(Pytorch) Distributed Training - DDP
https://www.youtube.com/watch?v=toUSzwR0EV8
Contents
- Distributed Training?
- Gradient Accumulation
- Computational Graph
- Pytorch 코드
- DDP
- Procedure
- Collective Communication
- Rank
- DDP (Pytorch code)
1. Distributed Training?
Q1. When to use?
-
모델이 너무 커서, gpu에 올릴 수 없다!
\(\rightarrow\) 모델을 쪼개서 여러 gpu에 나눠서 올리자! Model parallelism (MP)
-
데이터가 너무 많아서, 학습에 너무 오래걸린다!
\(\rightarrow\) 데이터를 쪼개서 여러 gpu에 나눠서 올리자! Data parallelism (DP)
Q2. (거시적) 두 분류
- Vertical scaling: C급 1개 \(\rightarrow\) A급 1개
- Horizontal scaling: C급 1개 \(\rightarrow\)C급 100개
2. Gradient Accumulation
참고
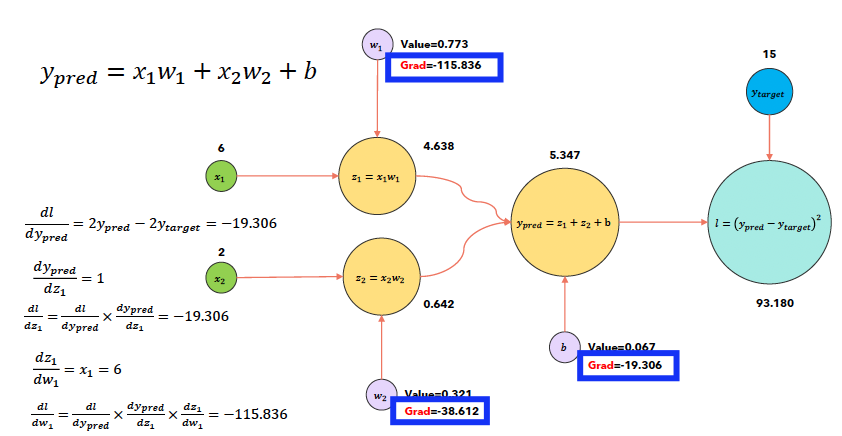
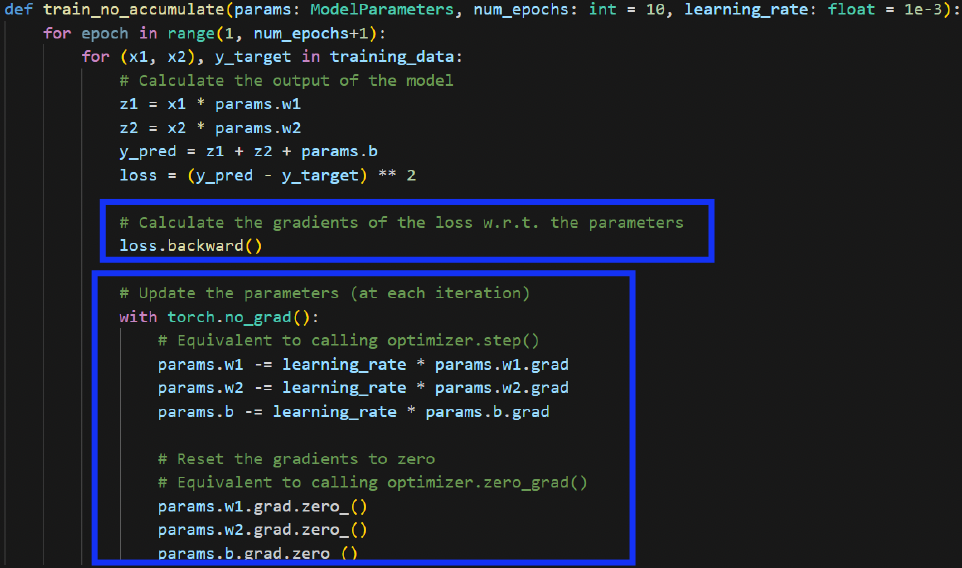
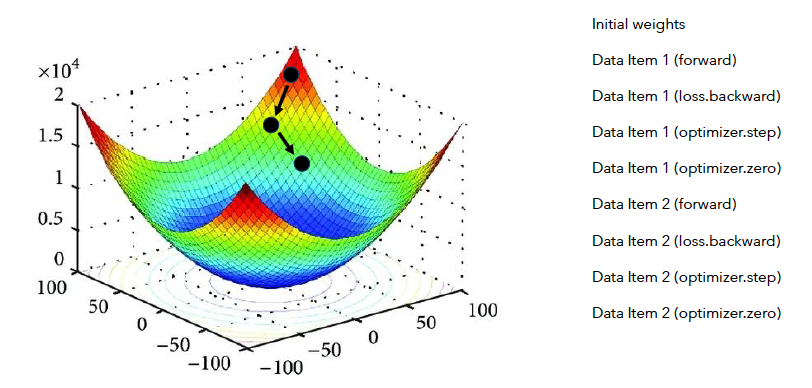
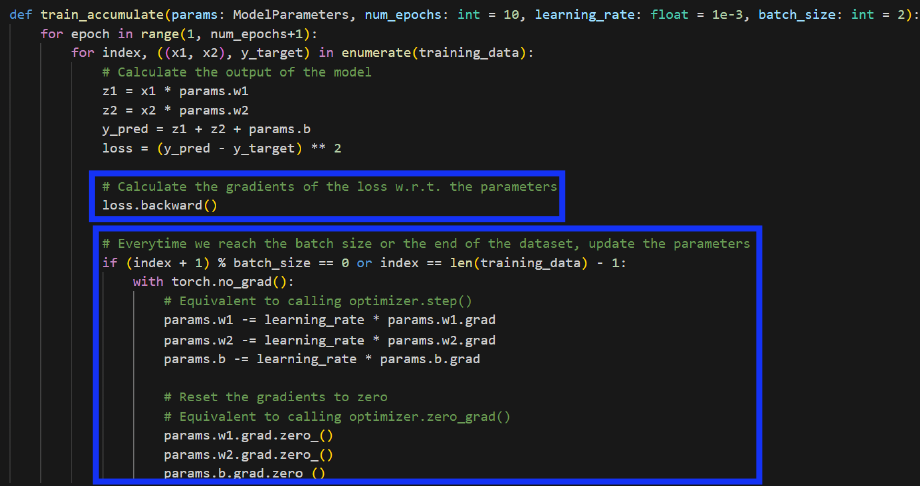
loss.backward()는 gradient를 축적(모을)뿐, 아직 update되는 것은 아니다.optimizer.step()을 해야 update가 된다.
(1) Computational Graph
a) loss.backward()시
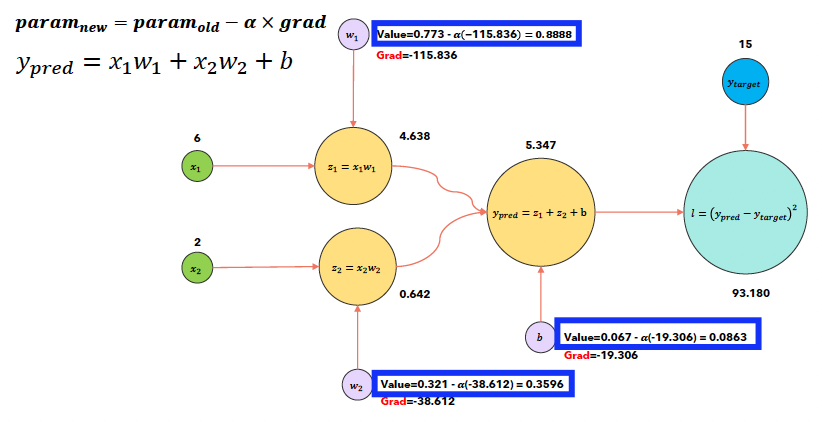
b) optimizer.step()시
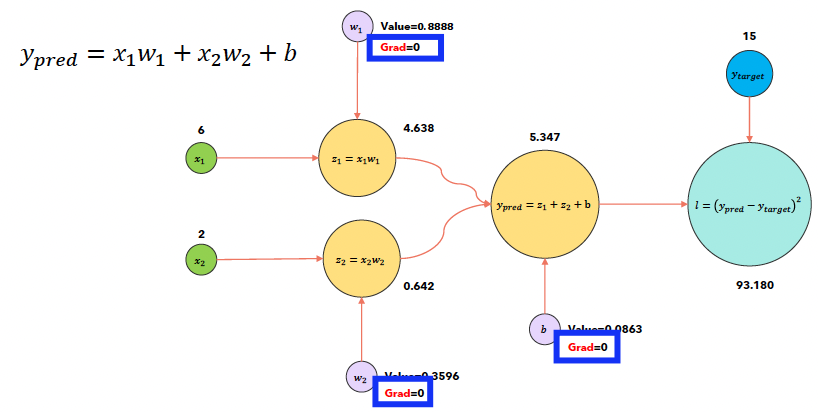
c) optimizer.zero_grad()시
(2) Pytorch 코드
a) Accumulation X
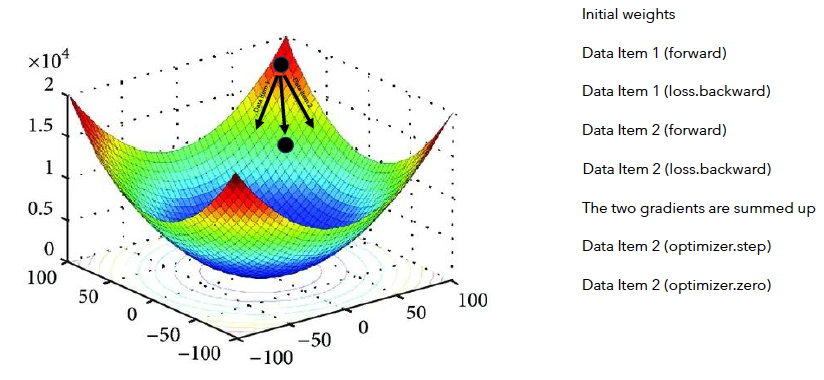
b) Accumulation O
3. DDP (Distributed Data Parallelism)
(참고: Node & GPU는 같은 것을 의미한다)
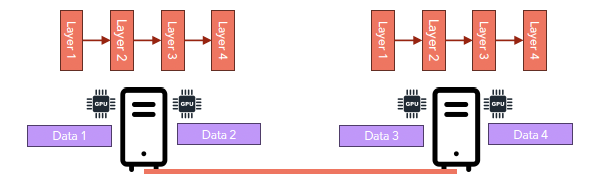
예시: 2개의 서버(컴퓨터), 각 서버에 2개의 Node(GPU)
- Server 1) Node 1-1
- Server 1) Node 1-2
- Server 2) Node 2-1
- Server 2) Node 2-2
(1) Procedure
- Step 1) Broadcast
- 모델 weight 복제하기 ( Node 1-1 \(\rightarrow\) Node 1-2,2-1,2-2 )
- Step 2) Forward & Gradient
- 각 Nodes는 각자의 data subset을 학습하여 gradient를 계산한다
- Step 3) All-reduce
- 3-1) 각 Node에서 계산한 gradient를 Node 1-1로 보내서 모은다.
- 3-2) Node 1-1은 모아진 gradient를 종합(평균)낸다
- 3-3) Node 1-1은 Node 1-2,2-1,2-2에 계산된 결과값을 보낸다.
- Step 4) Update:
- 각 노드는 각자의 optimizer를 사용하여 각자 model parameter를 update한다
(2) Collective Communication
어떠한 방식으로 gradient를 모으는지?
- 분산 학습에서 node간의 소통은 필수.
- 만약 node & server간의 소통이면, 1:1 \(\rightarrow\) point-to-point
- 만약 여러 node들 간의 소통이면, 1:N \(\rightarrow\) collective communication
**Collective communication **
- Allows to model the communication pattern between groups of nodes
Example)
1대N을 …
a) Point-to-point
- 5초 x 7 = 35초

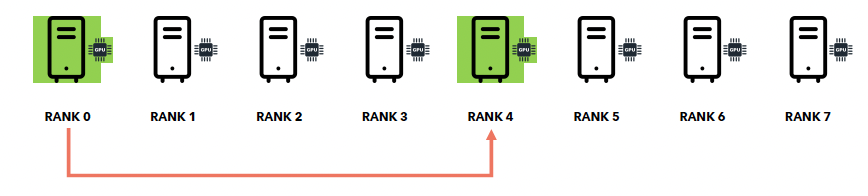
b) Collective communication: Broadcast
Broadcast = weight를 다른 gpu들로 복사하는 과정
- 5초 + 5초 + 5초 =15초
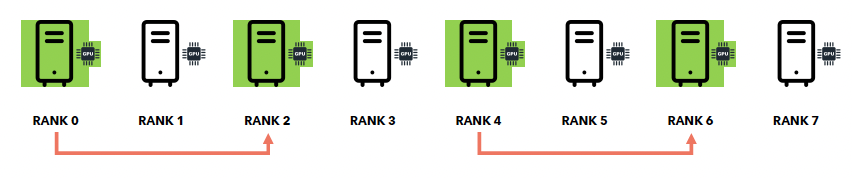

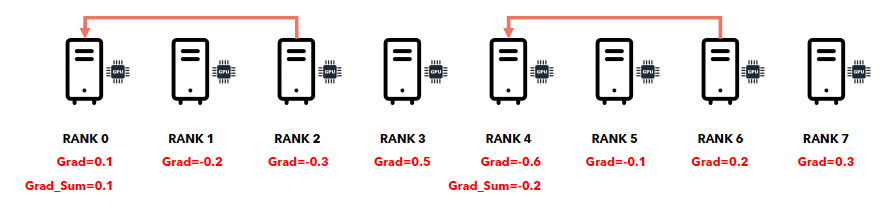
c) Collective communication: Reduce
Reduce = 각 node가 자신이 계산한 gradient를 node 1-1로 보내는 과정
- 5초 + 5초 + 5초 =15초

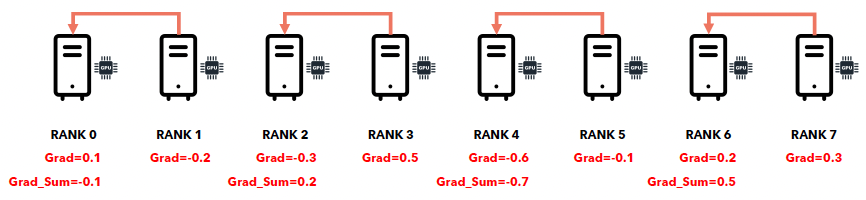
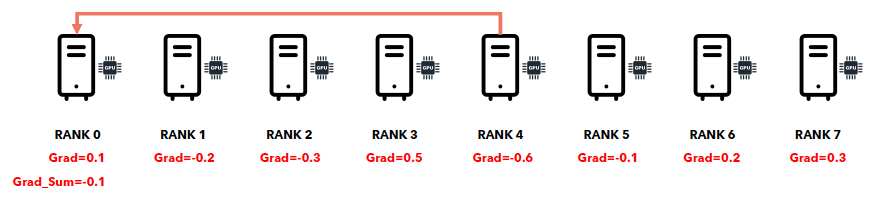
d) Collective communication: All-Reduce
All-Reduce = Reduce-Broadcast
- 둘을 각각 순차적으로 하는 것보다, 빠르게 이루어짐!
- 다만, 개념적으로는 둘을 차례로 한다고 생각하면 됨!
e) 기타: NCCL
NCCL(NVIDIA Collective Communications Library)
-
엔비디아에서 개발한 GPU 간 통신 라이브러리
-
주요 기능
-
여러 GPU 간 데이터 공유 및 동기화 ( GPU 간 직접 통신 (CPU 개입 최소화) )
-
효율적인 collective operations 지원 (예: AllReduce, Broadcast, ReduceScatter 등)
-
NVLink, PCIe, InfiniBand 등의 하드웨어 가속 지원
-
-
활용 예시
-
PyTorch의
DistributedDataParallel(DDP)에서 GPU 간 gradient 동기화 -
TensorFlow의 분산 학습에서 GPU 간 데이터 교환
-
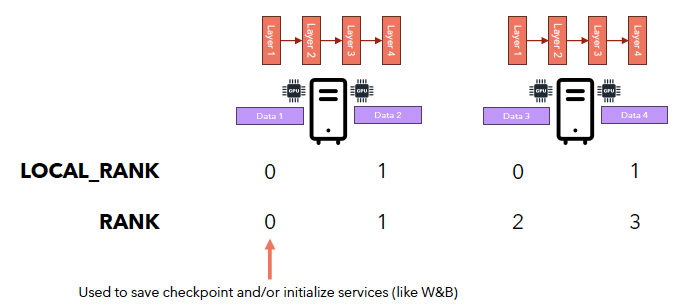
4. Rank
Local Rank vs. (Global) Rank
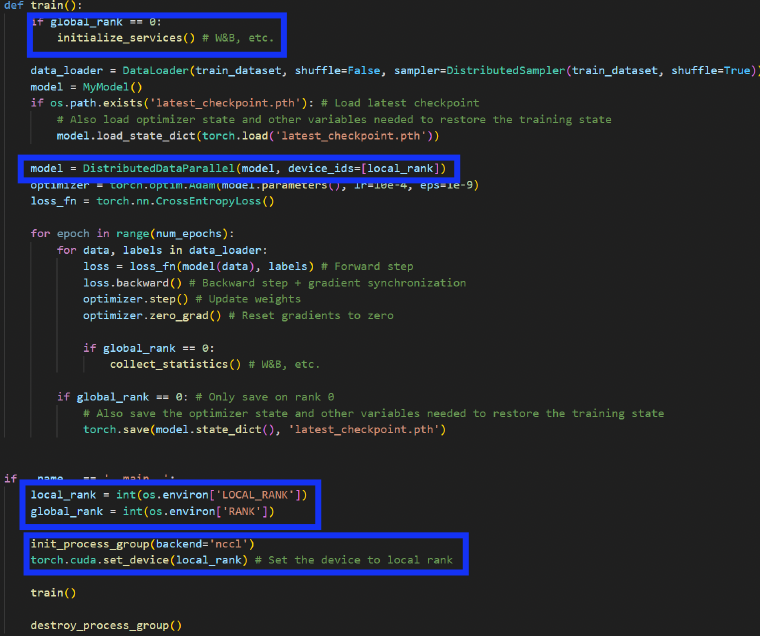
5. DDP (Pytorch Code)