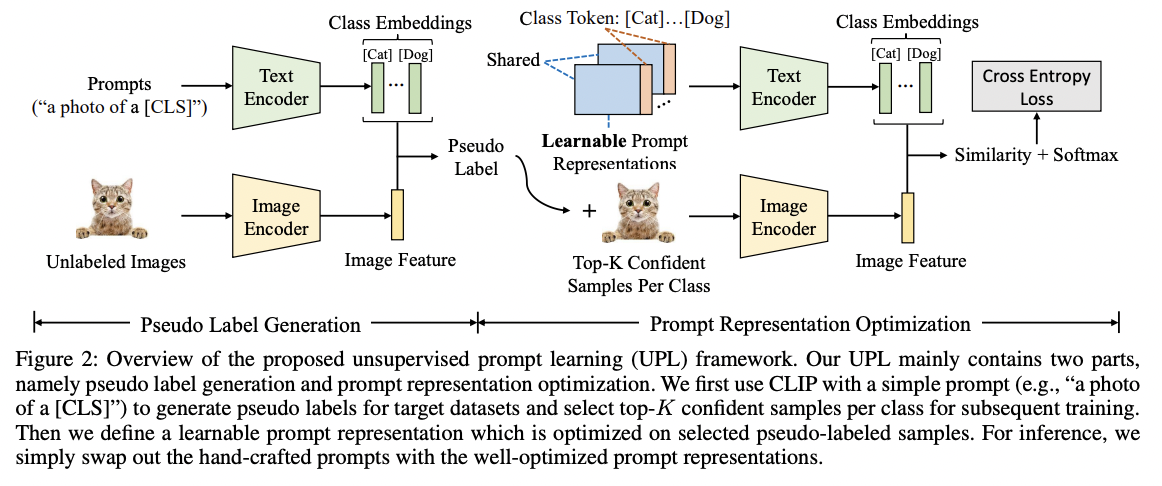
UPL (https://arxiv.org/pdf/2204.03649) (arxiv 2022)
- Title: Unsupervised prompt learning for visionlanguage model
- Limitation of previous works: Requiring labeled data from the target datasets
- Proposal: UPL = Unsupervised prompt learning
- Key point: Learnable prompts with self-training on selected pseudo-labeled samples.
- How to generate pseudo label?
- \(p_c=\frac{\exp \left(<\boldsymbol{f}_c^{\text {text }}, \boldsymbol{f}^{\text {image }}>/ \tau\right)}{\sum_{j=1}^C \exp \left(<\boldsymbol{f}_j^{\text {text }}, \boldsymbol{f}^{\text {image }}>/ \tau\right)}\).
- \(\hat{y}=\underset{c}{\operatorname{argmax}} p_c\).
-
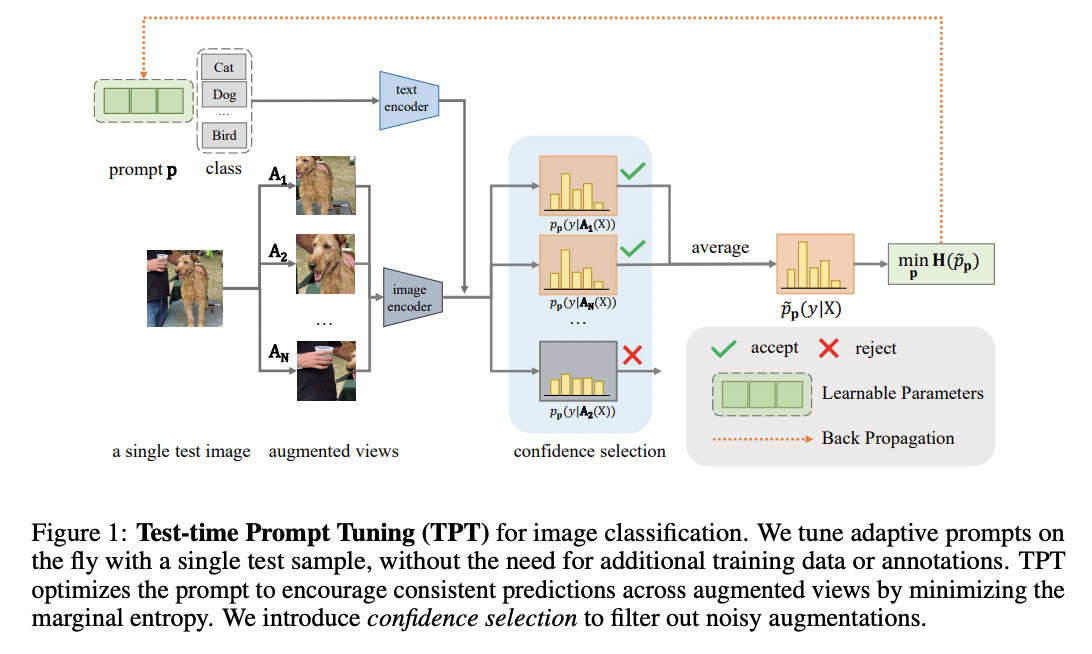
TPT (https://arxiv.org/pdf/2209.07511) (NeurIPS 2022)
-
Title: Test-time prompt tuning for zero-shot generalization in vision-language model
-
Limitation of previous (prompt tuning) works?
- Training on domain-specific data reduces a model’s generalization capability to unseen data!
-
Proposal: TPT = Test-time prompt tuning
- Key point: Explores test-time PT to learn adaptive prompts from a single downstream sample
-
By minimizing the entropy with confidence selection
\(\rightarrow\) So that the model has consistent predictions across different augmented views!
-
P1-2) Visual PT
Transfers VLMs by modulating the input of image encoder
Example)
-
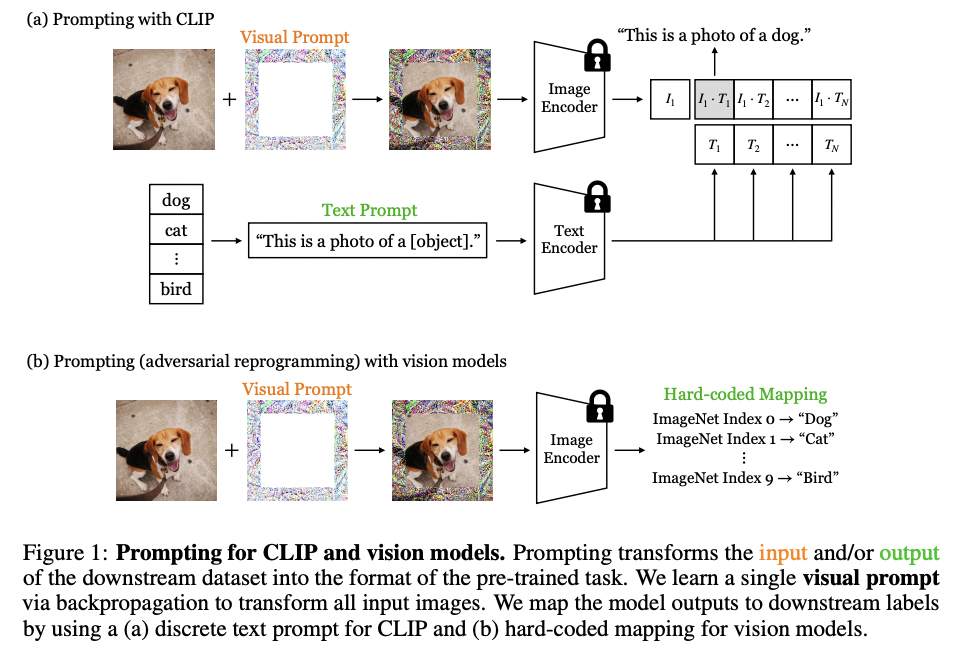
VP (https://arxiv.org/pdf/2203.17274) (arxiv 2022)
-
Title: Exploring Visual Prompts for Adapting Large-Scale Models
-
Proposal: VP = Visual Prompting
- Key point: Learnable image perturbations \(v\)
-
How? Modify the input image \(x^I\) by \(x^I+v\)
\(\rightarrow\) Aim to adjust \(v\) to minimize a recognition loss
-
- RePrompt (https://arxiv.org/pdf/2406.11132) (arxiv 2024)
- Title: RePrompt: Planning by Automatic Prompt Engineering for Large Language Models Agents
- Integrates retrieval mechanisms into visual prompt tuning
Summary of Visual PT:
\(\rightarrow\) Enables pixel-level adaptation to downstream tasks ( Benefit dense prediction tasks )
P1-3) Text-Visual PT
Benefiting from joint prompt optimization on multiple modalities
Example)
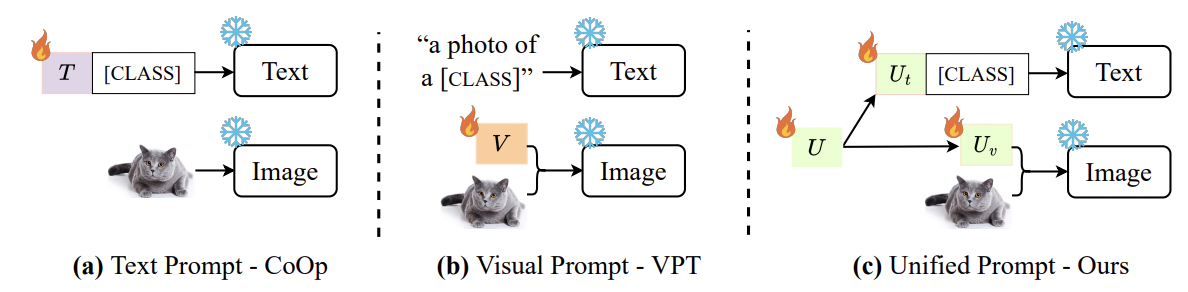
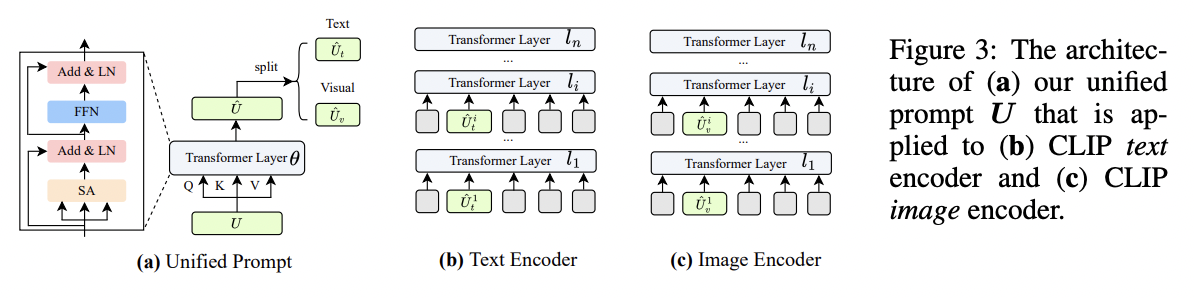
- UPT (https://arxiv.org/pdf/2210.07225) (arxiv 2022)
- Title: Unified Vision and Language Prompt Learning
- Proposal: UPT = Unified Prompt Tuning
- Goal: Learn a tiny NN to jointly optimize prompts across different modalities
-
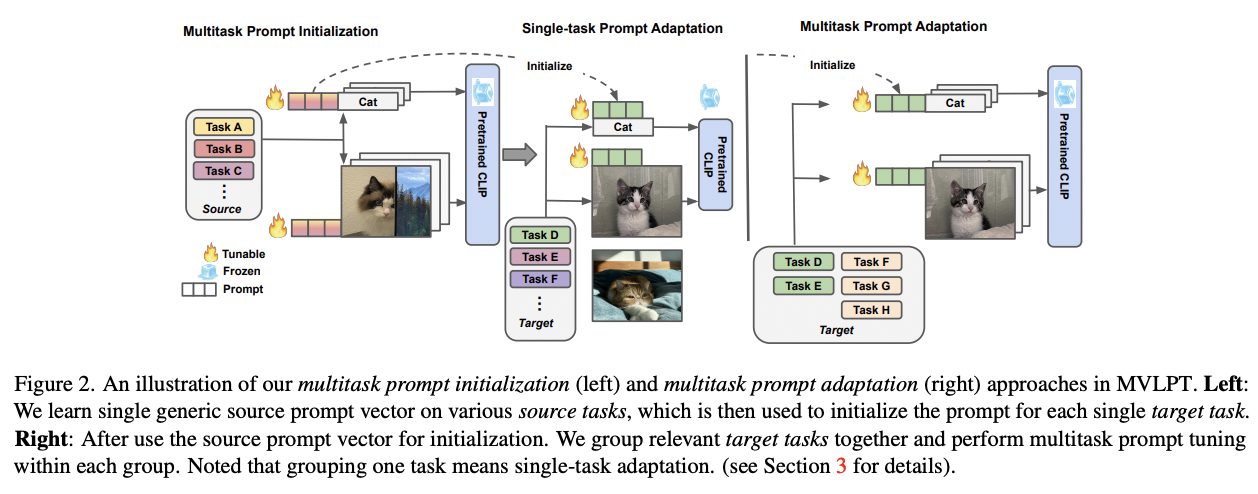
MVLPT (https://arxiv.org/pdf/2211.11720) (WACV 2024)
-
Title: Multitask Vision-Language Prompt Tuning
-
Proposal: MVLPT = Multitask Vision-Language Prompt Tuning
- Key point: Incorporate cross-task knowledge into text and image PT
-
Findings
-
(1) Effectiveness of learning a single transferable prompt from multiple source tasks
\(\rightarrow\) Used as initialization for the prompt for each target task
-
(2) Many target tasks can benefit each other from *sharing prompt vectors
\(\rightarrow\) \(\therefore\) Can be jointly learned via multitask prompt tuning!
-
Learnable prompts: \(\boldsymbol{U}=\left[\boldsymbol{U}_T, \boldsymbol{U}_V\right] \in \mathbb{R}^{d \times n}\) with length \(n\),
- where \(\boldsymbol{U}_T \in \mathbb{R}^{d \times n_T}, \boldsymbol{U}_V \in \mathbb{R}^{d \times n_V}\)
-
-
-
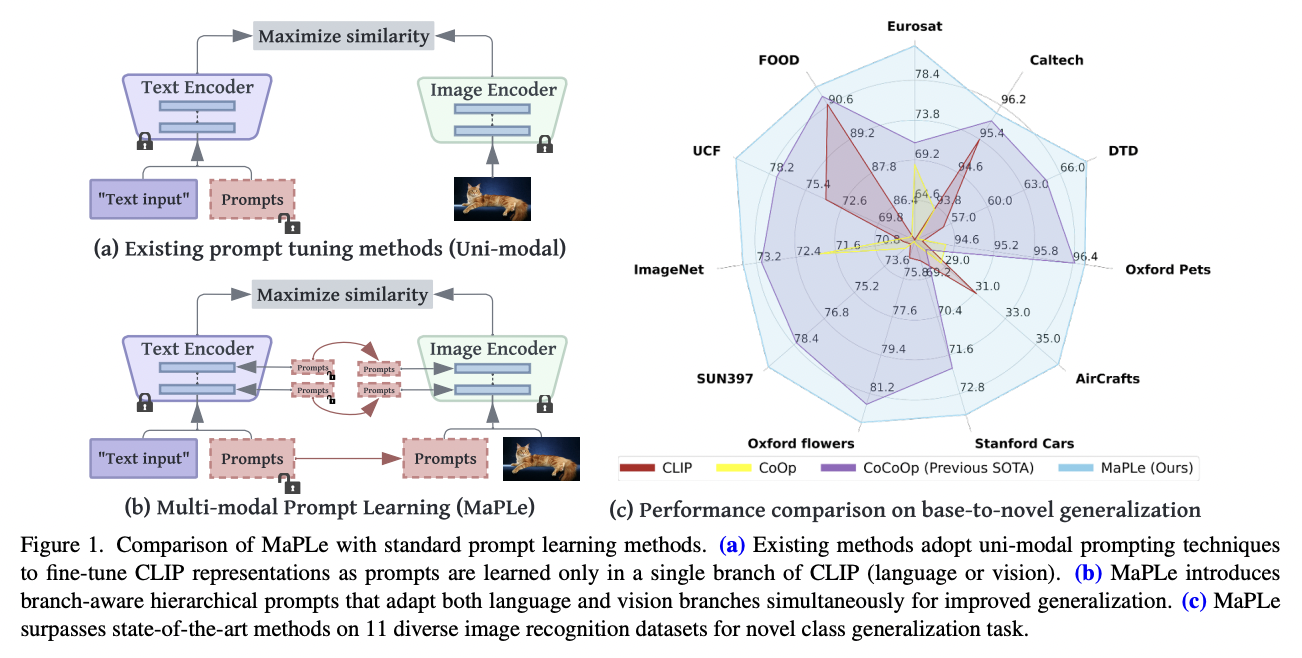
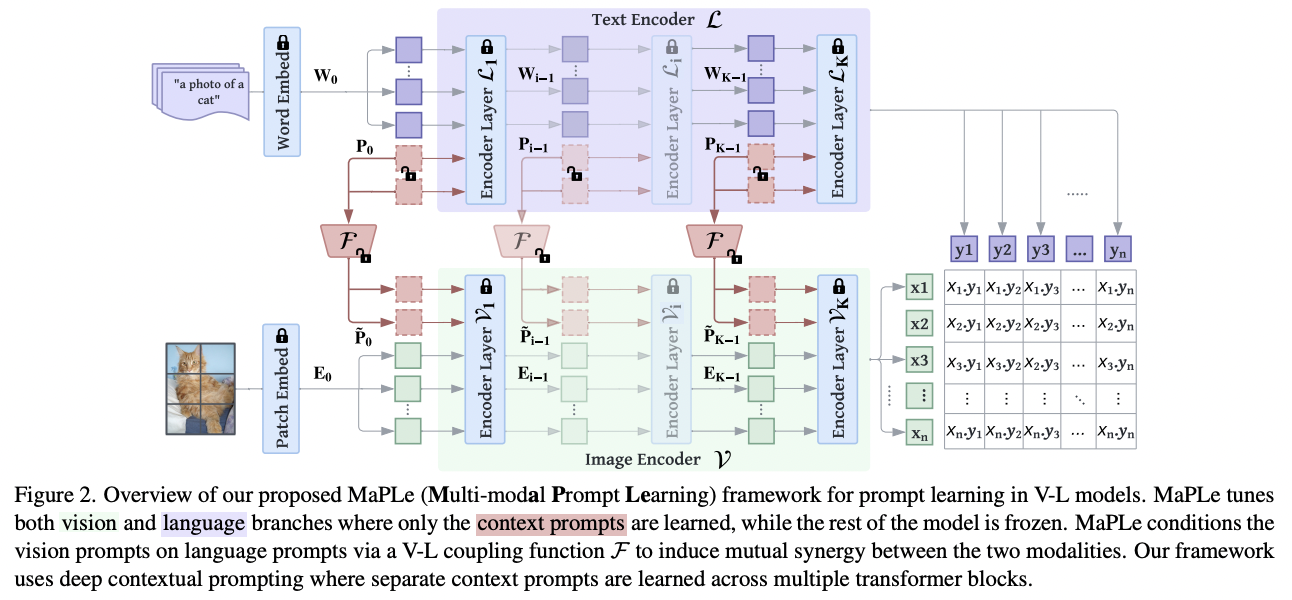
MaPLe (https://arxiv.org/abs/2210.03117) (CVPR 2023)
- Title: MaPLe: Multi-modal Prompt Learning
- Proposal: MaPLe = Multi-modal Prompt Learning
- To improve alignment between the vision & language representations
- Key point: Enabling a mutual promotion between text prompts & image prompts!
- Ensure mutual synergy
- Discourages learning independent uni-modal solutions
- CAVPT (https://arxiv.org/pdf/2208.08340) (arxiv 2023)
- Title: Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model
- Cross attention between class-aware visual prompts & text prompts
P1-4) Discussion
PT = Parameter-efficient VLM transfer
-
with a few learnable text/image prompts
-
requires little extra network layers or complex network modifications.
Nonetheless, low flexibility!
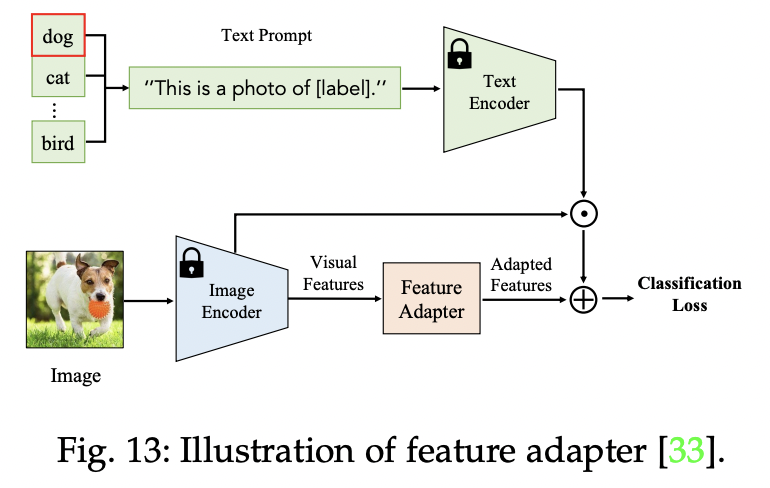
P2) via Feature Adaptation
Fine-tunes VLMs with an additional (light-weight) feature adapter
Example)
-
Clip-Adapter (https://arxiv.org/pdf/2110.04544) (arxiv 2021)
-
Title: CLIP-Adapter: Better Vision-Language Models with Feature Adapters
-
Add trainable linear layers after (1) language and (2) image encoders
( + Keep others frozen )
-
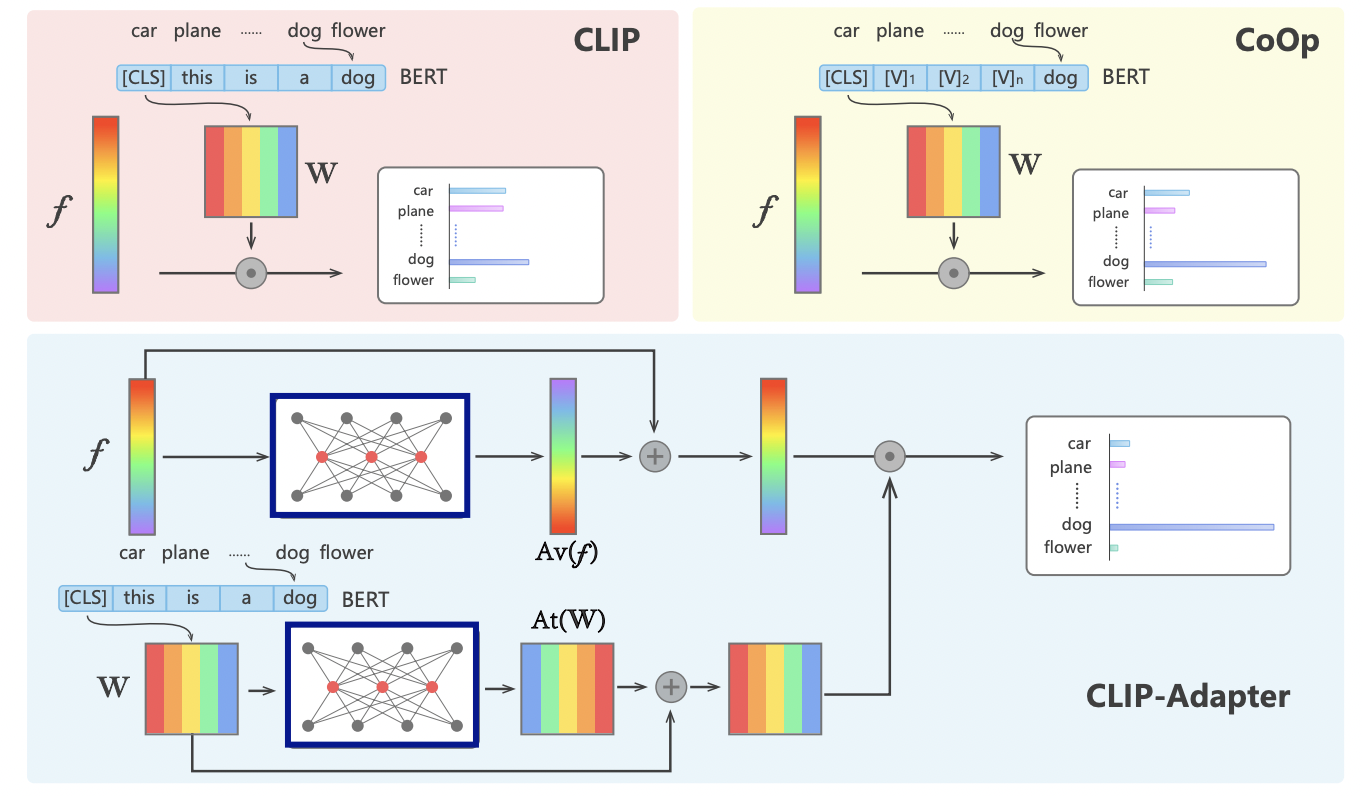
-
Tip-Adapter (https://arxiv.org/pdf/2111.03930) (ECCV 2022)
-
Title: Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
-
Proposal: Tip-Adapter = Training-Free CLIP-Adapter
\(\rightarrow\) Directly employs the embeddings of few-shot labelled images as the adapter weights!
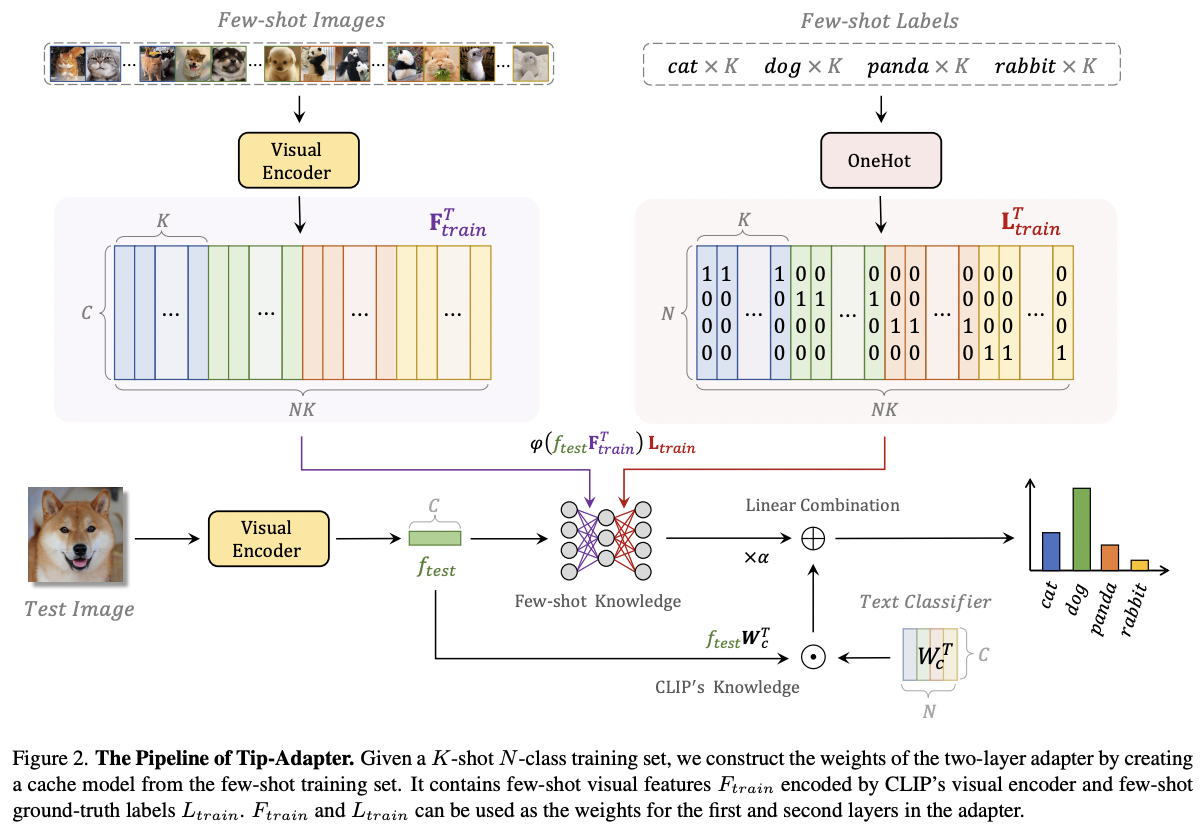
-
-
SVL-Adapter (https://arxiv.org/pdf/2210.03794) (BMVC 2022)
- Title: SVL-Adapter: Self-Supervised Adapter for Vision-Language Pretrained Models
- SSL adapter which employs an additional encoder
- Combines the complementary strengths of both
- (1) Vision-language pretraining
- (2) Self-supervised representation learning
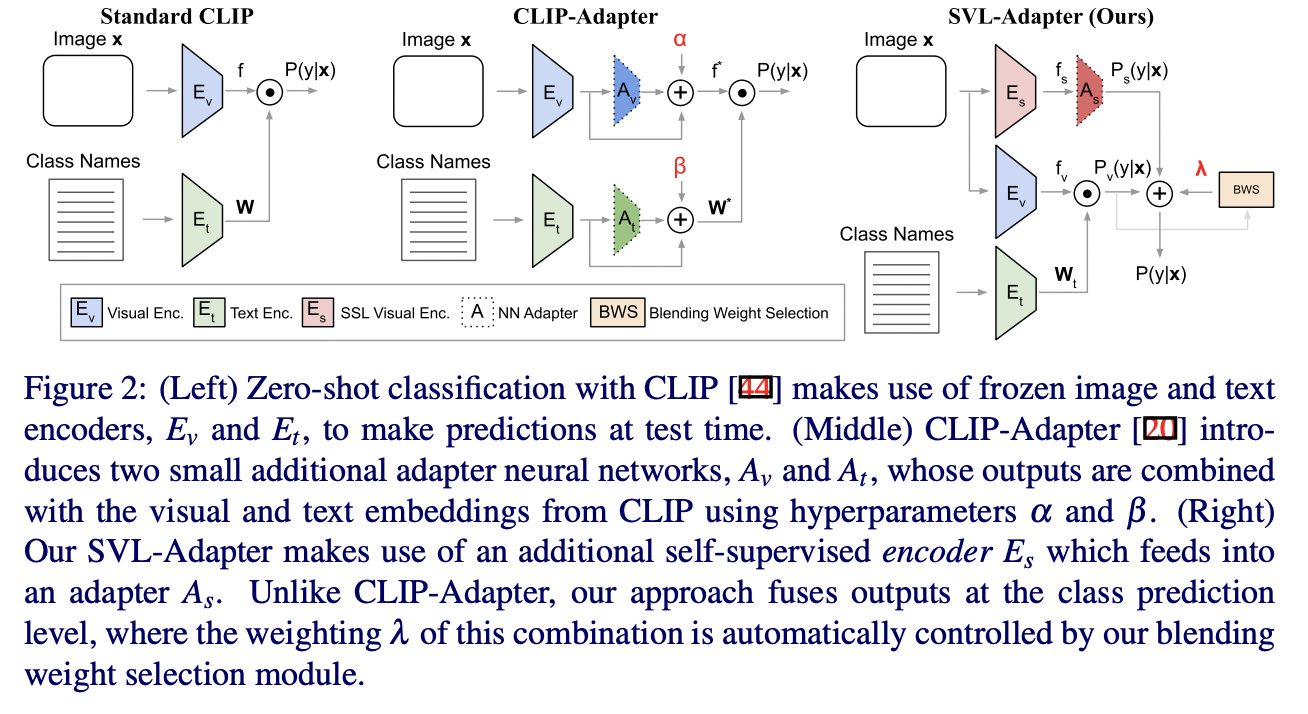
Discussion
Feature adaptation
-
Pros) Flexible and effective
-
Cons) Requires modifying network architecture
\(\rightarrow\) Can not handle VLMs that have concerns in intellectual property!
P3) Other Methods
- WiSE-FT (https://arxiv.org/pdf/2109.01903) (CVPR 2022)
- Title: Robust fine-tuning of zero-shot models
- Existing fine-tuning methods:
-
Pros) Improve accuracy on a given target distribution
-
Cons) Reduce robustness to distribution shifts
-
- Proposal: WiSE-FT = Weight-Space Ensembles for Fine-Tuning
- Details: Combines the weights of a (1) & (2)
- (1) Fine-tuned VLM
- (2) Original VLM
- Results: Provides large accuracy improvements under distribution shift

-
MaskCLIP (https://arxiv.org/pdf/2112.01071) (ECCV 2022)
-
Title: Extract free dense labels from clip
-
Proposal: MaskCLIP
- Extracts dense image features by modifying the architecture of the CLIP image encoder.
\(\rightarrow\) Examine the intrinsic potential of CLIP for pixel-level dense prediction
-
Results
- MaskCLIP yields compelling segmentation results!
- Suggests that MaskCLIP can serve as a new reliable source of supervision for dense prediction tasks to achieve annotation-free segmentation
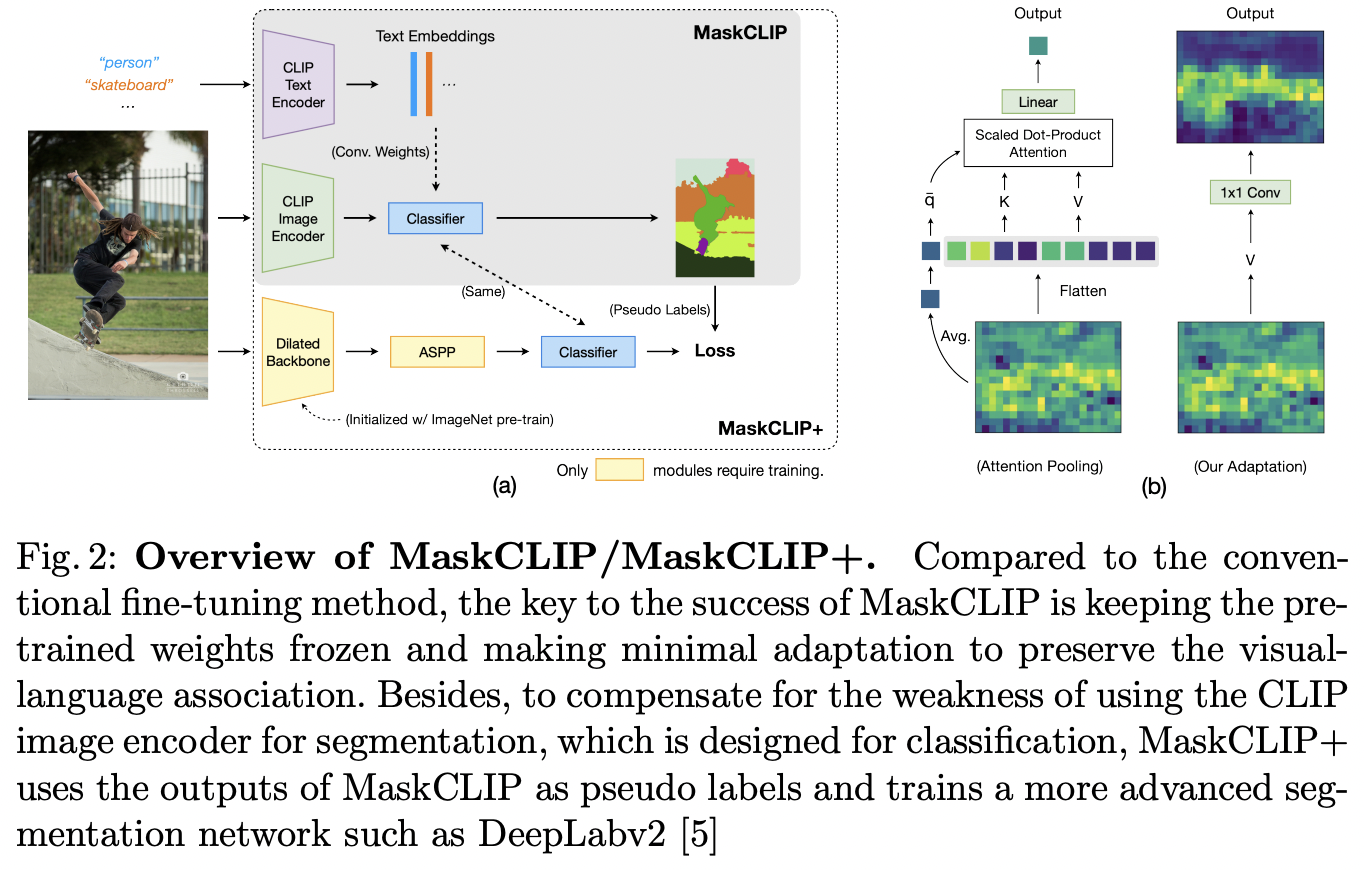
-
-
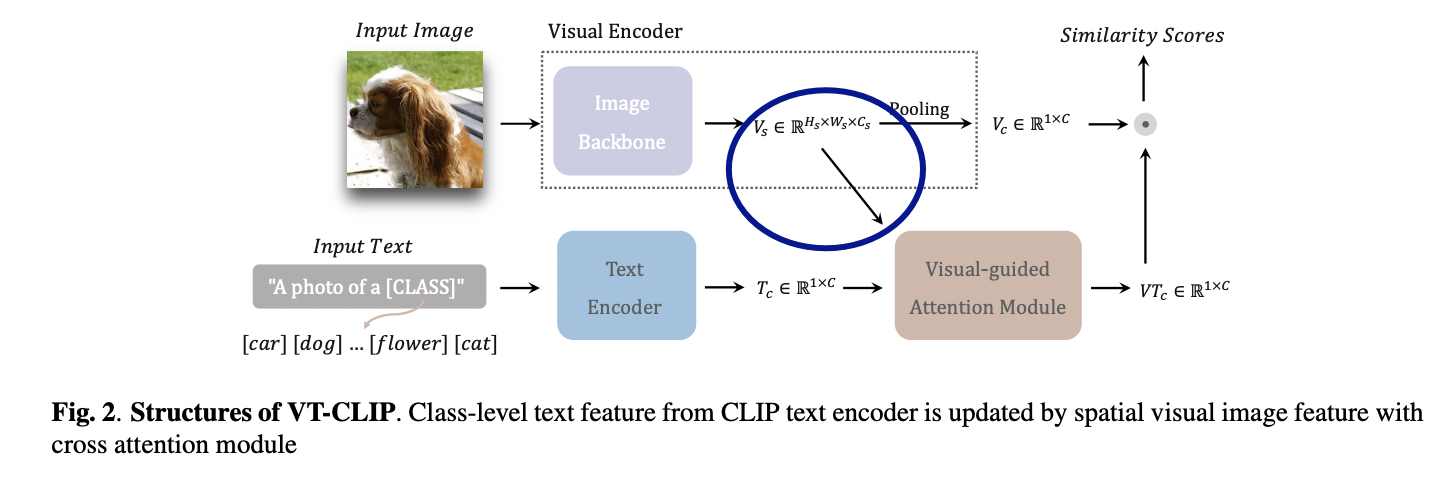
VT-CLIP (https://arxiv.org/pdf/2112.02399) (arxiv 2021)
-
Title: Vt-clip: Enhancing vision-language models with visual-guided texts
-
Limitation of previous CLIPs: Semantic gap within datasets
\(\rightarrow\) Pre-trained image-text alignment becomes sub-optimal on downstream tasks!
-
Proposal: VT-CLIP = Enhance CLIP via Visual-guided Texts
- To better adapt the cross-modality embedding space
-
How? Guide textual features of different categories to adaptively explore informative regions on the image and aggregate visual features
\(\rightarrow\) Texts become visual-guided
( = More semantically correlated with downstream images )
-
Details of visual-guided cross-attention module
-
Self-attention layer & Co-attention layer & Feed forward network
-
\(V T_c=\operatorname{Cross} \operatorname{Attn}\left(V_s, V_s, T_c\right)+T_c\),
-
where \(T_c\) and \(V_s\) are fed into the cross attention module,
with \(T_c\) serving as query, and \(V_s\) as key and value
\(\rightarrow\) \(V T_c\) denotes the adapted text features.
-
-
-
-
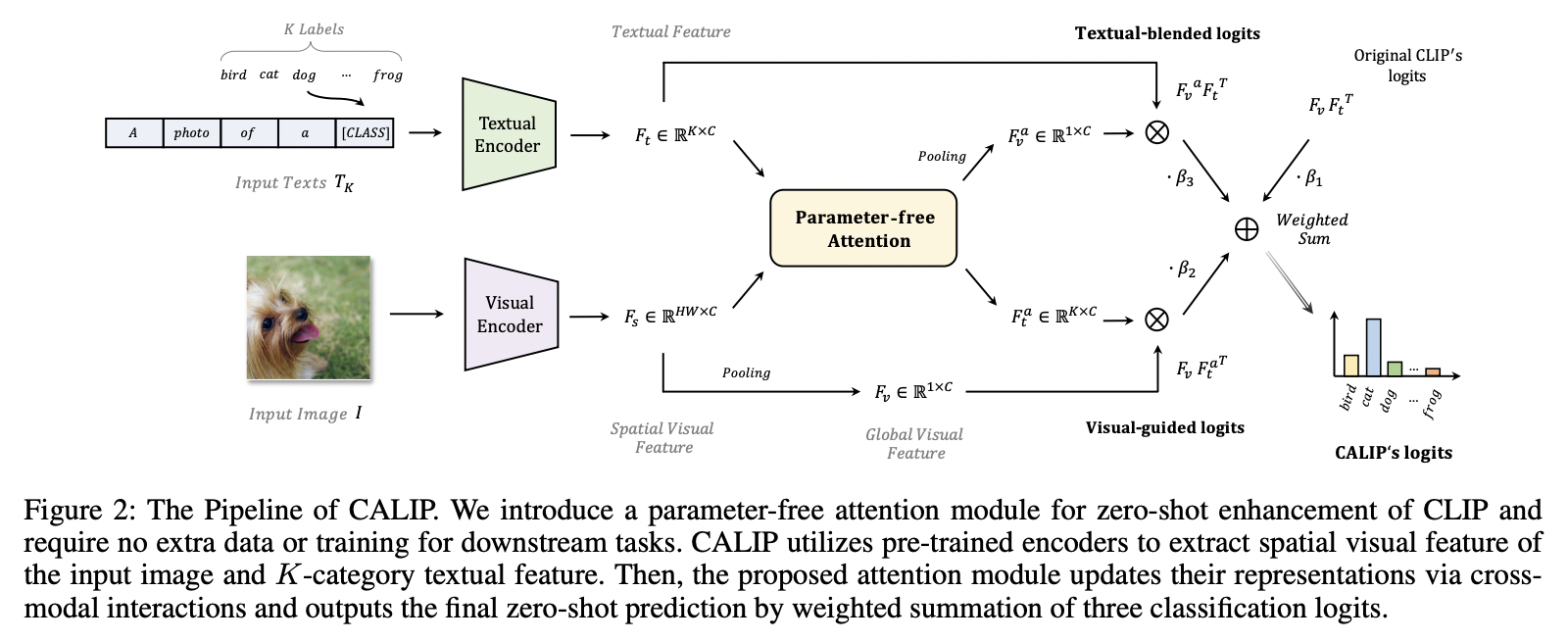
CALIP (https://arxiv.org/pdf/2209.14169) (AAAI 2023)
-
Title: Calip: Zero-shot enhancement of clip with parameter-free attention
-
Preivous works have tried to improve CLIP’s downstream accuracy
- e.g., Additional learnable modules upon CLIP
\(\rightarrow\) Extra training cost & data requirement: Hinder the efficiency
- Proposal: CALIP = CLIP + parameter-free Attention module
- Free-lunch enhancement method
- To boost CLIP’s zero-shot performance
- Details
- Guide visual and textual representations to interact with each other
- Explore cross-modal informative features via attention
- Results
- Text-aware image features
- Visual-guided text features
- CALIP vs. CALIP-FS.
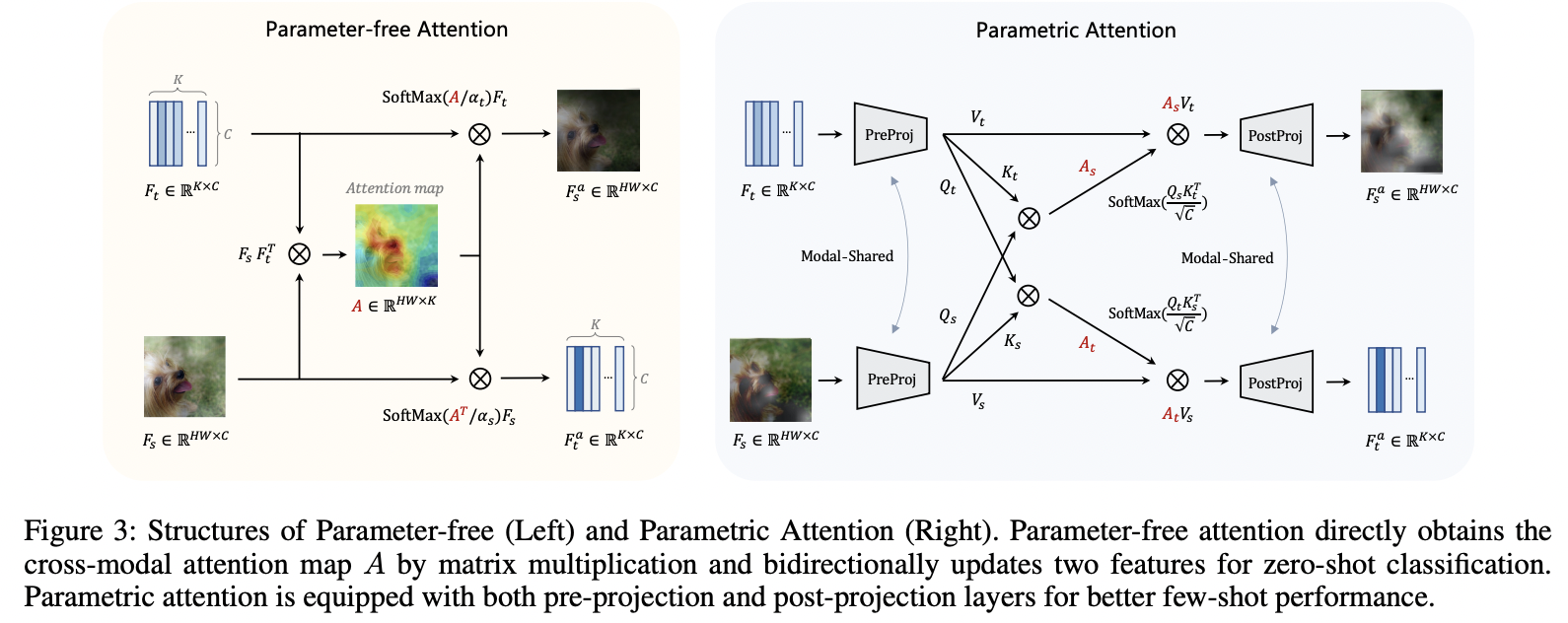
- CALIP:
- \(A=F_s F_t^T \in R^{H W \times K}\).
- \(\begin{aligned} & F_s^a=\operatorname{SoftMax}\left(A / \alpha_t\right) F_t \\ & F_t^a=\operatorname{SoftMax}\left(A^T / \alpha_s\right) F_s \end{aligned}\).
- CALIP-FS:
- \(\begin{aligned} & Q_t, K_t, V_t=\operatorname{PreProject}\left(F_t\right), \\ & Q_s, K_s, V_s=\operatorname{PreProject}\left(F_s\right), \end{aligned}\).
- \(\begin{aligned} & A_t=\operatorname{SoftMax}\left(\frac{Q_t K_s^T}{\sqrt{C}}\right) \in R^{K \times H W} \\ & A_s=\operatorname{SoftMax}\left(\frac{Q_s K_t^T}{\sqrt{C}}\right) \in R^{H W \times K} \end{aligned}\).
- \[\begin{aligned} F_t^a & =\operatorname{Post} \operatorname{Project}\left(A_t V_s\right) \\ F_s^a & =\operatorname{Post} \operatorname{Project}\left(A_s V_t\right) \end{aligned}\]
- CALIP:
-
-
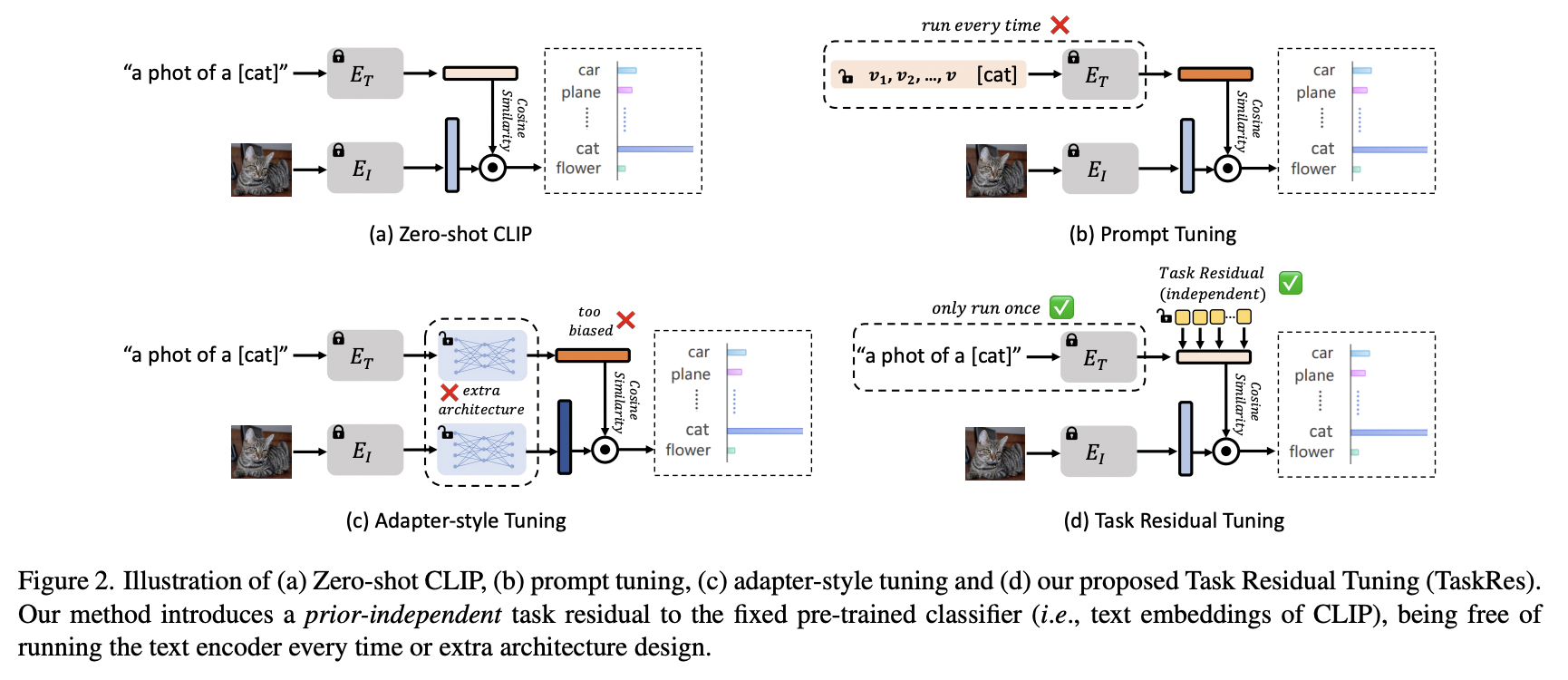
TaskRes (https://arxiv.org/pdf/2211.10277) (CVPR 2023)
-
Title: Task residual for tuning vision-language models
-
Limitation of previous works
- (1) Prompt tuning (PT): Discards the pre-trained text-based classifier and builds a new one
- (2) Adapter-style tuning (AT): Fully relies on the pre-trained features.
-
Solution : TaskRes = Task Residual Tuning
-
Details
-
Performs directly on the text-based classifier
- Text-based classifier = Text embeddings = Base classifier
-
Explicitly decouples (a) & (b)
- (a) Prior knowledge (of the pre-trained models)
- (b) New knowledge (regarding a target task)
-
Keeps the original classifier weights from the VLMs frozen
& Obtains a new classifier for the target task
-
- Result: Enables both (a) & (b)
- (a) Reliable prior knowledge preservation
- (b) Flexible task-specific knowledge exploration
- Task residual
- Set of tunable parameters \(\mathbf{x} \in \mathbb{R}^{K \times D}\)
- independent on the base classifier
- New classifier \(\mathbf{t}^{\prime}\) for the target task:
- \(\mathbf{t}^{\prime}=\mathbf{t}+\alpha \mathbf{x}\).
- Set of tunable parameters \(\mathbf{x} \in \mathbb{R}^{K \times D}\)
-
-
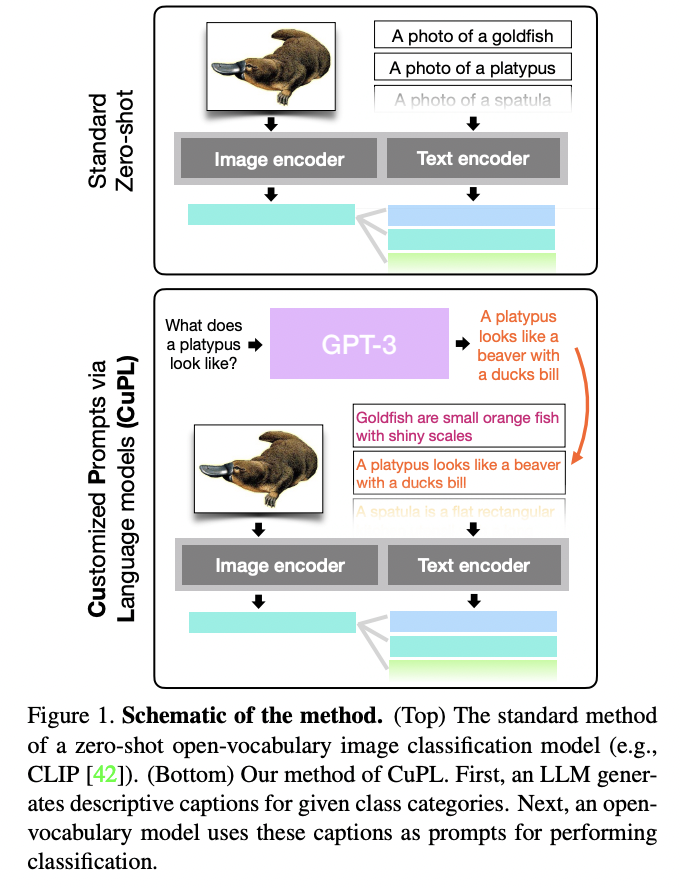
CuPL (https://arxiv.org/pdf/2209.03320) (ICCV 2023)
-
Title: What does a platypus look like? generating customized prompts for zero-shot image classification
-
Open-vocabulary models: New paradigm for image classification
- Classify among any arbitrary set of categories specified with natural language during inference.
-
Proposal: CuPL = Customized Prompts via Language models
-
Details:
- Augment text prompts!
- w/o relying on any explicit knowledge of the task domain
- Combine (1) & (2)
- (1) Open-vocabulary models
- (2) LLMs
- Augment text prompts!
-

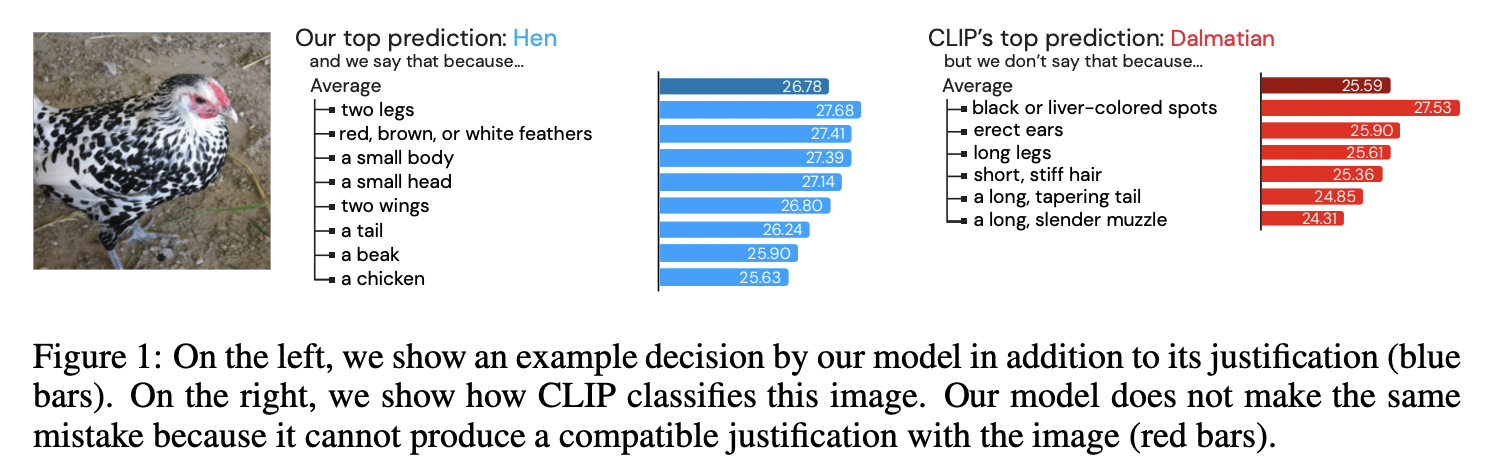
- VCD (https://arxiv.org/pdf/2210.07183) (ICLR 2023)
- Title: Visual classification via description from large language model
- Proposal: VCD = Visual Classification via Description from LLMs
- Limitation (of CLIP):
- Only using the category name \(\rightarrow\) Neglect to make use of the rich context of additional information!
- No intermediate understanding of why a category is chosen!
- Details
- Classification by description
- Ask VLMs to check for descriptive features rather than broad categories
- Explainability! Can get a clear idea of what features the model uses to construct its decision
- Classification by description
- \(s(c, x)=\frac{1}{ \mid D(c) \mid } \sum_{d \in D(c)} \phi(d, x)\).
- \(D(c)\) : Set of descriptors for the category \(c\)
- \(\phi(d, x)\) : Log probability that descriptor \(d\) pertains to the image \(x\).
- Represent \(d\) via a natural language sentence
- Classification: \(\underset{c \in C}{\arg \max } s(c, x)\)


(4) Summary & Discussion
Two major approaches for VLM transfer:
- (1) Prompt tuning
- (2) Feature adapter
Future works
- Previous studies: Few-shot supervised transfer
- Recent studies: Unsupervised transfer