A Survey on Speech LLMs
https://arxiv.org/pdf/2410.18908
Contents
2.Recent Advances in Speech LLMs
- Evolution of Speech LLMs Architectures
- Advancements of Speech LLMs in Key Tasks and Challenges
2. Recent Advances in Speech LLMs
(1) Evolution of Speech LLMs Architectures
Challenges in the field of SLU
- (1) Long-form speech understanding
- (2) Hotword recognition
\(\rightarrow\) Begun to explore the integration of “LLMs into SLU”
a) Transformer + (Traditional) Speech Models
[1] Speech-Transformer (Dong et al. (2018))
( Title: A no-recurrence sequence-to-sequence model for speech recognition )
-
(1) Task: Speech Recognition
-
(2) Idea: End-to-end speech recognition system based on the Transformer
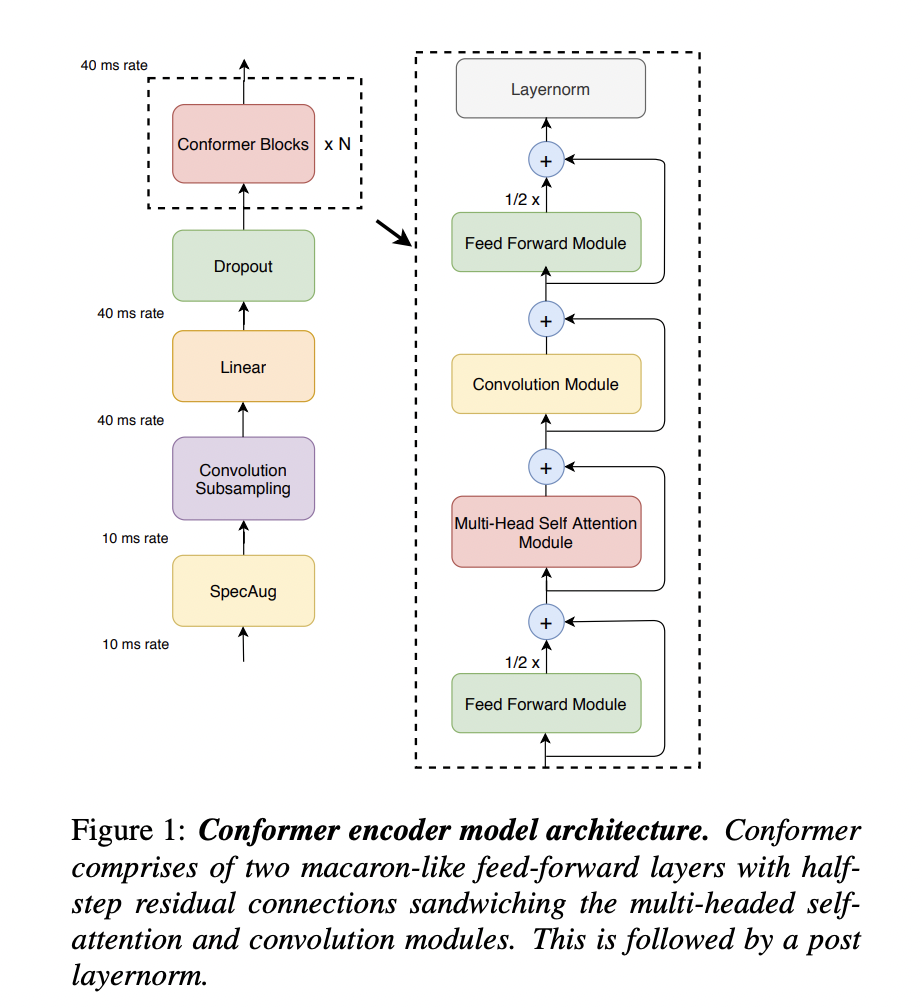
[2] Conformer (Gulati et al. (2020))
( Title: Conformer: Convolution-augmented Transformer for Speech Recognition )
-
(1) Task: Speech Recognition
- (2) Idea: Combines CNN with Transformer
- Transformer: Capture content-based “global” interactions
- CNN: Exploit “local” features
- (3) Results: Make the Transformer more robust in processing speech signals!
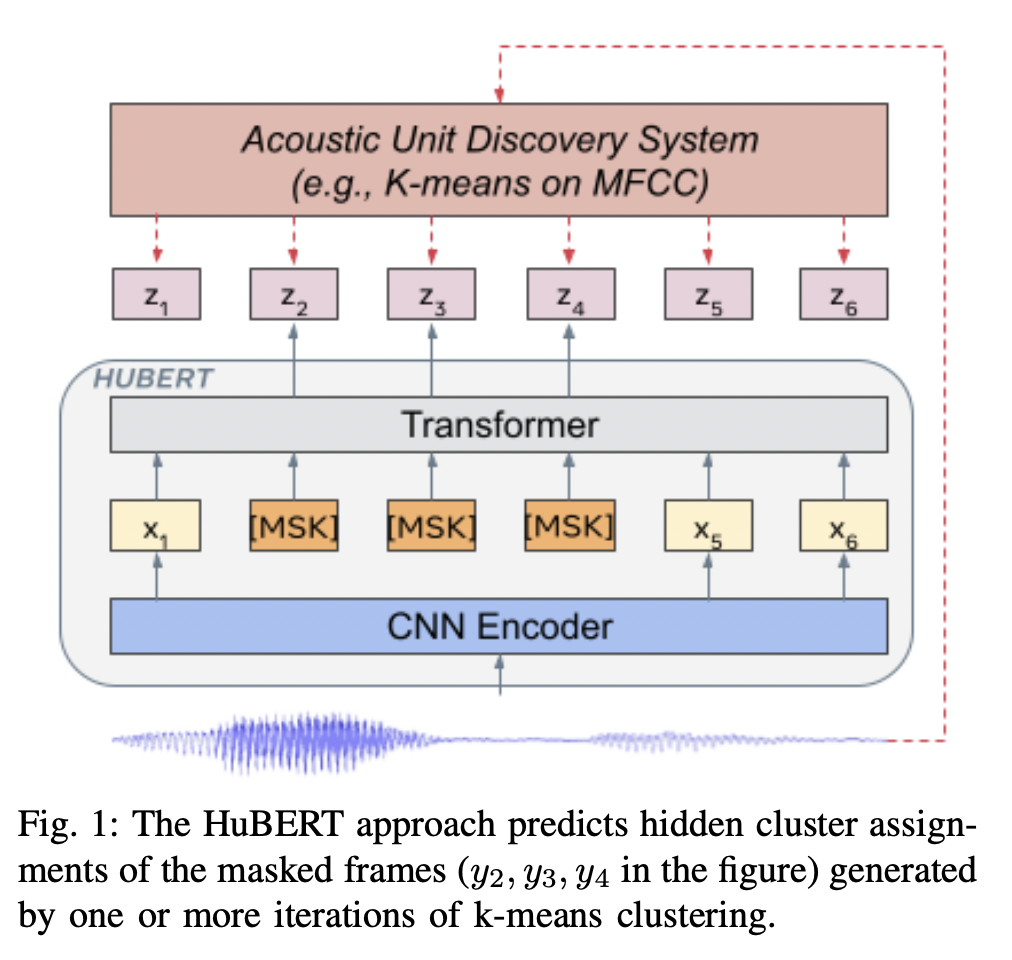
[3] HuBERT (Hidden-Unit BERT)
( Title: HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units )
- (1) Task: SSL for Speech
- SSL on a large corpus of unlabeled speech data
- (2) Idea: Utilize LLMs to process audio features
- (3) Details:
- Offline clustering step
- Aligned target labels for a BERT-like prediction loss
- \(L_m\left(f ; X,\left\{Z^{(k)}\right\}_k, M\right)=\sum_{t \in M} \sum_k \log p_f^{(k)}\left(z_t^{(k)} \mid \tilde{X}, t\right)\).
- \(p_f^{(k)}(c \mid \tilde{X}, t)=\frac{\exp \left(\operatorname{sim}\left(A^{(k)} o_t, e_c\right) / \tau\right)}{\sum_{c^{\prime}=1}^C \exp \left(\operatorname{sim}\left(A^{(k)} o_t, e_{c^{\prime}}\right) / \tau\right)}\).
- (Output) feature sequence: \(\left[o_1, \cdots, o_T\right]\).
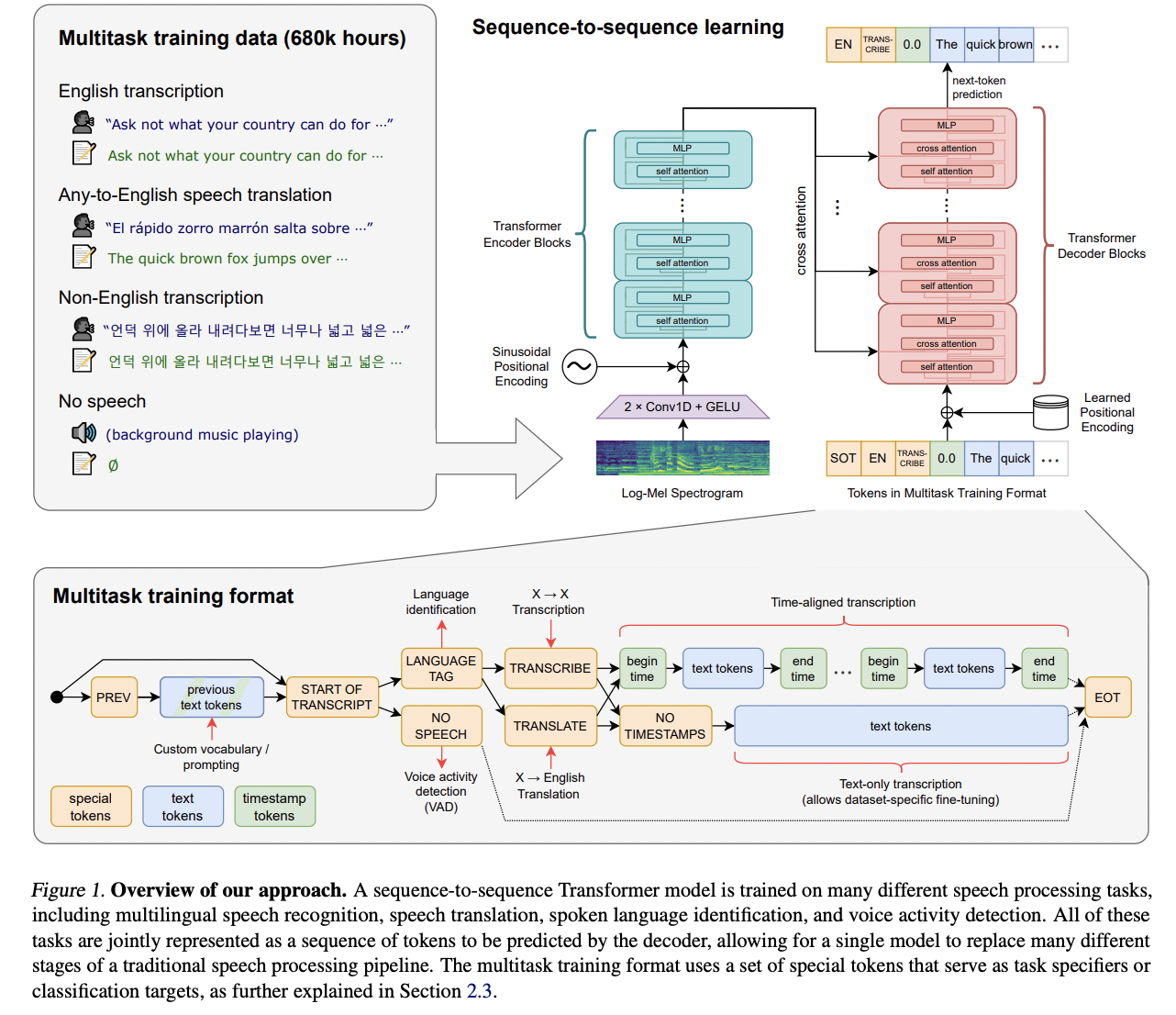
[4] Whisper (Radford et al. (2022))
( Title: Robust Speech Recognition via Large-Scale Weak Supervision )
- (1) Task: SSL for Speech
- (2) Idea: Integrated multilingual & multitask capabilities into a single model
- (3) Details:
- Pretrained simply to predict large amounts of transcripts of audio
- 680,000 hours of multilingual and multitask supervision
- Also in zero-shot transfer setting
- Pretrained simply to predict large amounts of transcripts of audio
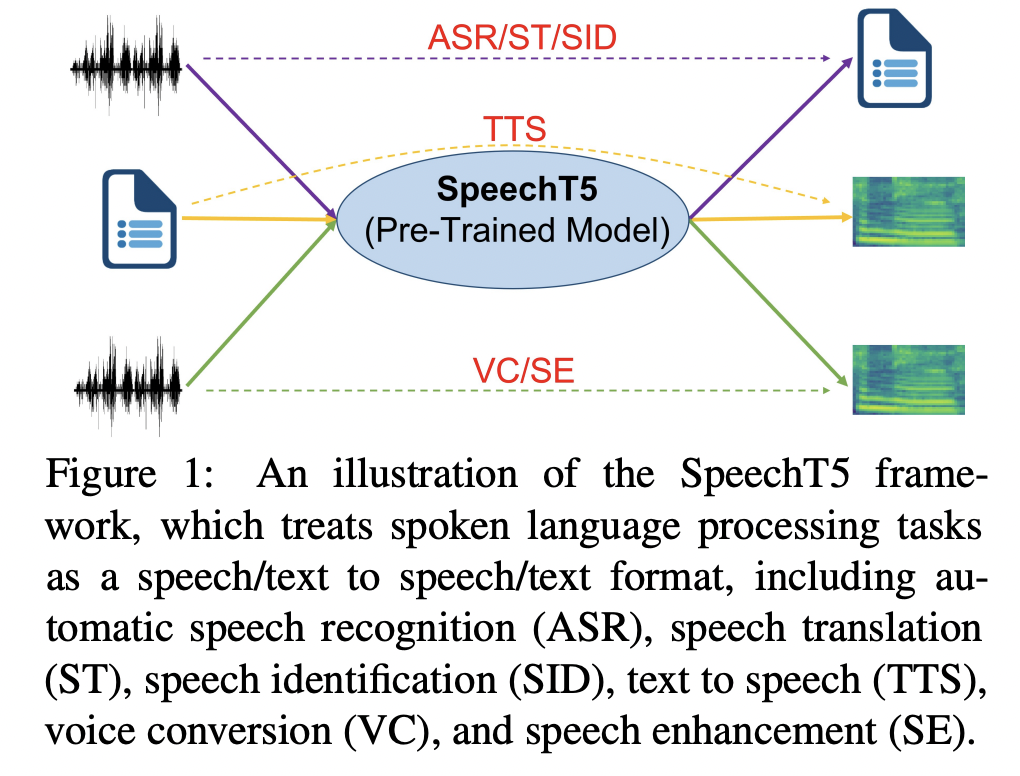
[5] SpeechT5 (Junyi Ao et al. (2022))
( Title: SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing )
-
(1) Task: SSL for Speech
-
(2) Idea: Unified encoder-decoder framework
- For various spoken language processing tasks
-
(3) Goal: Pre-training (SSL) SpeechT5 to learn a unified-modal representation
\(\rightarrow\) Improve the modeling capability for both speech and text
-
(4) Architecture
- (1) Shared encoder-decoder network
- Shared = shared across “speech & text”
- (2) Six modal-specific (speech/text) pre/post-nets
- (1) Shared encoder-decoder network
-
(5) Process
- Step 1) Pre-nets
- Preprocess the input speech/text
- Step 2) Encoder-decoder
- Sequence-to-sequence transformation
- Step 3) Post-nets
- Generate the output in the speech/text modality
- Step 1) Pre-nets
-
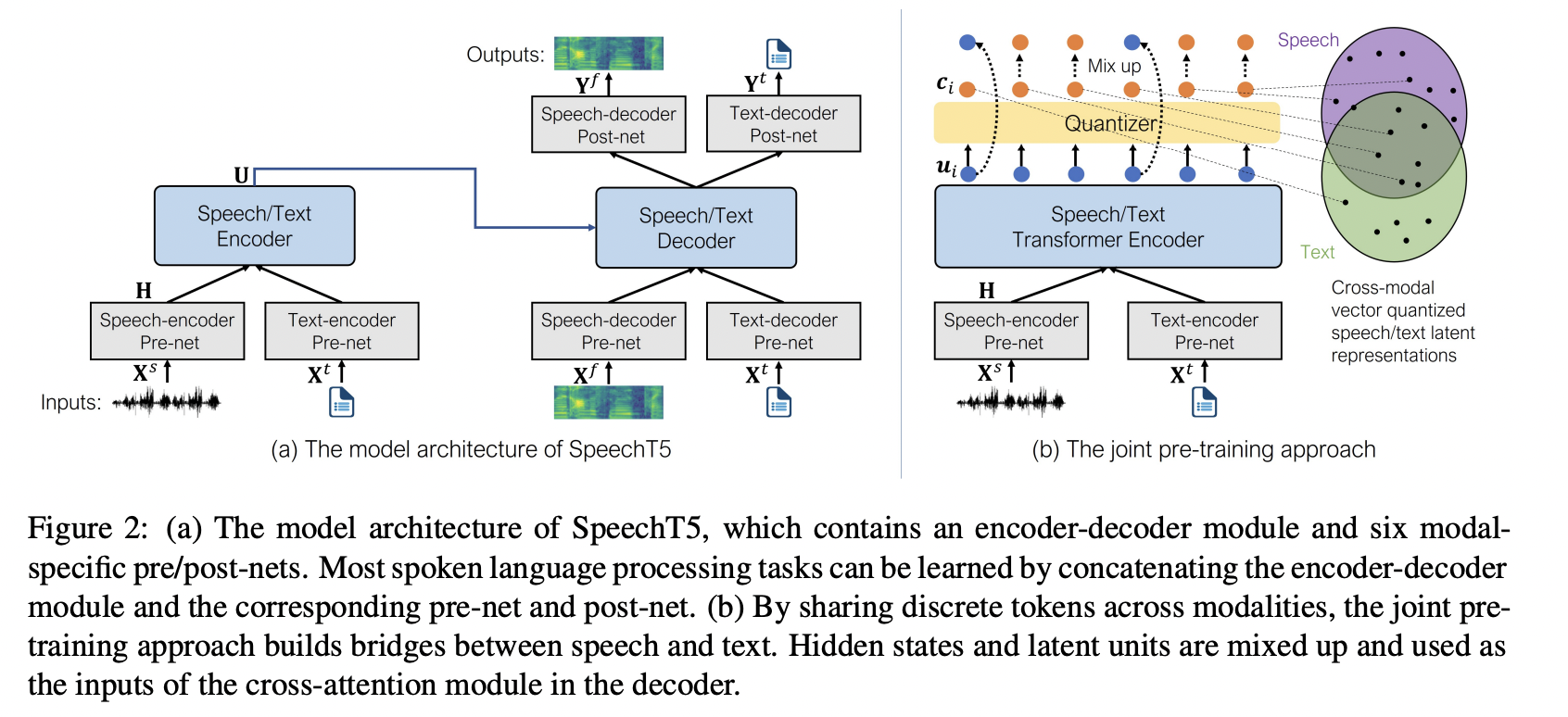
(6) Cross-modal pretraining tasks
-
How to align the textual and speech information?
\(\rightarrow\) Cross-modal vector quantization approach
-
Randomly mixes up speech/text states with latent units
-
b) Direct Audio Processing with LLMs
Using LLM as a WHOLE to process audio features (extracted by traditional speech recognition tools)
- Leverages the powerful (1) contextual understanding and (2) reasoning abilities of LLMs
\(\rightarrow\) Gradually evolved into the main trend of using LLMs in the field of speech recognition
= Speech LLMs
Aligning speech & text modalities
- By passing (extracted) features from speech to downstream language models
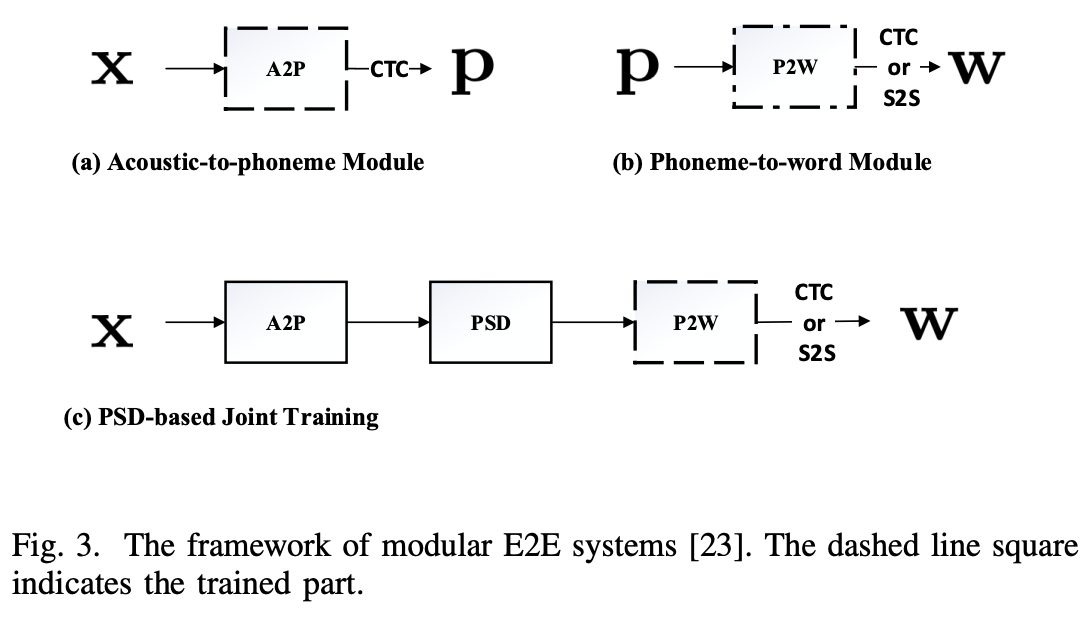
[1] Modular E2E ASR system (Qi Liu et al. (2020))
( Title: Modular end-to-end automatic speech recognition framework for acoustic-to-word model )
-
(1) Previous works (Traditional CTC-based):
- Isolate the acoustic feature-to-text mapping as a standalone unit
-
(2) Idea: Separating the mapping of speech feature information from the speech feature extraction process into two independent modules:
- (1) Acoustic-to-phoneme (A2P) model
- a) Dataset: Trained on “acoustic data”
- b) Task: Predicts the corresponding phoneme sequence with given acoustic features
- (2) Phoneme-to-word (P2W) model
- a) Dataset: Trained on both “text and acoustic data”
- b) Task: Translates the phoneme sequence to the desired word sequence
- Fine-tuned by the acoustic data
- (1) Acoustic-to-phoneme (A2P) model
-
Decoding phase: Two models will be integrated!
\(\rightarrow\) Act as a standard “acoustic-to-word (A2W)” model
-
Can be easily trained with extra text data and decoded in the same way as a standard E2E ASR system
-
Phoneme synchronous decoding (PSD)
-
Designed to “speed up” the decoding of CTC
-
Removes the blank frames in the phoneme posterior sequence
\(\rightarrow\) Greatly reduce the information rate without performance loss!
-
This paper = Downsampling layer between the A2P and P2W network
-
Speech LLMs can mainly be divided into 2 categories
- (1) Discrete Sequence Modeling
- (2) Continuous Sequence Modeling
(1) Discrete Sequence Modeling
= Condense audio feature information into discrete tokens
Examples:
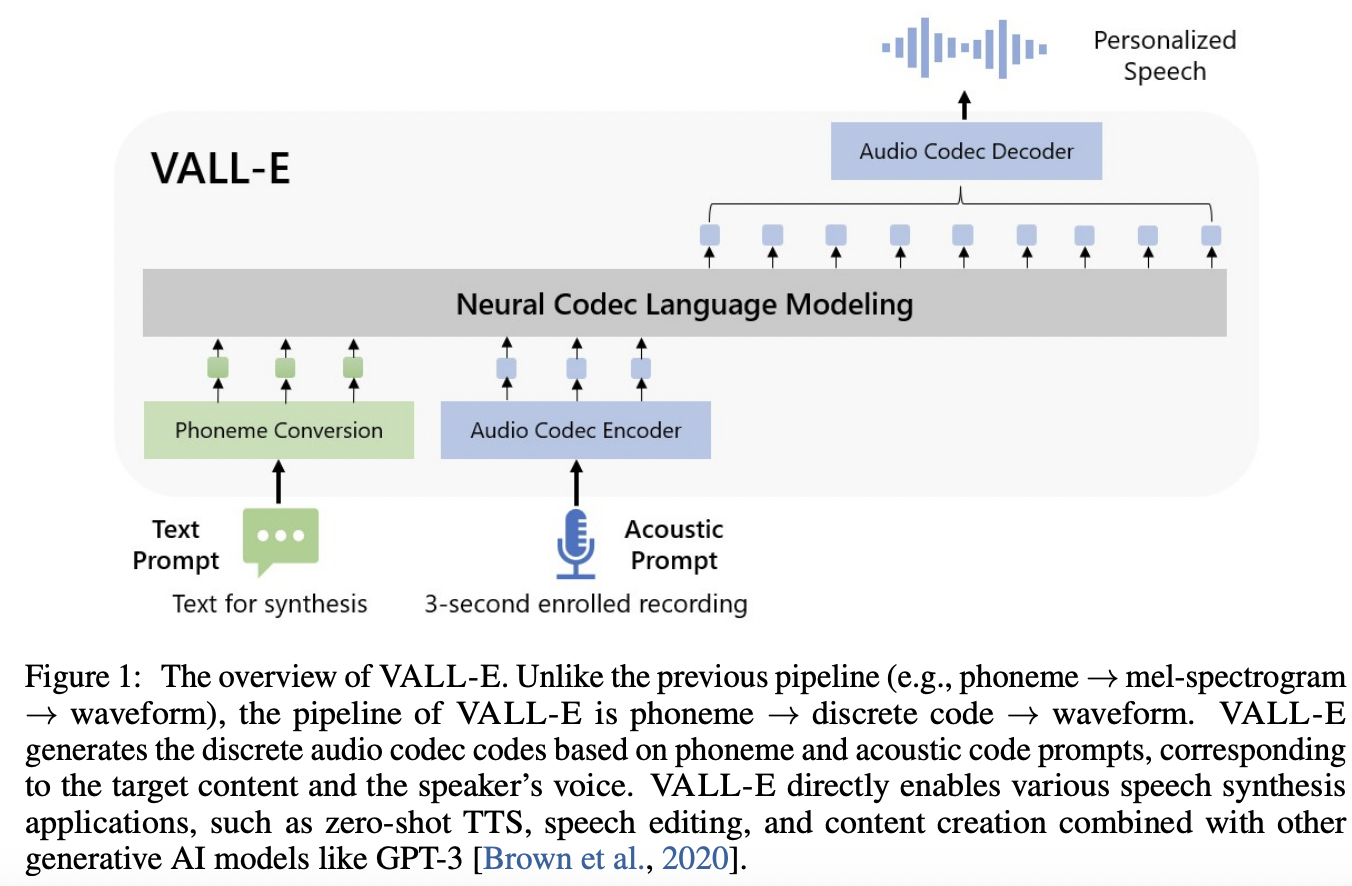
[1] Vall-E (2023)
( Title: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers )
- (1) Idea: LLMs to process audio features
- To achieve more natural text-to-speech generation
- (2) Architecture: Transformer
- (3) Pre-training: Neural Codec Language Modeling
- 60K hours of English speech
- (4) Results:
- Emerges in-context learning capabilities
- Can be used to synthesize high-quality personalized speech
- with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt!

- Dataset \(\mathcal{D}=\left\{\mathbf{x}_i, \mathbf{y}_i\right\}\),
- \(\mathbf{y}\) : audio sample
- \(\mathbf{x}=\left\{x_0, x_1, \ldots, x_L\right\}\) : Corresponding phoneme transcription
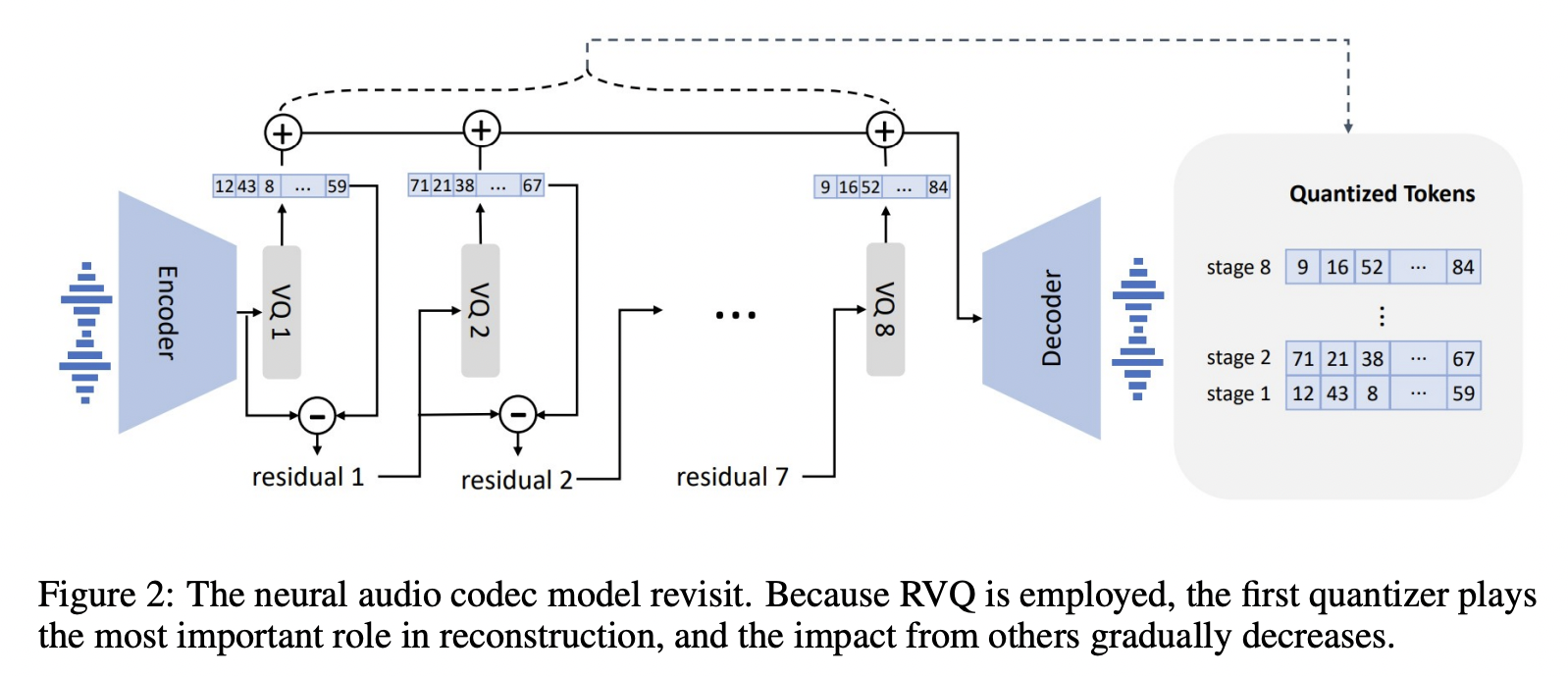
- (1) Pre-trained Neural codec model: \(\operatorname{Encoder}(\mathbf{y})=\mathbf{C}^{T \times 8}\)
- To encode each continuous audio sample into discrete acoustic codes
- \(\mathbf{C}\) = Two-dimensional acoustic code matrix
- Row vector \(\mathbf{c}_{t, \text { : }}\) : Eight codes for frame \(t\)
- Column vector \(\mathbf{c}_{:, j}\) : Code sequence from the \(j\)-th codebook, where \(j \in\{1, \ldots, 8\}\).
- \(T\) = Downsampled utterance length.
- (2) Neural codec decoder: \(\operatorname{Decodec}(\mathbf{C}) \approx \hat{\mathbf{y}}\).
- After quantization, reconstruct the waveform
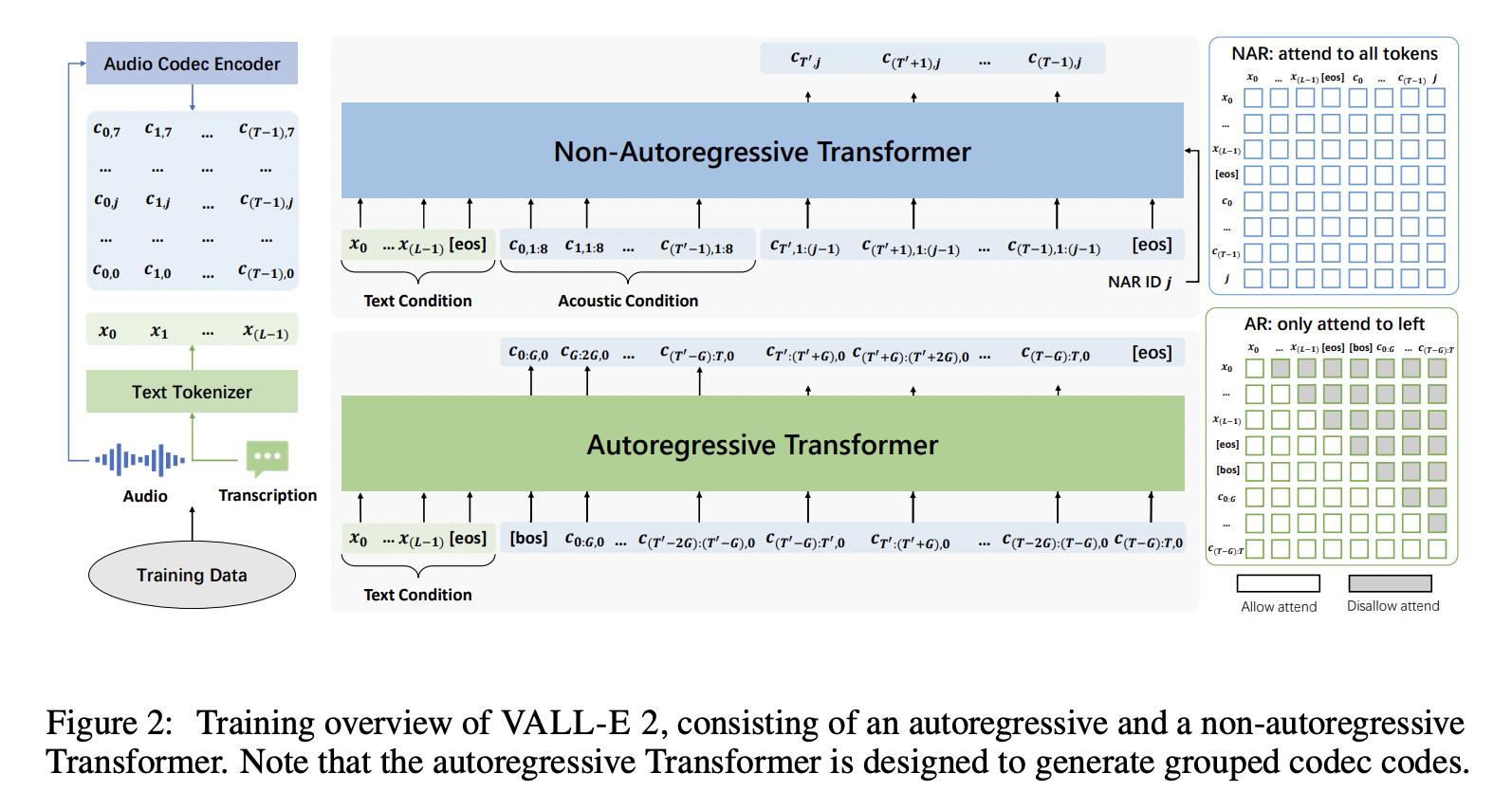
[2] Vall-E 2 (2023)
( Title: VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers )
- Zero-shot text-to-speech synthesis (TTS)
- Two enhancements (vs. Vall-E)
- (1) Repetition Aware Sampling
- (2) Grouped Code Modeling
- (1) Repetition Aware Sampling
- Refines the original nucleus sampling process
- By accounting for token repetition in the decoding history
- Stabilizes the decoding & Circumvents the infinite loop issue
- Refines the original nucleus sampling process
- (2) Grouped Code Modeling
- Organizes codec codes into groups
- To effectively shorten the sequence length
- Boosts inference speed & Addresses the challenges of long sequence modeling
- Organizes codec codes into groups
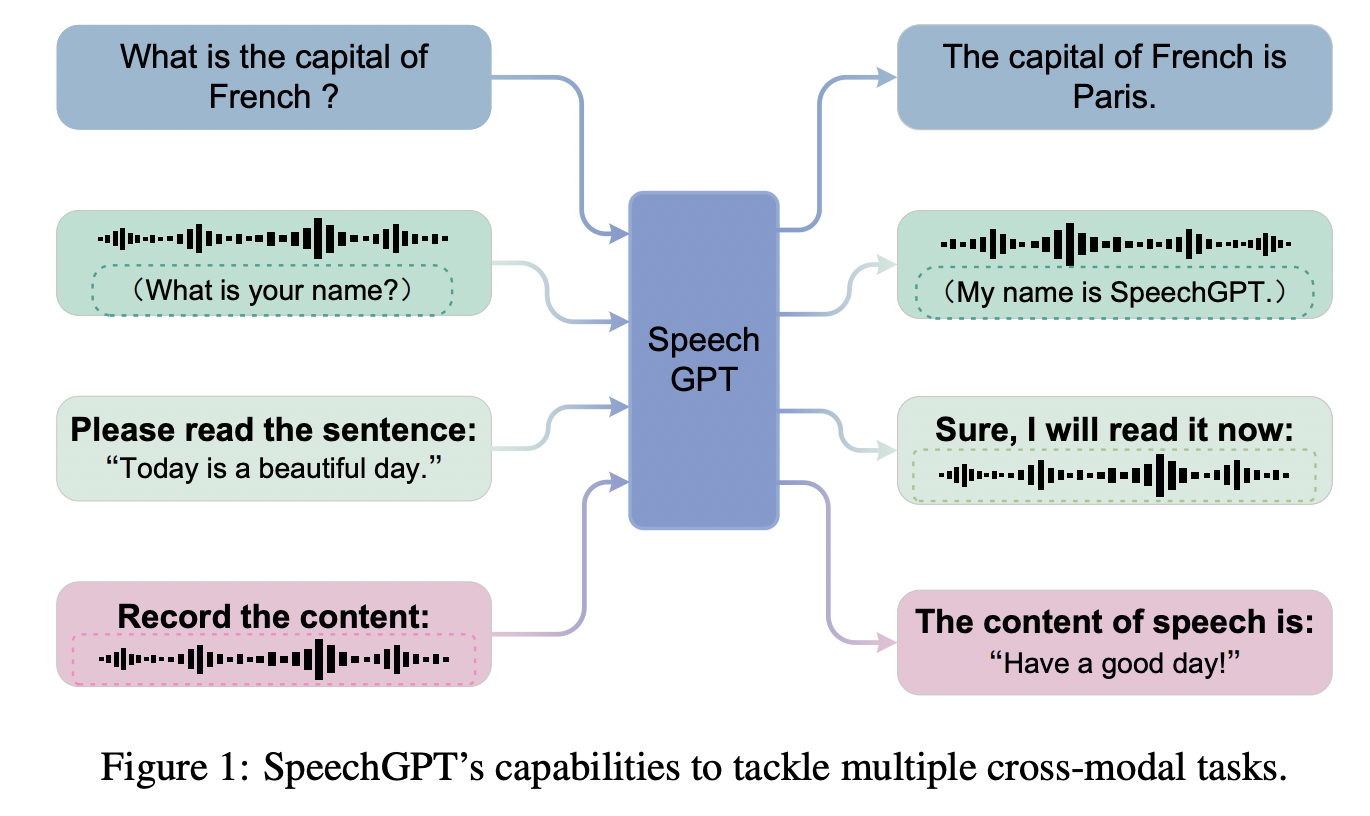
[3] SpeechGPT (2023)
( Title: Speechgpt: Empowering large language models with intrinsic crossmodal conversational abilities )
-
(1) Trend: Multi-modal LLMs is crucial for AGI
-
(2) Motivation: Current speech LLMs typically adopt the cascade paradigm!
\(\rightarrow\) Preventing inter-modal knowledge transfer
-
(3) Proposal
-
Deep integration of speech models and LLMs
-
Not only of processing audio & but also interacting through natural language
-
New interactive paradigm to the field of speech recognition
-
- Dataset: Construct SpeechInstruct with discrete speech representations
- Large-scale cross-modal speech instruction dataset.
- Three-stage training strategy
- (1) Modality-adaptation pretraining
- (2) Cross-modal instruction fine-tuning
- (3) Chain-of-modality instruction fine-tuning
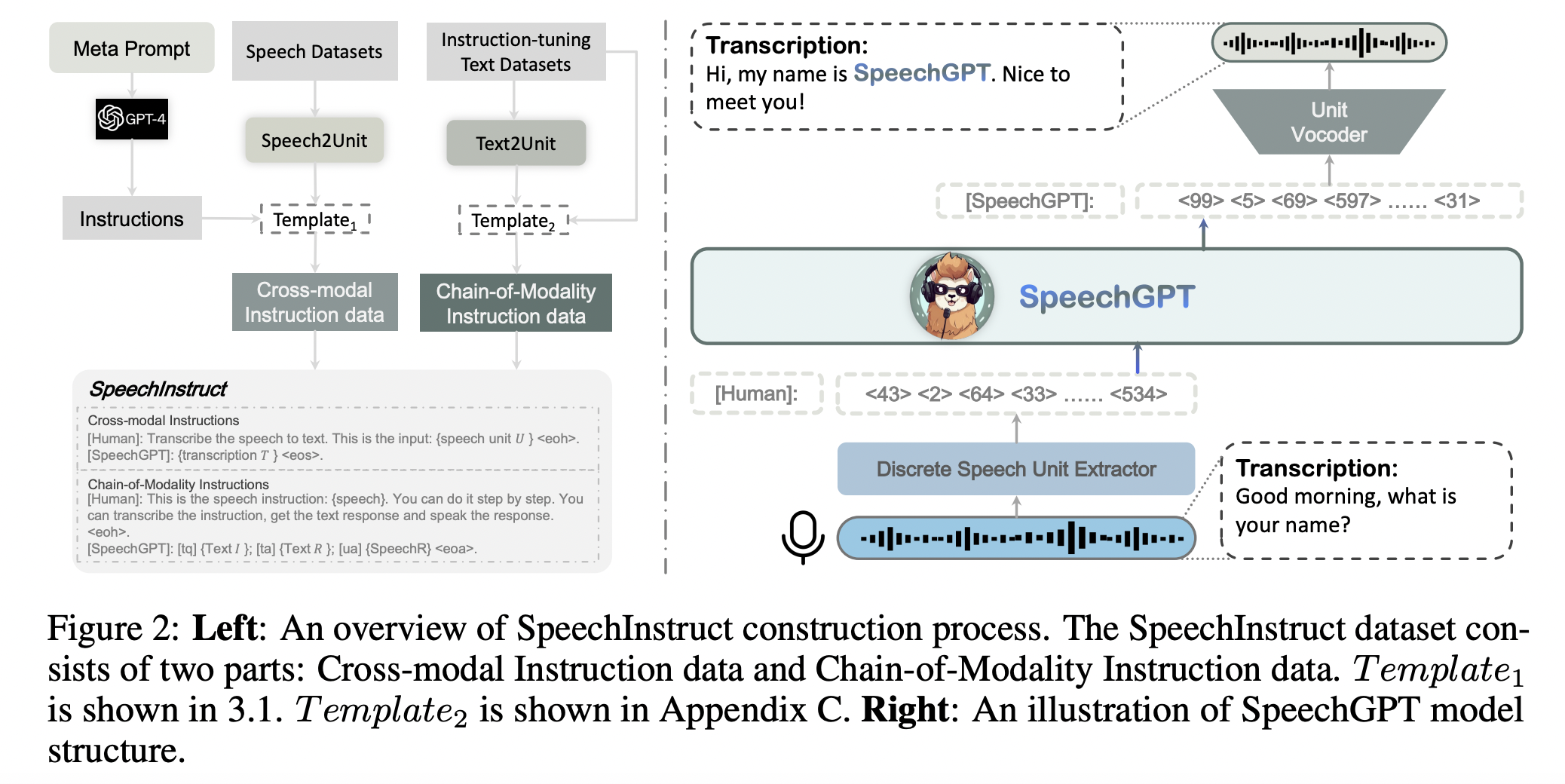
a) Modality-adaptation pretraining
- (1) Goal: To enable LLM to handle discrete units modality
- (2) Dataset: Unlabeled speech corpus \(C\)
- (3) Task: Next-token prediction task
- With corpus \(C\) consisting of speech \(U_1, U_2, \ldots, U_m\),
- (4) NLL loss: \(\mathcal{L}(L \mid C)=-\sum_{j=1}^m \sum_{i=1}^{n_j} \log P\left(u_{i, j} \mid u_{<i, j} ; L\right)\).
- \(m\) = Number of speech in \(C\)
- \(n_j\) = Number of discrete unit token in \(U_j\),
- \(u_{i, j}\) = \(i\)-th unit token in the \(j\)-th speech.
b) Cross-modal instruction fine-tuning
- (1) Goal: Align speech and text modalities utilizing paired data
- (2) Dataset: SpeechInstruct
- Consists of samples \(T_1, T_2, \ldots, T_x\).
- (3) Task: Fine-tune the model
- Each sample \(T_j\) consisting of \(t_1, t_2, \ldots, t_{n_j}\) is formed by concatenating a prefix and a text.
- (4) NLL loss ( only the text part, ignoring the prefix )
- \(\mathcal{L}(L \mid I)=-\sum_{j=1}^x \sum_{i=p_j+1}^{y_j} \log P\left(t_{i, j} \mid t_{<i, j} ; L\right)\).
- \(x\) = Nmber of samples in corpus \(I\)
- \(y_j\) = Number of tokens in sample \(T_j\)
- \(p_j\) = Number of tokens in the prefix part of \(T_j\),
- \(t_{i, j}\) = \(i\)-th word in \(T_j\).
- \(\mathcal{L}(L \mid I)=-\sum_{j=1}^x \sum_{i=p_j+1}^{y_j} \log P\left(t_{i, j} \mid t_{<i, j} ; L\right)\).

c) Chain-of-Modality Instruction Fine-Tuning
- Use LoRA to fine-tune it on Chain-of-Modality Instruction in SpeechInstruct
- Add LoRA weights (adapters) to the attention mechanisms
- Same loss function as stage 2.
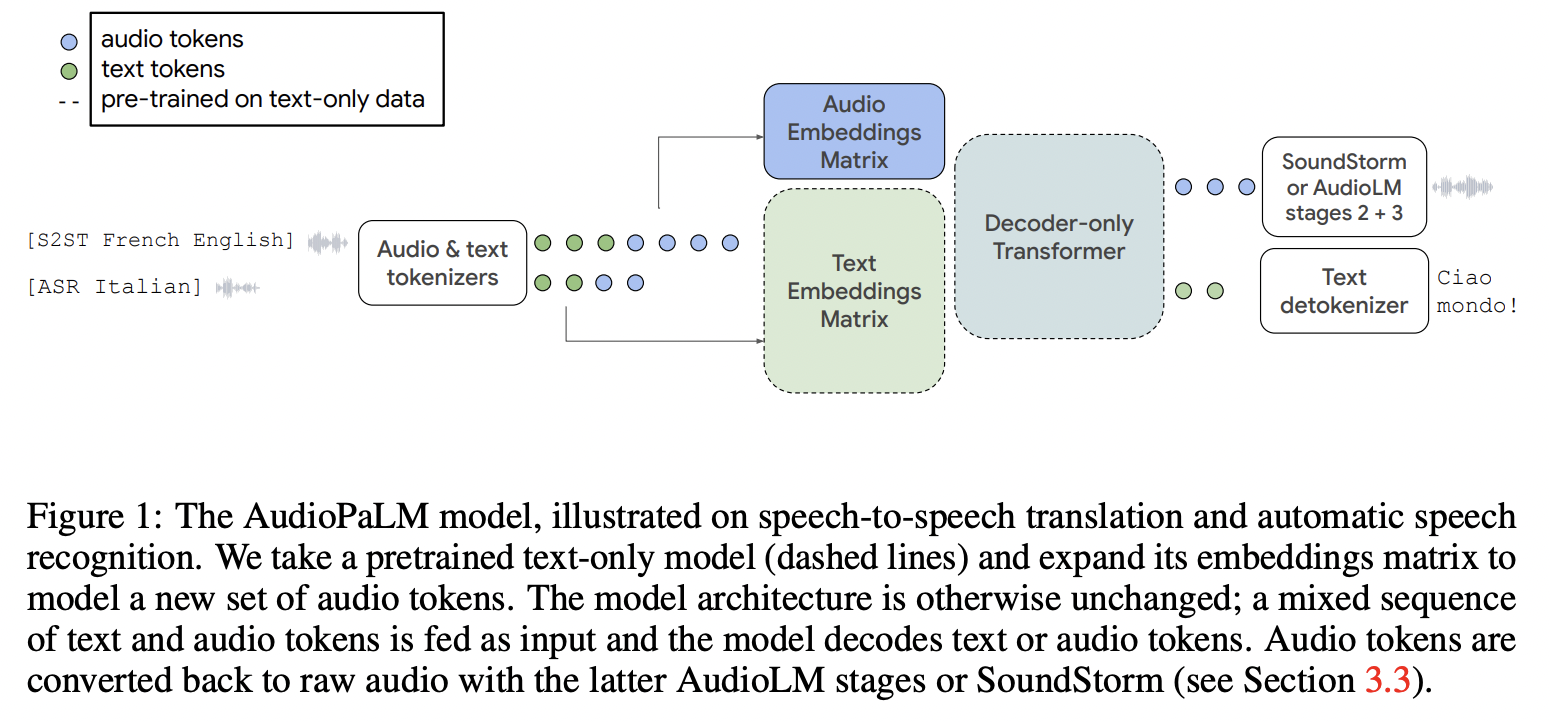
[4] AudioPaLM (2023)
( Title: AudioPaLM: A Large Language Model That Can Speak and Listen )
-
(1) AudioPaLM = LLM for speech understanding and generation
-
Expand the capabilities of speech recognition into multimodal processing
\(\rightarrow\) Enhancing performance in multimodal tasks
-
-
(2) Details = PaLM-2 (text-based) + AudioLM (speech-based)
\(\rightarrow\) Into a unified multimodal architecture
- Can process and generate text and speech
- (3) Datasets
- Audio: Speech in the source language
- Transcript: Transcript of the speech in Audio
- Translated audio: Spoken translation of the speech in Audio
- Translated transcript: Written translation of the speech in Audio.
- (4) Tasks
- ASR (automatic speech recognition): Audio \(\rightarrow\) Transcript
- AST (automatic speech translation): Audio \(\rightarrow\) Translated transcript
- S2ST (speech-to-speech translation): Audio \(\rightarrow\) Translated audio
- TTS (text-to-speech): Transcript \(\rightarrow\) Audio
- MT (text-to-text machine translation): Transcript \(\rightarrow\) Translated transcript
(2) Continuous Sequence Modeling
= Audio feature information is projected into continuous input embedding vectors
Examples:
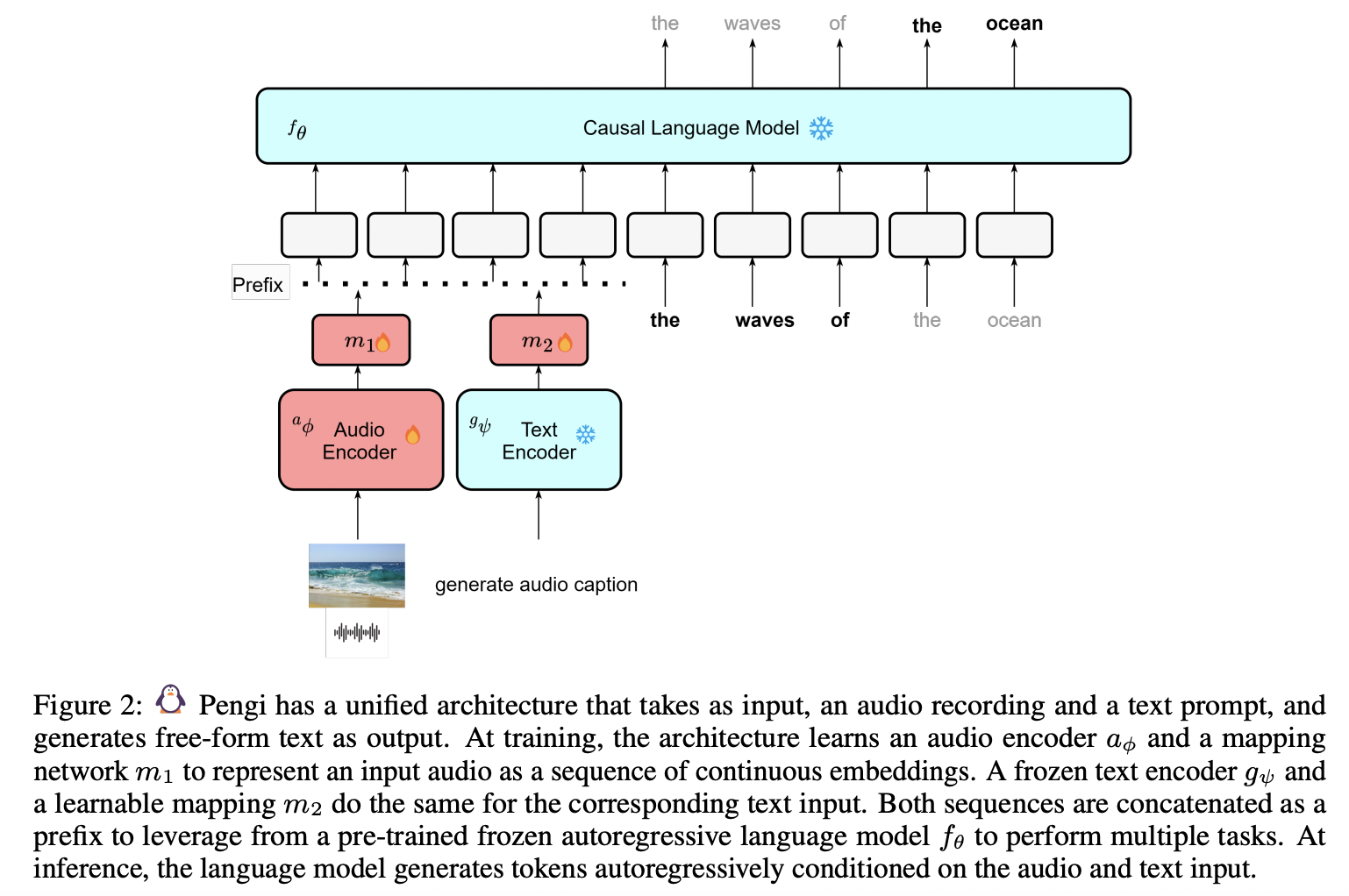
[1] Pengi (2023)
( Title: Pengi: An audio language model for audio tasks )
-
(1) Motivation
= Current models inherently lack the capacity to produce the requisite language for open-ended tasks
- e.g., Audio Captioning or Audio Question Answering.
- (2) Pengi: A novel Audio Language Model
- Leverages Transfer Learning by framing all audio tasks as text-generation tasks.
- Projects “speech” modality into the “text” space of LLMs w/o changing LLM params
- (3) Input & Output
- Input: Audio & Text
- a) Audio input = Represented as a sequence of continuous embeddings by an audio encoder.
- b) Text input = ~ by text encoder
- Output: Free-form text
- Both input & output are combined as a prefix to prompt a pre-trained frozen LLMs
- Input: Audio & Text
-
Unified architecture
-
Enables both open-ended tasks and close-ended tasks
w/o any additional fine-tuning or task-specific extensions
-

[2] SLAM-LLM (2024)
( Title: An embarrassingly simple approach for llm with strong asr capacity )
- (1) Task: Automatic speech recognition (ASR)
- (2) Motivation: Recent works use complex designs such as …
- Compressing the output temporally for the speech encoder
- Tackling modal alignment for the projector
- Utilizing PEFT for the LLM
-
(3) Finding: Simple design is OK!
- (4) How: Addition of a linear projector
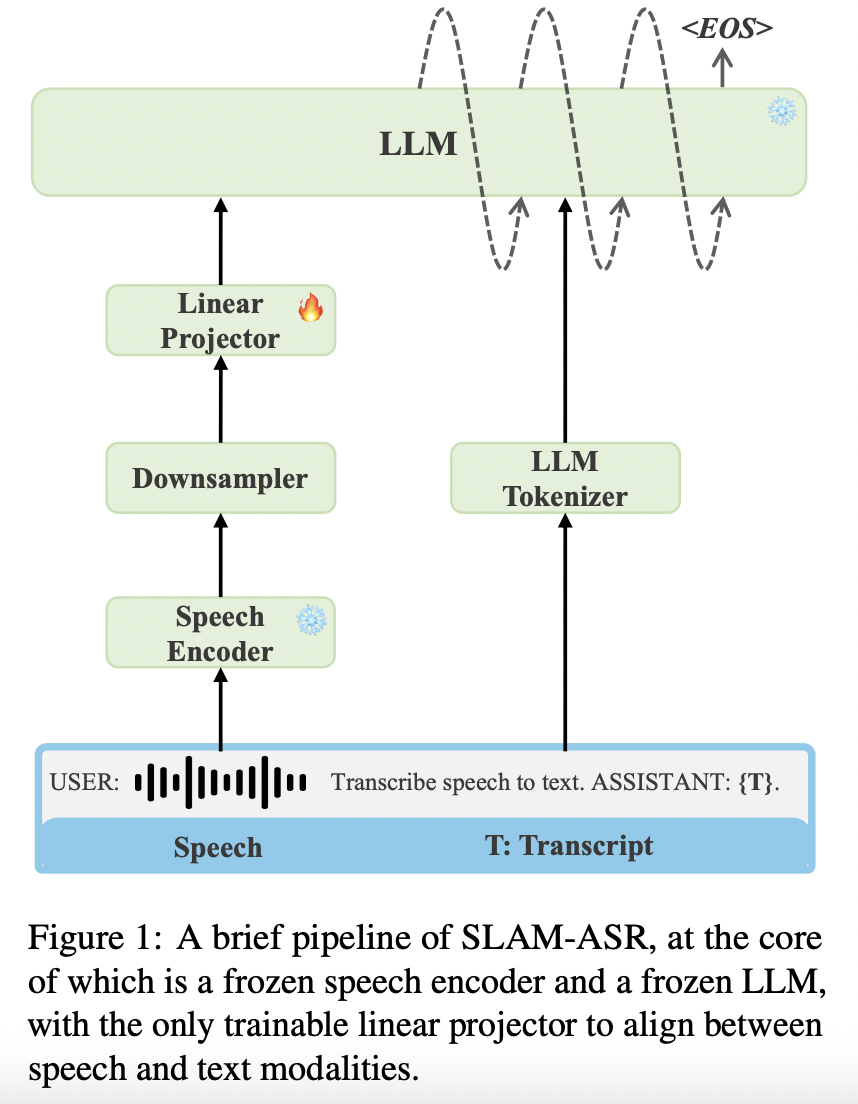
Address the issues inherent in these conventional methods!
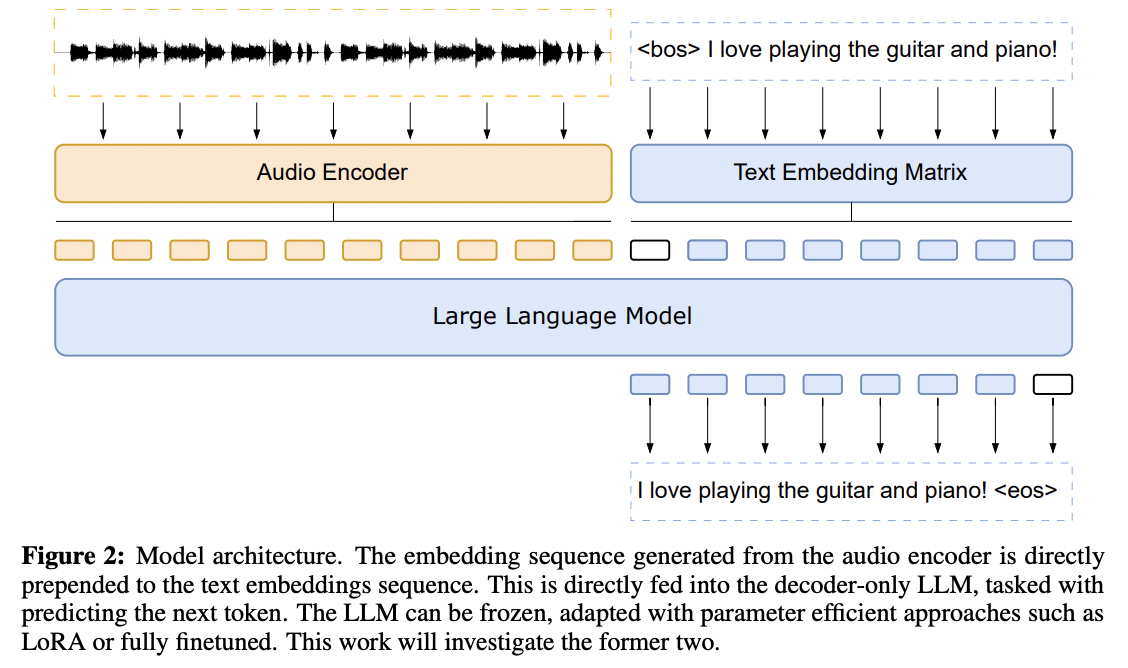
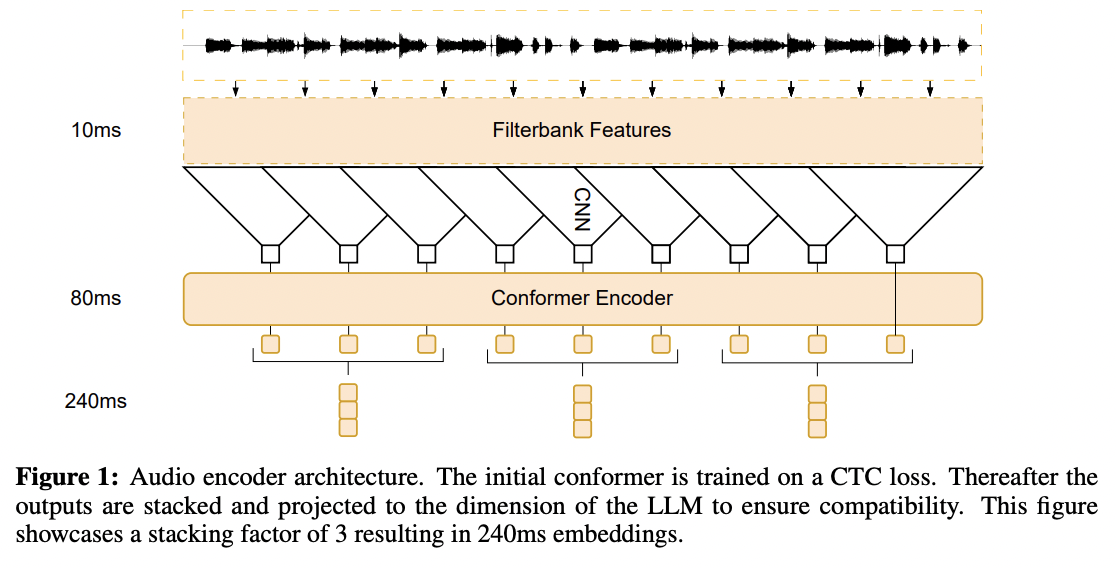
[1] Fathullah et al. (2024)
( Title: Prompting large language models with speech recognition abilities )
-
Introduced the Conformer mechanism
-
Task: Speech recognition
-
Goal: Extend the capabilities of LLMs by directly attaching a small audio encoder
-
How? By directly prepending a sequence of audial embeddings to the text token embeddings
\(\rightarrow\) LLM can be converted to an automatic speech recognition (ASR) system!
-
Results: Achieving advancements in handling long speech sequences
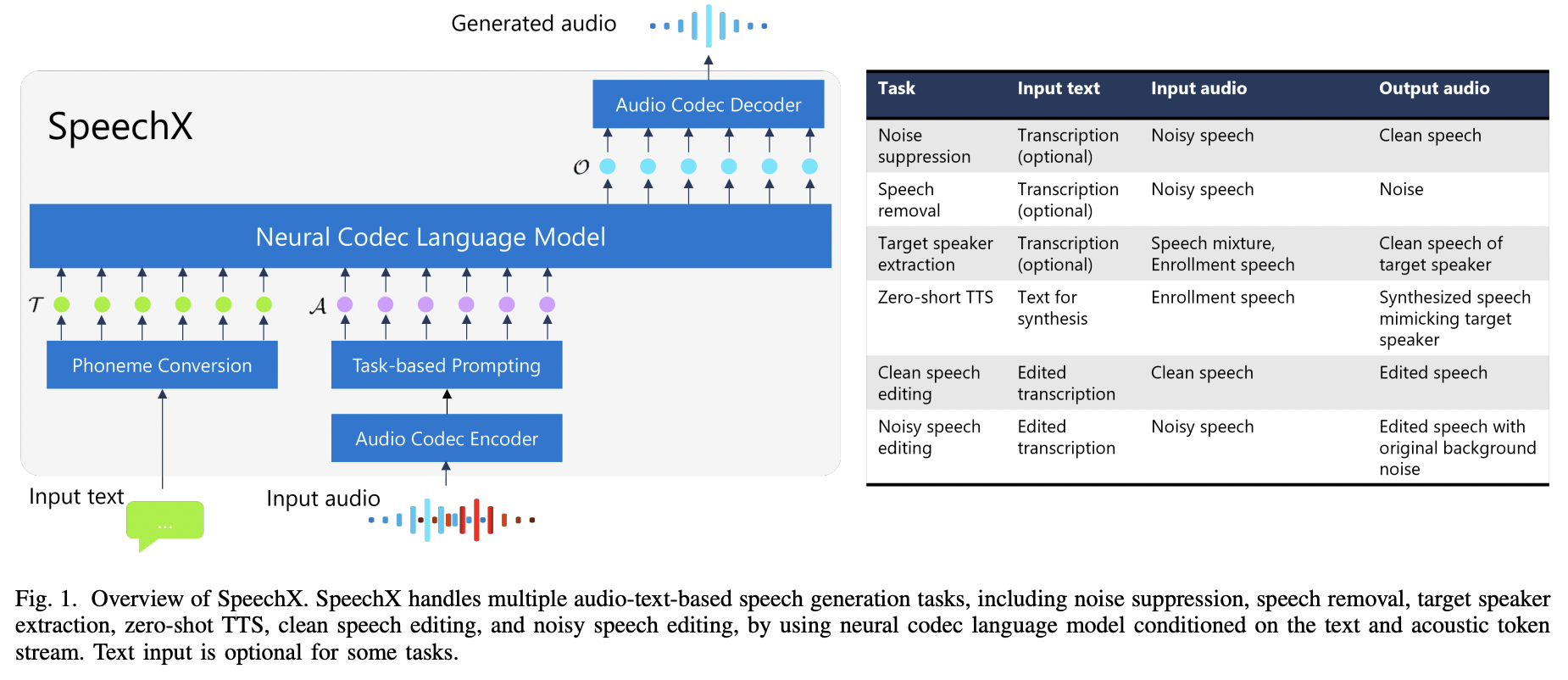
[2] SpeechX (2024)
( Title: Speechx: Neural codec language model as a versatile speech transformer )
-
(1) Recent works: Generative speech models based on “audio-text” prompts
-
(2) Motivation: Limitations in handling diverse audio-text speech generation tasks
- e.g., Transforming input speech & processing audio captured in adverse acoustic conditions
-
(3) Solution: SpeechX = A versatile speech generation model
-
(4) Details
- Capable of zero-shot TTS and various speech transformation tasks
- Deal with both clean and noisy signals
- Combines neural codec language modeling with multi-task learning using task-dependent prompting
-
(5) Neural Codec Language modeling
-
Autoregressive (AR) and non-auto-regressive (NAR) models
-
Generate Neural code sequence: \(\mathcal{O}\) ( = acoustic tokens )
With two input prompts:
- Textual prompt \(\mathcal{T}\)
- Acoustic prompt \(\mathcal{A}\).
-
-
(5) Results:
- Achieved breakthroughs in multilingual, multitask speech recognition
- Enabling seamless switching between languages and supporting challenges
- e.g., Long-form speech understanding and hotword recognition
(2) Advancements of Speech LLMs in Key Tasks and Challenges
Speech LLM paradigm
- Significant success across various tasks
a) Improvement in Traditional Tasks in SLU
Traditional tasks
- (1) Automatic speech recognition (ASR)
- (2) Speaker identification (SID)
- (3) Speech translation (ST)
(1) Automatic Speech Recognition (ASR)
- a) Task: Convert spoken language into text
- b) Modern ASR systems: Enhanced by LLMs!
- c) Aim to achieve …
- a) Higher accuracy
- b) Better noise resilience
- c) Greater adaptability to diverse accents and dialects
-
d) Foundational for …
- a) Voice-controlled applications
- b) Interactive voice response systems
- c) Automated transcription services.
-
e) Metric: Word Error Rate (WER)
-
f) Traditional models: Based on LSTM or GRU
\(\rightarrow\) Introduction of LLMs has significantly improved these results!
- In multilingual speech recognition, LLMs have demonstrated superior performance across various languages!
- Dataset: Multilingual LibriSpeech (MLS)
(2) Speech translation
-
a) Task: Converting “spoken language” \(\rightarrow\) into (written or spoken text in) “another language”
-
b) Two steps
- Step 1) Automatic speech recognition (ASR)
- Transcribes spoken words into text
- Step 2) Machine translation (MT)
- Translates the transcribed text into the target language
- Step 1) Automatic speech recognition (ASR)
-
c) Used in real-time applications
- e.g., multilingual meetings, conferences, and live broadcasts
-
d) With the successful application of LLMs in the field of MT
\(\rightarrow\) speech translation domain has also begun to gradually incorporate LLMs!
-
e) Advancements
- Not only has it improved the accuracy of speech translation tasks
- but it has also broadened the range of supported languages
(3) Others
-
LLMs have excelled in multitask learning scenarios!
-
Example: Qwen-Audio model (2023)
(Title: Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models )
- Impressive performance in tasks that combine speech-to-text with other modalities
- e.g., sentiment analysis and speaker identification
- Reducing WER by 10% and improving sentiment recognition accuracy by 8% compared to single-task models
- Impressive performance in tasks that combine speech-to-text with other modalities
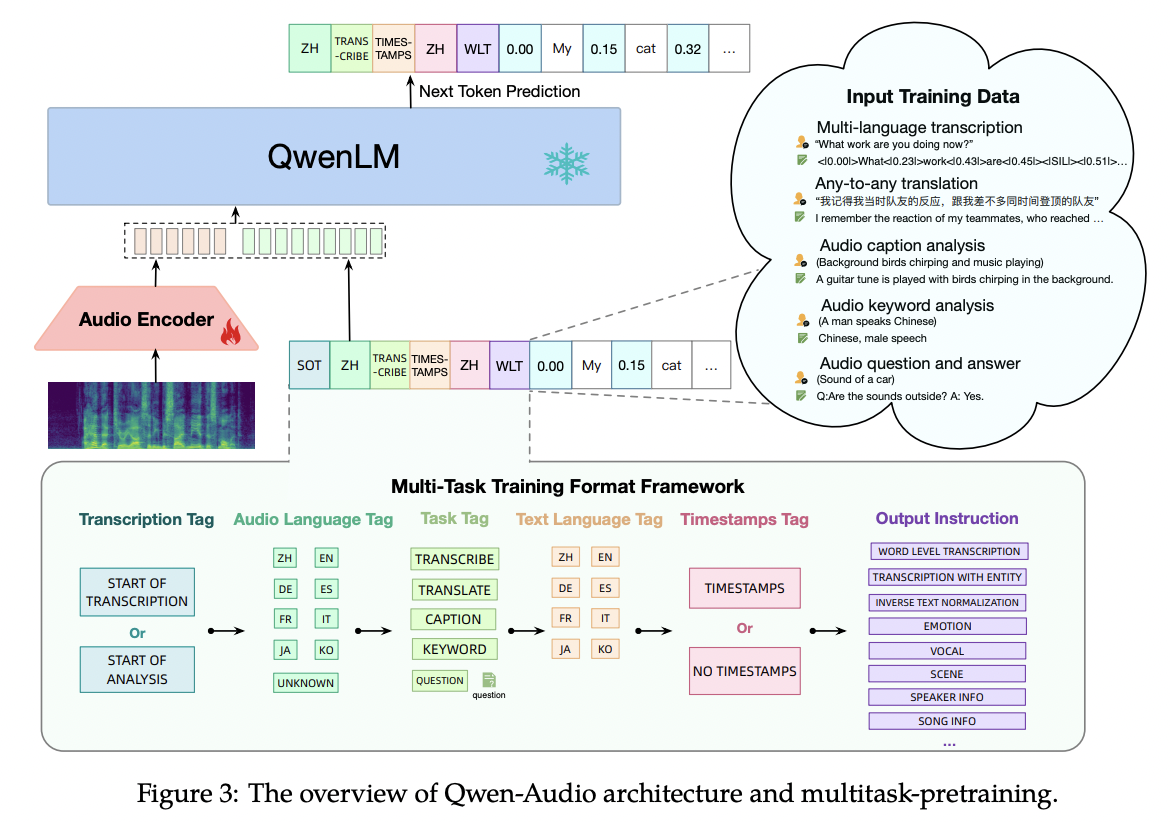
b) Long-Form Speech Understanding
Traditional speech recognition systems
\(\rightarrow\) Struggled with long-form speech understanding!!
“Long-form speech understanding”
- Why? Due to context loss** over **“extended” periods
- When? Particularly pronounced in audio segments longer than “one minute”
- a) Traditional models: Sharp increase in WER
- b) LLM-based models: Significantly mitigated this problem!
Whisper (Audio)
- Maintains contextual consistency across long-form audio
- Results: Demonstrating an 18% reduction in WER
- On audio segments exceeding five minutes, compared to traditional models.
UniAudio & Pengi (Speech)
- Remarkable performance in maintaining low WERs across extended speech segments
- How? By integrating advanced contextual understanding
c) Hotword Recognition
Especially in noisy environments!!
[1] GenTranslate (2023)
( Title: GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators )
-
a) Task: Translation
-
b) Recent advances in LLMs + Speech:
-
Multilingual speech and machine translation
\(\rightarrow\) Typically utilize beam search decoding and top-1 hypothesis selection for inference.
-
Limitation?
- Struggle to fully exploit the rich information in the diverse N-best hypotheses
- Making them less optimal for translation tasks that require a single, high-quality output sequence
-
-
Solution: GenTranslate
- Goal? Generate better results from the diverse translation versions in N-best list
- How? By leveraging the contextual understanding capabilities of LLMs
-
Result:
- 22% improvement in hotword recognition accuracy
- High robustness in noisy conditions

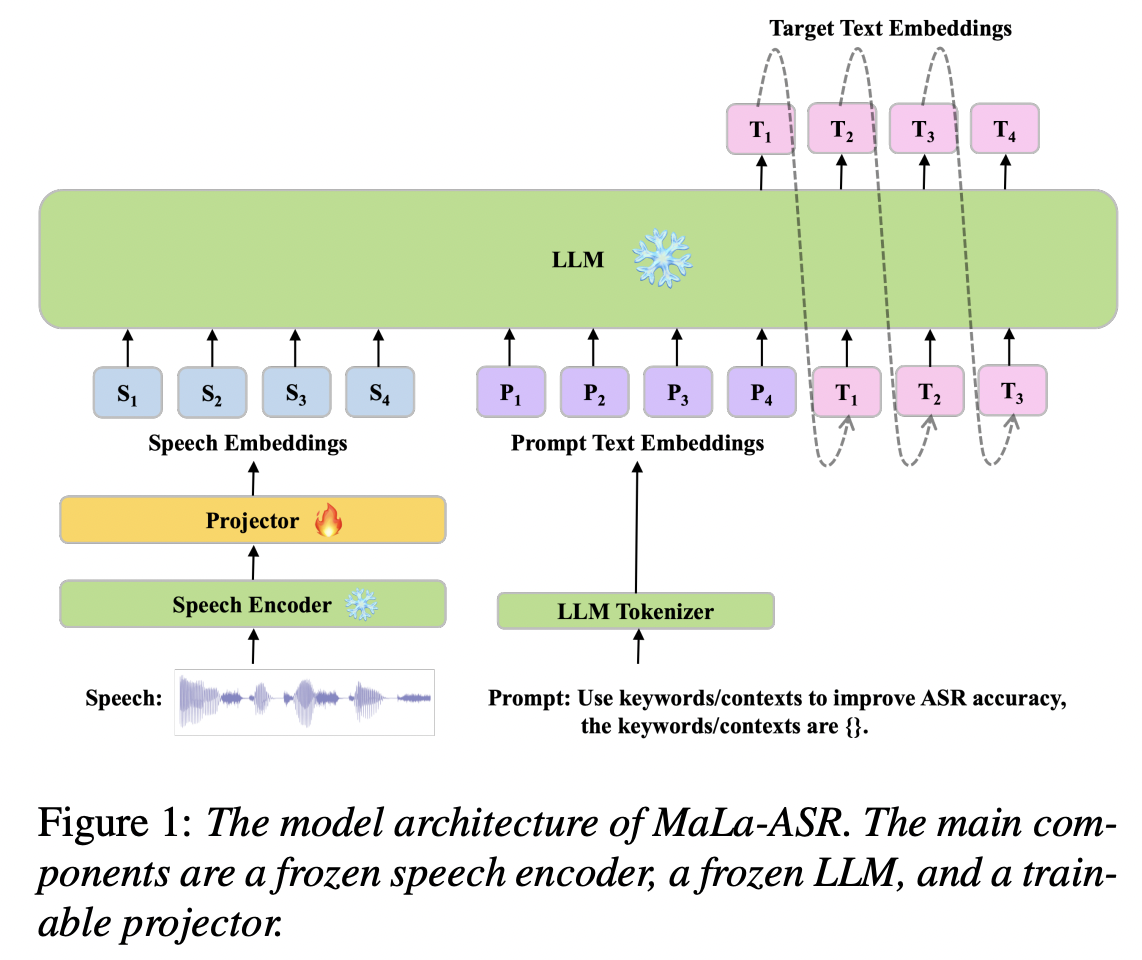
[2] Mala-ASR and Whisper
( Title: Multimedia-assisted llm-based asr )
- Not only improves hotword recognition accuracy
- But also adapts dynamically to new hotwords in real-time!
\(\rightarrow\) Particularly valuable in dynamic environments
(like live broadcasts or interactive voice response (IVR) systems)
d) Real-time Multimodal Interaction
The integration of LLMs into speech recognition
\(\rightarrow\) Expanded the scope of tasks beyond traditional speech-to-text
\(\rightarrow\) Enabling real-time multimodal interaction
VoxtLM and LauraGPT
-
Facilitate seamless integration of (1) speech + (2) visual and textual inputs
-
Providing coherent and accurate multimodal outputs
-
E.g., Live transcription and synchronized translation during presentations
\(\rightarrow\) Both speech & visual context need to be processed simultaneously!
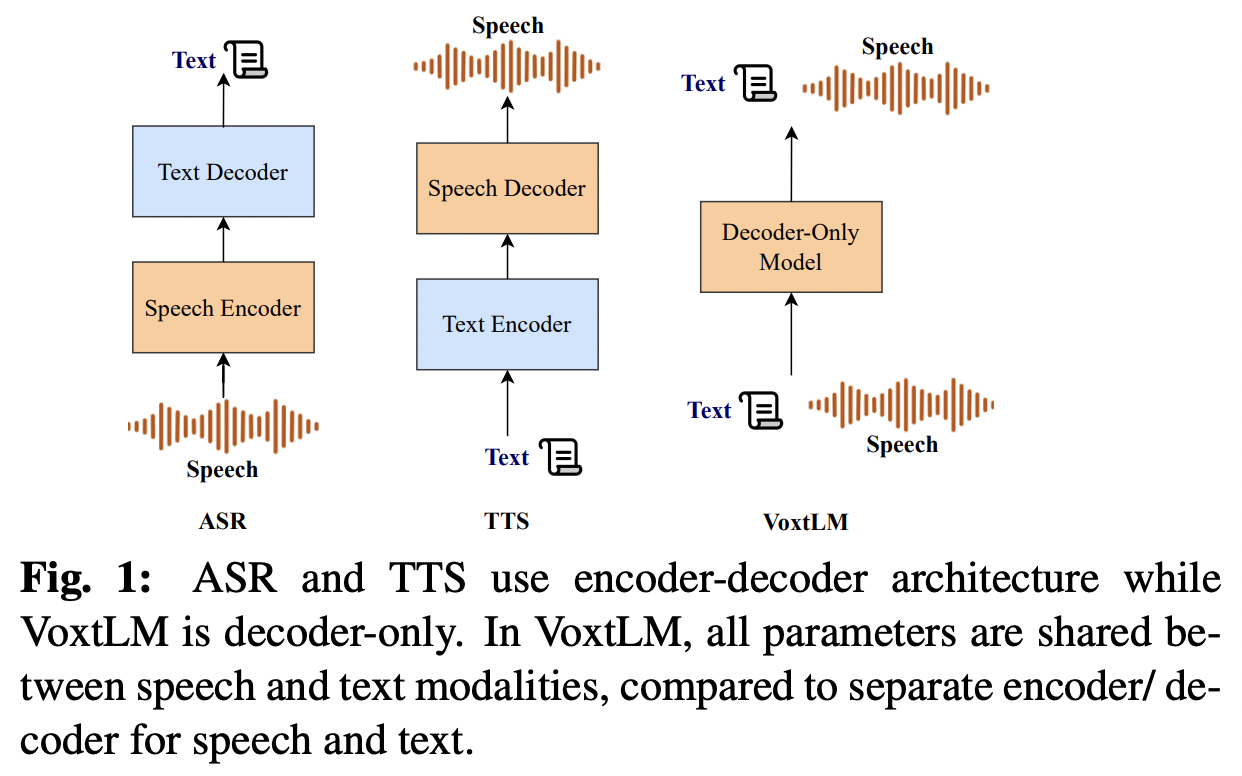
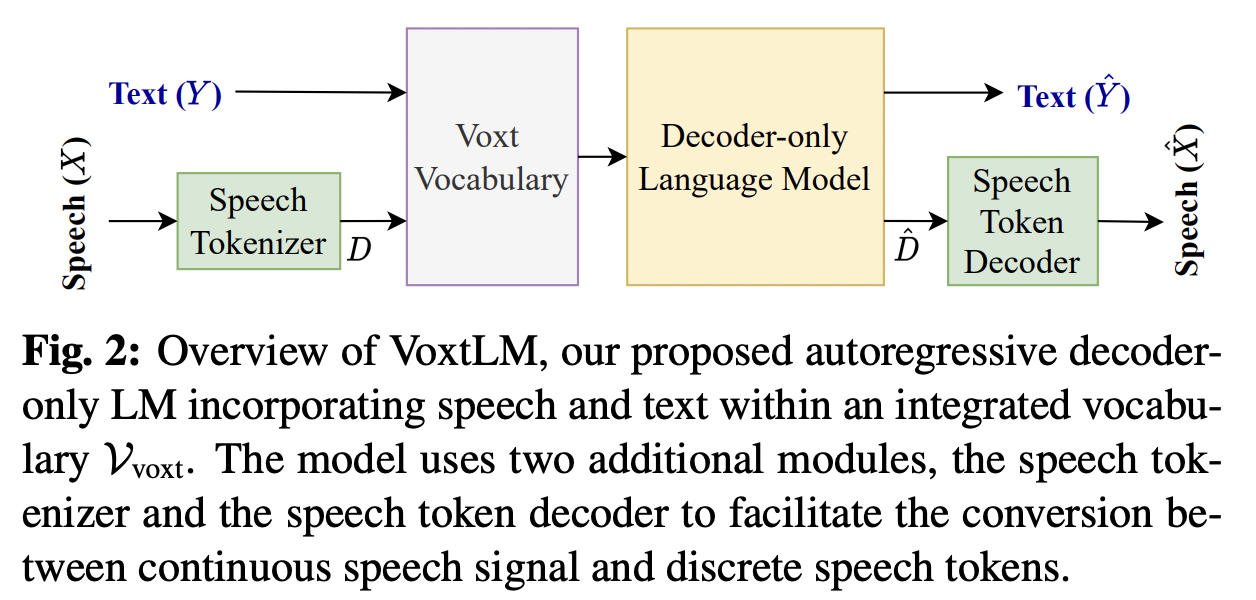
[1] VoxtLM (2024)
( Title: Voxtlm: Unified decoder-only models for consolidating speech recognitionsynthesis and speech, text continuation tasks )
- Can perform four tasks:
- (1) Speech recognition
- (2) Speech synthesis
- (3) Text generation
- (4) Speech continuation.
- How? Integrates (a) + (b)
- (a) Text vocabulary
- (b) Discrete speech tokens
- With: Self-supervised speech features & Special tokens to enable multitask learning

LLM-based systems have introduced new functionalities!
\(\rightarrow\) E.g., Generation of descriptive text, summaries, and even translations based on audio input.
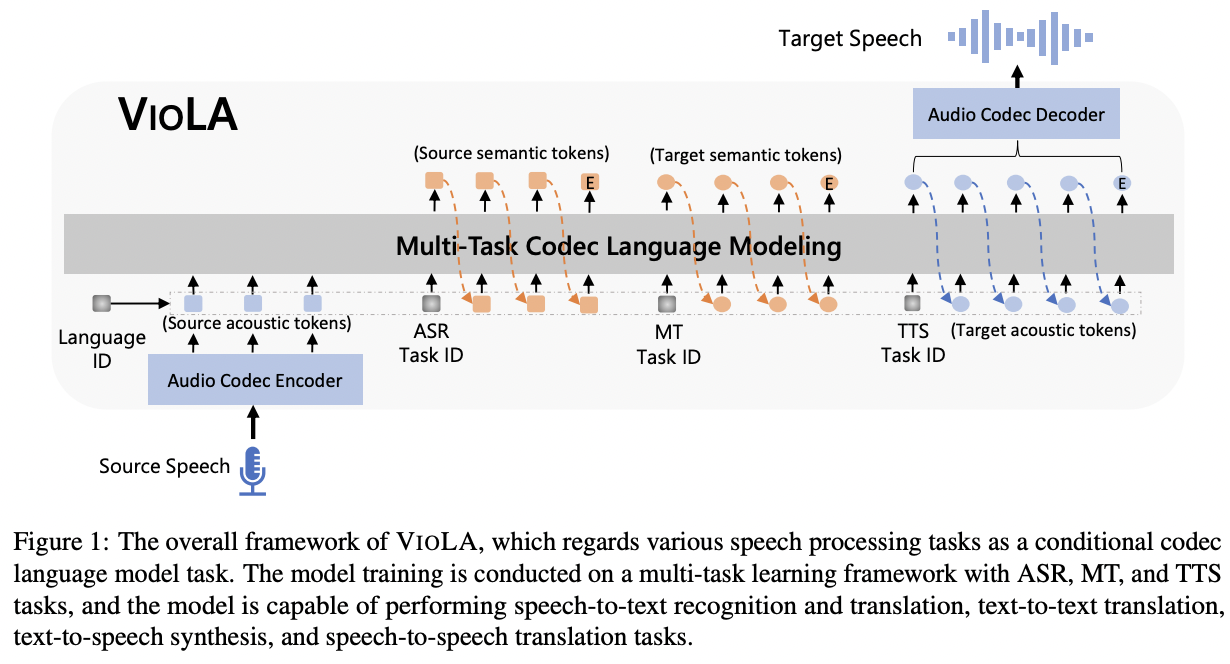
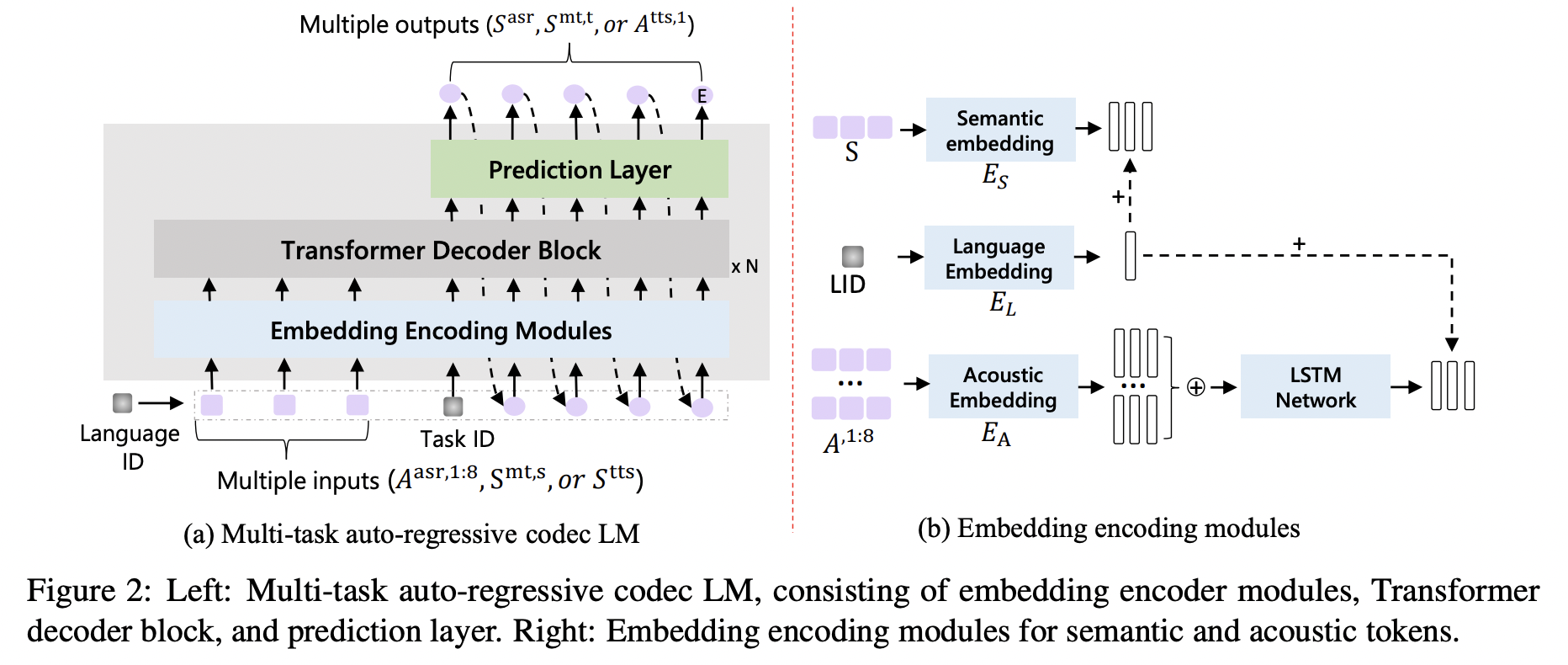
[2] ViOLA (2023)
( Title: VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation )
-
Proposal: VIOLA
- Single auto-regressive Transformer decoder-only network
- Unifies various crossmodal tasks involving speech and text!
- e.g., speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks
- Conditional codec language model task via multi-task learning framework.
-
Details:
-
(1) Convert all the **Speech \(\rightarrow\) Discrete tokens **
- with an offline neural codec encoder
\(\rightarrow\) All the tasks are converted to token-based sequence conversion problems
- Can be naturally handled with “one” conditional language model.
-
(2) Integrate “task IDs (TID)” and “language IDs (LID)” into the proposed model
-
-
Generate coherent summaries and crosslanguage translations with high fluency and accuracy,
-
Speech recognition systems can interact with and interpret complex multimodal data streams!