How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and Outlook - Part 1
Contents
- Abstract
- Introduction
- Background and Taxonomy
- Taxonomy
- Background
- TimeAsX: Resuing Foundation Models of Other Modalities for Efficient TSA
- Time As Text
- Time As Image
- Time As Other Modalities
- Domain-Specific TS Works
Abstract
New recent field: Multiple Modalities for TSA (MM4TSA)
Q) How TSA can benefit from multiple modalities?
Discuss three benefits:
- (1) Reusing foundation models of other modalities for efficient TSA
- (2) Multimodal extension for enhanced TSA
- (3) Cross-modality interaction for advanced TSA
Group the works by the introduced modality type
- .e.g, text, images, audio, tables, and others
1. Introduction
(1) Multimodal + TS
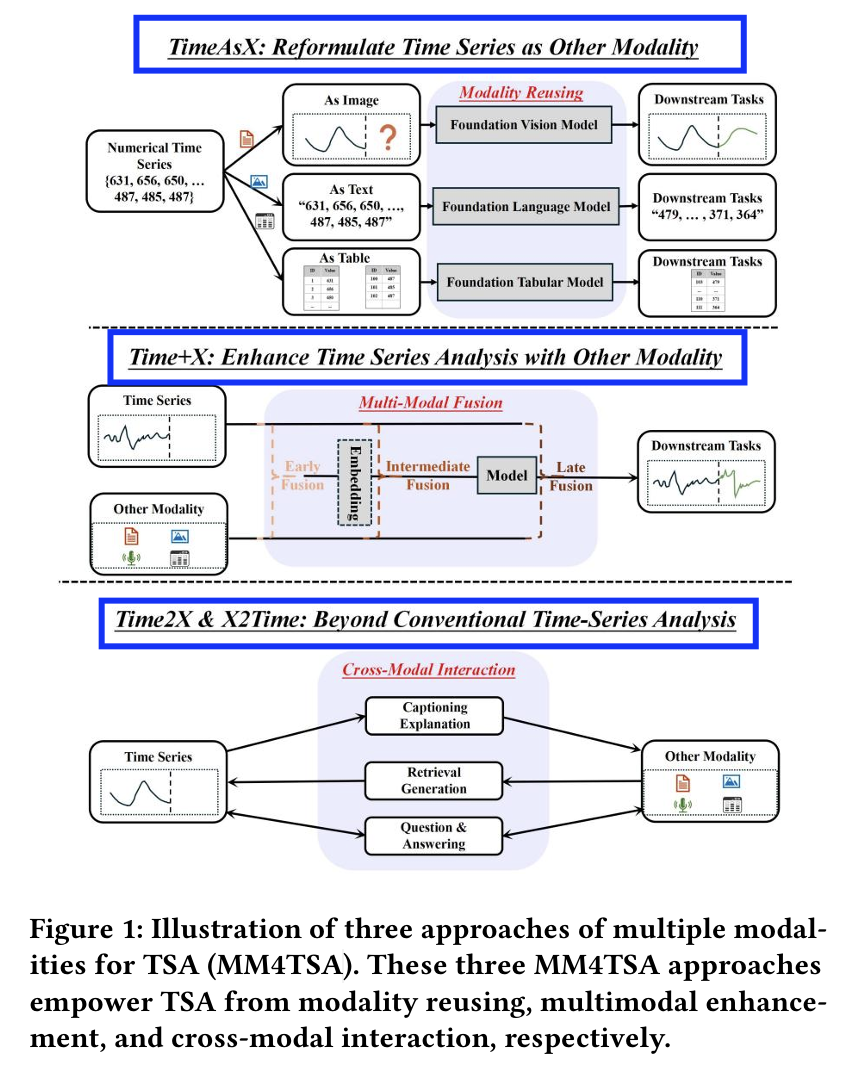
- (1) Modality reusing
- (2) Multimodal enhancement
- (3) Cross-modal interaction
Existing works: mainly focus on (1) Reusing LLMs
\(\rightarrow\) Only a sub-sub-branch!
(2) Overview
This survey paper
= First review of emerging MM4TSA field
Systematically identifies three key approaches (Figure 1)
- (1) TimeAsX: Reusing Foundation Models from Other Modalities for Efficient TSA
- (2) Time+X: Multimodal Extensions for Enhanced TSA
- (3) Time2X and X2Time: CrossModality Interaction for Advanced TSA.
Comprehensively cover multiple modalities
- e.g., language, vision, tables, and audio
Representative studies from specific domains
- e.g., finance, medical, and spatio-temporal
Identify key gaps associated with each approach:
- (1) Which modality to reuse?
- (2) How to handle heterogeneous modality combinations?
- (3) How to generalize to unseen tasks?
2. Background and Taxonomy
(1) Background
TS: \(X_{1: T}=\left\{x_1, x_2, \ldots, x_T\right\}\).
TS tasks:
-
(Basic) Forecasting, Classification, Anomaly detection, Imputation
-
(Extension) Videos, event streams
\(\rightarrow\) These data are inherently multimodal!
(2) Taxonomy
(Existing surveys: Mainly focus on reusing LLMs for TSA (i.e., our Time As Text))
3. TimeAsX: Resuing Foundation Models of Other Modalities for Efficient TSA
(Compared to TS), NLP &Vision have richer data and deeper exploration
\(\rightarrow\) Have led to many advanced foundation models
- e.g., GPT, DeepSeek, Llama, and Qwen
Question) Can we reuse these off-the-shelf foundation models from “rich” modalities for efficient TSA?
=> “TimeAsX”
- Reused modality into text, image, audio, and table
(1) Time As Text
Recent works have explored the usage of LLMs for TSA tasks
Motivation: Both language and TS have a sequence structure
Divided three groups
- a) Direct alignment without training
- b) Training for alignment under an existing vocabulary
- c) Training for alignment with an expanded vocabulary
a) Direct Alignment without Training
Key concepts
- Do not need any update to LLM
- Mainly focus on how to input TS data as text input
- Two cateogires
- (1) Better Tokenization
- (2) Task-specific Prompting
(1) Better Tokenization
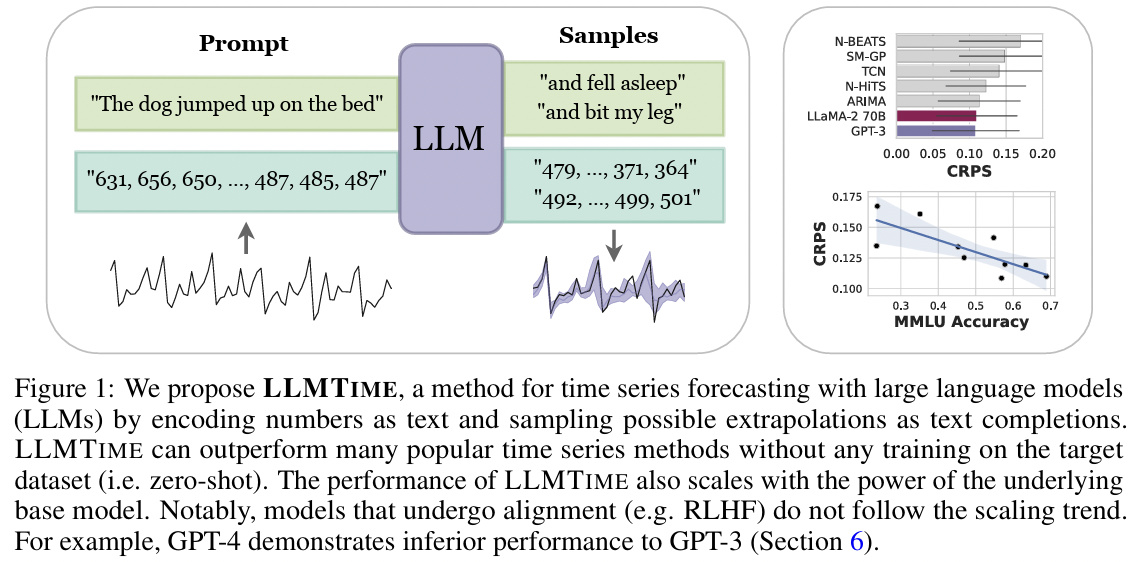
LLMTime[58]: Inputs the TS data as text to the LLM- Title: Large Language Models Are Zero-Shot Time Series Forecasters
- https://arxiv.org/pdf/2310.07820
(2) Task-specific Prompting
- Carefully prompting the LLMs to provide context about the TS domain and task.
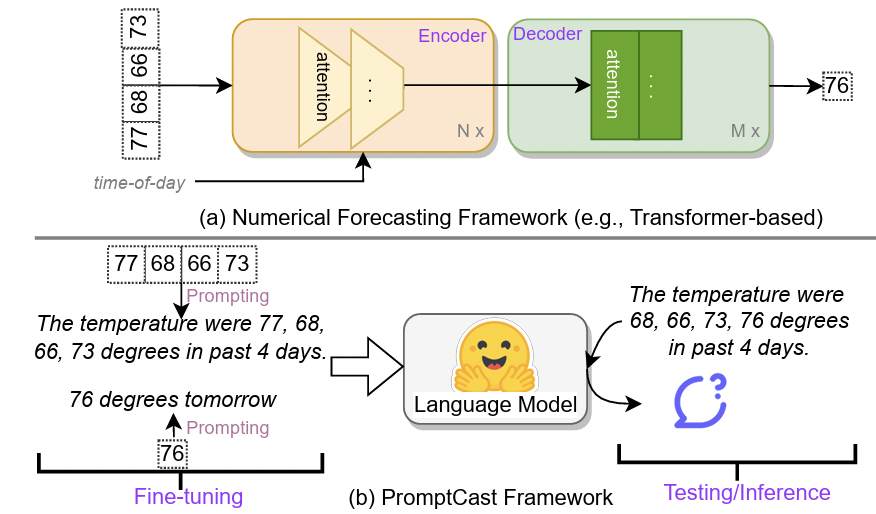
PromptCast[204]: Provides specific text prompts to LLMs- Prompts: Contain information such as domain information
- e.g., Time-step, task and past time-series values
- Title: PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting
- https://arxiv.org/pdf/2210.08964
- Prompts: Contain information such as domain information
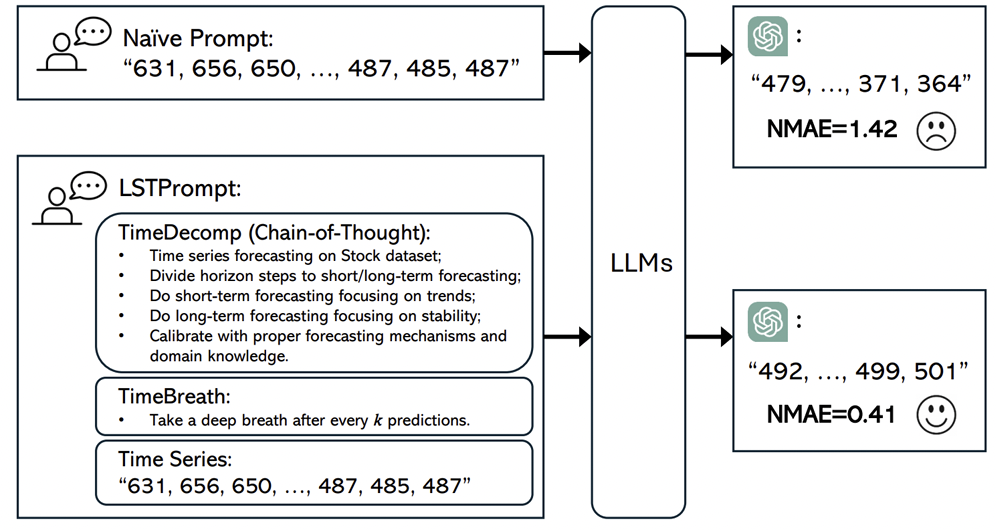
LSTPrompt[124]: Uses more sophisticated CoT prompting- Provide useful sequence of steps for LLMs to reason about TS
- Focusing on different trends and patterns for long and short term forecasting.
- Title: LSTPrompt: Large Language Models as Zero-Shot Time Series Forecasters by Long-Short-Term Prompting
- https://arxiv.org/pdf/2402.16132
LLMTime
PromptCast
LSTPrompt
b) Training for Alignment Under Existing Vocabulary
Aligns TS with LLMs by treating TS as a sentence in a known vocabulary
Background
- Dimension of both language vocabulary and TS patches are high!
- \(\rightarrow\) Simplify the training procedure by correlating to objectives from certain TS tasks
Solution: LLMs will be treated as TS models by adding time-to-text transformation modules (and modules vice versa)
Categorized into…
- (1) Embedding alignment
- (2) Prototype alignment
- (3) Context alignment
(1) Embedding Alignment
-
TS is aligned to existing vocabulary by training the initial and final layers as projections from TS to language vocabularies (or vice versa)
-
aLLM4TS[217],OneFitsAll[234]-
Use a frozen LLM backbone
-
Generate patch embeddings of TS datasets & feed to LLM
-
Embedding layer & Output layer
\(\rightarrow\) Fine-tuned on the TS data
- [217] Title: Multi-Patch Prediction: Adapting LLMs for Time Series Representation Learning
- [217] https://arxiv.org/pdf/2402.04852
- [217] Title One fits all: Power general time series analysis by pretrained lm
- [217] https://arxiv.org/pdf/2302.11939
-
-
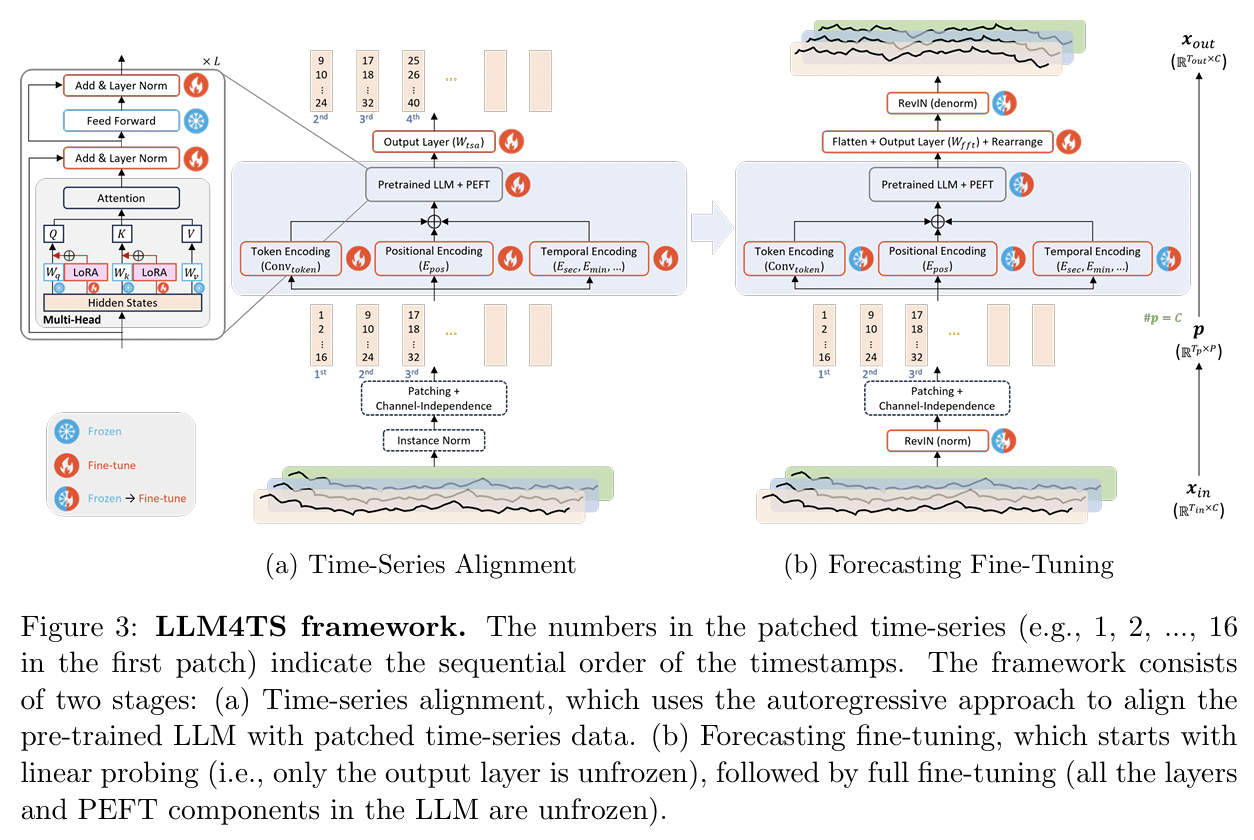
LLM4TS[32]: Additionally fine-tunes the LNs- Title: LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters
- https://arxiv.org/pdf/2308.08469
(2) Prototype Alignment
- Train input modules to map TS values into fixed embeddings (prototypes) that are closer to embedding space of pre-trained distribution
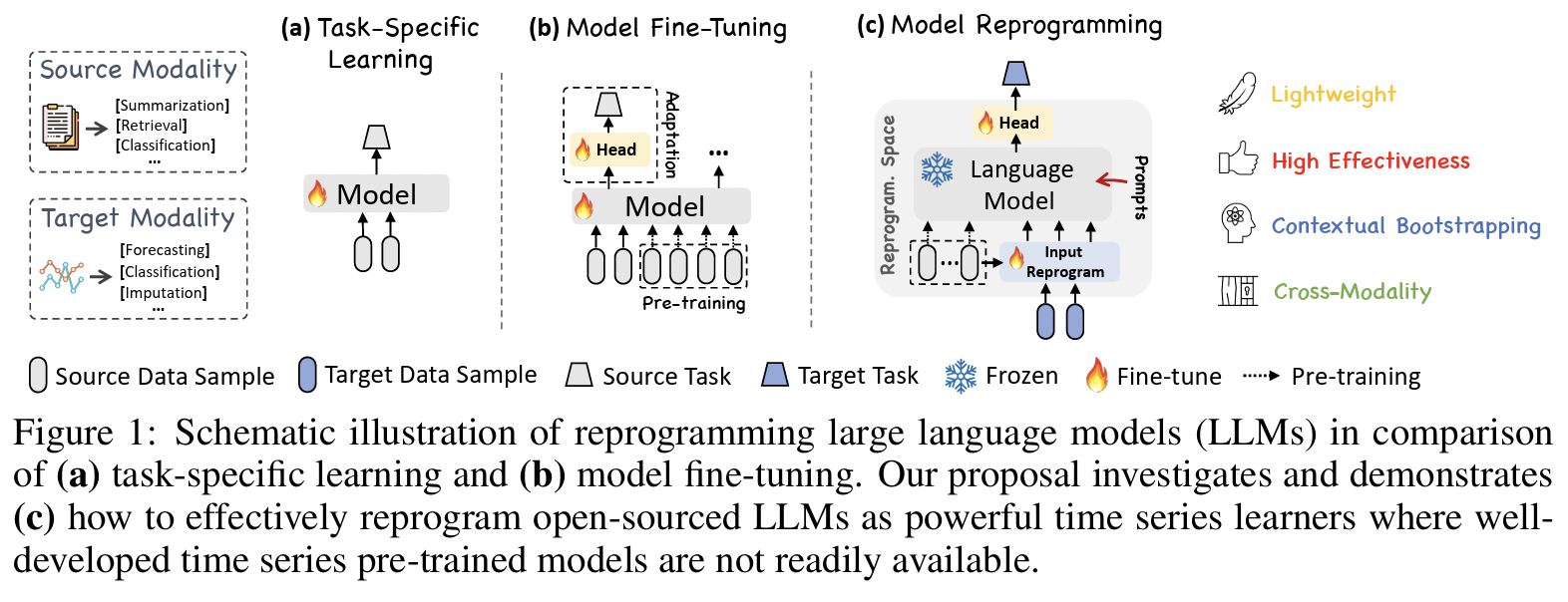
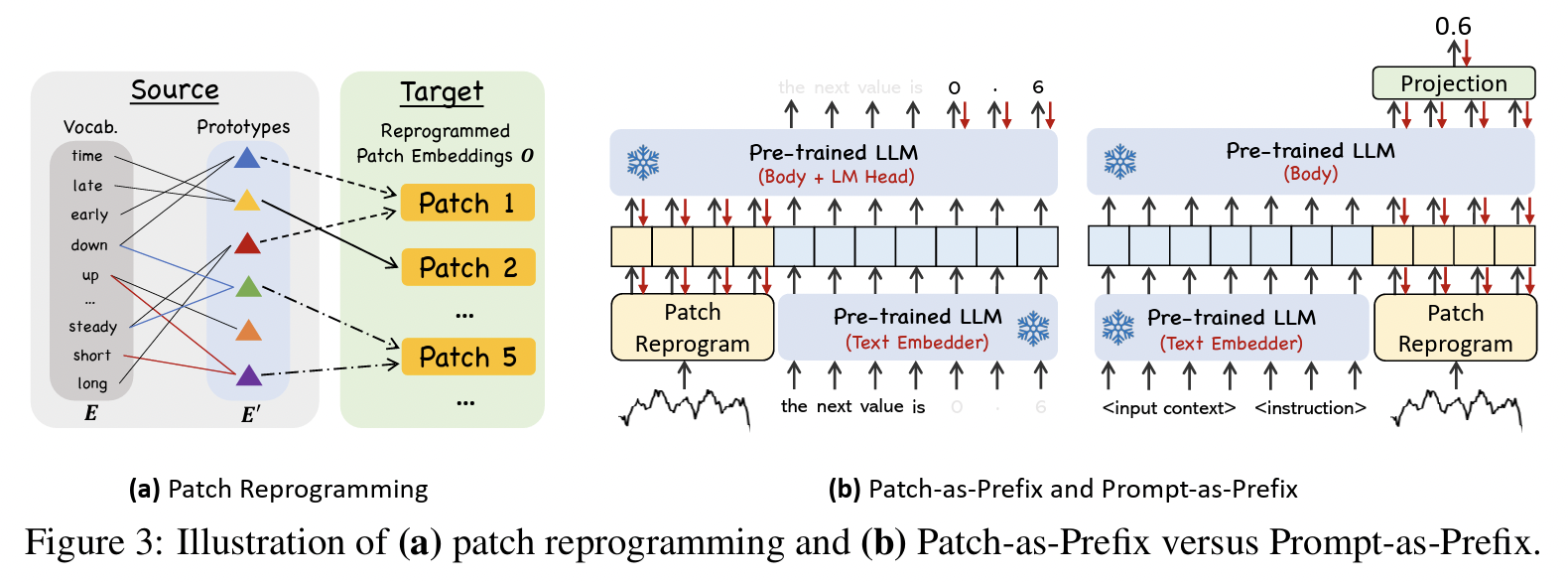
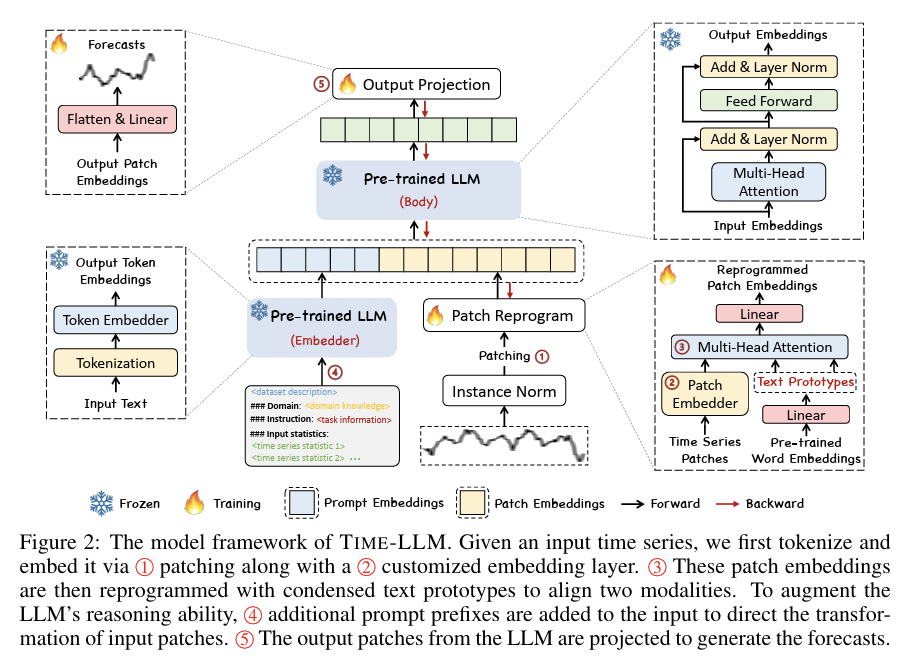
TimeLLM[141]:- Combines text-based prompting with patch-based input
- Patches are reprogrammed to generate output embeddings via a trainable layer.
- Title: Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
- https://arxiv.org/pdf/2310.01728
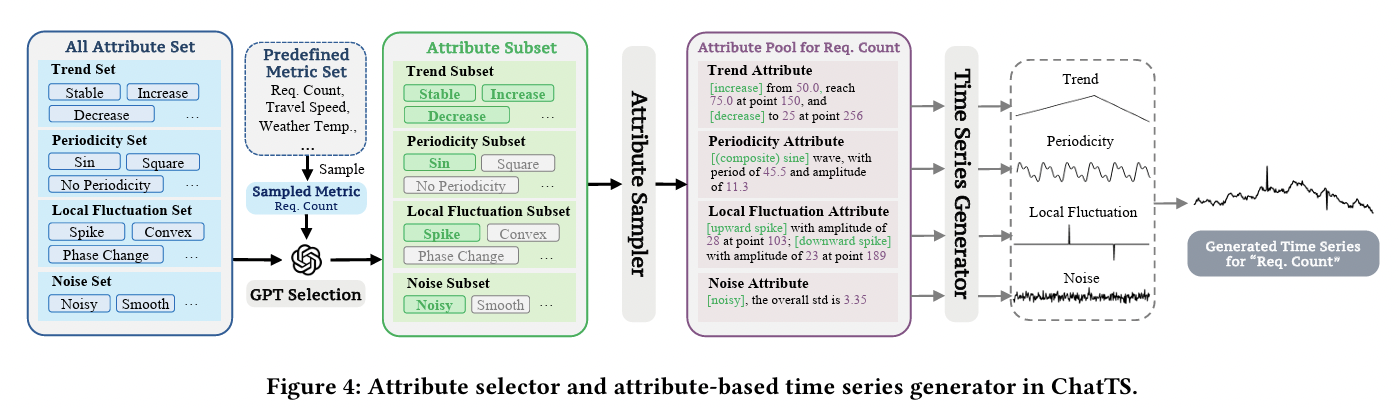
ChatTS[196]:- Uses fixed attribute descriptors that capture important TS properties
- e.g., trends, noise, periodicity, and local variance.
- Title: ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
- https://arxiv.org/abs/2412.03104
- Uses fixed attribute descriptors that capture important TS properties
(3) Context Alignment
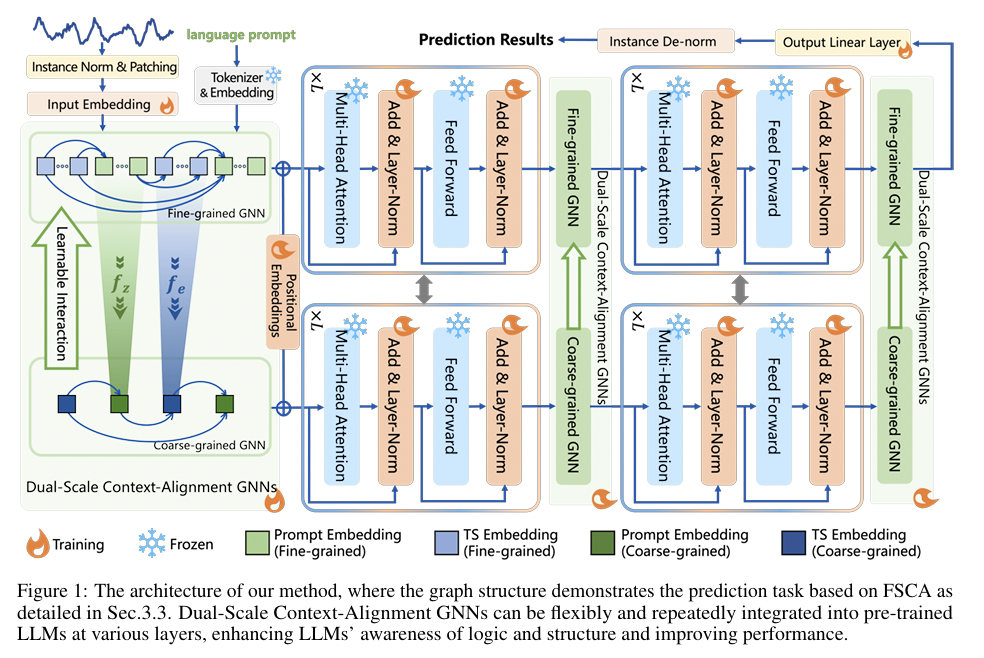
FSCA[68]- Identifies the need to more intricately align text context with TS when fed together as input embeddings.
- Employ GNN to model the interaction between TS & Text
- Train together with embedding and LN layers of LLM when pre-training.
- Title: Context-Alignment: Activating and Enhancing LLM Capabilities in Time Series
- https://arxiv.org/abs/2501.03747
aLLM4TS
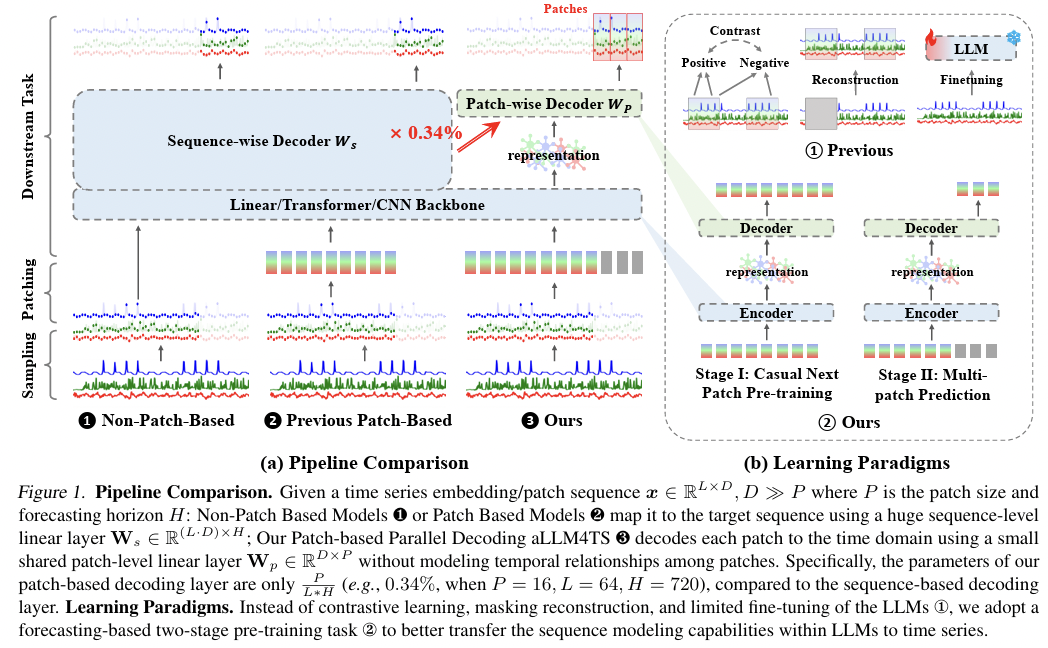
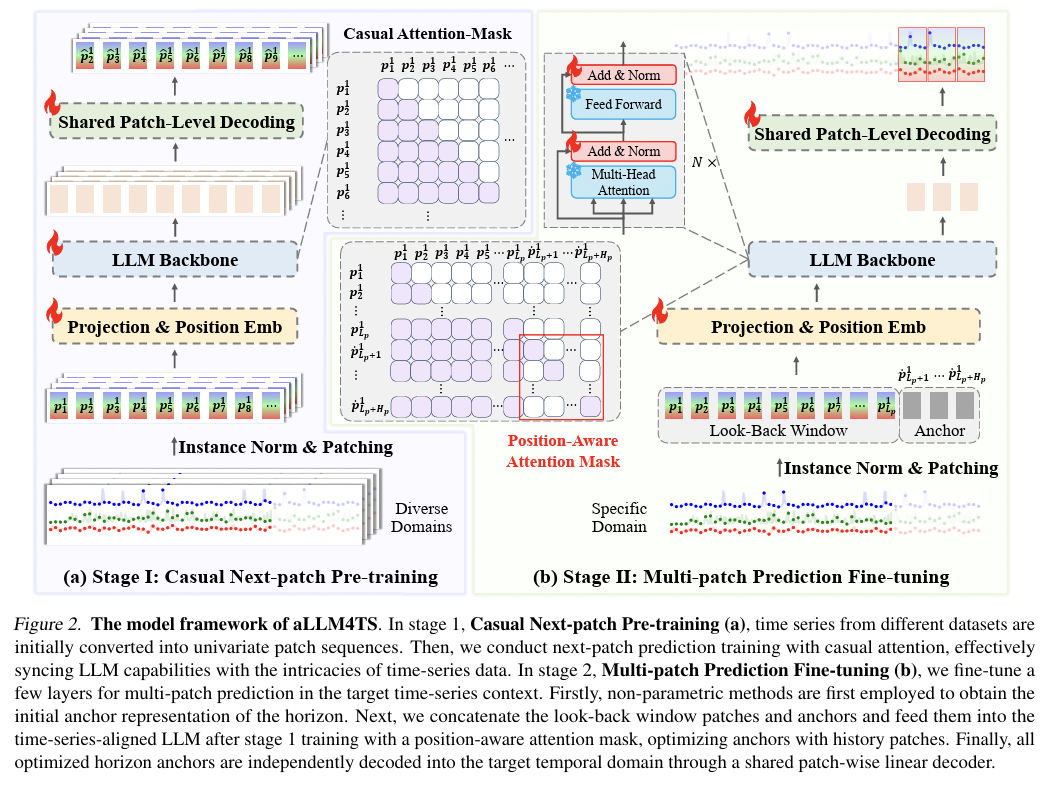
OneFitsAll
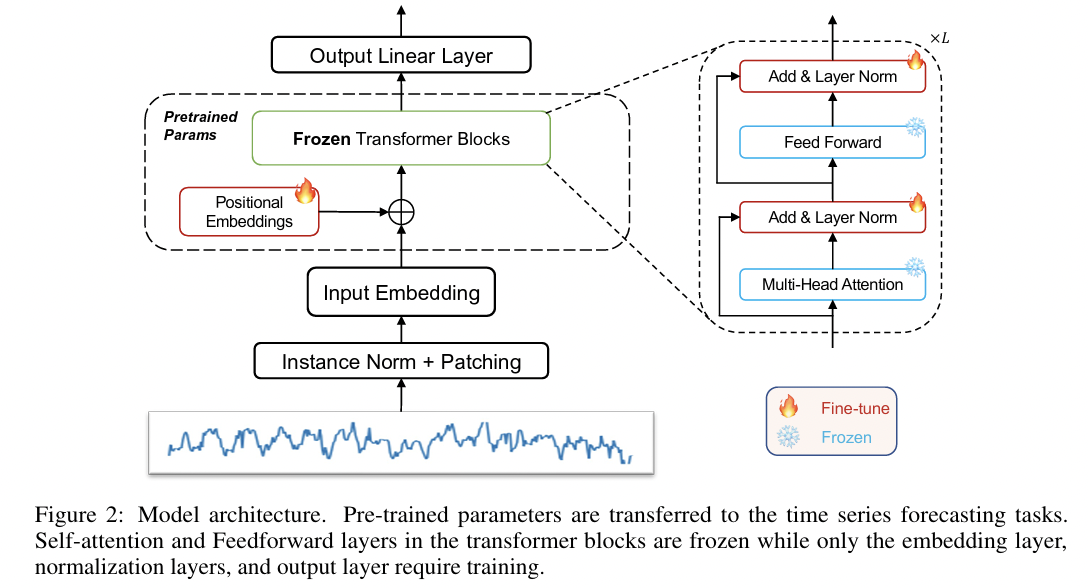
LLM4TS
TimeLLM
ChatTS
FSCA
c) Training for Alignment with Expanded Vocabulary
Expand LLM vocabulary to align with TS datasets
Treat TS data as sentences in a foreign language
\(\rightarrow\) Adapt the LLMs toward such a language!
Differ in how they design the adaptor functions to map TS to expanded vocabulary.
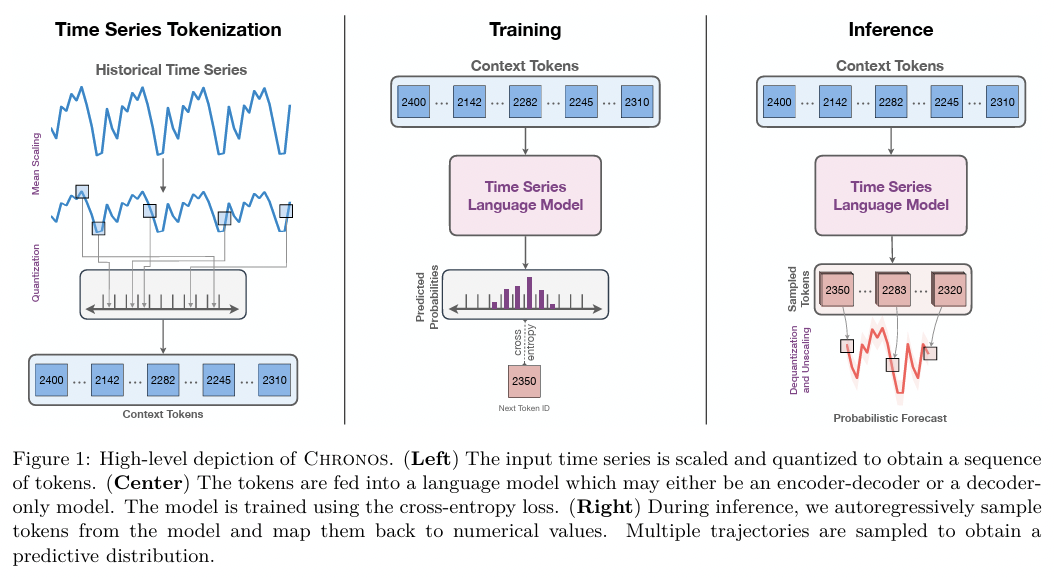
Chronos [7]
- Quantizes the normalized input TS values into discrete tokens
- Title: Chronos: Learning the Language of Time Series
- https://arxiv.org/pdf/2403.07815
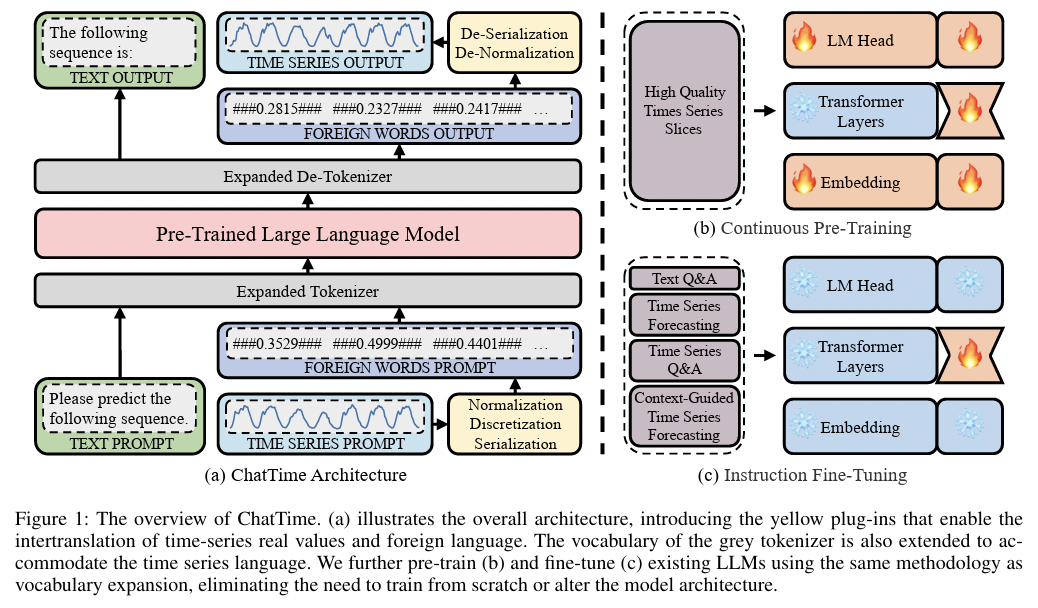
ChatTime [180]
-
Introduce additional tokens for quantized values of input TS
( as well as NaN or missing values )
-
Title: ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
-
https://arxiv.org/abs/2412.11376
Chronos
ChatTime