
Vision-Language Models for Vision Tasks: A Survey
https://arxiv.org/pdf/2304.00685
Contents
- (7) VLM Knowledge Distillation
7. VLM Knowledge Distillation
VLMs capture generalizable knowledge!
- Covers a wide range of visual and text concepts
How to distill such general knowledge, while tackling complex dense prediction tasks?
- e.g., Object detection and semantic segmentation
(1) Motivation of Distilling Knowledge from VLMs
VLM transfer vs. VLM knowledge distillation
- (1) VLM transfer
- Generally keeps the original VLM architecture
- (2) VLM knowledge distillation
- Distills general knowledge to task-specific models without the restriction of VLM architecture
(2) Common Knowledge Distillation Methods
VLMs = Pre-trained with architectures and objectives designed for image-level (=coarse) representation
\(\therefore\) Most VLM knowledge distillation methods focus on …
- Transferring “image-level” knowledge \(\rightarrow\) “region- or pixel-level” tasks
- e.g., Object detection, Semantic segmentation

P1) for Object Detection
(Task introduction) Open-vocabulary object detection
-
Aims to detect objects described by arbitrary texts
( i.e., objects of any categories beyond the training/base class vocabulary )
-
CLIP-based models: Cover very broad vocabulary
\(\rightarrow\) Many studies explore to distill VLM knowledge to enlarge the detector vocabulary
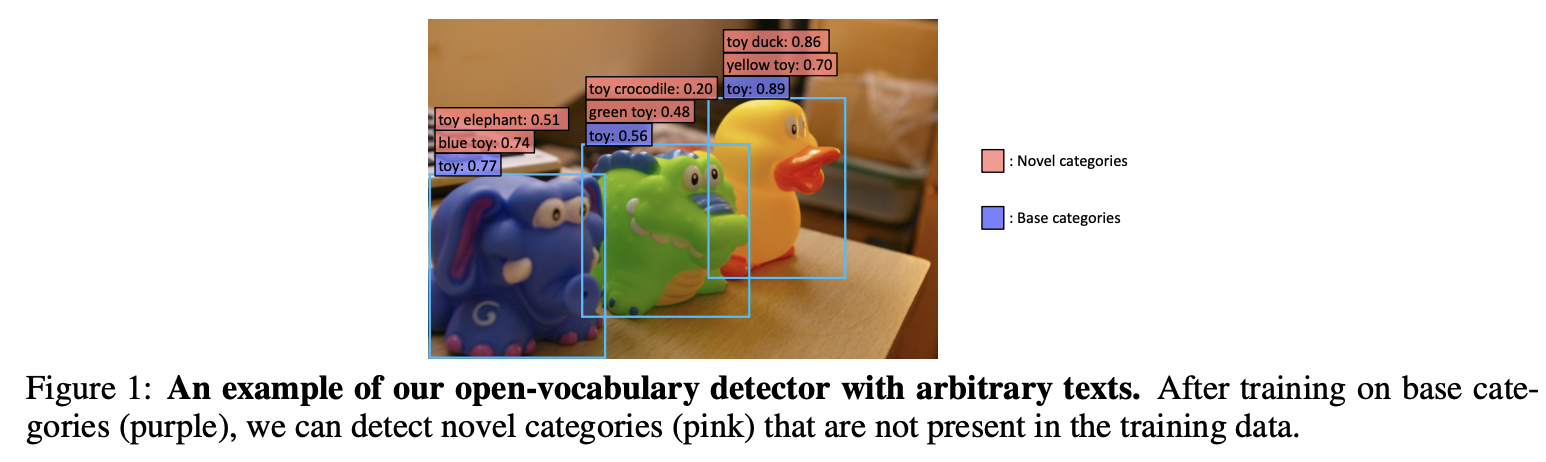
Examples
-
ViLD (https://arxiv.org/pdf/2104.13921) (ICLR 2022)
-
Title: Open-vocabulary object detection via vision and language knowledge distillation
-
Goal: Advancing open-vocabulary two-stage object detection
-
Proposal: ViLD = Vision and Language knowledge Distillation
-
Distills (teacher) VLM knowledge to a (student) two-stage detector,
whose embedding space is enforced to be consistent with that of CLIP image encoder
-
-
How? Distills the knowledge from (teacher) to (student)
- (Teacher) Pretrained open-vocabulary image classification model
- (Student) Two-stage detector
-
Teacher encoder: Encode category texts & image regions of object proposals.
-
Student detector: Region embeddings of detected boxes are aligned with the text and image embeddings inferred by the teacher
-
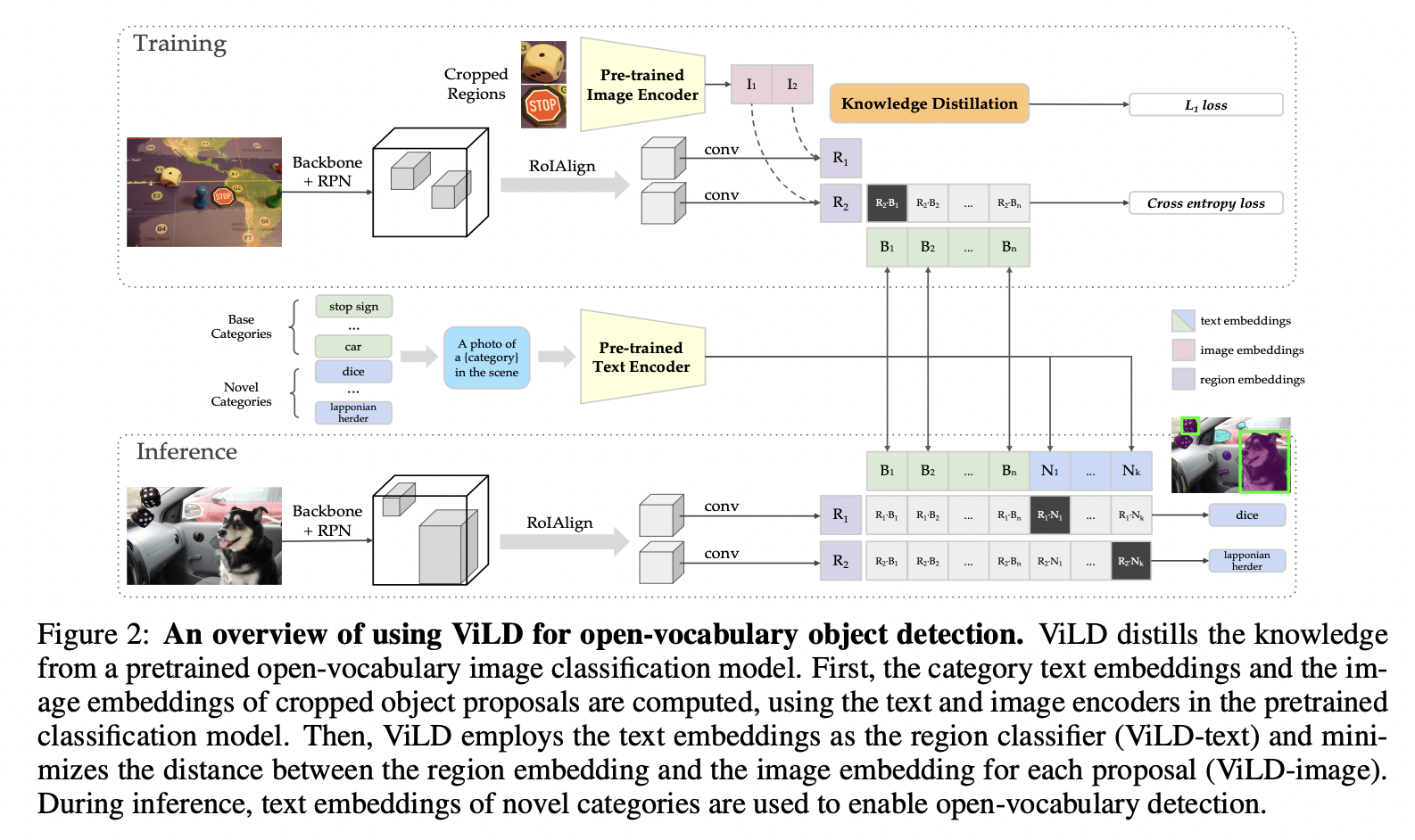
-
HierKD (https://arxiv.org/pdf/2203.10593) (CVPR 2022)
-
Title: Open-vocabulary one-stage detection with hierarchical visual-language knowledge distillation
-
Goal: Advancing open-vocabulary object one-stage detection
-
Previous works)
-
(1) Two-stage detectors
- Employ instance-level visual-to-visual knowledge distillation to align the visual space of the detector with the semantic space of pretrained VLM
-
(2) One-stage detector
-
Absence of class0agnostic object proposals
\(\rightarrow\) Hinders the knowledge distillation on unseen objects
-
-
-
Proposal: HierKD = Hierarchical visual-language knowledge distillation
- Key Idea: Explores hierarchical global-local KD
-
Details
-
Explores hierarchical global-local KD of unseen categories
-
Combine the (proposed) global-level KD & (common) instance-level KD
\(\rightarrow\) To learn the knowledge of both seen and unseen categories
-
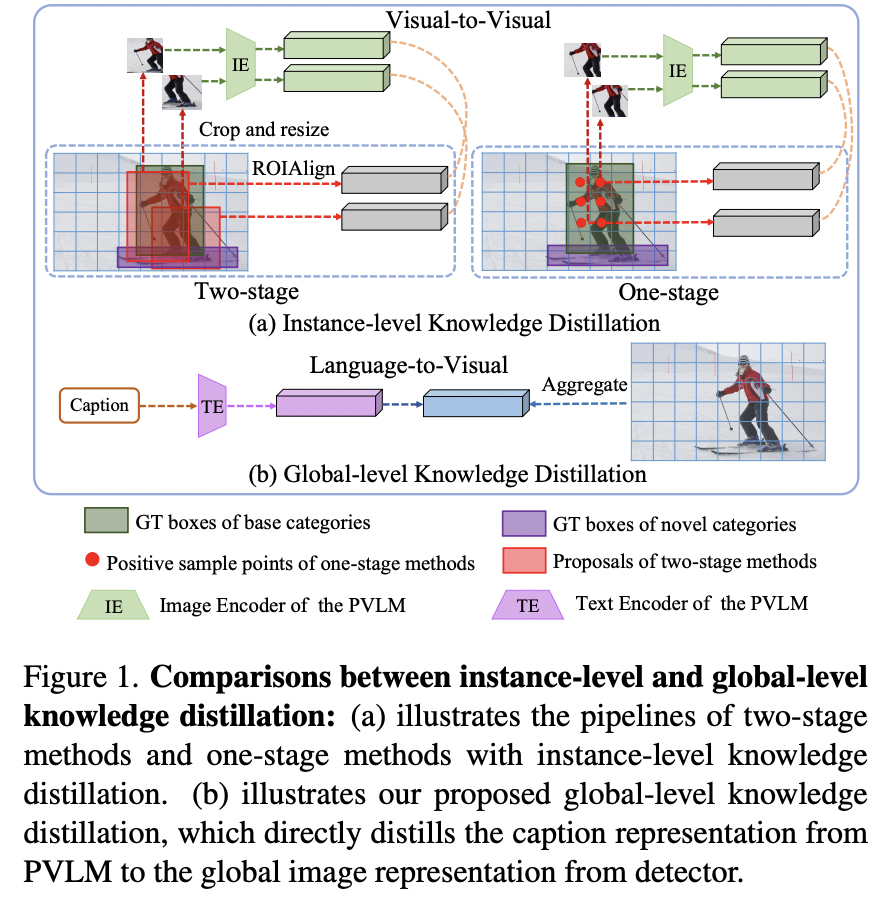
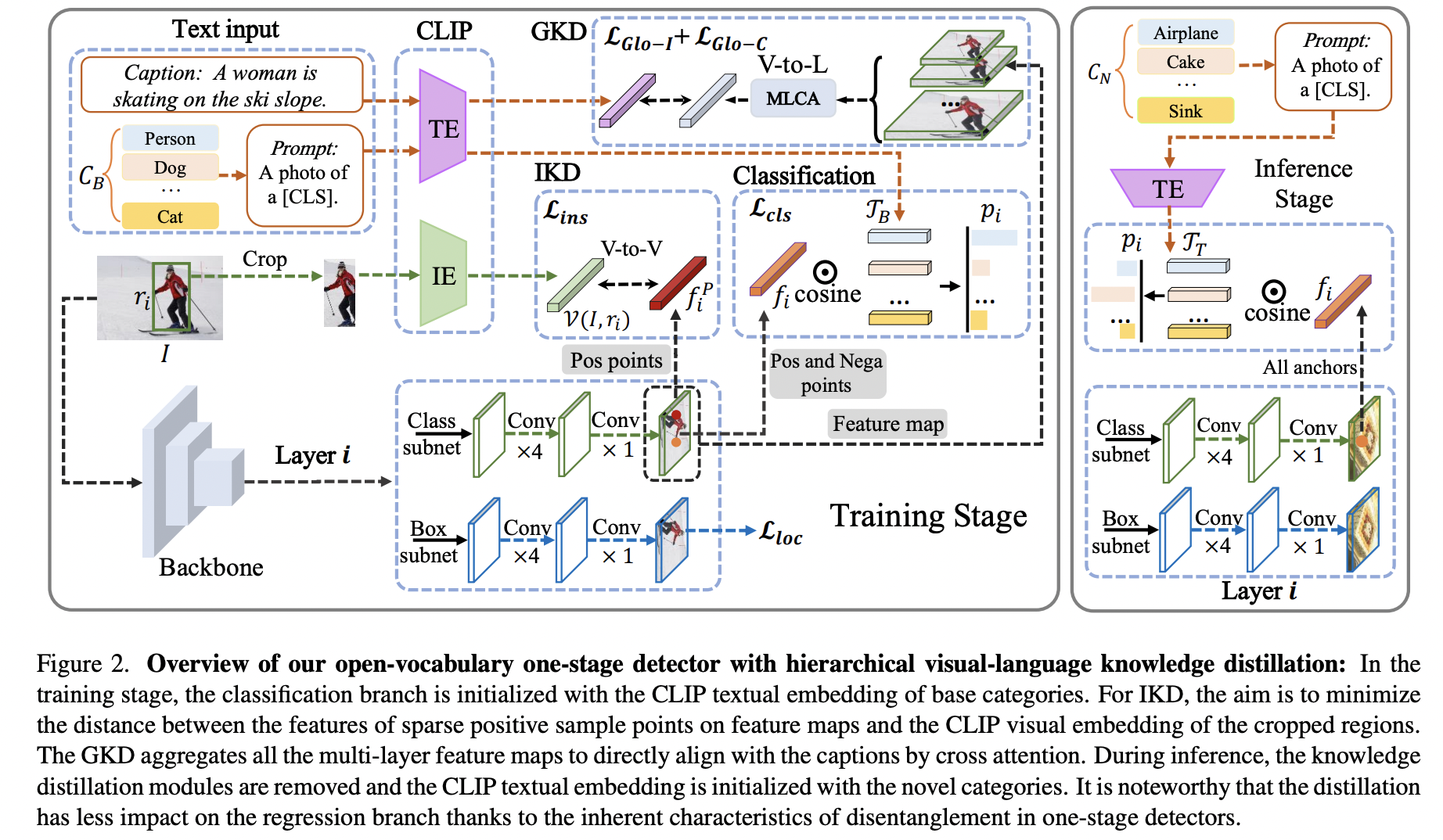
-
- RKD (https://arxiv.org/pdf/2207.03482) (NeurIPS 2022)
- Title: Bridging the gap between object and imagelevel representations for open-vocabulary detection
-
Previous works) Open-vocabulary detection (OVD)
- Typically enlarge their vocabulary sizes by leveraging different forms of weak supervision
- Two popular forms of weak-supervision used in OVD
- (1) Pretrained CLIP
- (2) Image-level supervision
- Limitation
- (1) CLIP: Lacks precise localization of objects
- (2) Image-level supervision: Do not accurately specify local object regions
- Solution: Object-centric alignment of the language embeddings from CLIP
-
Proposal: RKD = Region-based KD
- Key Idea: Explores “region-based” KD for aligning region-level and image-level embeddings
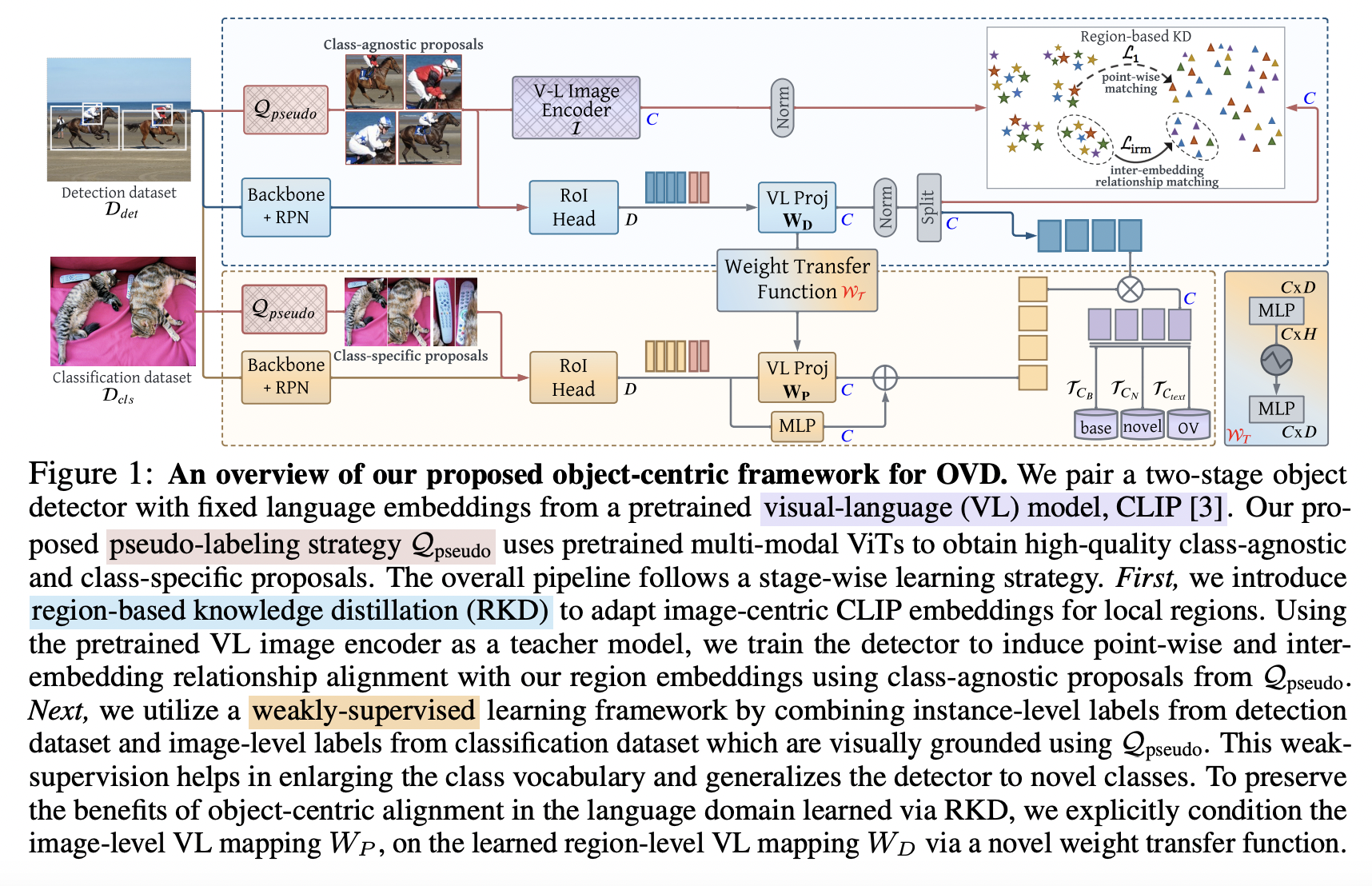
-
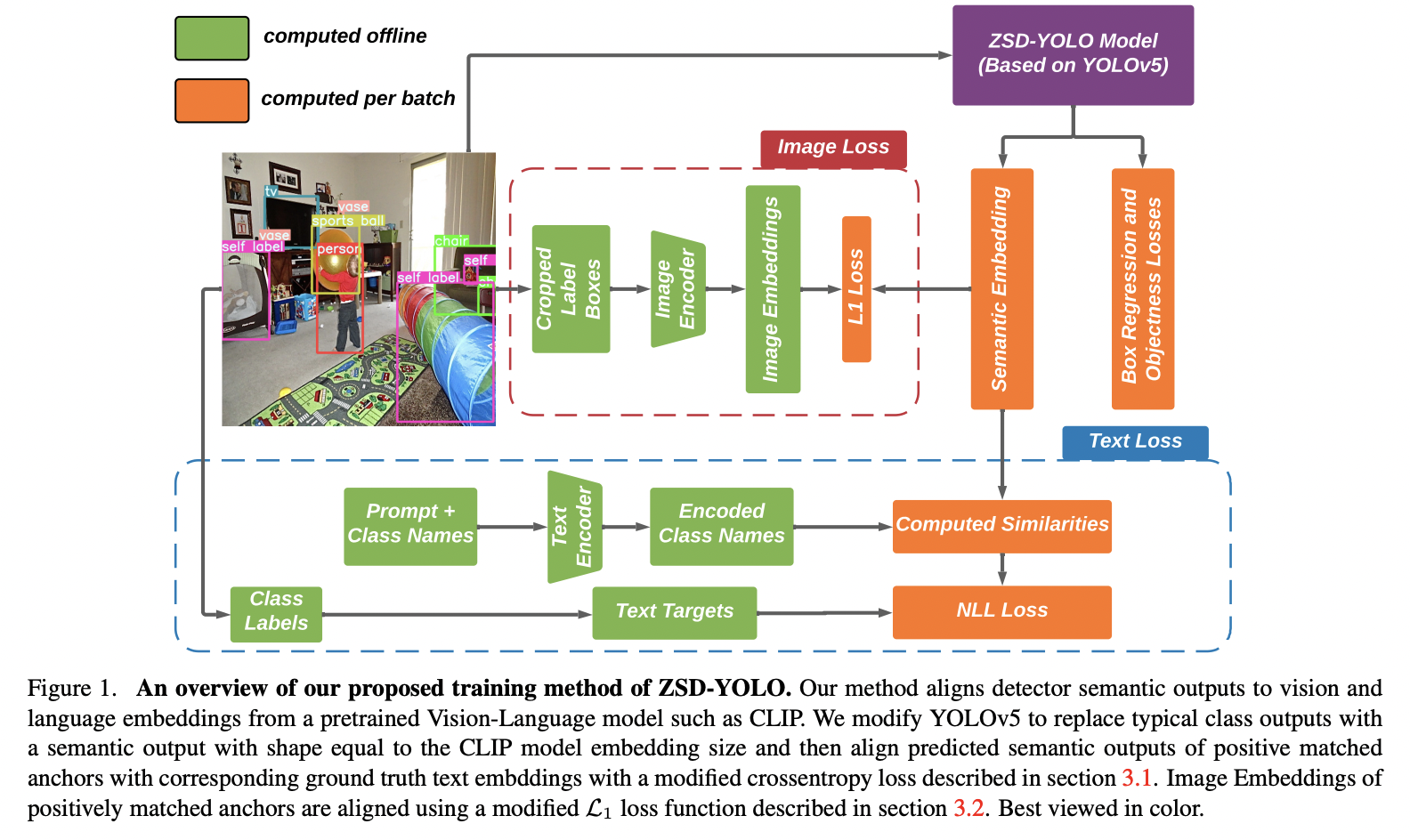
ZSD-YOLO (https://arxiv.org/pdf/2109.12066) (ICDMW 2022)
-
Title: Zero-shot Object Detection Through Vision-Language Embedding Alignment
-
Proposal: ZSD-YOLO =
- Key Idea: Self-labeling data augmentation for better object detection.
-
Task: Object detection = (1) + (2)
- (1) Non-semantic task = Localization
- (2) Semantic task = Classification
-
Propose Vision-language embedding alignment
-
Goal: To transfer (1) \(\rightarrow\) (2)
- (1) Generalization capabilities of a pretrained model (e.g., CLIP)
- (2) Object detector (e.g.,YOLOv5)
-
Proposed loss function
-
To align the image and text embeddings (from the pretrained model)
with the modified semantic prediction head (from the detector)
-
-
-
-
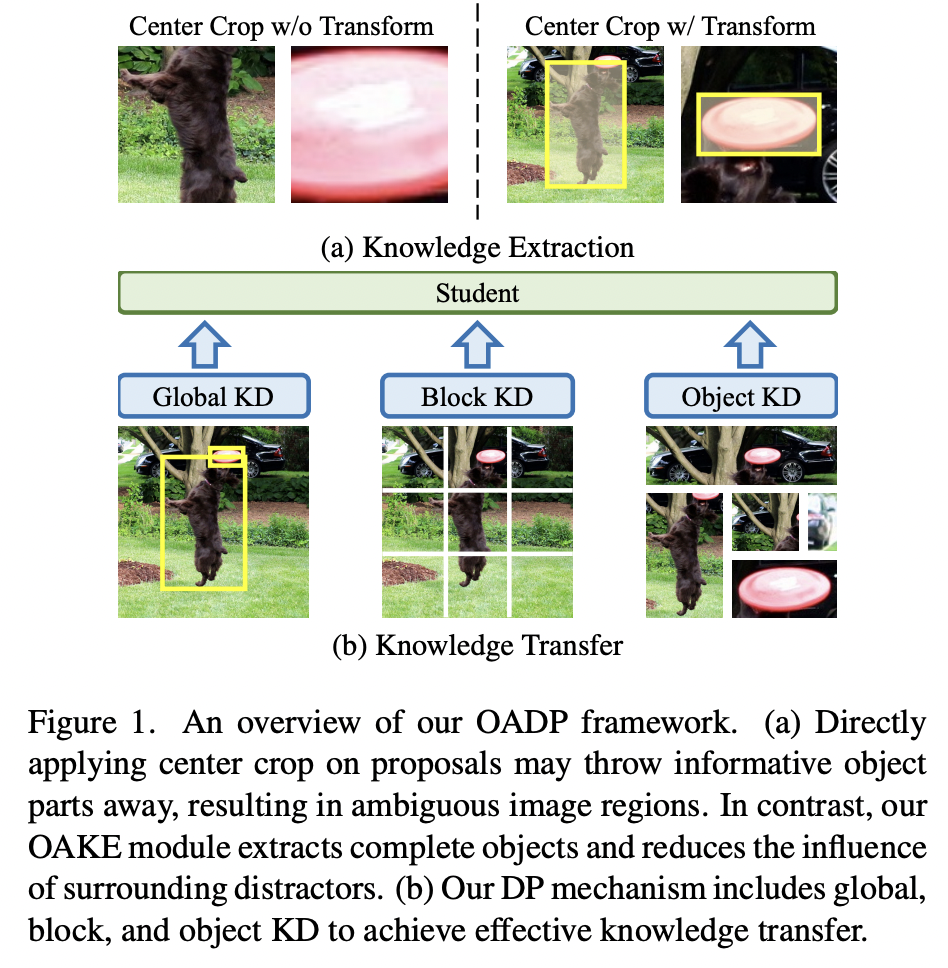
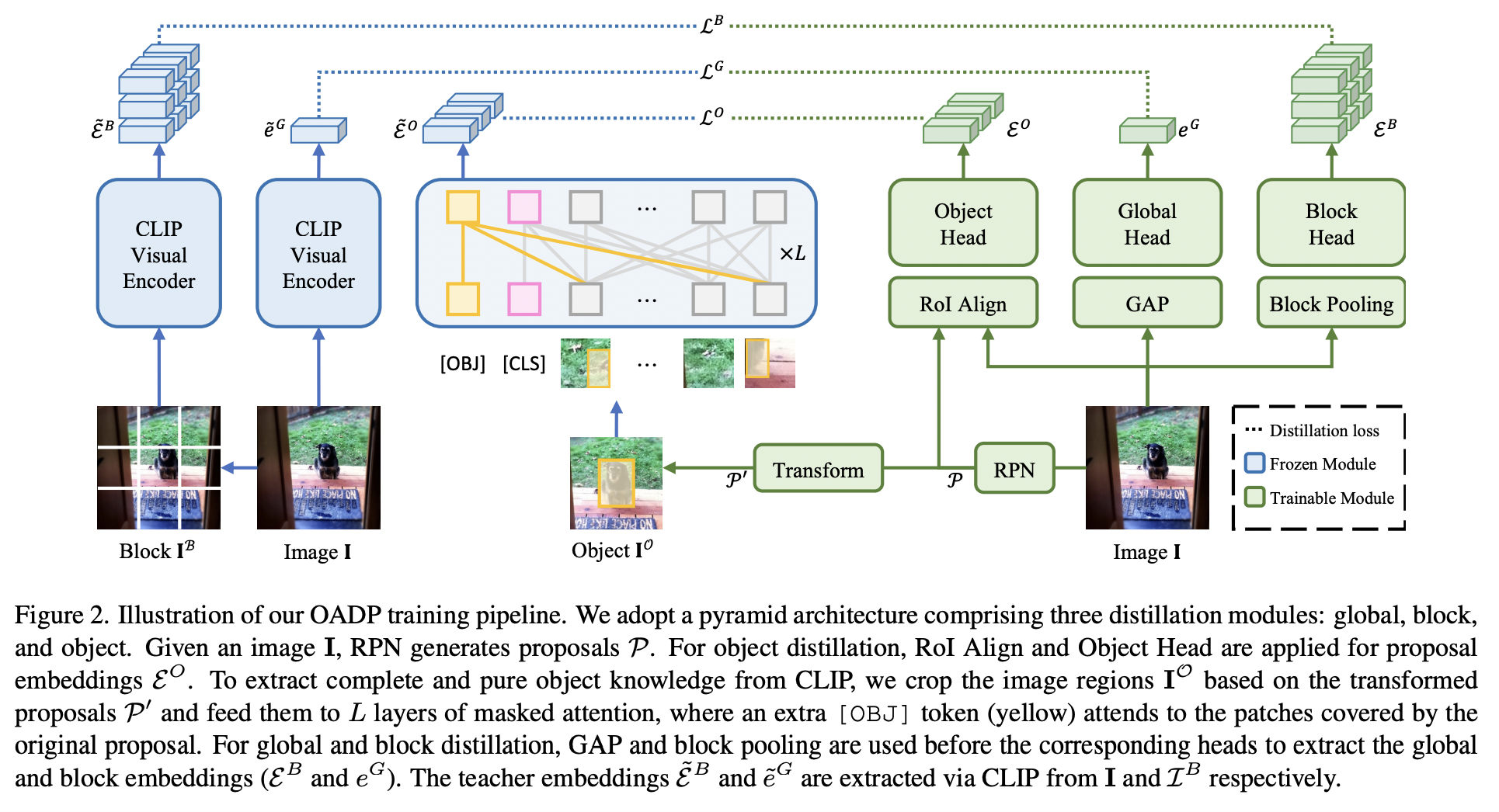
OADP (https://arxiv.org/pdf/2303.05892) (CVPR 2023)
-
Title: Object-aware distillation pyramid for openvocabulary object detection
-
Task: Open-vocabulary object detection
-
Previous methods) KD to extract knowledge from pretrained VLMs & transfer it to detectors
\(\rightarrow\) Non-adaptive proposal cropping & single-level feature mimicking processes
-
- Proposal: OADP = Object-Aware Distillation Pyramid
- Two modules
- (1) Object-Aware Knowledge Extraction (OAKE) module
- Adaptively transforms object proposals
- Adopts object-aware mask attention to obtain precise and complete knowledge of objects
- (2) Distillation Pyramid (DP) mechanism
- Global and block distillation
- To compensate for the missing relation information in object distillation
- (1) Object-Aware Knowledge Extraction (OAKE) module
-
-
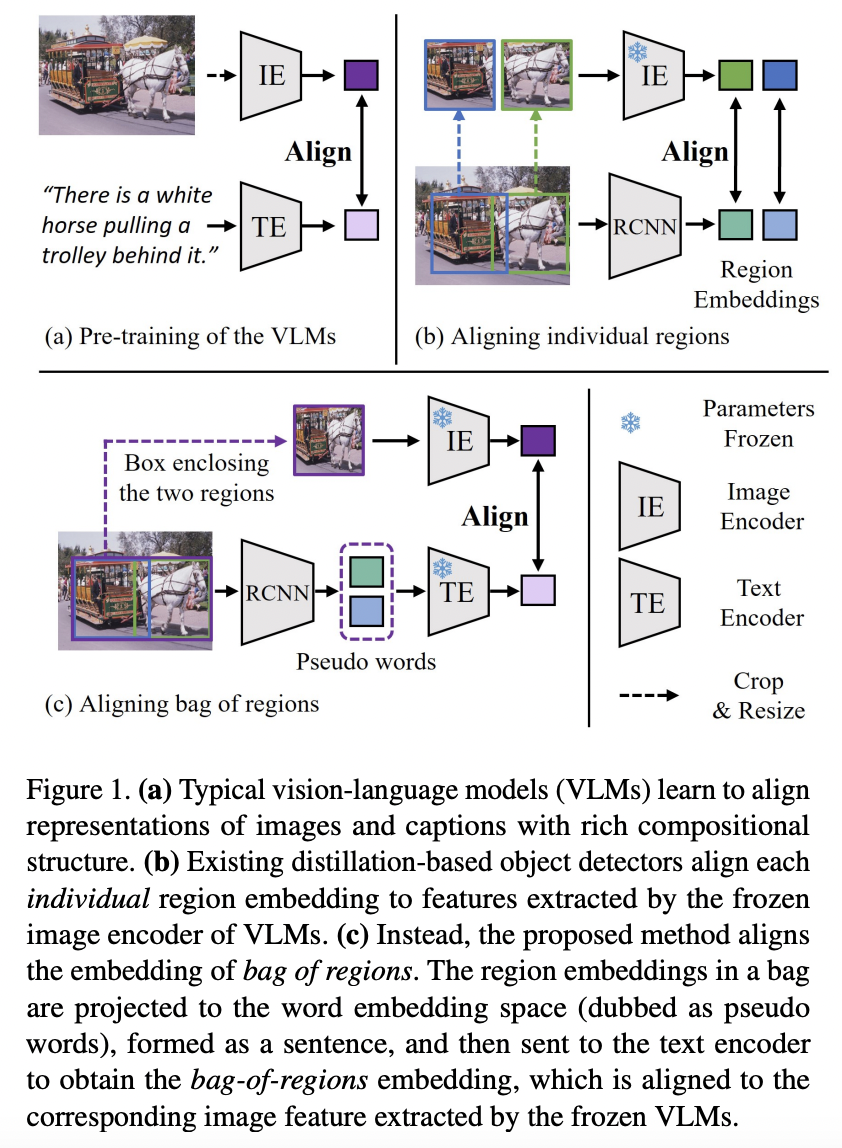
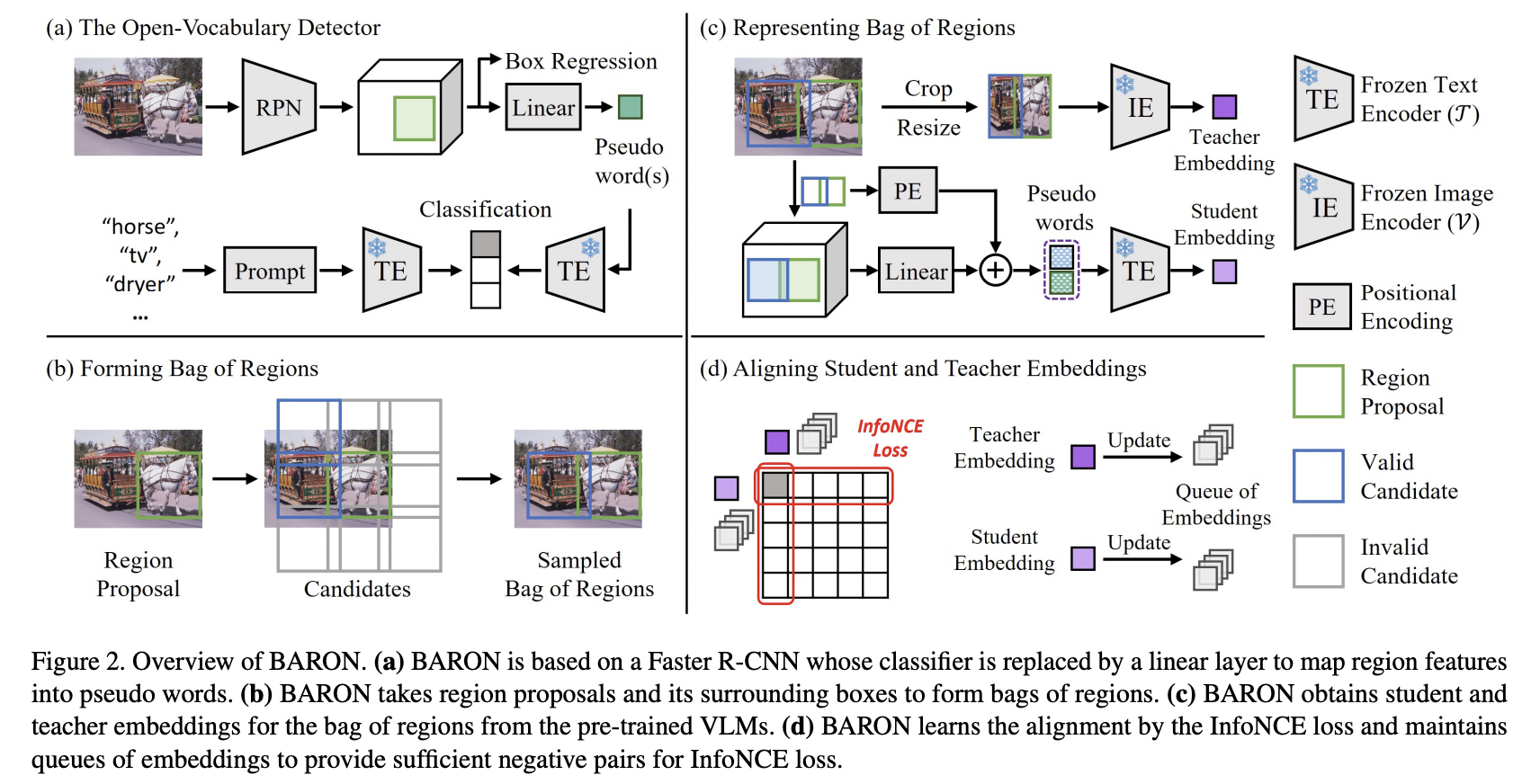
BARON (https://arxiv.org/pdf/2302.13996) (CVPR 2023)
-
Title: Aligning bag of regions for open-vocabulary object detection
-
Task: Open-vocabulary object detection
-
Existing works
- Only align region embeddings individually with the corresponding features extracted from the VLMs.
- Such a design leaves the compositional structure of semantic concepts in a scene under-exploited, although the structure may be implicitly learned by the VLMs.
-
Proposal: BARON = Bag of Regions
- Key idea: Uses neighborhood sampling to distill a bag of regions instead of individual regions.
-
Details
-
Align the embedding of bag of regions beyond individual regions
\(\rightarrow\) Groups contextually interrelated regions as a “bag”
-
Embeddings of regions in a bag = Embeddings of words in a sentence
-
-
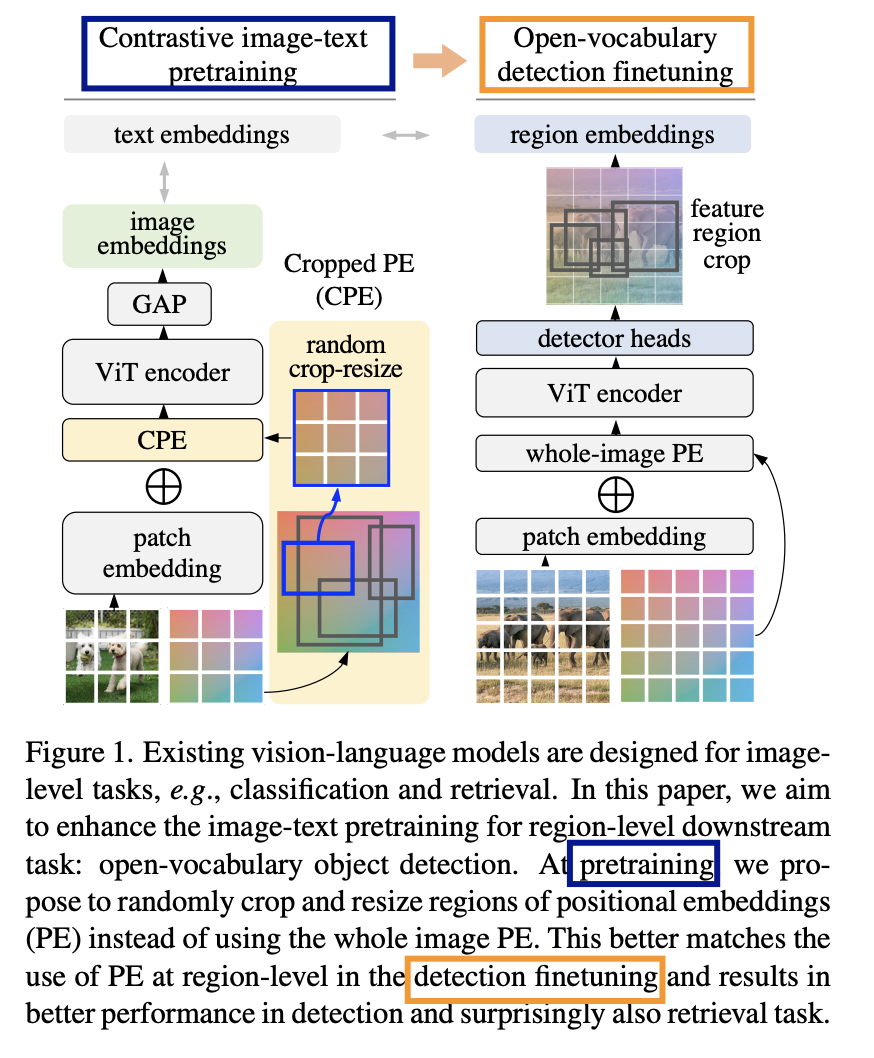
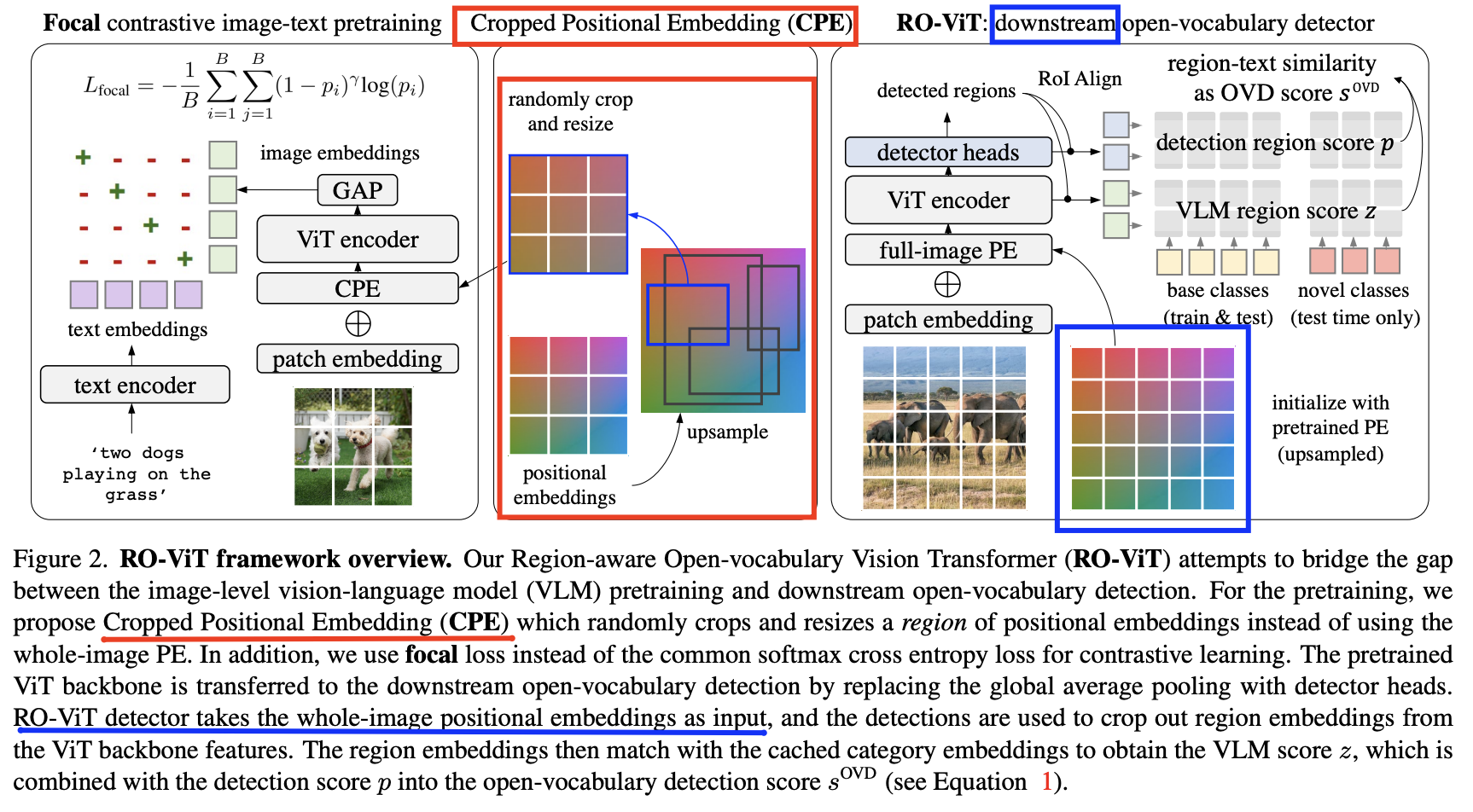
- RO-ViT (https://arxiv.org/pdf/2305.07011) (CVPR 2023)
- Title: Region-aware pretraining for open-vocabulary object detection with vision transformers
- Task: Open-vocabulary object detection
- Proposal: RO-ViT = Region-aware Open-vocabulary Vision Transformers (RO-ViT)
- Key idea: Distills regional information from VLMs
- Details
- Contrastive image-text pretraining
- Bridge the gap between (a) & (b)
- (a) Image-level pretraining
- (b) Open-vocabulary object detection
- (1) Positional Embedding
- Pretraining) Randomly crop and resize regions of “positional embeddings (PE)”
- Finetuning ) Use the whole image PE
- (2) Replacement: Softmax cross entropy loss (in CL) \(\rightarrow\) Focal loss
- (3) Novel object proposals to improve open-vocabulary detection finetuning.
Examples (distillation via prompt learning)
-
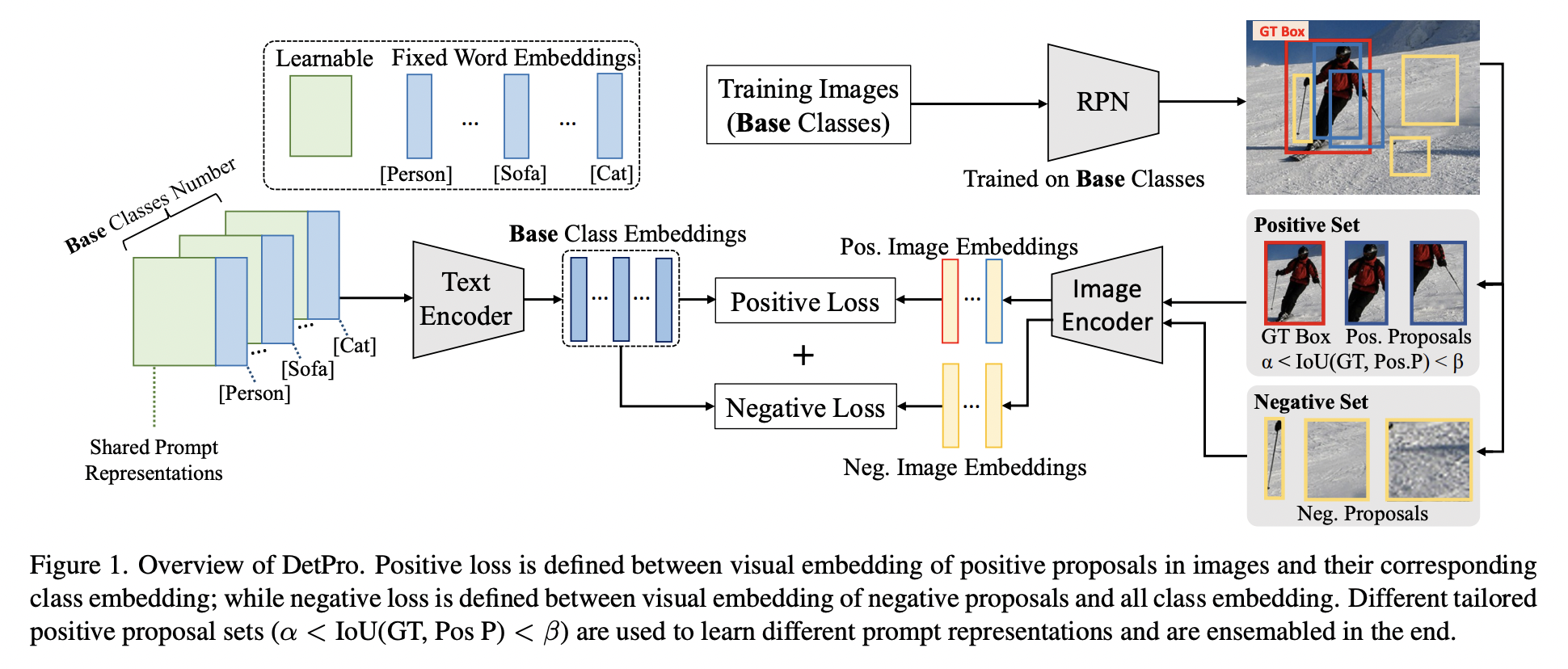
DetPro (https://arxiv.org/pdf/2203.14940) (CVPR 2022)
-
Title: Learning to prompt for open-vocabulary object detection with vision-language model
-
Task: Open-vocabulary object detection
\(\rightarrow\) Detectors trained on base classes are devised for detecting new classes
-
Previous works:
- Step 1) Embed class text embedding
- By feeding prompts to the text encoder (of a pre-trained VLMs)
- Step 2) Class text embedding = used as a region classifier
- To supervise the training of a detector
- Key element = Proper prompt
- Requires careful words tuning and ingenious design
- But, laborious prompt engineering!
- Step 1) Embed class text embedding
-
Proposal: DetPro = Detection Prompt
-
Key idea: Introduces a detection prompt technique
\(\rightarrow\) To learn continuous prompt representations!
-
-
Details
-
Goal: Learn continuous prompt representations for OVD based on pretrained VLMs
-
Two highlights:
-
(1) Background interpretation scheme
\(\rightarrow\) To include the proposals in image background into the prompt training
-
(2) Context grading scheme
\(\rightarrow\) To separate proposals in image foreground for tailored prompt training
-
-
-
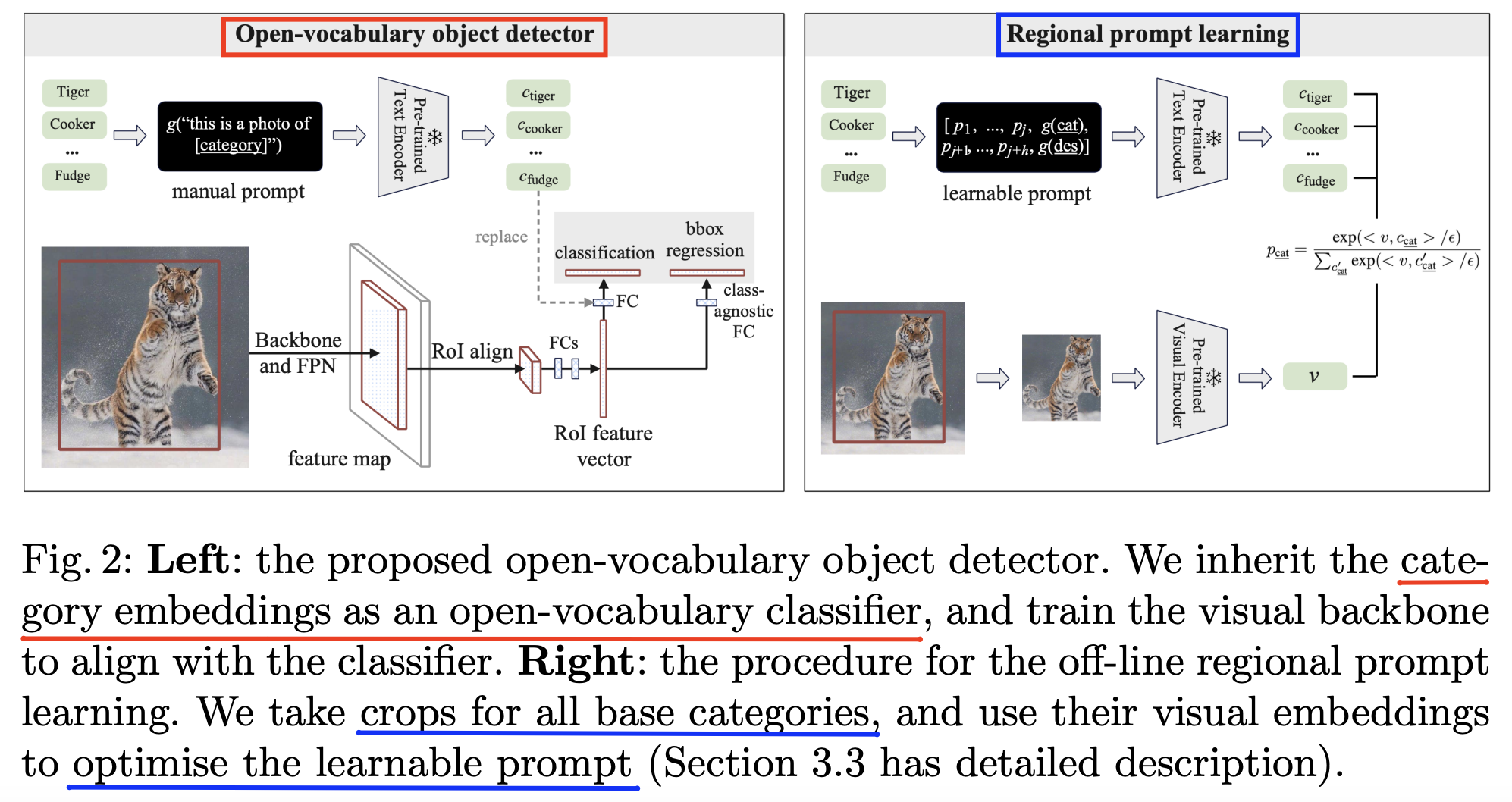
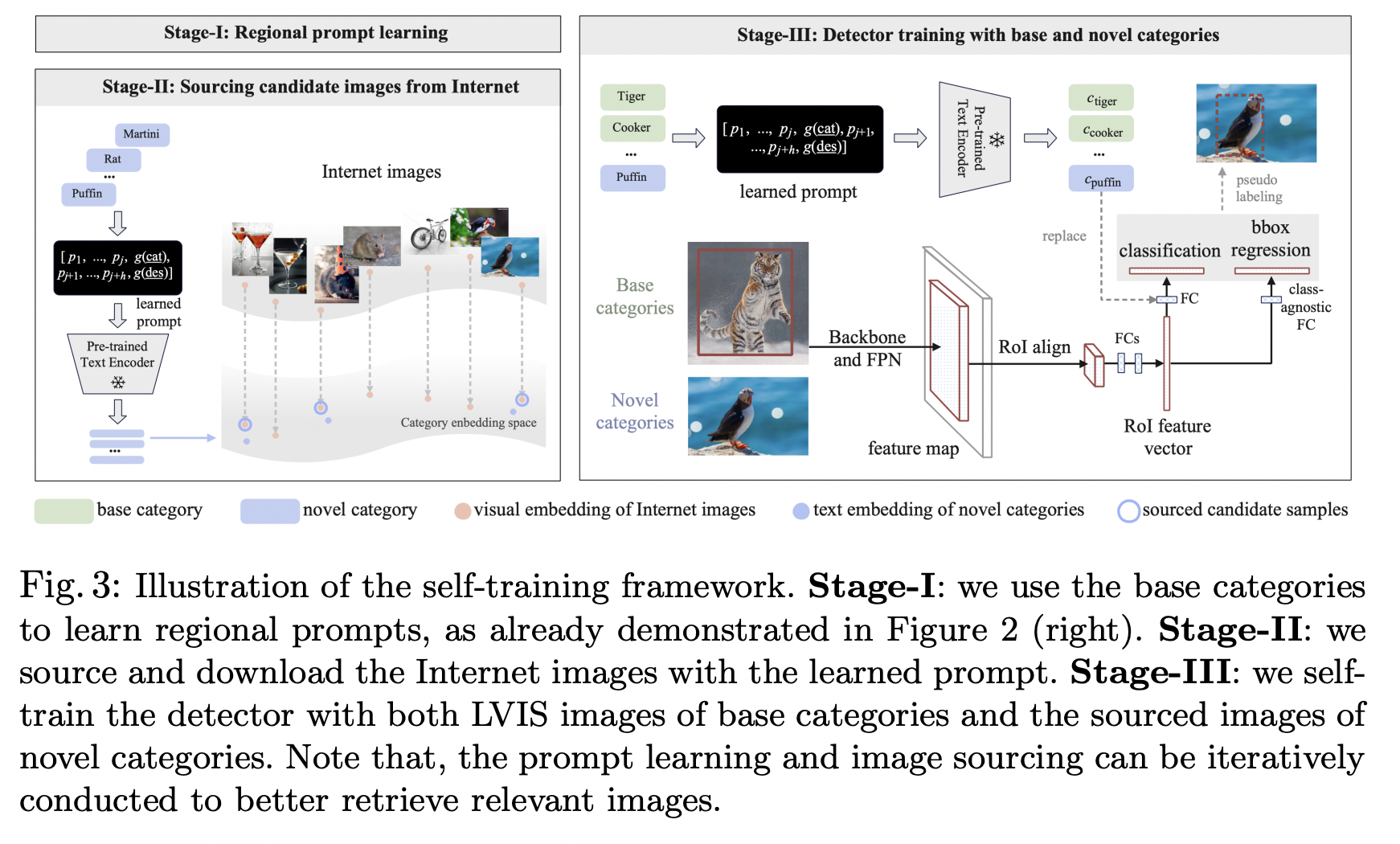
- PromptDet [188] (ECCV 2022)
- Title: Promptdet: Towards open-vocabulary detection using uncurated images
- Task: Open-vocabulary object detection
- Proposal: PromptDet =
- Key idea: Introduces regional prompt learning
- To aligning (1) word embeddings with (2) regional image embeddings
- Key idea: Introduces regional prompt learning
- Four contributions
- (i) Two-stage open-vocabulary object detector
- Class-agnostic object proposals are classified with a text encoder (from pretrained VLM)
- (ii) Regional prompt learning
- To align the textual embedding space & regional visual object features
- (iii) Available online resource via a self-training framework
- Allows to train the proposed detector on a large corpus of noisy uncurated web images
- (iv) Extensive experiments
- Challenging LVIS and MS-COCO dataset.
- (i) Two-stage open-vocabulary object detector

Examples (distillation via pseudo labeling)
-
PB-OVD (https://arxiv.org/pdf/2111.09452) (ECCV 2022)
-
Title: Open vocabulary object detection with pseudo bounding-box labels
-
Task: Open-vocabulary object detection
-
Previous) Only on a limited set of object categories
-
Recent) Open vocabulary and zero-shot detection methods
- By training on a pre-defined base categories to induce generalization to novel objects
\(\rightarrow\) Still constrained by the small set of base categories available for training
-
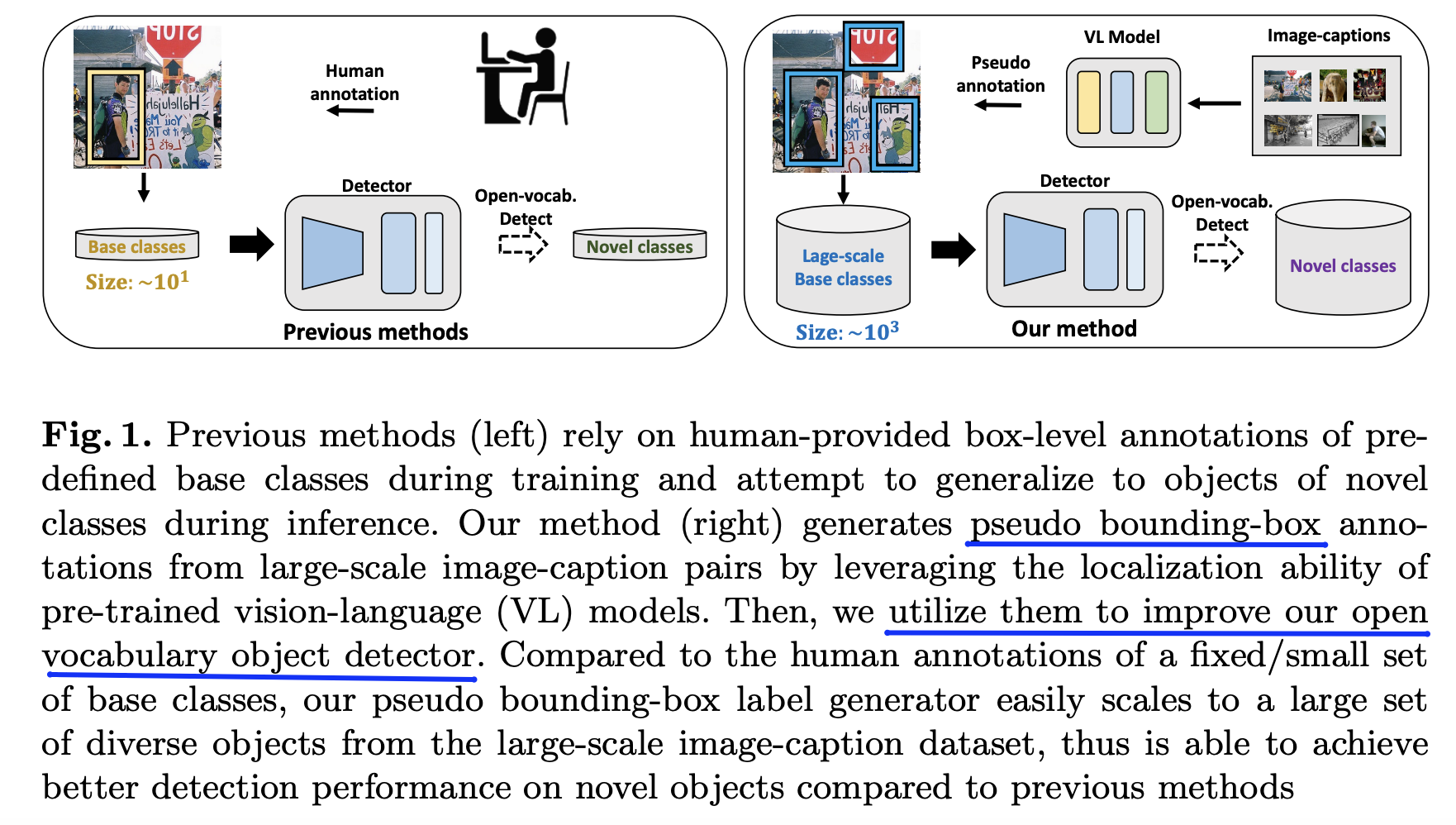
- Proposal: PB-OVD = Pseudo Bounding box OVD
- Key idea: Trains object detectors with “VLM-predicted pseudo bounding boxes”
- Details
- Automatically generate “pseudo bounding-box” annotations of diverse objects
- From large-scale image-caption pairs.
- To enlarge the set of base classes
- Leverages the localization ability of pre-trained VLMs to generate pseudo bounding-box labels
- Automatically generate “pseudo bounding-box” annotations of diverse objects
-
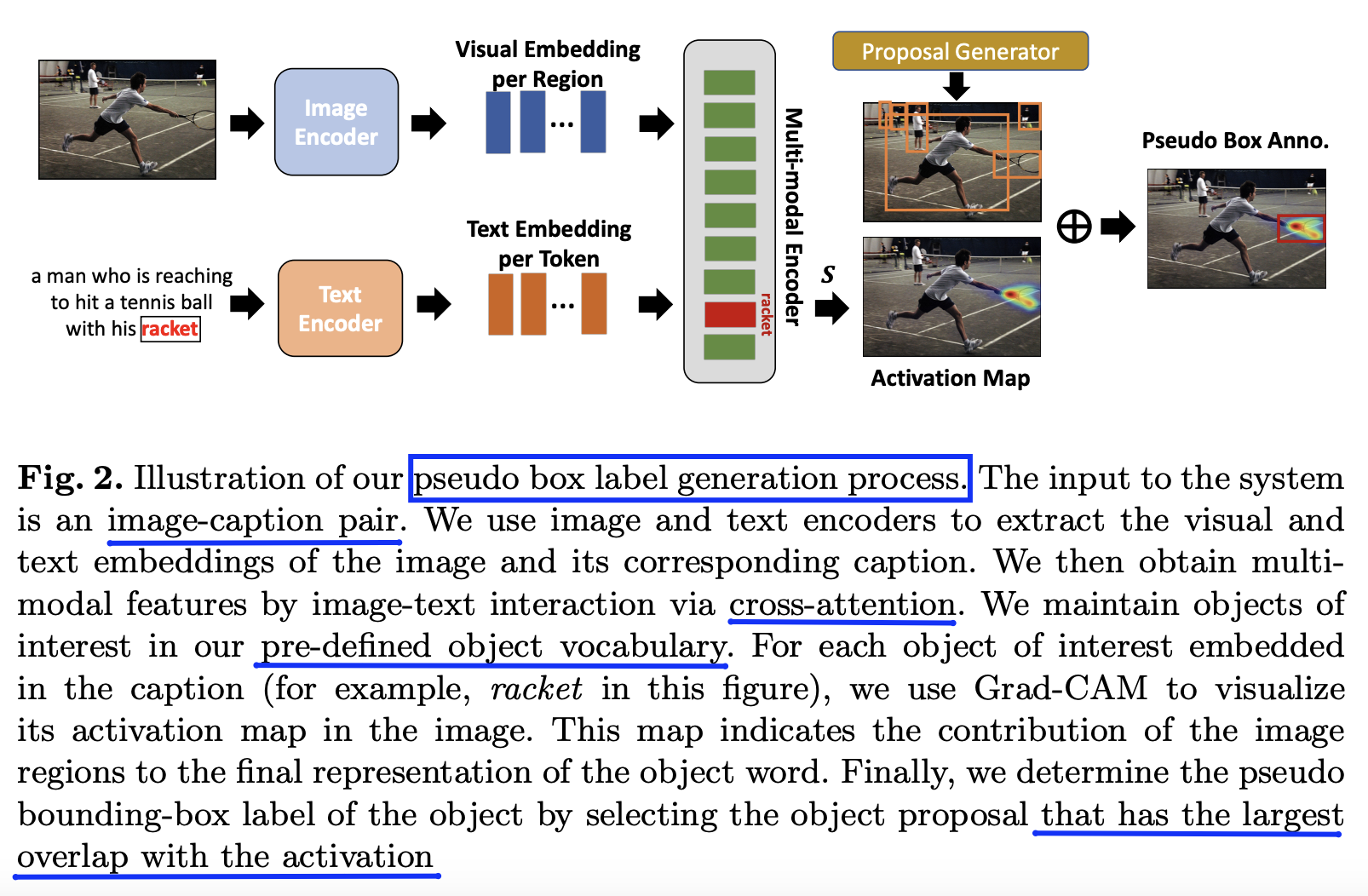
-
XPM (https://arxiv.org/pdf/2111.12698) (CVPR 2022)
-
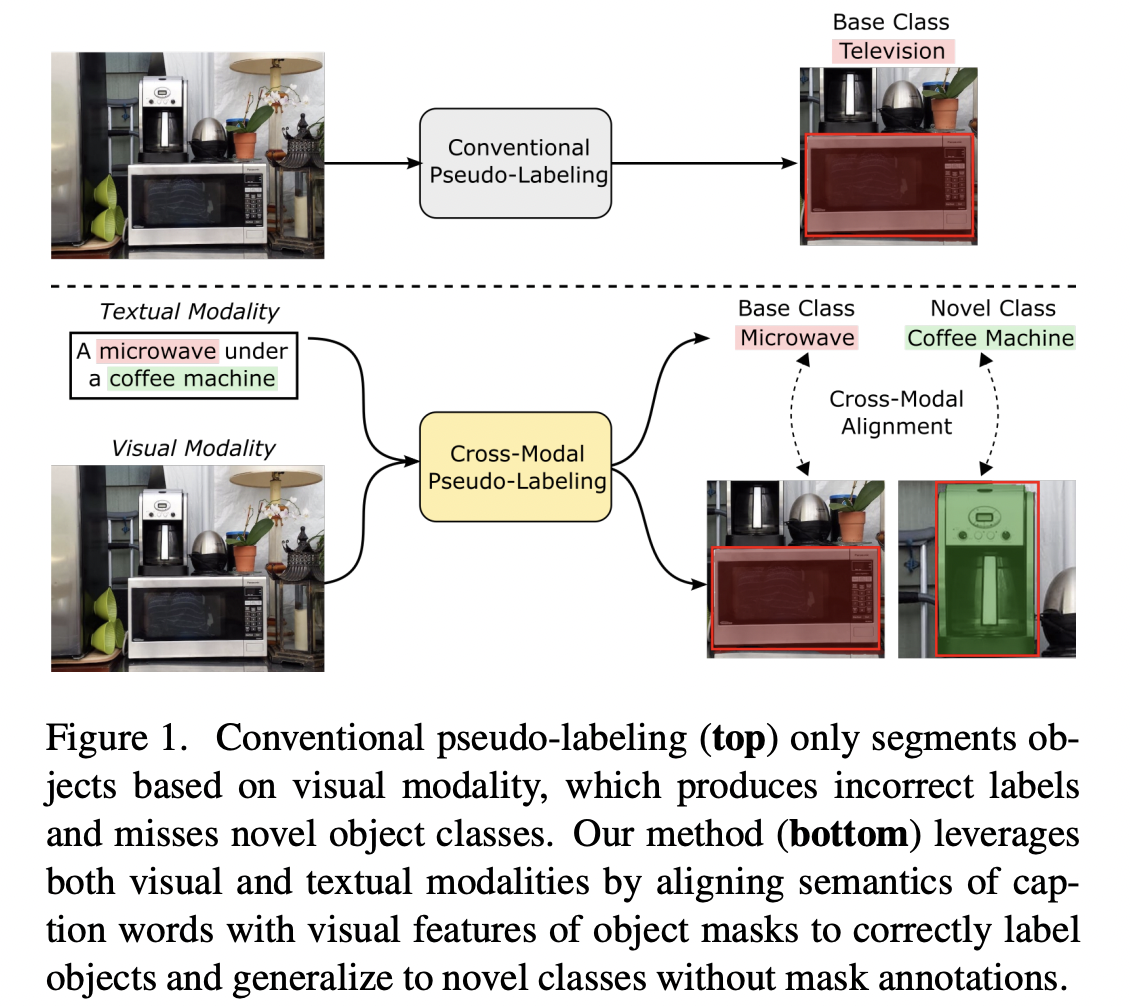
Title: Open-vocabulary instance segmentation via robust cross-modal pseudo-labeling
-
Task: Open-vocabulary instance segmentation
-
Goal: Aims at segmenting novel classes without mask annotations
-
Previous works:
- Step 1) Pretrain a model on captioned images covering many novel classes
- Step 2) Finetune it on limited base classes with mask annotations
\(\rightarrow\) Limitation of Step1) High-level textual information
- Cannot effectively encode the details (required for pixel-wise segmentation)
-
-
Proposal: XPM = Cross(X)-modal Pseudo Mask
- Key idea: Cross-modal pseudo-labeling framework
-
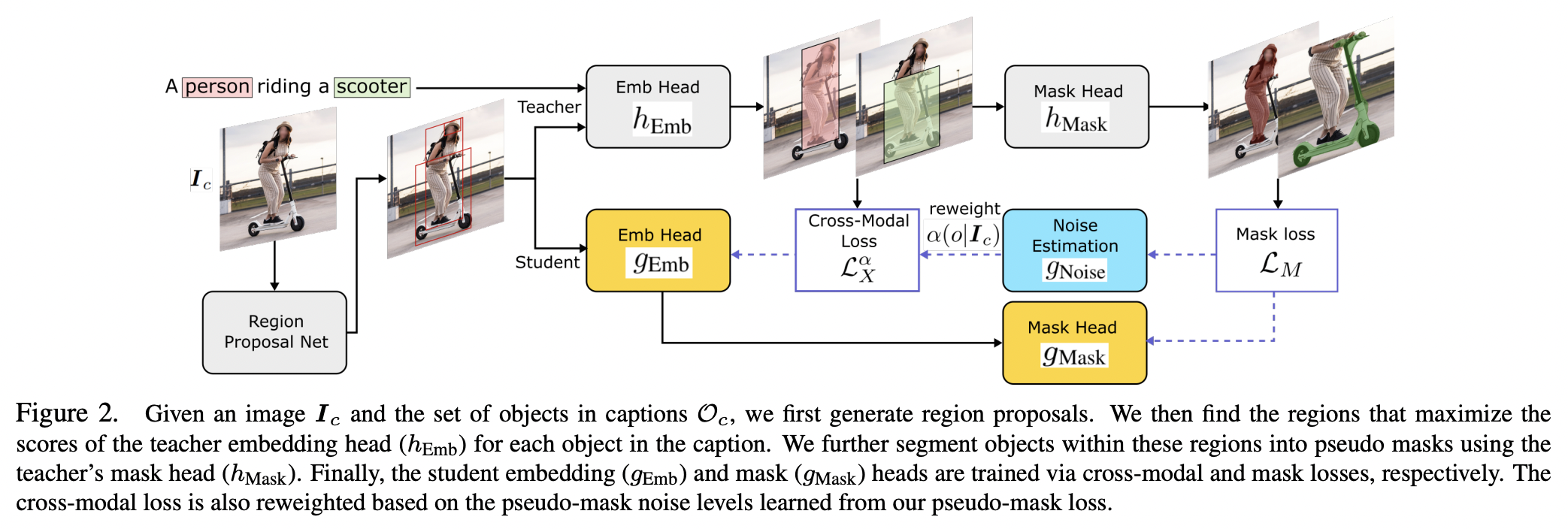
Architecture
-
Teacher model with…
- (1) Embedding head (for classification)
- (2) Class-agnostic mask head (for segmentation)
\(\rightarrow\) Distill the mask knowledge from teacher predictions and captions!
-
Student model
- Jointly learns from pseudo masks & Estimates mask noise levels to downweight unreliable pseudo masks!
-
-
Details:
-
Generates “training pseudo masks”. How?
- By aligning (1) word semantics in captions with (2) visual features of object masks in images
-
Capable of labeling novel classes in captions
-
Noises in pseudo masks ?
\(\rightarrow\) Robust student model that selectively distills mask knowledge
- By estimating the mask noise levels
-
-
P2) for Semantic Segmentation
KD for open-vocabulary semantic segmentation
- Leverages VLMs to enlarge the vocabulary of segmentation models
- Aaim to segment pixels described by arbitrary texts
Example
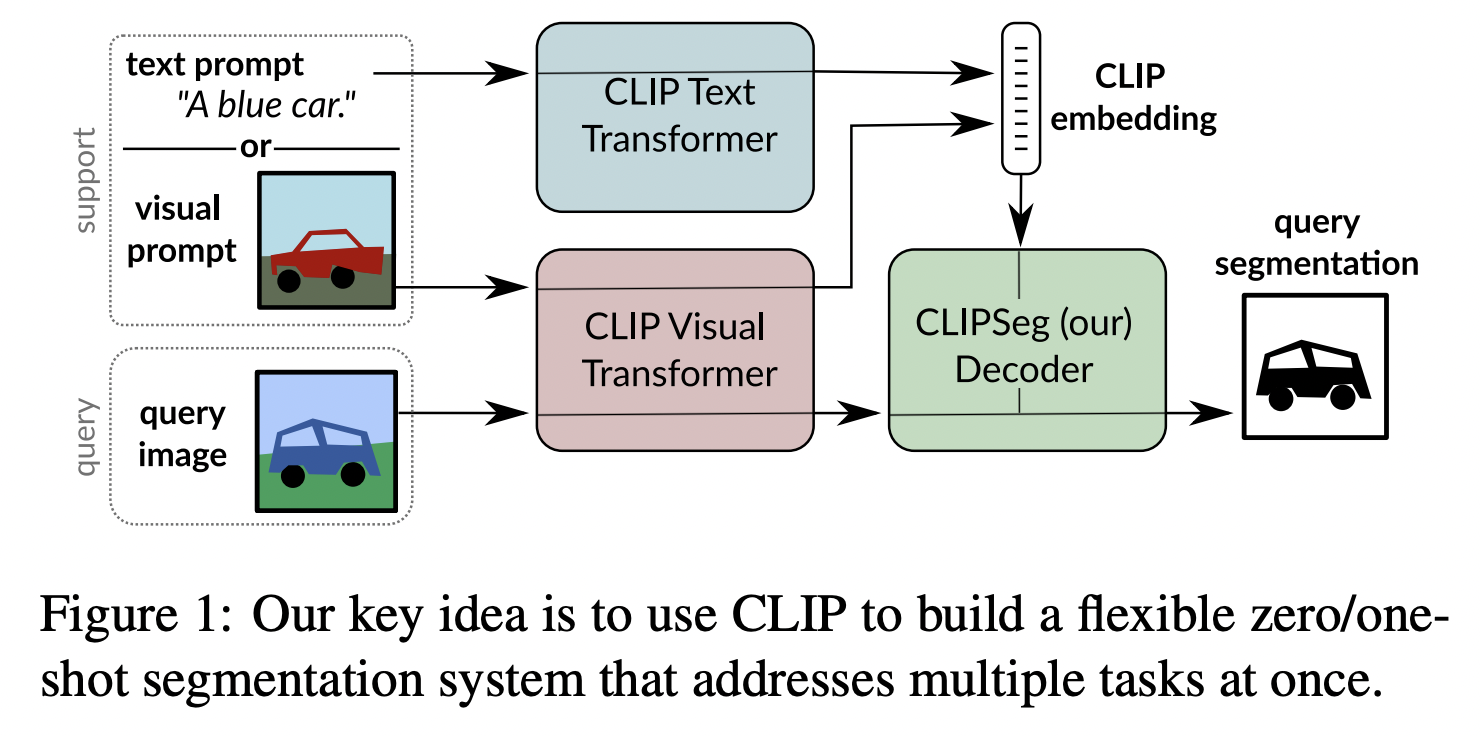
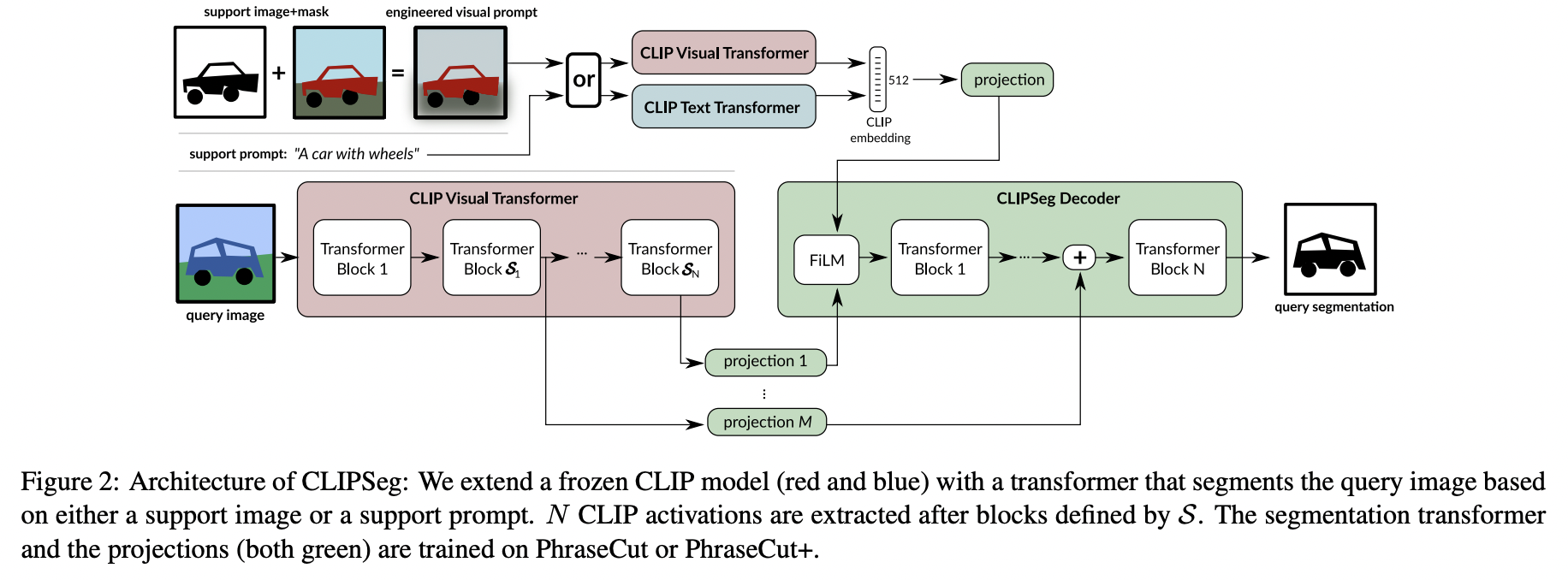
- CLIPSeg (https://arxiv.org/pdf/2112.10003) (CVPR 2022)
- Title: Image segmentation using text and image prompts
- Task: Semantic segmentation
- Proposal: CLIPSeg
- Key idea: Lightweight transformer decoder to extend CLIP for semantic segmentation
- Details
- Image segmentations based on “arbitrary” prompts at test time.
- Prompt: Either a text or an image
- Transformer-based decoder that enables dense prediction
- Image segmentations based on “arbitrary” prompts at test time.
-
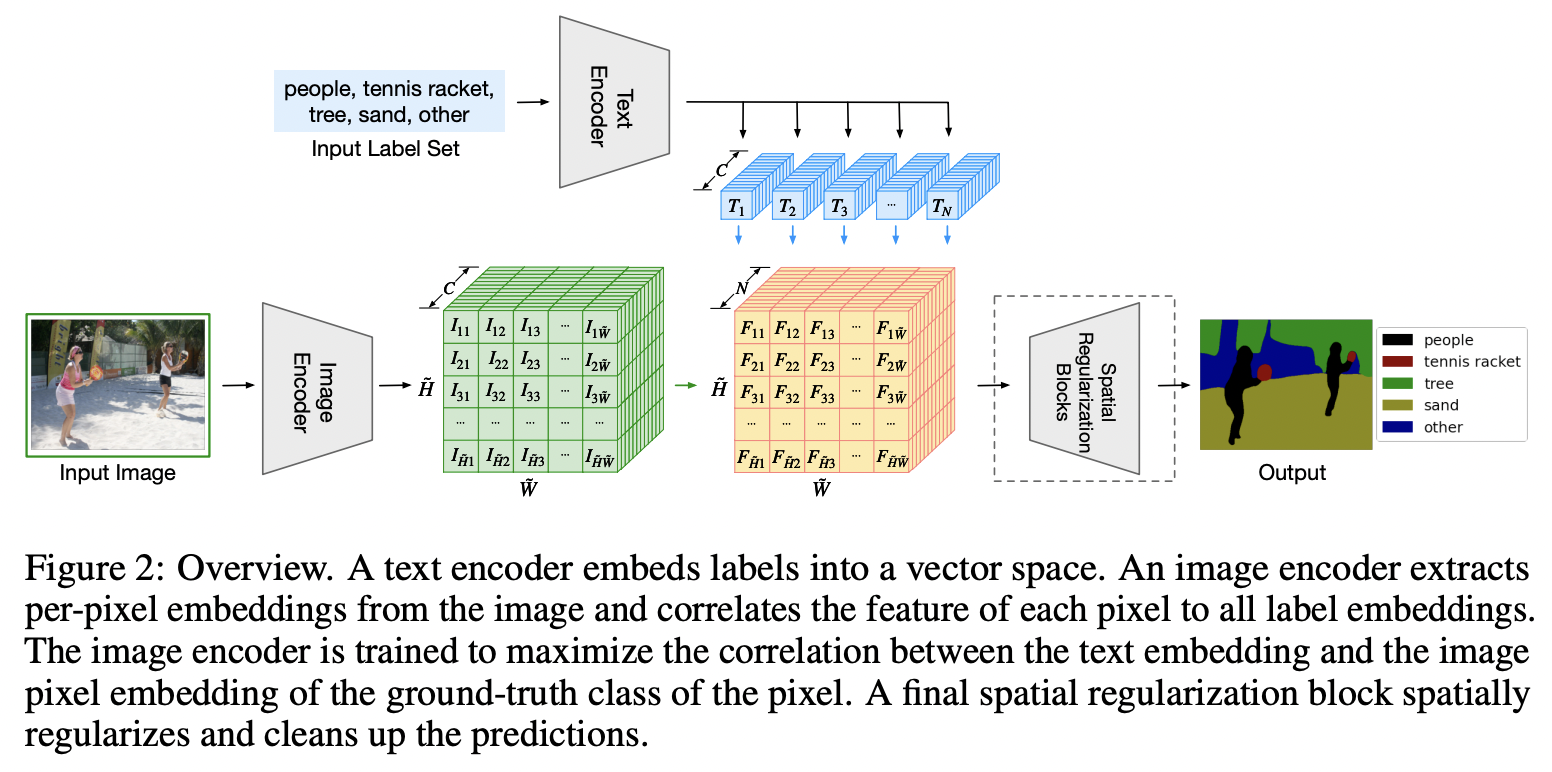
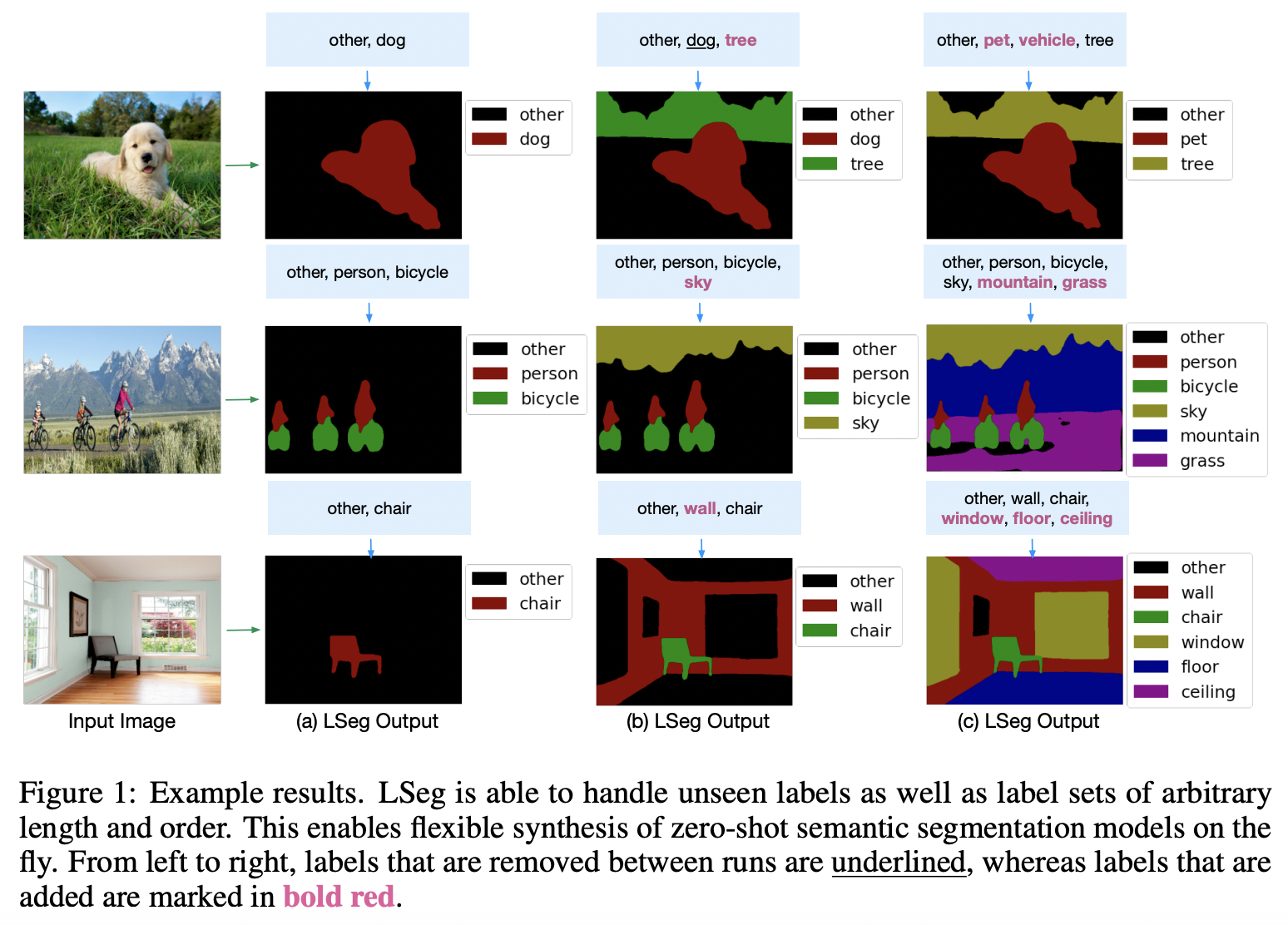
LSeg (https://arxiv.org/pdf/2201.03546) (ICLR 2021)
-
Title: Language-driven semantic segmentation
-
Proposal: LSeg = Language-driven semantic image segmentation
- Key idea: Maximizes the correlation between (1) & (2)
- (1) Text embeddings
- (2) Pixel-wise image embedding (encoded by segmentation models)
- Key idea: Maximizes the correlation between (1) & (2)
-
Details
-
Image encoder
- Trained with a contrastive objective
- To align pixel embeddings to the text embedding
-
Text embeddings
-
Provide a flexible label representation
\(\rightarrow\) Generalize to previously unseen categories at test time!
-
-
-
w/o retraining or requiring an additional training sample
-
-
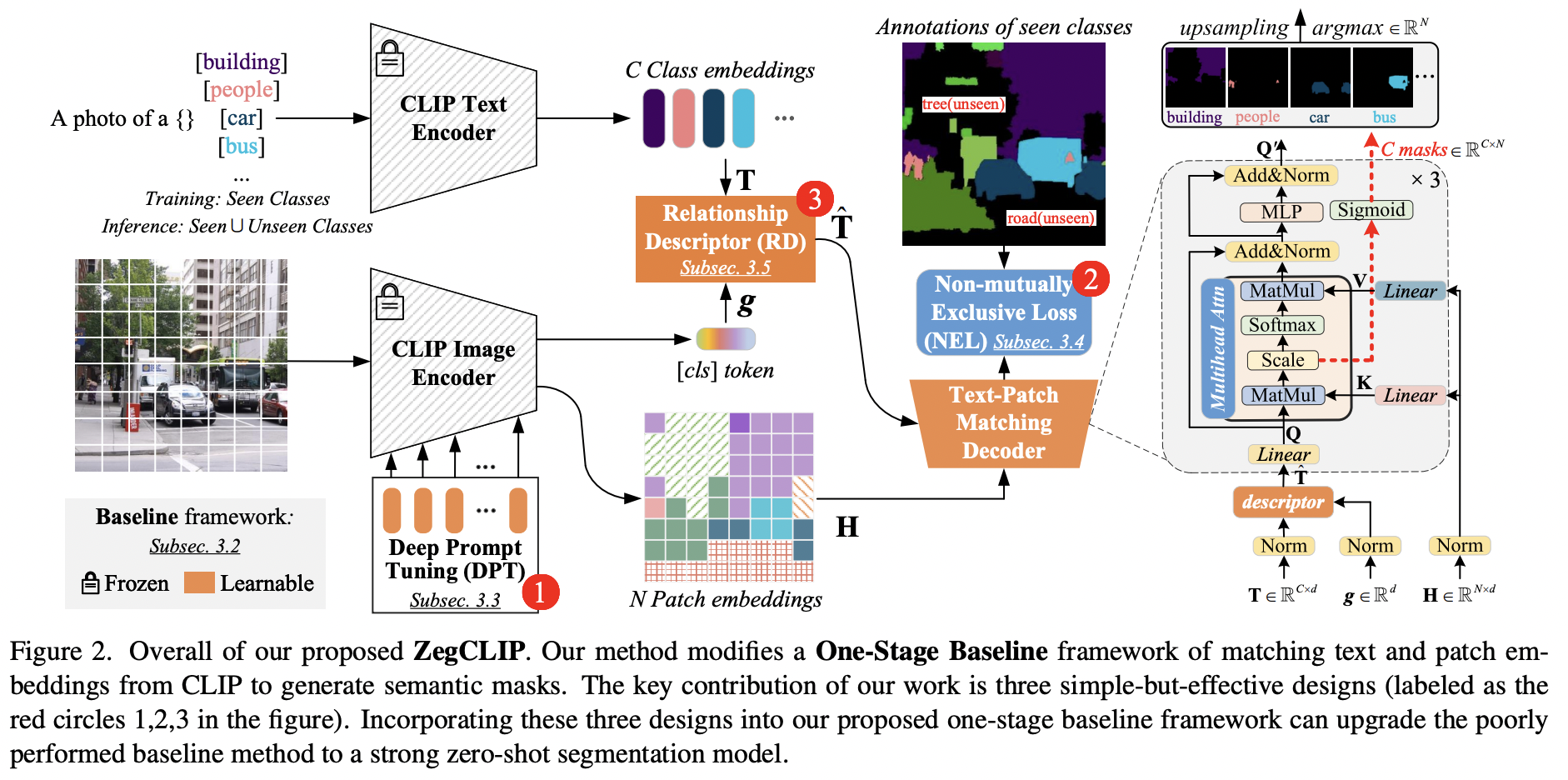
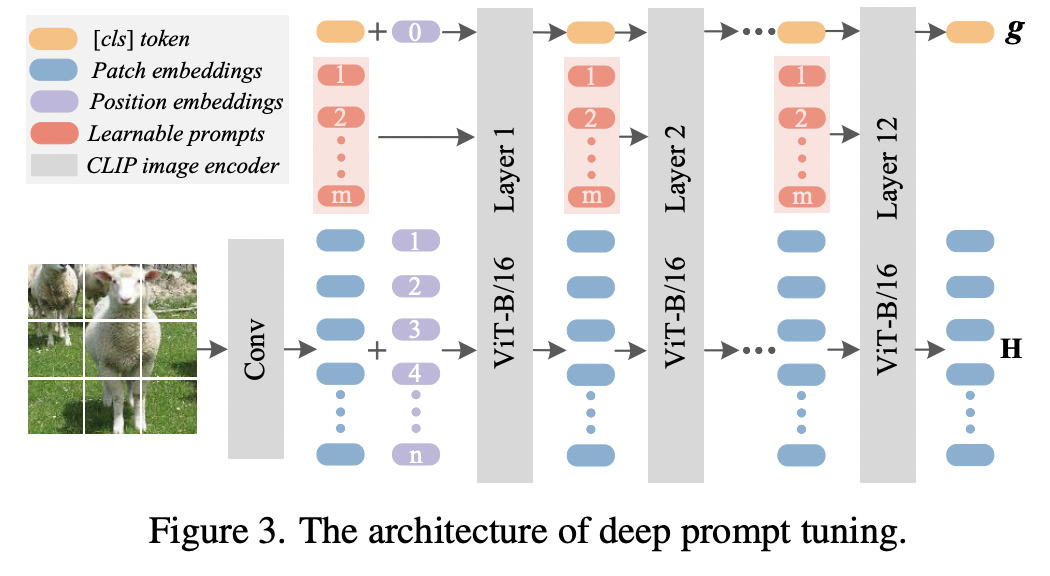
ZegCLIP (https://arxiv.org/pdf/2212.03588) (CVPR 2023)
-
Title: Zegclip: Towards adapting clip for zero-shot semantic segmentation
-
Task: Semantic segmentation
-
Previous works) CLIP has been applied to pixel-level zero-shot learning tasks via a two-stage scheme
- Step 1) Generate class-agnostic region proposals
- Step 2) Feed the cropped proposal regions to CLIP to utilize its image-level zero-shot classification
\(\rightarrow\) Requires two image encoders: a) For proposal generation & b) for CLIP
-
Proposal: ZegCLIP
- (1) Simpler-and-efficient one-stage solution
- (2) Employs CLIP to generate semantic masks
- (3) Introduces a relationship descriptor to mitigate overfitting on base classes
-
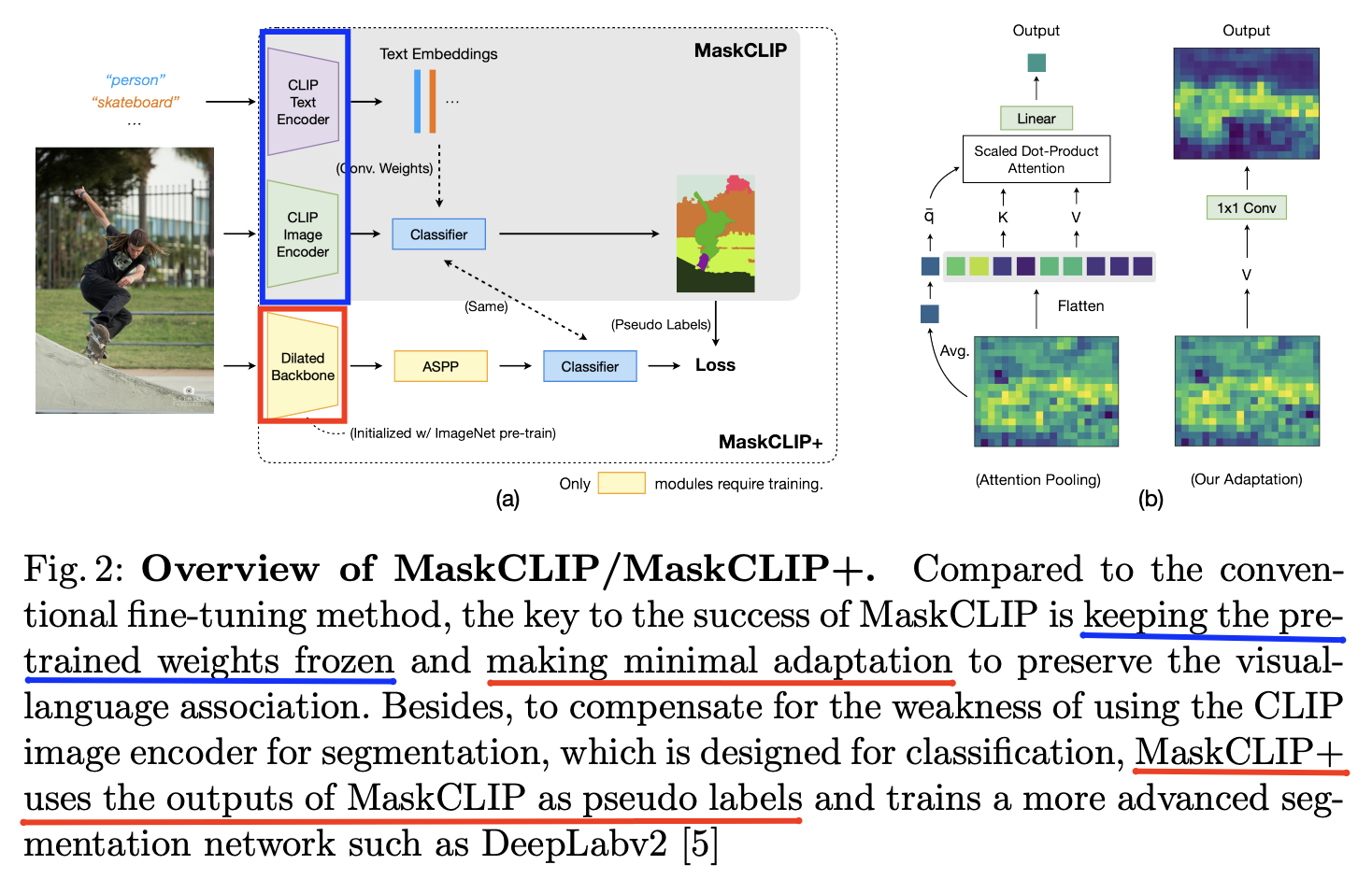
- MaskCLIP+ (https://arxiv.org/pdf/2112.01071) (ECCV 2022)
- Title: Extract free dense labels from CLIP
- Task: Semantic segmentation
- Proposal: MaskCLIP+
- Key idea: Distill knowledge with VLM-predicted “pixel-level” pseudo labels
- Examine the potential of CLIP for pixel-level dense prediction (e.g., semantic segmentation )
- Details
- Yields compelling segmentation results w/o annotations and fine-tuning
- Figure 2 (b): Modification to yield pixel-level mask predictions ( instead of a global image-level prediction )
- (1) Modify the image encoder of CLIP
- (1) Removing the query and key embedding layers
- (2) Reformulating the value-embedding layer and the last linear layer into two respective 1×1 convolutional layers.
- (2) Keep the text encoder unchanged!
- (1) Modify the image encoder of CLIP
- MaskCLIP +: MaskCLIP + pseudo labeling and self-training
- SSIW (https://arxiv.org/pdf/2112.03185) (arxiv 2021)
-
Title: Semantic segmentation in-the-wild without seeing any segmentation examples
-
Task: Semantic segmentation
- Supervised methods: Require many pixel-level annotations for every new class category
\(\rightarrow\) Images with rare class categories are unlikely to be well segmented!
-
Proposal: SSIW
- Key idea: Distill knowledge with VLM-predicted “pixel-level” pseudo labels
-
Details
- Creating semantic segmentation masks **w/o training segmentation networks **
- Input & Output
- (1) Input = Image-level labels
- Can be obtained automatically or manually
- (2) Output = Pixel-level pseudo-label
- Instead of the manual pixel-level labels
- (1) Input = Image-level labels
- Process
- Relevance Map Mining: Employ VLMs to create a rough segmentation map for each class
- Relevance Map Refinement: Using a test-time augmentation technique
- Given the pseudo-labels, we utilize single-image segmentation techniques to obtain high-quality output segmentation masks.
-
Proposal: SSIW
- Key idea: distill knowledge with VLM-predicted “pixel-level” pseudo labels
-
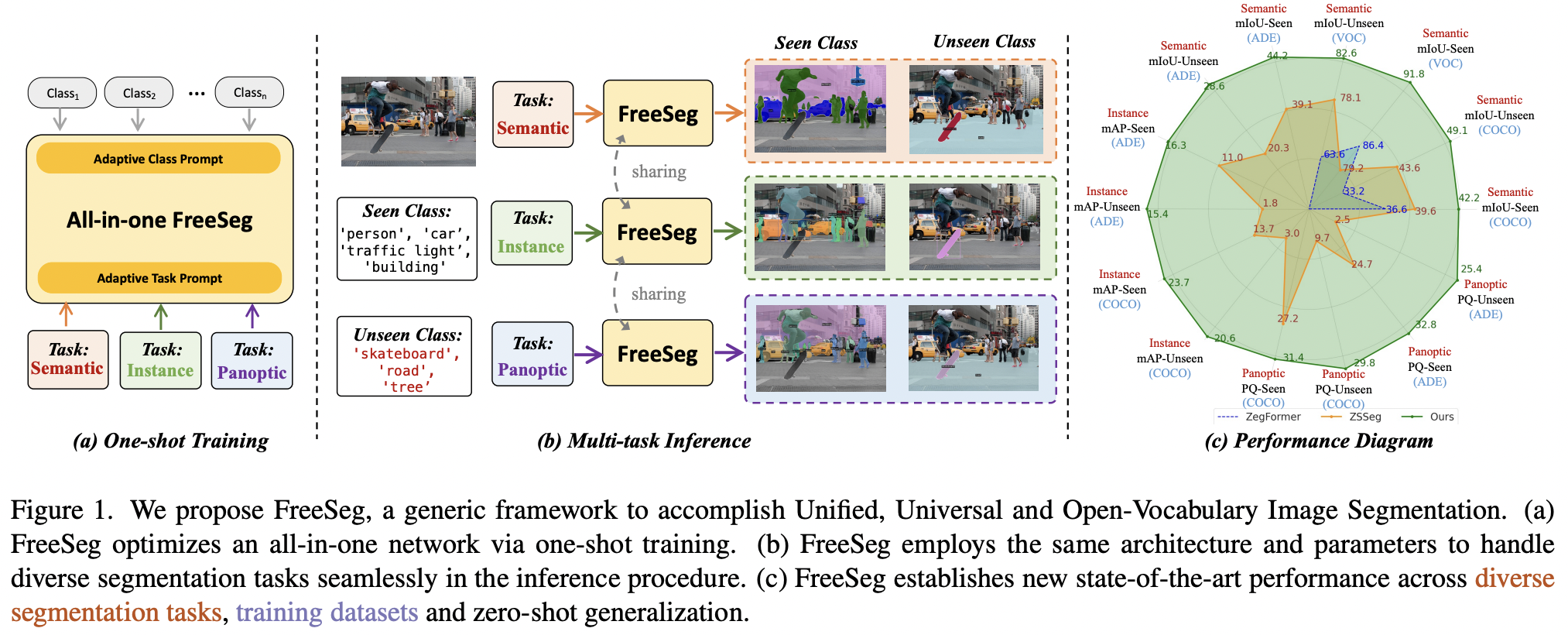
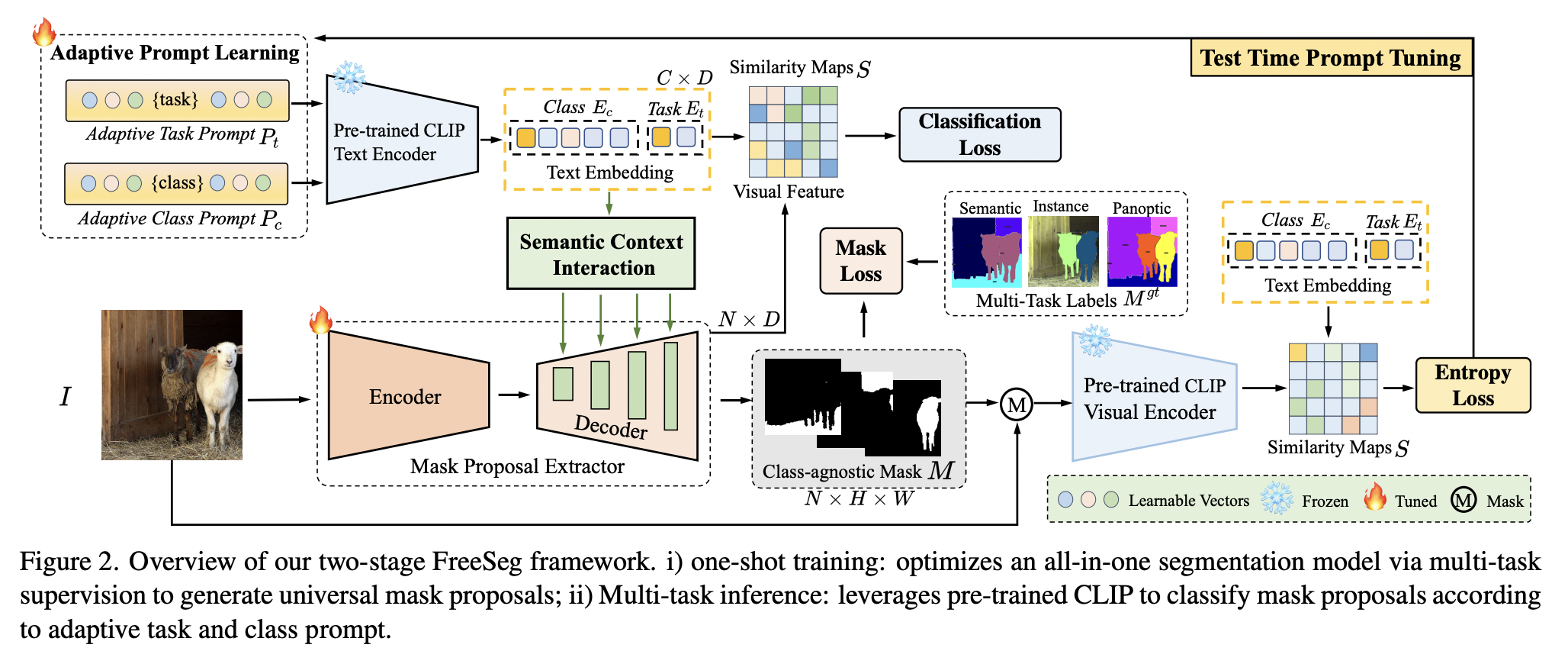
- FreeSeg (https://arxiv.org/pdf/2303.17225) (CVPR 2023)
-
Title: Freeseg: Unified, universal and open-vocabulary image segmentation
-
Task: Segmentation
- Semantic, Instance, Panoptic segmentation
-
Limitations of previous works
-
Specialized architectures or parameters for specific segmentation tasks
\(\rightarrow\) Hindering the uniformity of segmentation models
-
- Proposal: FreeSeg
- Key idea: Generic framework to accomplish Unified, Universal and Open-Vocabulary Image Segmentation
- Details
- Generates mask proposals & Performs zero-shot classification for them.
- All-in-one network via one-shot training
- Same architecture and parameters to handle diverse segmentation tasks seamlessly in the inference
- Adaptive prompt learning
- To capture task-aware and category-sensitive concepts
-
KD for weakly-supervised semantic segmentation
- Leverage both VLMs and weak supervision (e.g., image-level labels)
Example
- CLIP-ES (https://arxiv.org/pdf/2212.09506) (CVPR 2023)
- Title: Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation.
- Proposal: CLIP-ES
- Key idea: Employs CLIP to refine the class activation map by deigning a softmax function and a class-aware attention-based affinity module for mitigating the category confusion issue.
- CLIMS (https://arxiv.org/pdf/2203.02668) (CVPR 2022)
- Title: Clims: Cross language image matching for weakly supervised semantic segmentation
- Proposal: CLIMS
- Key idea: Employs CLIP knowledge to generate high-quality class activation maps for better weakly-supervised semantic segmentation.
(3) Summary & Discussion
Most VLM studies:
Explore knowledge distillation over two dense visual recognition tasks
- (1) Object detection
- To better align “image-level and object-level representations”
- (2) Semantic segmenting
- Focus on tackling the mismatch between “image-level and pixel-level representations”
Can also be categorized based on their methodology
- (1) Feature-space distillation
- Enforces embedding consistency between (1) & (2)
- (1) VLM’s encoder
- (2) Detection (or segmentation) encoder
- Enforces embedding consistency between (1) & (2)
- (2) Pseudo-labelling distillation
- Employs VLM-generated pseudo labels
- To regularize detection or segmentation models.
Compared with VLM transfer..
- VLM knowledge distillation has clearly better flexibility
- Allowing different downstream networks regardless of the original VLMs