
A Sentence-level Hierarchical BERT Model for Document Classification with Limited Labelled Data (HBM)
Contents
- Abstract
- Introduction
- Related Work
- The Hierarchical BERT Model
- Token-level Roberta Encoder
- Sentence-level BERT Encoder
- Prediction Layer
- Training HBM
0. Abstract
-
LIMITED labeled data로 DL 학습하기!
-
BERT : 적은 labeled data로도 좋은 성능
BUT, LONG document classification에는 그다지…
-
따라서, 이 논문에서는 HBM (Hierarchical BERT Model)를 제안한다
HBM
- 1) sentence-level feature 학습
- 2) limited labeled data 상황속에서도 잘 작동
- 특히, document가 “길 때”, 기존의 알고리즘보다 나은 성능을 보임
1. Introduction
(A) BERT
- extract extensive language features from large corpora
- labeled data가 limited 상황에서 good
-
pre-training & fine-tuning
- text가 너무 길 때, BERT도 완벽하진 못하다!
(B) HAN (Hierarchical Attention Network)
- sentence-level information을 문서에서 뽑아낸다
(A) + (B) = HBM
- improve the performance of BERT-based models / in document classification / under low labeled data context / by considering the sentence structure information
BERT vs HBM
- BERT : captures connections between WORDS
- HBM : captures connections between SENTENCES
- sentence : 서로 동일하게 중요 X
- higher attention score 받은 문장은, representation of document에 더 많이 반영
2. Related Work
BERT
-
일반적으로 DL에서 5,000 examples per class가 필요하다고 봄
-
class 별 100~1,000 examples가 있는 case에서, BERT가 document classification에서 최강자
-
하지만…
-
(1) BERT 자체의 modification을 준 것과 비교해서 더 나은지 확인해바야!
( 다른 구닥다리랑 싸워서 이긴거 말고 )
-
(2) long text를 처리하는데에 BERT는 부적합
-
\(\rightarrow\) using a sentence-level language model to alleviate the LONG-texts problems suffered by BERT
기타
- HAN : Bi-GRU with attention
- HIBERT (Hierarchical Bidirectional Encoder Representations from Transformers) : for document summarization
- 주로 labeled data가 abundant 하다고 가정함 ( limited (X) )
Contribution
- 1) propose HBM
- capture sentence structure
- with small amounts of labeled data
- 2) salient sentences identified by HBM are useful as explanations for document classification
3. The Hierarchical BERT Model
3가지의 요소로 구성
- (1) token-level Roberta encoder
- (2) sentence-level BERT encoder
- (3) prediction layer
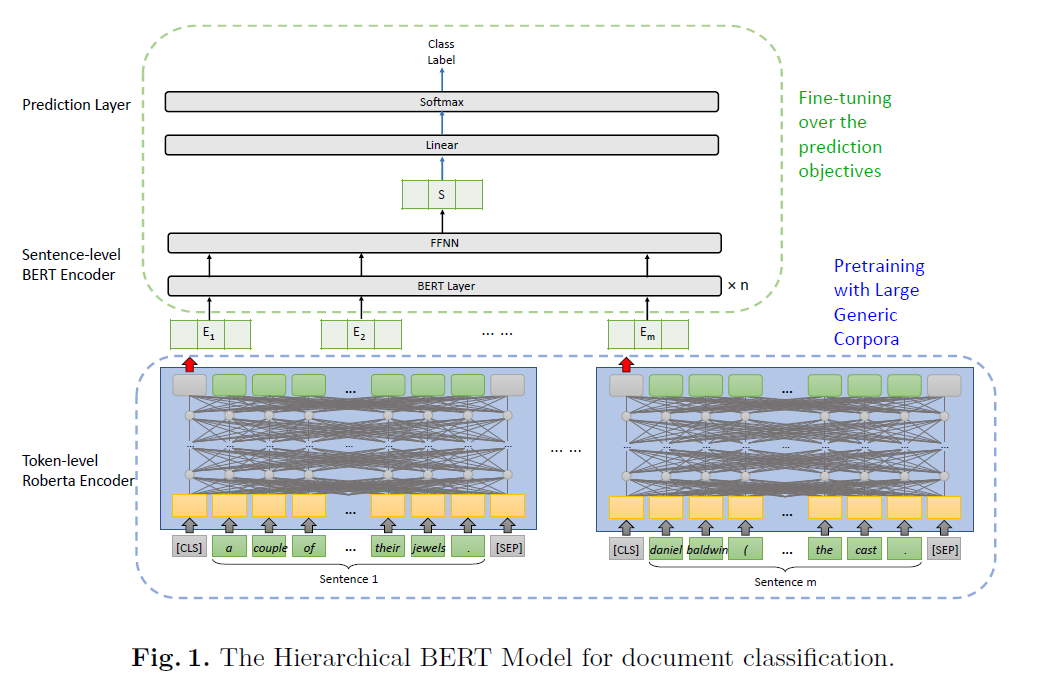
간단 소개 :
-
step 1) raw text가 token-level Roberta Encoder에 들어가서 text feature를 extract
( = form vector representation for each sentence )
-
step 2) sentence vector가 sentence-level BERT encoder의 input으로 들어가서 intermediate representation 생성
-
step 3) intermediate representation ( = document representation )가 prediction layer로 들어가서 document class 예측
3-1) Token-level Roberta Encoder
-
Roberta = BERT + larger datasets
-
pre-trained Roberta를 사용하여 raw text features를 뽑아내 ( word 단위 )
\[\mathcal{D}=\left(E_{1}, E_{2}, \ldots, E_{m}\right)\]-
\(E_i\) : \(i\)번째 sentence vector of document \(\mathcal{D} \in \mathbb{R}^{m \times d_{e}}\)
( by averaging token embeddings contained in each sentence )
-
(최대) \(m\)개의 문장이 1개의 document 형성
-
3-2) Sentence-level BERT Encoder
- extract sentence structure information, for generating intermediate document representation \(S\)
- 여러 identical BERT layer로 구성
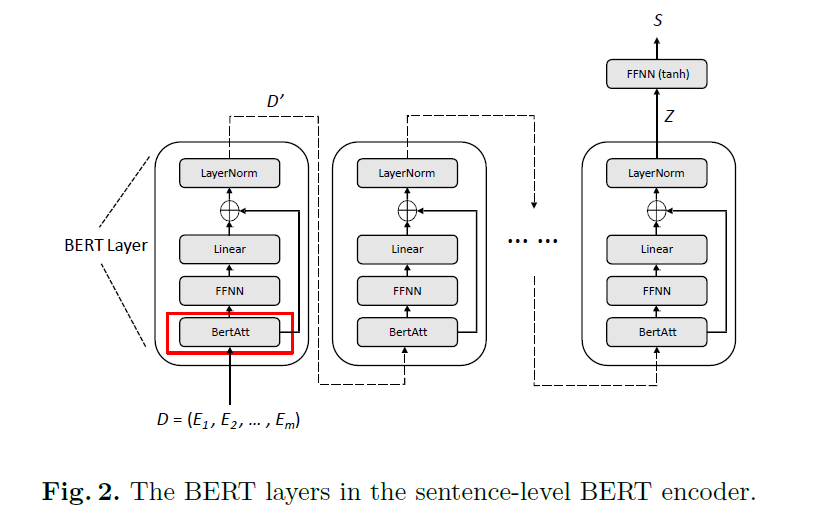
BertAtt layer의 output :
\(\operatorname{BertAtt}(\mathcal{D})=\text { LayerNorm }(\mathcal{D}+\operatorname{MultiHead}(\mathcal{D}))\).
- \(\operatorname{MultiHead}(\mathcal{D})=\operatorname{Concat}\left(\text { head }_{1}, \text { head }_{2}, \ldots, \text { head }_{h}\right) \times W^{O}\).
- \(\text { head }_{i} =\text { Attention }\left(Q_{i}, K_{i}, V_{i}\right)=\operatorname{Softmax}\left(Q_{i} \times K_{i}^{\top} / \sqrt{d_{e}}\right) \times V_{i}\).
- \(Q_{i} =\mathcal{D} \times W_{i}^{Q}\).
- \[K_{i}=\mathcal{D} \times W_{i}^{K}\]
- \(V_{i}=\mathcal{D} \times W_{i}^{V}\).
- \(\text { head }_{i} =\text { Attention }\left(Q_{i}, K_{i}, V_{i}\right)=\operatorname{Softmax}\left(Q_{i} \times K_{i}^{\top} / \sqrt{d_{e}}\right) \times V_{i}\).
output of BertAtt : passed through FFNN
\(\mathcal{D}^{\prime}=\text { LayerNorm }\left(\operatorname{BertAtt}(\mathcal{D})+\operatorname{Relu}\left(\operatorname{BertAtt}(\mathcal{D}) \times W^{r}\right) \times W^{S}\right)\).
-
intermediate document representation \(\mathcal{S}\).
\(\mathcal{S}=\operatorname{Tanh}\left(\operatorname{Avg}(\mathcal{Z}) \times W^{t}\right)\).
-
이 \(\mathcal{S}\)가 final prediction layer로 pass
3-3) Prediction Layer
-
compute raw score for each class
-
\(\left[t_{0}, t_{1}, \ldots, t_{y}\right]=\mathcal{S} \times W\).
- \(W \in \mathbb{R}^{d_{e} \times y}\).
-
\(t_{0}, t_{1}, \ldots, t_{y}\) : raw score of document for \(0^{t h}\) to \(y^{t h}\) class
- 이 \(t\)가 softmax로 들어감
3-4) Training HBM
( pre-training + fine-tuning 구조 )
[ pre-training ]
- several self-supervised methods ( MLM, NSP )
[ fine-tuning ]
- task-specific head is added
이 모델은, fine-tuning시..
- (freeze O) Roberta
- (freeze X) sentence-level BERT & prediction layer