
Vision-Language Models for Vision Tasks: A Survey
https://arxiv.org/pdf/2304.00685
Contents
- (8) Performance Comparison
- (9) Future Directions
8. Performance Comparison
Compare, analyze and discuss the ..
- (1) VLM pre-training
- (2) VLM transfer learning
- (3) VLM knowledge distillation methods
(1) Performance of “VLM Pretraining”
P1) Zero-shot prediction
- Widely adopted evaluation setup
- Analyze VLM’s generalization ability over unseen tasks w/o (task-specific) fine-tuning
- Three Tasks
- (1) Image classification
- (2) Object detection
- (3) Semantic segmentation
P2) (Zero-shot) Image classification
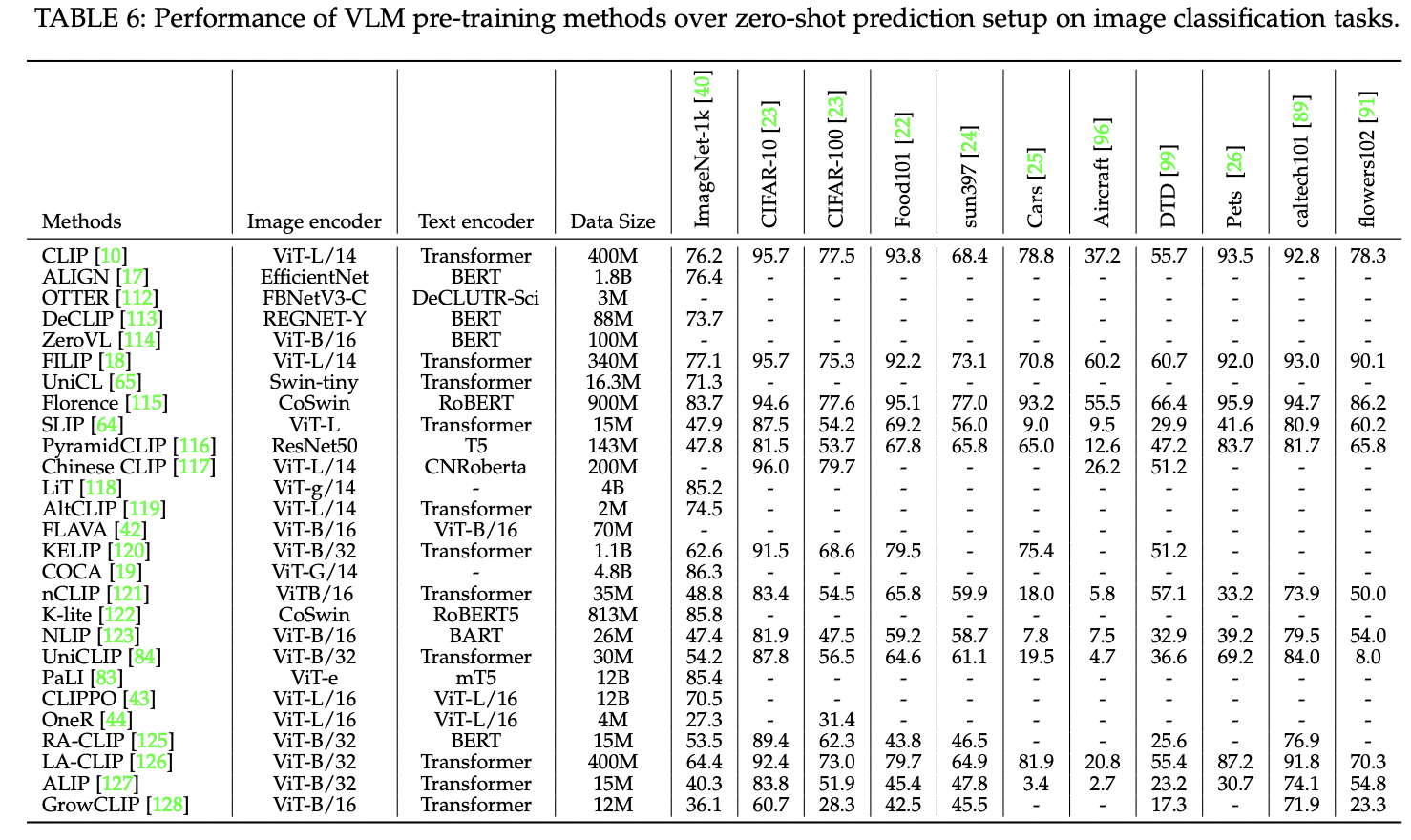
- 11 widely adopted image classification tasks
Conclusion
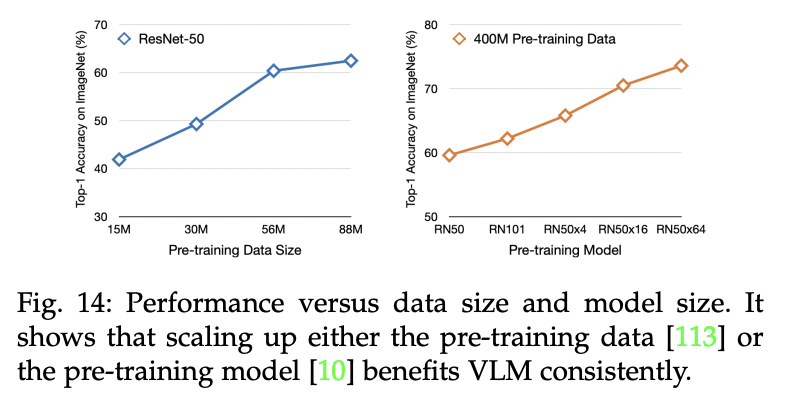
- (1) Peformance vs. Training data size
- Scaling up the pre-training data leads to consistent improvements;
- (2) Peformance vs. Model size
- Scaling up model sizes improves the VLM performance consistently;
- (3) Utilization of image-text training data
- With such data, can achieve superior zero-shot performance
- Examples
- COCA achieves SOTA performance on ImageNet
- FILIP performs well consistently across 11 tasks
P3) Three factors: Generalization of VLMs
- (1) Big data
- Image-text pairs are almost infinitely available on the Internet
- VLMs are usually trained with millions or billions of image and text samples
- (2) **Big model **
- Generally adopt much larger models (e.g., ViT-G in COCA with 2B parameters)
- (3) Task-agnostic learning
- Supervision in VLM pre-training is usually general & task-agnostic
- Help train generalizable models that works well across various downstream tasks
P4) (Zero-shot) Object detection & Semantic segmentation
VLM pre-training methods for (1) object detection and (2) semantic segmentation
- with local VLM pre-training objectives (e.g., region-word matching)
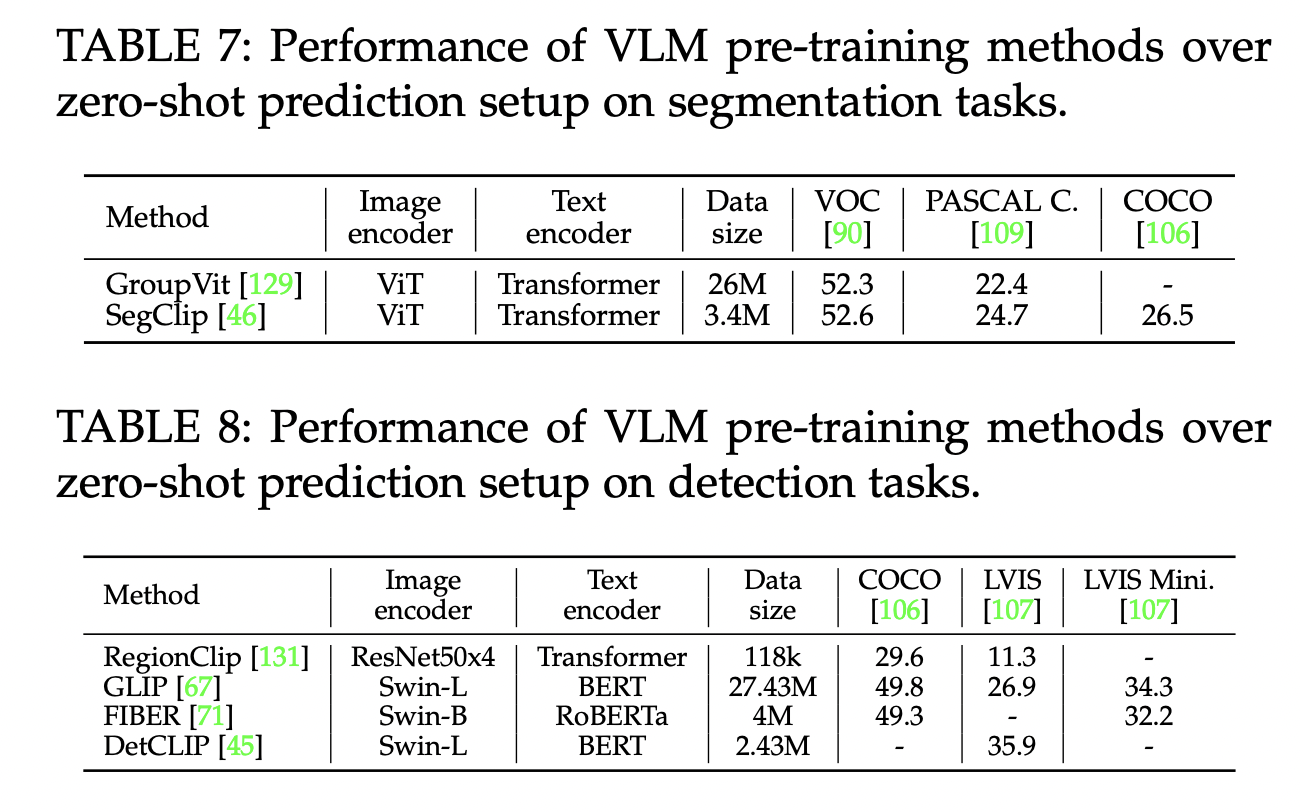
$\rightarrow$ VLMs enable effective zero-shot prediction on both dense prediction tasks!
P5) Limitation of VLMs
- (1) The performance saturates !
- Further scaling up won’t improve performance
- (2) Extensive computation resources
(2) Performance of VLM “Transfer Learning”
P1)
Three setups
- (1) Supervised transfer
- (2) Few-shot supervised transfer
- (3) Unsupervised transfer
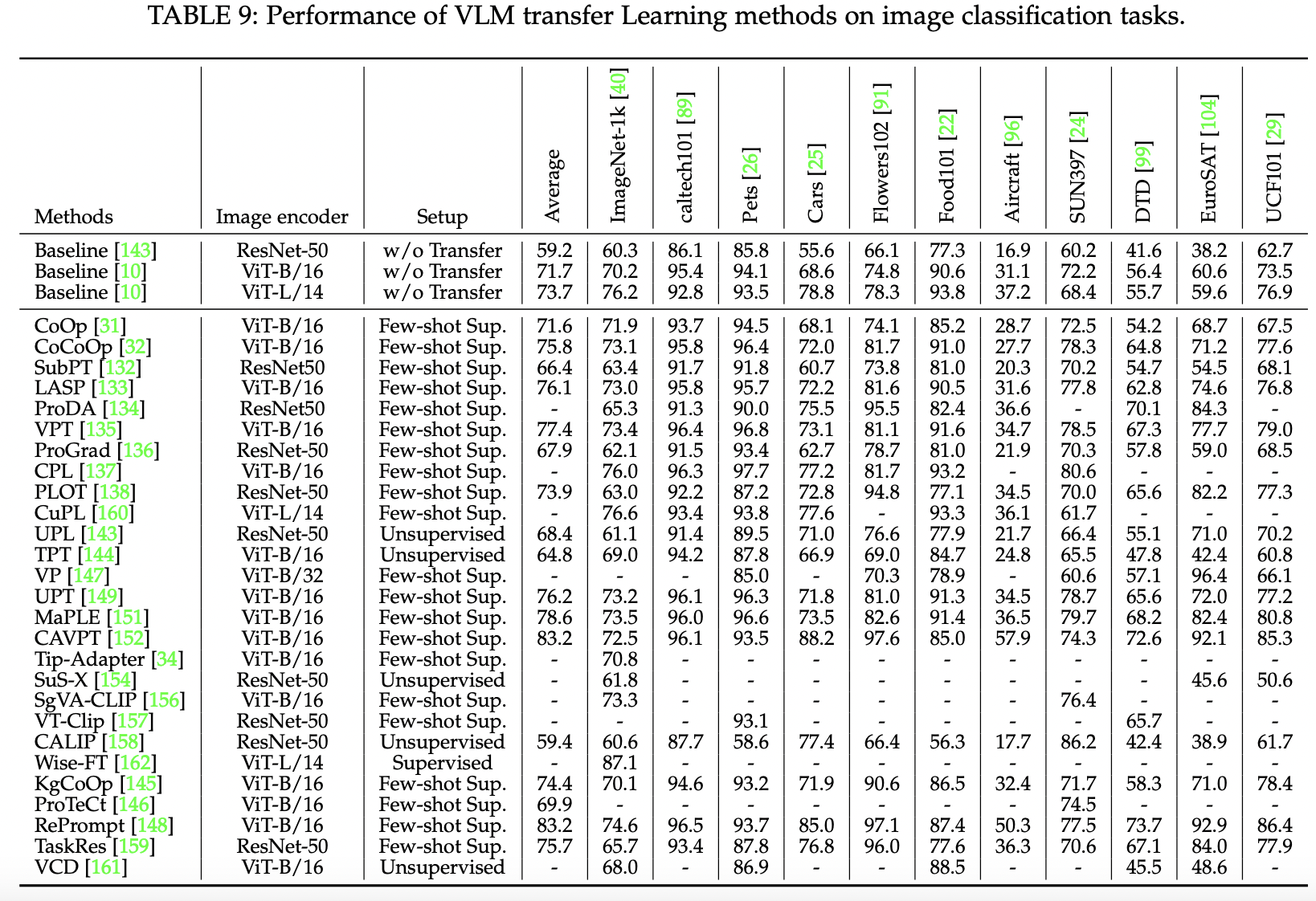
- 11 widely adopted image classification datasets
- Performance of 16-shot setup (for all few-shot supervised methods)
- Different backbones
- CNN: ResNet-50
- Transformer: ViT-B and ViT-L
P2-4) Conclusions
Three conclusions
- (1) VLM transfer setups helps in downstream tasks consistently
- Pre-trained VLMs generally suffer from domain gaps with task-specific data
- VLM transfer can mitigate this!
- (2) Performance of few-shot supervised transfer < supervised transfer
- As VLMs may overfit to few-shot labelled samples with degraded generalization
- (3) Unsupervised transfer can perform comparably with few-shot supervised transfer
- As unsupervised transfer can access massive unlabelled downstream data with much lower overfitting risks
- Nevertheless, unsupervised transfer also faces several challenges such as noisy pseudo labels
(3) Performance of VLM Knowledge Distillation
P1)
This section presents how VLM knowledge distillation helps in the tasks of object detection and semantic segmentation. Tables 10 and 11 show the knowledge distillation performance on the widely used detection datasets (e.g., COCO [106] and LVIS [107]) and segmentation datasets (e.g., PASCAL VOC [90] and ADE20k [111]), respectively. We can observe that VLM knowledge distillation brings clear performance improvement on detection and segmentation tasks consistently, largely because it introduces general and robust VLM knowledge while benefiting from taskspecific designs in detection and segmentation models.
(4) Summary
P1)
Several conclusions can be drawn from Tables 6-11. Regarding performance, VLM pre-training achieves remarkable zeroshot prediction on a wide range of image classification tasks due to its well-designed pre-training objectives. Nevertheless, the development of VLM pre-training for dense visual recognition tasks (on region or pixel-level detection and segmentation) lag far behind. In addition, VLM transfer has made remarkable progress across multiple image classification datasets and vision backbones. However, supervised or few-shot supervised transfer still requires labelled images, whereas the more promising but challenging unsupervised VLM transfer has been largely neglected.
P2)
Regarding benchmark, most VLM transfer studies adopt the same pre-trained VLM as the baseline model and perform evaluations on the same downstream tasks, which facilitates benchmarking greatly. They also release their codes and do not require intensive computation resources, easing reproduction and benchmarking greatly. Differently, VLM pre-training has been studied with different data (e.g., CLIP [10], LAION400M [21] and CC12M [79]) and networks (e.g., ResNet [6], ViT [57], Transformer [58] and BERT [14]), making fair benchmarking a very challenging task. Several VLM pre-training studies also use non-public training data [10], [18], [83] or require intensive computation resources (e.g., 256 V100 GPUs in [10]). For VLM knowledge distillation, many studies adopt different taskspecific backbones (e.g., ViLD adopts Faster R-CNN, OVDETR uses DETR) which complicates benchmarking greatly. Hence, VLM pre-training and VLM knowledge distillation are short of certain norms in term of training data, networks and downstream tasks.
9. Future Directions
VLM enables effective usage of web data, zero-shot prediction without any task-specific fine-tuning, and openvocabulary visual recognition of images of arbitrary categories. It has been achieving great success with incredible visual recognition performance. In this section, we humbly share several research challenges and potential research directions that could be pursued in the future VLM study on various visual recognition tasks