
Diffusion Models and Representation Learning: A Survey
https://arxiv.org/pdf/2407.00783
Contents
3. Methods
Methods related to diffusion models and representation learning
Section 3.1
-
Current frameworks utilizing “representations learned by pre-trained diffusion models”
( for downstream recognition tasks )
Section 3.2
- Methods that leverage advances in representation learning to improve diffusion models themselves
(1) Diffusion Models for Representation Learning
CL & Diffusion
(1) **Contrastive learning **: Not fully self-supervised!!
\(\because\) Require supervision in the form of augmentations!
(2) Diffusion models
-
Promising alternative to CL in representation learning!
-
Denoising process = Encourages the learning of semantic image representations
\(\rightarrow\) Can be used for downstream recognition tasks.
-
Similar to the learning process of Denoising Autoencoders (DAE)
Diffusion vs. DAE
-
Main difference?
\(\rightarrow\) Diffusion models additionally take the diffusion timestep \(t\) as input
\(\rightarrow\) Can thus be viewed as multi-level DAEs with different noise scales
-
DAEs learn meaningful representations! Why not diffusion model?
a) Leveraging intermediate activations
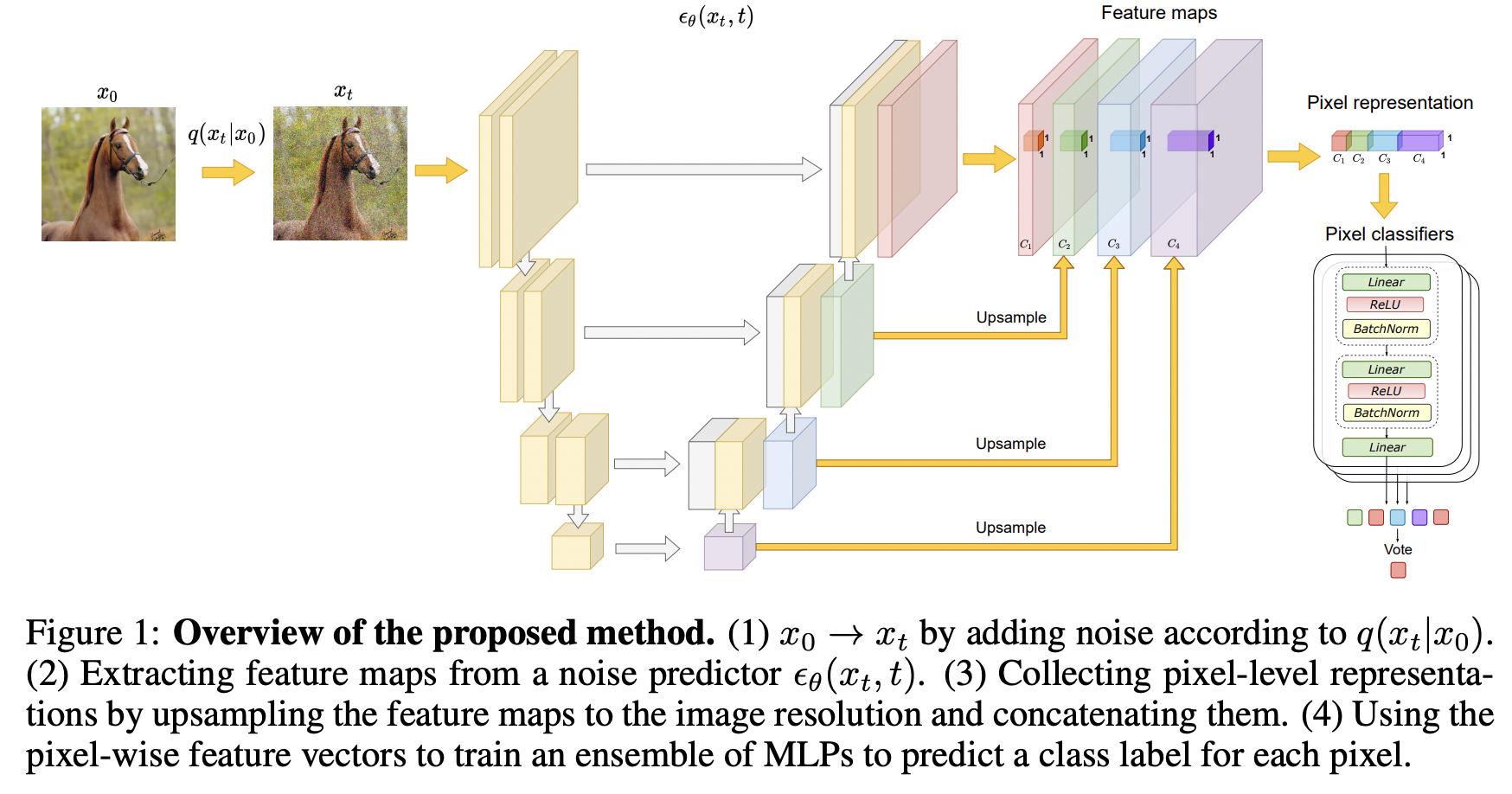
DDPM-Seg
-
Investigate the intermediate activations from the U-Net
\(\rightarrow\) These activations capture semantic information!
( Can be used for downstream semantic segmentation )
-
How to select the “ideal diffusion timestep” and “decoder block activation” to extract ??
\(\rightarrow\) Need to understand the Pixel-level representations of different decoder blocks!
- Train an MLP to predict the semantic label
- From features produced by different decoder blocks on a specific diffusion step \(t\).
- Details
- Fixed set of blocks \(B\) of the pre-trained U-Net decoder
- Higher diffusion timesteps are upsampled to the image size (using bilinear interpolation) and concatenated
- Ensemble of independent MLPs which predict a semantic label for each pixel.
- Final prediction = By majority voting.
DDAE (Denoising Diffusion Auto Encoder)
-
Examine whetehre DAE can acquire discriminative representations for classification via generative pre-training!
- DDAE
- Unified self-supervised learners
- By pre-training on unconditional image generation, DDAE has already learned strongly linear-separable representations within its intermediate layers without auxiliary encoders!
- Diffusion pre-training = General approach for generative-and-discriminative dual learning
- Denoising
- \(x_t=\alpha_t x_0+\sigma_t \epsilon\).
- \(\mathcal{L}_{\text {denoise }}=\mid \mid D_\theta\left(x_t, t\right)-x_0 \mid \mid ^2\).
- Investigate the discriminative efficacy of extracted features …
- for different backbones (U-Net and DiT)
- under different frameworks (DDPM and EDM).
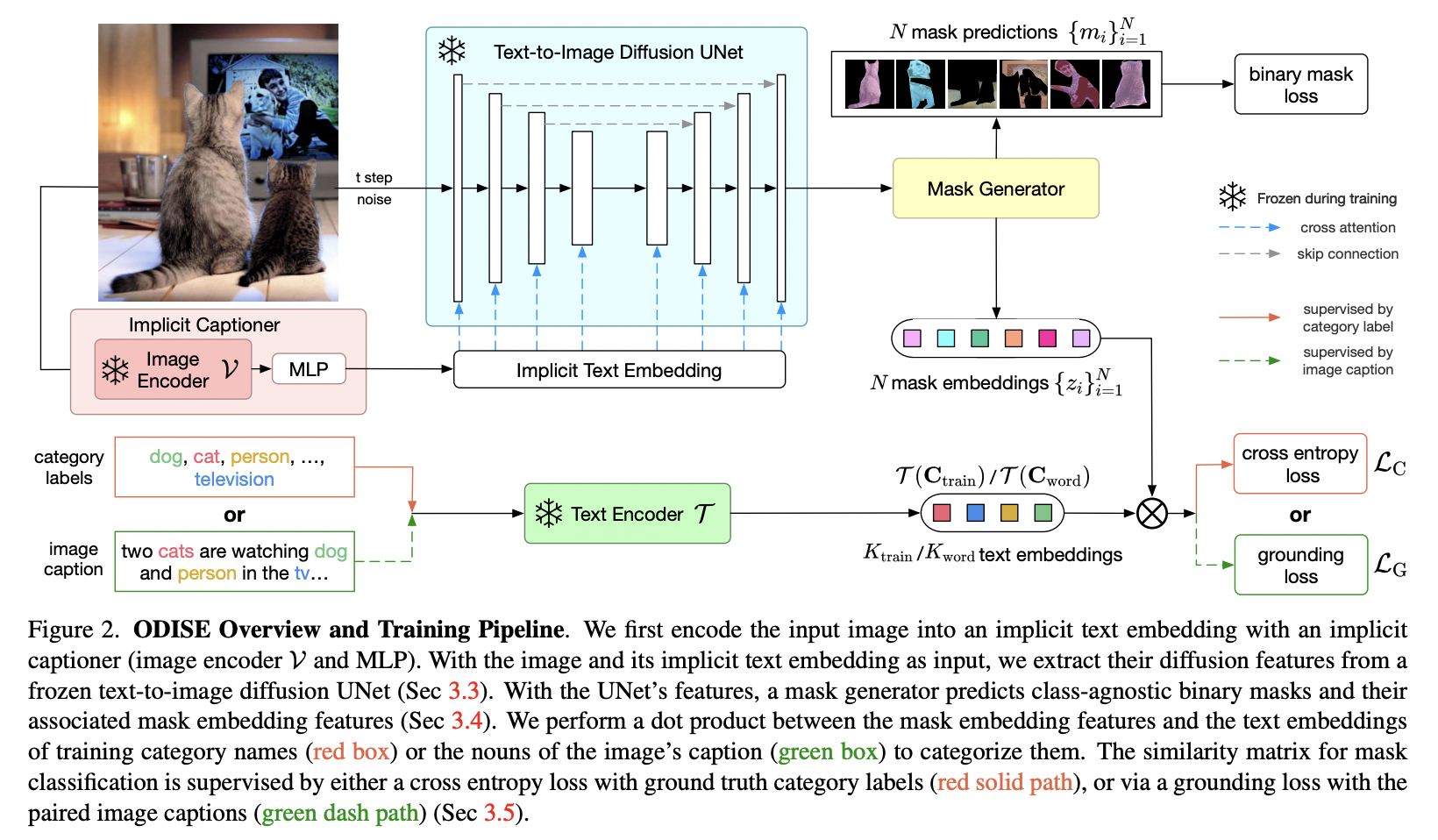
ODISE
-
Unites (1) text-to-image diffusion models with (2) discriminative models to perform panoptic segmentation
-
Extracts the internal features of a (pre-trained) text-to-image diffusion model
\(\rightarrow\)These features are input to a mask generator trained on annotated masks
- Mask classification
- Categorizes each generated binary mask into an open vocabulary category
- by relating the predicted mask’s diffusion features with text embeddings of object category names.
- Backbone: Stable Diffusion U-Net DDPM backbone
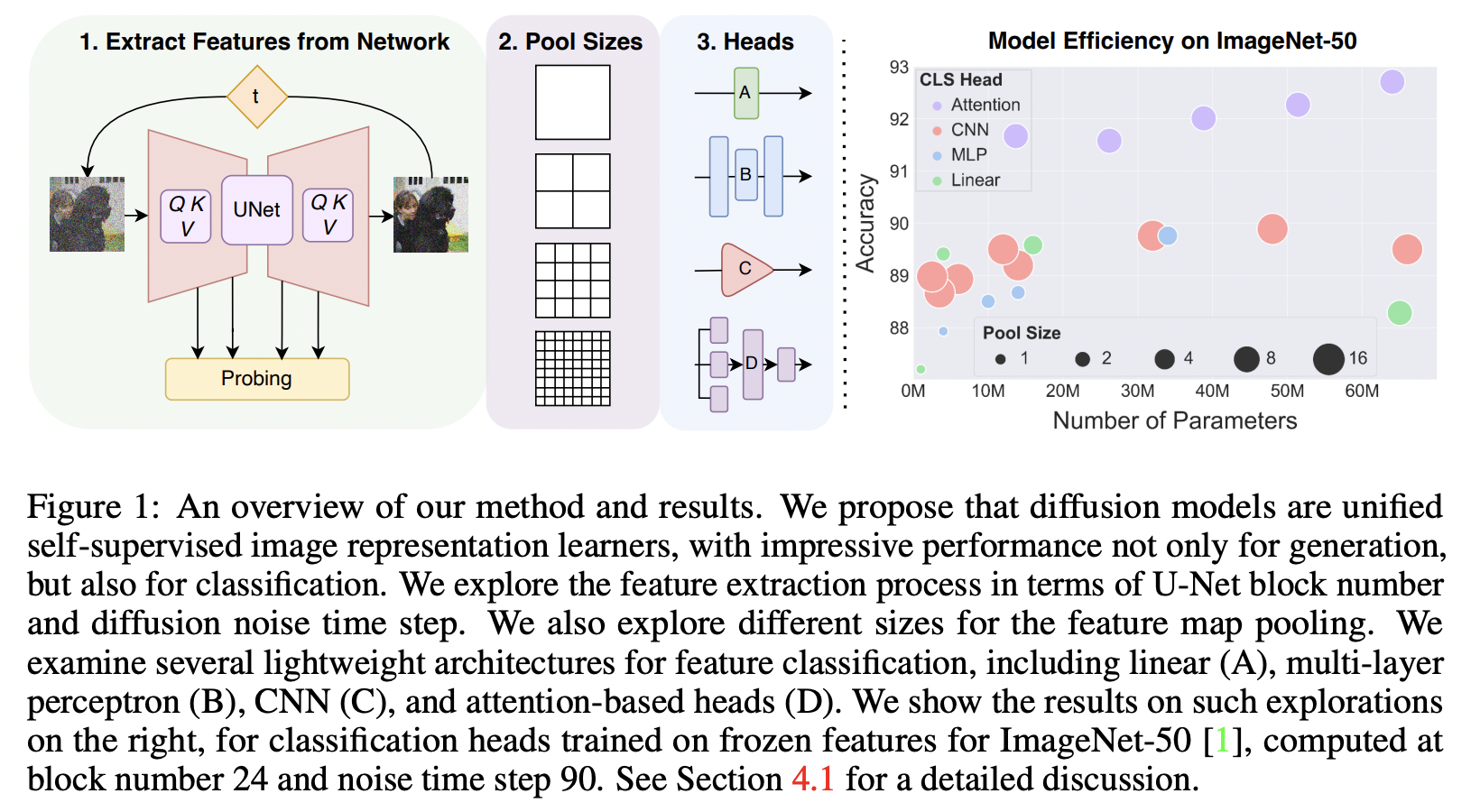
Guided diffusion classification (GDC)
- Also propose leveraging intermediate activations from the unconditional ADM U-Net architecture
- Task: ImageNet classification.
- Other experiments
- Impact of different sizes for feature map pooling
- Several different lightweight architectures for classification
- e.g., Linear, MLP, CNN, and attention-based classification heads
Extends GDC by introducing two methods for more fine-grained block and denoising time step selection
- (1) DifFormer
- (2) DifFeed
DifFormer
- Attention mechanism replacing the fixed pooling and linear classification head from [125] with an attention-based feature fusion head. This fusion head is designed to replace the fixed flattening and pooling operation required to generate vector feature representations from the U-Net CNN used in the GDC approach with a learnable pooling mechanism.
DifFeed
- dynamic feedback mechanism that decouples the feature extraction process into two forward passes. In the first forward pass, only the selected decoder feature maps are stored. These are fed to an auxiliary feedback network that learns to map decoder features to a feature space suitable for adding them to the encoder blocks of corresponding blocks. In the second forward pass, the feedback features are added to the encoder features, and the DifFeed attention head is used on top of those second forward pass features. These additional improvements further increase the quality of learned representations and improve ImageNet and fine-grained visual classification performance.
The previously described diffusion representation learning methods focus on segmentation and classification, which are only a subset of downstream recognition tasks. Correspondence tasks are another subset that generally involves identifying and matching points or features between different images. The problem setting is as follows: Consider two images \(\mathbf{I}_1\) and \(\mathbf{I}_2\) and a pixel location \(p_1\) in \(\mathbf{I}_1\). A correspondence task involves finding the corresponding pixel location \(p_2\) in \(\mathbf{I}_2\). The relationship between \(p_1\) and \(p_2\) can be semantic (pixels that contain similar semantics), geometrical (pixels that contain different views of an object) or temporal (pixels that contain the same object deforming over time). DIFT (Diffusion Features) [157] is an approach leveraging pre-trained diffusion model representations for correspondence tasks. DIFT also relies on extracting diffusion model features. Similarly to previous approaches, diffusion timestep and network layer numbers used for extraction are an important consideration. The authors observe more semantically meaningful features for large diffusion timesteps and earlier network layer combinations, whereas lower-level features are captured in smaller diffusion timesteps and later denoising network layers. DIFT is shown to outperform other self-supervised and weaklysupervised methods across a range of correspondence tasks, showing on-par performance with state-of-the-art methods on semantic correspondence specifically.