
Document level Multi aspect Sentiment Classification by Jointly Modeling Users, Aspects, and Overall Ratings (2018)
Contents
- Abstract
- Introduction
- 소비자 리뷰
- Multi-task Learning
- HUARN 간단 소개
- Data & Observation
- Data
- Observation
- Methods
- Formalizations
- Multi-task Learning Framework
- 사용한 모델 ( Hierarchical Bidirectional Gated Recurrent Network )
- 모델 상세 소개
0. Abstract
Document-level multi-aspect sentiment classification
-
목적 : “다양한 측면(aspect)”에서 소비자의 감정을 예측하기!
-
기존의 연구들 : 주로 “리뷰 text 그 자체”에만 주로 focus
( 한계 : 리뷰의 전체 평점(overall rating)과 리뷰 남긴사람의 선호(user preference)을 고려 X )
위의 한계를 극복하기 위해 논문은, HUARN (Hierarchical User Aspect Rating Network)를 제안
- user preference & overall rating을 jointly하게 고려한 알고리즘
- 계층적 (hierarchical) 구조를 사용함
- 구조 : word / sentence / document
- sentence 및 document representation을 얻기 위해, user attention & aspect attention 사용
- GOAL : document representation + user + overall rating, 3가지 사용하여 aspect rating 예측하기!
1. Introduction
(1) 소비자 리뷰
소비자 리뷰를 남기는 플랫폼이 많아지고 있음
- ex) Trip advisor & Yelp
이러한 리뷰를 자동적으로 분석할 필요성이 높아지고 있음!
( 리뷰의 형식 예시 )

(2) Multi-task Learning
-
“다양한” task를 푸는 “하나”의 모델
-
document-level multi-aspect sentiment classification 문제를 푸는데 적절한 방법
- input : 동일한 review
- output : 여러 종류의 aspect sentiment
-
핵심 : aspect-specific document representation
-
ex) 5문장으로 된 리뷰에서, 제품의 “발림성”과 관련된 내용은 3번째 문장에 주로 담겨있고,
제품의 “가격”과 관룐된 내용은 2번째 문장에 주로 담겨있을 수 있다!
따라서, “속성 별”로 document representation이 있을 필요가 있다!
-
(3) HUARN 간단 소개
-
abstract에서 얘기한 그대로!
-
Contribution 3가지
-
1) document-level multi-aspect sentiment classification을 수행하기 위해, Trip advisor review를 사용함 ( 유저 & 전체 평점 정보 사용 )
- 2) user preference와 overall rating을 “하나의 모델”에 통합시킨 첫 시도!
- 3) real world dataset에 적용하니 GOOD
-
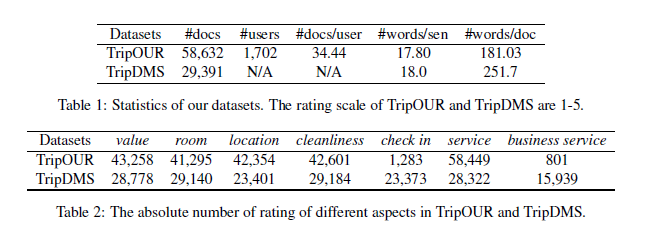
2. Data & Observation
(1) Data
Trip Advisor의 2가지 dataset을 사용함
( 둘 다 7가지 속성 (value, room, location….service)을 담고 있음 )
- data 1) TripDMS : 유저 정보 X
- data 2) TripOUR : 유저 정보 O
(2) Observation
[a] user preference
user별 2 가지 성향
- 1) user-rating consistency : 후하게 주는 사람은 늘 후하게~ 박한사람은 늘 박하게~
- 2) user-text consistency : 주로 사용하는 단어들이 사람별로 차이
위의 2가지 유저 성향 확인을 위해, 아래와 같은 가설검정을 수행함!
-
(1) 3개의 vector를 만든다 ( \(\mathbf{v}_{s}\), \(\mathbf{v}_{r}\) , \(\mathbf{v}_{a}\) )
- \(\mathbf{v}_{s_i}\) : 동일한 유저 \(i\)한테서 남겨진 두 리뷰 \(\left(d_{i}\right.\) and \(\left.d_{i}^{+}\right)\) 로부터 얻어짐
- \(\mathbf{v}_{r_i}\) : 유저 \(i\)한테서 남겨진 리뷰 \(\left(d_{i}\right.\) ) 와, 다른 random 리뷰
- \(\mathbf{v}_{a_i}\) : random한 속성
-
(2) user-rating consistency 계산
( notation : \(y\), \(y^{+}\), \(y^{-}\)는 각각 \(d,d^{+},d^{-}\)의 감정 )
- \(\mathbf{v}_{s}\) 는 \(\mid \mid y-y^{+} \mid \mid\)로 계산
- \(\mathbf{v}_{r}\) 는 \(\mid \mid y-y^{-} \mid \mid\)로 계산
-
(3) user-text consistency
- 두 리뷰의 bag-of-words의 코사인유사도
-
(4) 가설 검정 수행
-
방법 : two-sample t-test
-
\(H_{0}: \mathbf{v}_{s}=\mathbf{v}_{r}\).
\(H_{1}: \mathbf{v}_{s}<\mathbf{v}_{r}\).
-
유저 정보가 있는 dataset인 TripOUR에 대해 수행한 결과, ( 유의수준 \(\alpha=0.01\) ) 기각함!
-
결론 : 유저 정보 유의미하다!
-
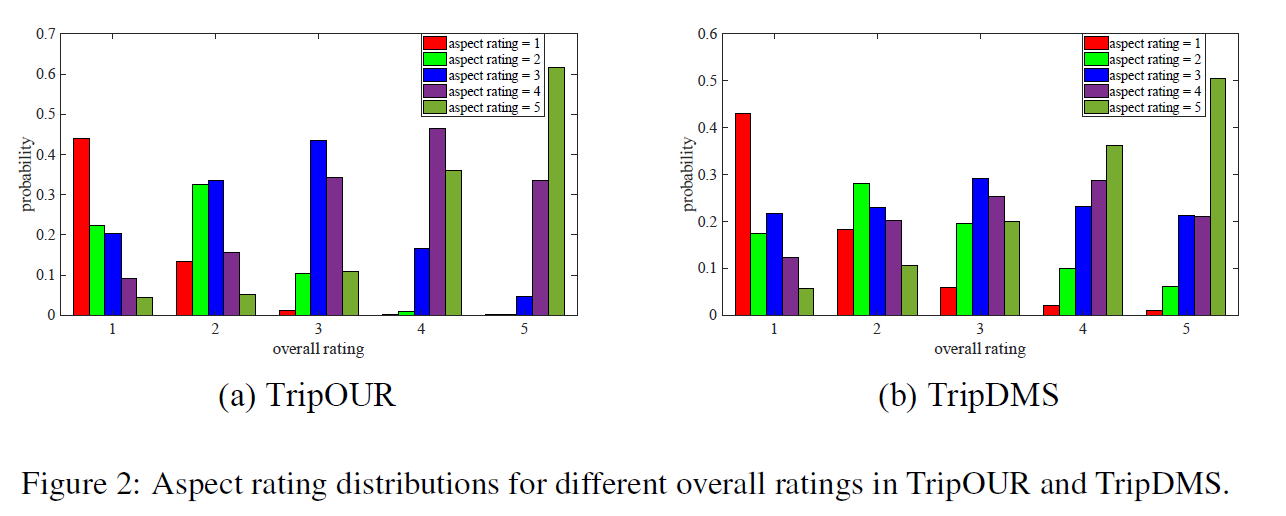
[b] overall ratings
유저는 전체 평점(overall rating)을 남길 때, 여러 요소를 동시에 고려한다
- overall rating can “partly reflect” the user’s attitude to aspects
- 이를 overall rating prior라고 부르겠다!
위의 사항을 실제로 확인해본 결과,
- 전체 평점 5점/5점 준 사람은, 70%이상의 aspect에서 별 4점~5점/5점을 줌
3. Methods
HUARN 알고리즘에 2가지의 정보( 유저 정보 & overall ratings )를 사용함
알고리즘 소개 순서
- 순서 1) formalizations of document-level multi-aspect sentiment classification
- 순서 2) multi-task learning framework
- 순서 3) 사용한 모델 아키텍쳐
- 순서 4) 모델 상세 소개
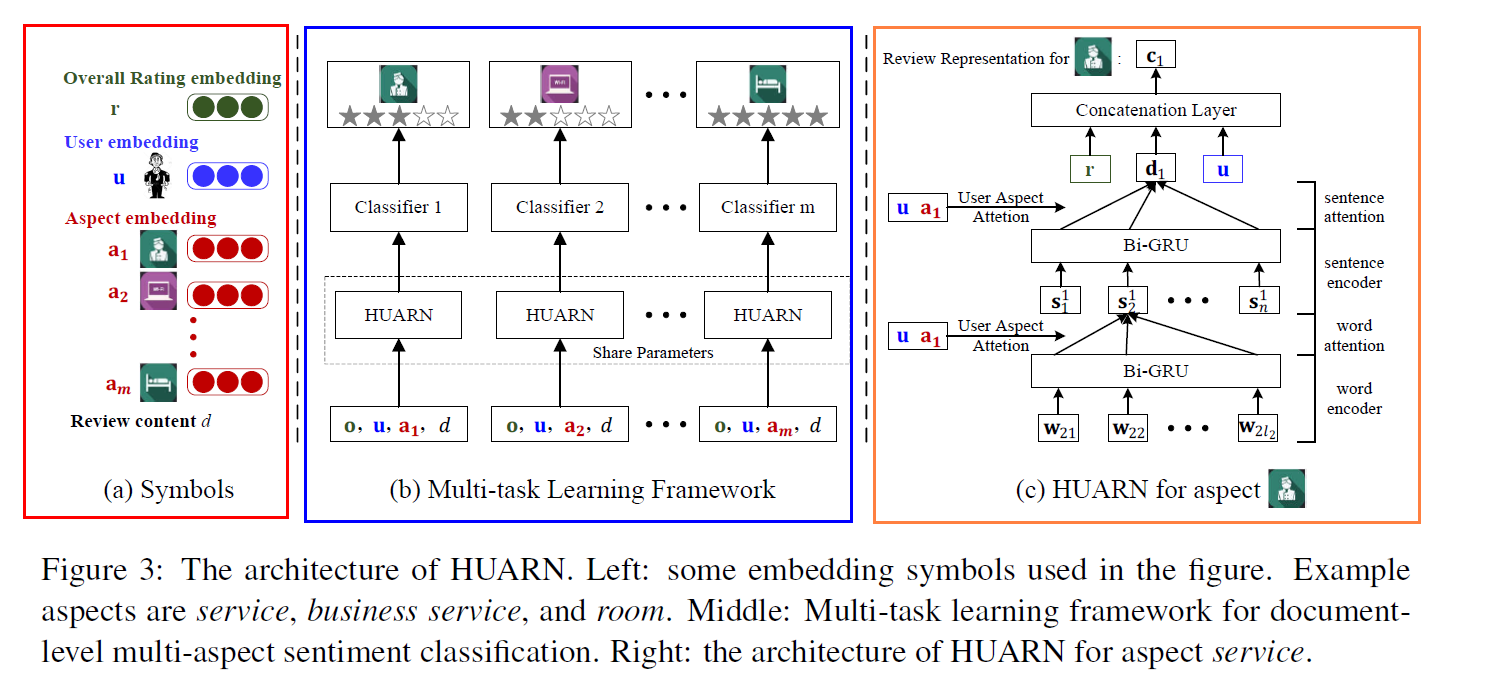
(1) Formalizations
( 위 그림의 빨간 네모 (Fig3-a) )
Notation 소개
- corpus \(D\) of 특정 domain ( ex. 호텔 )
- \(m\)개의 속성 ( \(\left\{a_{1}, a_{2}, \ldots, a_{m}\right\}\) )
- 특정 review \(d\) ( = sample of \(D\) )
- 총 \(n\)개의 문장으로 구성됨 ( \(\left\{s_{1}, s_{2}, \ldots, s_{n}\right\}\) )
- 그 중 하나의 문장 \(s_{i}\)는 \(l_{i}\) 개의 단어로 구성됨 ( \(\left\{w_{i 1}, w_{i 2}, \ldots, w_{i l_{i}}\right\}\) )
- 총 \(n\)개의 문장으로 구성됨 ( \(\left\{s_{1}, s_{2}, \ldots, s_{n}\right\}\) )
- overall rating (전체 평점) : \(r\)
- 해당 리뷰 작성자 : \(u\)
(2) Multi-task Learning Framework
( 위 그림의 파란 네모 (Fig3-b) )
document-level multi-aspect sentiment classification 문제를 multi-task learning 문제로써 푼다!
- 각 aspect rating 맞추기 = 하나의 classification task
- (공통) 서로 같은 document encoder network
- (task별(=속성별)) 서로 다른 softmax classifier
(3) 사용한 모델 ( Hierarchical Bidirectional Gated Recurrent Network )
( 위 그림의 주황 네모 (Fig3-c) )
-
계층적 구조를 반영함! ( we model the semantics of a document through a hierarchical structure from word-level, sentence-level to document-level )
-
bi-GRU를 사용함 ( for 문장 & 문서 representation 임베딩 )
큰 흐름 3줄 요약
- 1) 문장 \(s_{i}\)가 주어졌을 때, 각 단어 \(w_{i j}\) 를 vector \(\mathbf{w}_{i j}\)로 임베딩한다
- 2) 그런 뒤, Bi-GRU를 사용해서 hidden representation \(\mathbf{h}_{i j}\) 얻어낸다
- 3) 모아진 Hidden states \(\left\{\mathbf{h}_{i 1}, \mathbf{h}_{i 2}, \ldots \mathbf{h}_{i l_{i}}\right\}\) 를 average pooling하여 sentence representation \(\mathbf{s}_{i}\) 얻어냄
- 4) 모아진 sentence vectors \(\left\{\mathbf{s}_{1}, \mathbf{s}_{2}, \ldots, \mathbf{s}_{n}\right\}\)를 Bi-GRU로 넣어서 마찬가지로 document representation \(\mathbf{d}\) 를 얻어냄
(4) 모델 상세 소개
[a] User / Aspect / Overall rating 인코딩하기
모든 단어가 각 문장에, 그리고 모든 문장이 각 문서에 “동일한 영향 미치지 X”
유저별로도 차이 존재. ( user-text consistency )
user-text consistency 를 고려하고, aspect-specific representation을 만들 기 위해,
- (1) user attention
- (2) aspect attention
을 수행한다.
(1) Word-level Attention
- user \(u\) and aspect \(\left\{a_{k} \mid k \in 1,2, \ldots, m\right\}\) 를 각각 vector \(\mathbf{u}\) and \(\mathbf{a}_{k}\)로 임베딩
- word-level hidden states \(\left(\mathbf{h}_{i j}\right)\) 를 average pooling layer로 넣지 않고, user-aspect attention
\(\begin{aligned} \mathbf{m}_{i j} &=\tanh \left(\mathbf{W}_{w h} \mathbf{h}_{i j}+\mathbf{W}_{u} \mathbf{u}+\mathbf{W}_{a} \mathbf{a}_{k}+\mathbf{b}_{w}\right) \\ \alpha_{i j} &=\frac{\exp \left(\mathbf{v}_{w}^{T} \mathbf{m}_{i j}\right)}{\sum_{j} \exp \left(\mathbf{v}_{w}^{T} \mathbf{m}_{i j}\right)} \\ \mathbf{s}_{i}^{k} &=\sum_{j} \alpha_{i j} \mathbf{h}_{i j} \end{aligned}\).
- \(\mathbf{W}_{w h}, \mathbf{W}_{w u}, \mathbf{W}_{w a}\) and \(\mathbf{b}_{w}\) : parameters in the attention layer
- \(\alpha_{i j}\) : importance of the \(j\) -th word for user \(u\) and aspect \(a_{k}\)
- \(\mathbf{s}_{i}^{k}\) : representation of sentence \(s_{i}\) for aspect \(a_{k}\)
(2) Sentence-level Encoder & Attention
\(\begin{aligned} \mathbf{t}_{i} &=\tanh \left(\mathbf{W}_{s h} \mathbf{h}_{i}^{k}+\mathbf{W}_{s u} \mathbf{u}+\mathbf{W}_{s a} \mathbf{a}_{k}+\mathbf{b}_{s}\right) \\ \beta_{i} &=\frac{\exp \left(\mathbf{v}_{s}^{T} \mathbf{t}_{i}\right)}{\sum_{i} \exp \left(\mathbf{v}_{s}^{T} \mathbf{t}_{i}\right)} \\ \mathbf{d}_{k} &=\sum_{i} \beta_{i} \mathbf{h}_{i}^{k} \end{aligned}\).
- \(\beta_{i}\) : importance of the \(i\) -th sentences for user \(u\) and aspect \(a_{k}\).
(3) Concatenation Layer
-
user-rating consistency와 overall rating prior를 explicitly하게 인코딩하기 위해!
-
\(\mathbf{c}_{k}=\mathbf{u} \oplus \mathbf{r} \oplus \mathbf{d}_{k}\).
- user embedding \(\mathbf{u}\)
- rating embedding \(\mathbf{r}\)
- document vector \(\mathbf{d}_{k}\)
[b] Document-level Multi-aspect Sentiment Classification
위를 통해, review 별로 & 속성 별로 representation을 얻어냄
- \(k\) 번째 review의 (속성 별) representation들 : \(\left\{\mathbf{c}_{k} \mid k \in 1,2, \ldots, m\right\} .\)
- user, aspect, overall rating and document 정보가 모두 반영되어 있는 representation이다
속성 \(a_k\) 에 대한 최종 예측 :
- \(\mathbf{p}(d, k)=\operatorname{softmax}\left(\mathbf{W}_{l k} \mathbf{c}_{k}+\mathbf{b}_{k}\right)\).
Loss Function : cross entropy
- \(L=-\sum_{d \in D} \sum_{k \in\{1,2, \ldots, m\}} \sum_{l=1}^{L} \mathbb{1}\left\{g_{d, k}=l\right\} \cdot \log \left(p_{l}(d, k)\right)\).
- \(p_{l}(d, k)\) : predicted probability of sentiment class \(l\) for \(d\) based on \(a_{k}\)
- \(\mathbf{W}_{l k}, \mathbf{b}_{k}\) : parameters of softmax layer for classifying review \(\mathbf{c}_{k}\)
- \(g_{d, k}\) : ground truth label for review \(d\) for aspect \(a_{k}\).