
A Survey on Speech LLMs
https://arxiv.org/pdf/2410.18908
Contents
4.Multimodal Information Fusion
5.Training Strategies
4. Multimodal Information Fusion
Critical issue (in Speech LLM)??
\(\rightarrow\) Alignment btw (1) audio modality & the (2) text modality
Requires 2 steps
- Step 1) Audio Feature Post-Process
- Step 2) Audio and Text Connection
Step 1) “Audio Feature” Post-Process
$\rightarrow$ Focuses on determining “what specific audio info” is needed
Tend to directly use the “final layer” output of the encoder
Approaches
-
# 1. Extract the “output of the final layer” of the encoder
- # 2. Using “intermediate layer outputs” to capture more granular features
- # 3. “Attention” mechanisms to emphasize relevant parts of the audio signal
Step 2) Audio & Text Connection
$\rightarrow$ Addresses how to “effectively combine” these two types of information.
Audio feature must be integrated with the textual modality!
\(\rightarrow\) To enable the LLM to perform the final inference.
Classified into 2 categories:
- (1) Transforming the audio feature into the textual modality space
- (2) Merging the audio and textual modality spaces
a) “Audio-to-Text” Modality Conversion
LLMs are primarily designed for “TEXT”modalities!
- How? Employ “projector”
- To transform the extracted audio modality features
- Effect? Minimizes modifications to the LLM
Two common methods are employed!
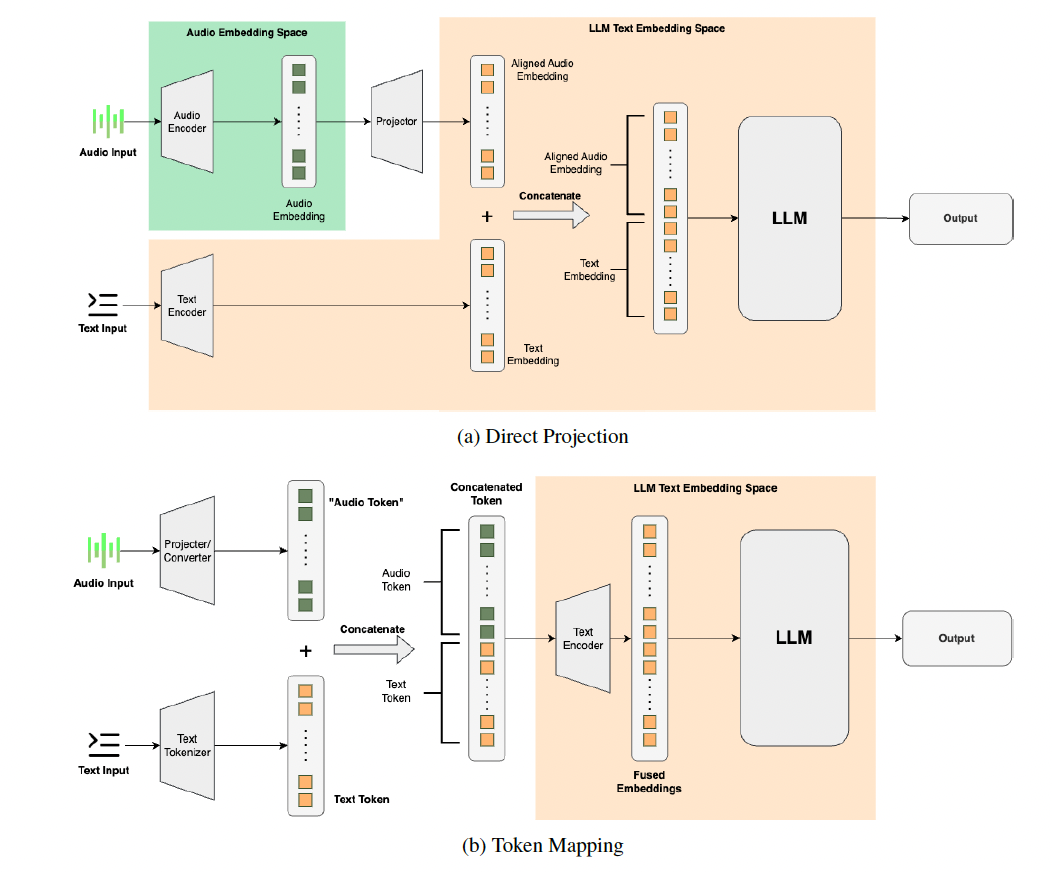
(1) Direct Projection
- Step 1) Projection
- Directly projected into the LLM’s text feature space
- Step 2) Concatenate
- Audio embeddings are then concatenated with the input text’s embedding vector
- Step 3) Feed to LLM
(2) Token Mapping
-
Step 1) Map into tokens
- Audio feature information is mapped into text tokens
-
Step 2) Concatenate
-
Audio tokens are combined with the text tokens
\(\rightarrow\) Token sequence that includes both audio and text info
-
-
Step 3) Feed to LLM
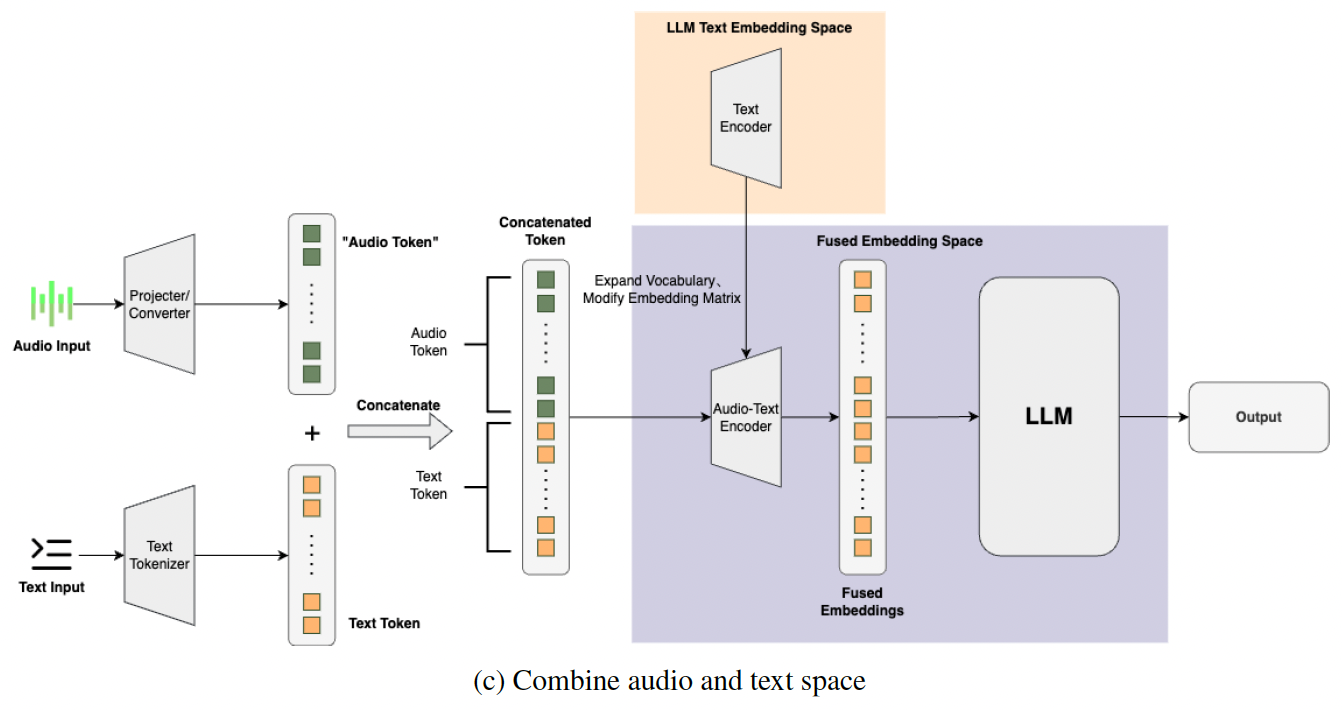
b) “Combining” Audio and Text Feature Space
Above method: Does not achieve lossless modality fusion in the true sense
\(\rightarrow\) Information loss may occur during modality conversion!
Solution: Modify the original input space of the LLM to integrate the audio modality
- Augments the token space by adding audio tokens on top of the existing text tokens, creating a new token space.
5. Training Strategies
Training of current Speech LLMs: 3 approaches
- (1) Pretraining
- (2) Supervised fine-tuning (SFT)
- (3) Reinforcement learning (RL)
(1) Pretraining
-
Dataset: Audio-text pairs
- Common strategies: SSL
- To better integrate speech encoders with LLMs, some researchers attempt to re-pretrain speech encoders
- Thorough re-training of multimodal large models is necessary!
(2) Supervised Fine-Tuning (SFT)
$\rightarrow$ Further fine-tuning is often required!
Supervised fine-tuning
- Common approach
- Labeled data from downstream task datasets is used to train the model
- To achieve alignment between the (1) speech encoder and the (2) LLM
- To enhance performance on specific tasks
- Common training methods:
- (1) Fine-tuning connectors
- (2) Fine-tuning the encoder
- (3) LLMs
- Involves handling modality alignment and completing the model’s learning of text-token mapping
(3) Reinforcement Learning (RL)
Commonly used method in training LLMs
- Especially in the field of safety alignment
Ensures that the LLM optimizes in the desired direction!