
Code Review for HAN (Hierarchical Attention Network)
Reference
-
https://simonjisu.github.io/nlp/2018/07/05/packedsequence.html
- https://github.com/Hazoom/bert-han/blob/master/src/models/han.py
- https://github.com/Hazoom/bert-han/blob/master/src/models/bert_wordattention.py
- https://github.com/Hazoom/bert-han/blob/master/src/models/sentenceattention.py
(참고) pad & pack sequence
다음과 같은 Input ( input_seq2idx ) 이 있다고 해보자
- 배치 크기 = 5 ( 5개의 문장 )
- 문장 최대 길이 = 6 ( 제일 긴 문장의 token 수는 6개 )
- 히든 크기 = 2 ( hidden dimension )
input_seq2idx
============================================
tensor([[ 1, 16, 7, 11, 13, 2],
[ 1, 16, 6, 15, 8, 0],
[ 12, 9, 0, 0, 0, 0],
[ 5, 14, 3, 17, 0, 0],
[ 10, 0, 0, 0, 0, 0]])
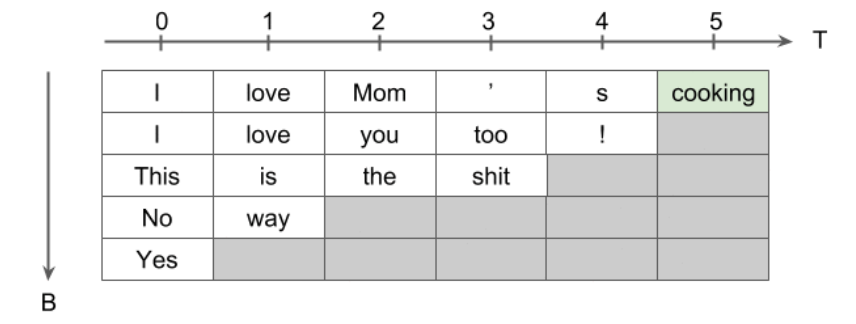
위의 Input ( input_seq2idx )에 embedding을 거쳐서
embeded = embed(input_seq2idx)와 같이 임베딩을 한다.
그런 뒤…
(1) pack_padded_sequence
-
packed_output = pack_padded_sequence(embeded, input_lengths.tolist(), batch_first=True) -
Output의 크기 :
packed_output[0].size(): torch.Size([18, 2]) … 18개의 문장 & 2개의 hidden dimensionpacked_output[1]: tensor([ 5, 4, 3, 3, 2, 1]))
(2) pad_packed_sequence
-
output, output_lengths = pad_packed_sequence(packed_output, batch_first=True) -
Output의 크기 :
output.size(): torch.Size([5, 6, 2]output_lengths: tensor([ 6, 5, 4, 2, 1]))
1. Word Attention
예시 data : 100개의 문서
- (5,7,3,12,….,8)개의 문장 (=총 1050 문장) , 최대 문장 길이 =12
- (54,23,82,25,….77)개의 단어 (=총 8만 단어) , 최대 단어 길이 =82
[INPUT 소개] 의미 및 차원 :
docs: encoding된 문서… size = ( 문서 개수, 패딩 O 문서 길이, 패딩 O 문장 길이 ) = (100,12,82)doc_lengths: 문서 길이… size = ( 문서 개수 ) = 100- 값 : (5,7,3,12,….,8)
sent_lengths: 문장 길이…size = ( 문서 개수, 최대 문장 길이 ) = (100,12)
@registry.register("word_attention", "WordAttention")
class WordAttention(nn.Module):
def __init__(self,
device: str,
preprocessor: AbstractPreproc,
word_emb_size: int,
dropout: float,
recurrent_size: int,
attention_dim: int):
super().__init__()
self._device = device
self.preprocessor = preprocessor
self.embedder: abstract_embeddings.Embedder = self.preprocessor.get_embedder()
self.vocab: vocab.Vocab = self.preprocessor.get_vocab()
self.word_emb_size = word_emb_size
self.recurrent_size = recurrent_size
self.dropout = dropout
self.attention_dim = attention_dim
self.embedding = nn.Embedding(num_embeddings=len(self.vocab), embedding_dim=self.word_emb_size)
assert self.recurrent_size % 2 == 0 # bi-LSTM할것이기 때문에!
assert self.word_emb_size == self.embedder.dim
# init embedding
init_embed_list = []
for index, word in enumerate(self.vocab):
# (1) embedder에 있을 경우 -> LookUp Table에서 찾아
if self.embedder.contains(word):
init_embed_list.append(self.embedder.lookup(word))
# (2) embedder에 없을 경우 -> 새롭게 embedding
else:
init_embed_list.append(self.embedding.weight[index])
init_embed_weight = torch.stack(init_embed_list, 0)
self.embedding.weight = nn.Parameter(init_embed_weight)
self.encoder = nn.LSTM(
input_size=self.word_emb_size,
hidden_size=self.recurrent_size // 2, # (bi-LSTM이므로)
dropout=self.dropout,
bidirectional=True,
batch_first=True,
)
self.dropout = nn.Dropout(dropout)
self.word_weight = nn.Linear(self.recurrent_size, self.attention_dim)
self.context_weight = nn.Linear(self.attention_dim, 1)
def recurrent_size(self):
return self.recurrent_size
def forward(self, docs, doc_lengths, sent_lengths):
#################
### 계층 구조 1 ##
#################
#-----------------------------------------#
# (Step 1) SENT 많은 DOC 순으로 sort
### doc_lengths = 100(=5,7,3,12,....,8) -> 100(=12,11,....3)
### sent_lengths = 100x12(=54,23,...77) -> 100x12(=71,77..12)
doc_lengths, doc_perm_idx = doc_lengths.sort(dim=0, descending=True)
docs = docs[doc_perm_idx]
sent_lengths = sent_lengths[doc_perm_idx]
#-----------------------------------------#
# (Step 2) [packing] 여러 DOC -> 여러 여러 SENT
##### ( Make a long batch of sentences )
##### BEFORE : (num_docs, padded_doc_length, padded_sent_length)
##### AFTER : (num_sents, padded_sent_length)
##### docs = 100x12x82 -> sents = 1050x82
packed_sents = pack_padded_sequence(docs, lengths=doc_lengths.tolist(), batch_first=True)
doc_bs = packed_sents.batch_sizes
sents = packed_sents.data
#-------------------------------------------------#
# (Step 3) [packing] 여러 DOC 여러 SENT 개수 -> 여러 여러 SENT 개수
##### ( Make a long batch of sentences lengths )
##### BEFORE : (num_docs, padded_doc_length)
##### AFTER : (num_sents)
##### sent_lengths = 100x12(=54,23,...77) -> 1050
packed_sent_lengths = pack_padded_sequence(sent_lengths, lengths=doc_lengths.tolist(), batch_first=True)
sent_lengths = packed_sent_lengths.data
#-------------------------------------------------#
# (Step 4) WORD 많은 SENT 순으로 sort
sent_lengths, sent_perm_idx = sent_lengths.sort(dim=0, descending=True)
sents = sents[sent_perm_idx]
#-----------------------------------------#
#################
### 계층 구조 2 ##
#################
#-----------------------------------------#
# (Step 1) [embedding] 여러 여러 SENT
input_ = self.dropout(self.embedding(sents))
#-----------------------------------------#
# (Step 2) [packing] 여러 여러 SENT -> 여러 여러 여러 WORD
packed_words = pack_padded_sequence(input_, lengths=sent_lengths.tolist(), batch_first=True)
#-----------------------------------------#
# (Step 3) [encoding] 여러 여러 여러 WORD
packed_words, _ = self.encoder(packed_words)
sentences_bs = packed_words.batch_sizes
#-----------------------------------------#
#################
### Attention ###
#################
u_i = torch.tanh(self.word_weight(packed_words.data))
u_w = self.context_weight(u_i).squeeze(1)
att = torch.exp(u_w - u_w.max())
##########################
### 다시 Padding 시키기 ###
#########################
# Restore as sentences by repadding
att, _ = pad_packed_sequence(PackedSequence(att, sentences_bs), batch_first=True)
att_weights = att / torch.sum(att, dim=1, keepdim=True)
# Restore as sentences by repadding
sents, _ = pad_packed_sequence(packed_words, batch_first=True)
sents = sents * att_weights.unsqueeze(2)
sents = sents.sum(dim=1)
##########################
### 다시 Sorting 시키기 ###
#########################
_, sent_unperm_idx = sent_perm_idx.sort(dim=0, descending=False)
sents = sents[sent_unperm_idx]
att_weights = att_weights[sent_unperm_idx]
return sents, doc_perm_idx, doc_bs, att_weights
2. Sentence Attention
[INPUT 소개] 의미 및 차원 :
sent_embeddings: 임베딩된 문장들 … size : (batch_size * padded_doc_length, sentence recurrent dim)doc_perm_idx: 문서 순서 index …. size : (batch_size)doc_bs: 문서의 batch size …. size : (max_doc_len)word_att_weights: word attention weights …. size : (batch_size * padded_doc_length, max_sent_len)
@registry.register("sentence_attention", "SentenceAttention")
class SentenceAttention(torch.nn.Module):
def __init__(
self,
device: str,
dropout: float,
word_recurrent_size: int,
recurrent_size: int,
attention_dim: int,
):
super().__init__()
self._device = device
self.word_recurrent_size = word_recurrent_size
self.recurrent_size = recurrent_size
assert self.recurrent_size % 2 == 0
self.dropout = dropout
self.attention_dim = attention_dim
self.encoder = nn.LSTM(
input_size=self.word_recurrent_size,
hidden_size=self.recurrent_size // 2,
dropout=self.dropout,
bidirectional=True,
batch_first=True,
)
self.dropout = nn.Dropout(dropout)
# LSTM 임베딩 결과 -> Attention 차원
self.sentence_weight = nn.Linear(self.recurrent_size, self.attention_dim)
# Attention 차원 -> Attention score
self.sentence_context_weight = nn.Linear(self.attention_dim, 1)
def recurrent_size(self):
return self.recurrent_size
def forward(self, sent_embeddings, doc_perm_idx, doc_bs, word_att_weights):
#-----------------------------------------#
# [Step 1] Sentence embedding에 드롭아웃
sent_embeddings = self.dropout(sent_embeddings)
#-----------------------------------------#
# [Step 2] Sentence embedding을 인코딩 (with LSTM)
packed_sentences, _ = self.encoder(PackedSequence(sent_embeddings, doc_bs))
#-----------------------------------------#
# [Step 3] Attention 계산
u_i = torch.tanh(self.sentence_weight(packed_sentences.data))
u_w = self.sentence_context_weight(u_i).squeeze(1)
att = torch.exp(u_w - u_w.max())
# Restore as sentences by repadding
att, _ = pad_packed_sequence(PackedSequence(att, doc_bs), batch_first=True)
sent_att_weights = att / torch.sum(att, dim=1, keepdim=True)
# Restore as documents by repadding
docs, _ = pad_packed_sequence(packed_sentences, batch_first=True)
# Compute document vectors
docs = docs * sent_att_weights.unsqueeze(2)
docs = docs.sum(dim=1)
# Restore as documents by repadding
word_att_weights, _ = pad_packed_sequence(PackedSequence(word_att_weights, doc_bs), batch_first=True)
# Restore the original order of documents (undo the first sorting)
_, doc_unperm_idx = doc_perm_idx.sort(dim=0, descending=False)
docs = docs[doc_unperm_idx]
word_att_weights = word_att_weights[doc_unperm_idx]
sent_att_weights = sent_att_weights[doc_unperm_idx]
return docs, word_att_weights, sent_att_weights
3. HAN (Hierarchical Attention Network)
차원 :
-
docs: (num_docs, padded_doc_length, padded_sent_length) -
doc_lengths: (num_docs) -
sent_lengths: (num_docs, max_sent_len) -
attention_masks: (num_docs, padded_doc_length, padded_sent_length)( =
docs와 동일한 size ) -
token_type_ids: (num_docs, padded_doc_length, padded_sent_length)( =
docs와 동일한 size )
@registry.register('model', 'HAN')
class HANModel(torch.nn.Module):
# class Preprocessor(abstract_preprocessor.AbstractPreproc): 생략
def __init__(self, preprocessor, device, word_attention, sentence_attention, final_layer_dim, final_layer_dropout):
super().__init__()
# (1) Preprocessor
self.preprocessor = preprocessor
# (2) Word Attention
self.word_attention = registry.instantiate(
callable=registry.lookup("word_attention", word_attention["name"]),
config=word_attention,
unused_keys=("name",),
device=device,
preprocessor=preprocessor.preprocessor)
# (3) Sentence Attention
self.sentence_attention = registry.instantiate(
callable=registry.lookup("sentence_attention", sentence_attention["name"]),
config=sentence_attention,
unused_keys=("name",),
device=device)
# (4) FFNN
self.mlp = nn.Sequential(
torch.nn.Linear(self.sentence_attention.recurrent_size, final_layer_dim),
nn.ReLU(),
nn.Dropout(final_layer_dropout),
torch.nn.Linear(final_layer_dim, self.preprocessor.get_num_classes())
)
# (5) Cross Entropy Loss
self.loss = nn.CrossEntropyLoss(reduction="mean").to(device)
##########################################################################################
def forward(self, docs, doc_lengths, sent_lengths,
labels=None, attention_masks=None, token_type_ids=None):
#----------------------------------------------------------------------#
# [STEP 1] Word attention을 사용해서 Sentence 임베딩
if attention_masks is not None and token_type_ids is not None:
sent_embeddings, doc_perm_idx, doc_bs, word_att_weights = self.word_attention(
docs, doc_lengths, sent_lengths, attention_masks, token_type_ids)
else:
sent_embeddings, doc_perm_idx, doc_bs, word_att_weights = self.word_attention(
docs, doc_lengths, sent_lengths)
#----------------------------------------------------------------------#
# [STEP 2] Sentence attention을 사용해서 Document 임베딩
doc_embeds, word_att_weights, sentence_att_weights = self.sentence_attention(
sent_embeddings, doc_perm_idx, doc_bs, word_att_weights
)
#----------------------------------------------------------------------#
# [STEP 3] 최종 Output
### 1) Score (Document Classification Result)
### 2) Attention weight ( word & sentence )
scores = self.mlp(doc_embeds)
outputs = (scores, word_att_weights, sentence_att_weights,)
if labels is not None:
loss = self.loss(scores, labels)
return outputs + (loss,)
return outputs