VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
https://arxiv.org/pdf/2111.02358
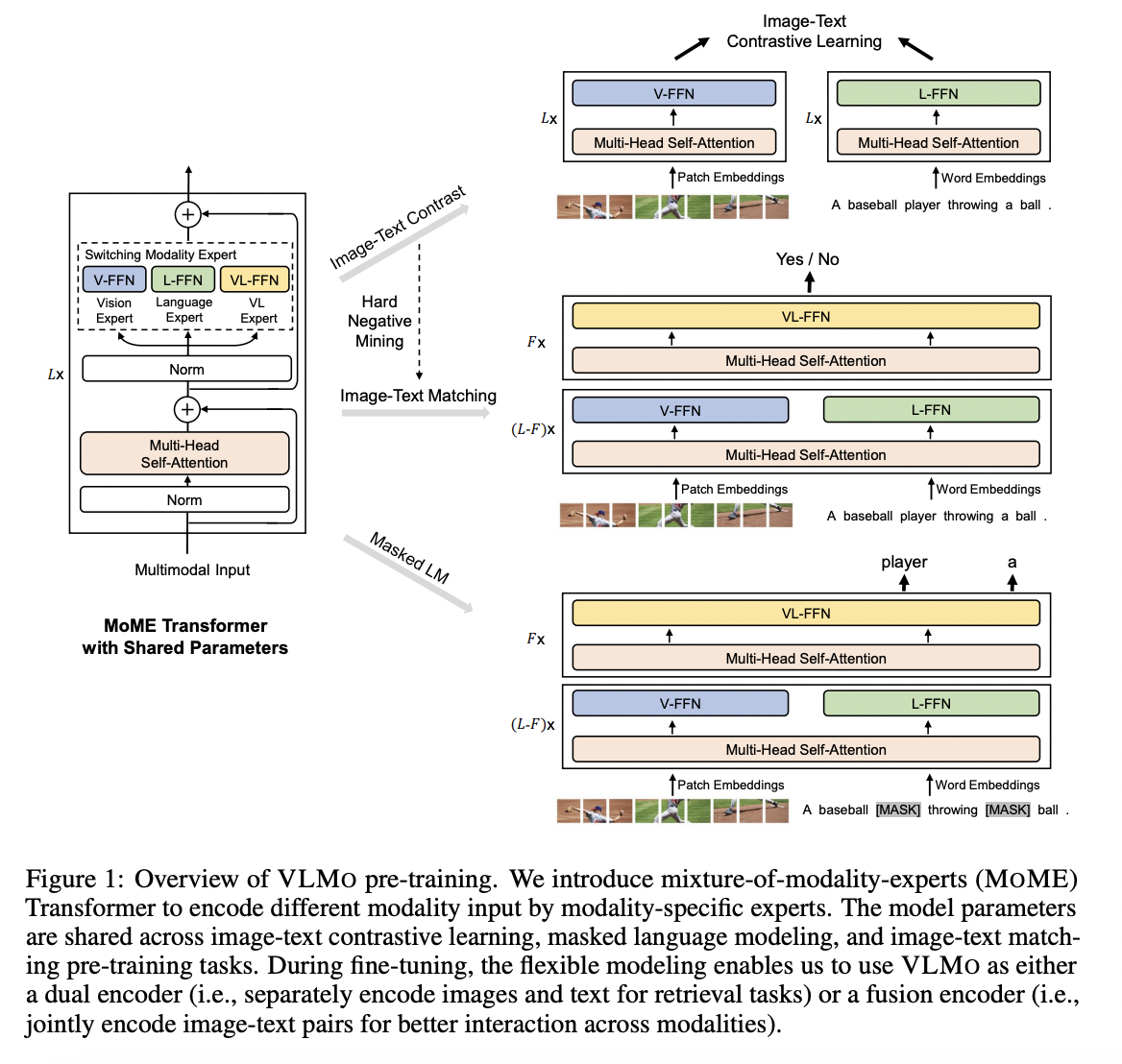
VLMo
Unified Vision-Language pretrained Model (VLMo)
- Dual encoder & Fusion encoder
- Mixture-of-Modality-Experts (MOME) Transformer
- Each block contains a pool of “modality-specific” experts & a shared selfattention layer.
- Can be fine-tuned as …
- Fusion encoder: For vision-language classification tasks
- Dual encoder: For efficient image-text retrieval
- Stagewise pre-training strategy
- Not only image-text pairs
- But also image-only & text-only data