Improving BERT performance for Aspect-Based Sentiment Analysis (2021)
Contents
- Abstract
- Related Works
- Aspect-Based Sentiment Analysis (ABSA) Tasks
- Aspect Extraction
- Aspect Sentiment Classification
- Proposed Models
- Parallel aggregation : P-SUM
- Hierarchical aggregation
0. Abstract
BERT를 improve 시킬 2가지 방법을 제안함
- 1) Parallel Aggregation
- 2) Hierarchical Aggregation
이 두 module을 BERT의 top에 쌓아 올려! ( for 2개의 ABSA tasks )
- [task 1] Aspect Extraction (AE)
- [task 2] Aspect Sentiment Classification (ASC)
1. Related Works
- GCN을 사용하여, 문장 sequence 내의 sentiment dependency를 고려할 수 있다
- AE task를 일종의 “sentence-pair classification task”로 바꿔풀기도!
- ex) construct auxiliary sentences using the aspect terms of a sequence
- domain-specific data사용을 통해 model이 enrich될 수 있다!
- post-training of BERT
2. Aspect-Based Sentiment Analysis (ABSA) Tasks
2-1) Aspect Extraction
- 목표 : 리뷰 내에서 특정 aspect(속성)과 관련된 속성 단어를 extract하기
- ex) “The laptop has a good battery”
- battery : “속성 단어”
- 이걸 sequence labeling task로 볼 수 있다!
- 모든 단어는 셋 중 하나로 labeling 된다 : \(\{B,I,O\}\)
- \(B\) : beginning word of aspect terms
- \(I\) : among the aspect terms
- \(O\) : not an aspect term
- 모든 단어는 셋 중 하나로 labeling 된다 : \(\{B,I,O\}\)
2-2) Aspect Sentiment Classification
- 목표 : Positive/Negative/Neutral 중 하나의 감정으로 분류하기
- ex) [CLS], \(w_1,...,w_n\), [SEP]
- 문장 전체에 대한 감정은 [CLS]에!
3. Proposed Models
Deep Models = Deeper Knowledge 포착 가능!
BERT의…
-
middle layer : syntatic info 담고 있다
-
higher layer : language semantic 담고 있다 \(\rightarrow\) 여기서 sentiment 뽑아내고자 함!
\(\rightarrow\) exploit the FINAL layers of BERT
여기서 제안하는 2가지 모델 :
- Parallel aggregation
- Hierarchical aggregation
서로 비슷하지만, 구현에 있어서 약간 차이가 있다.
여기서 풀려는 2가지 task :
- ASC : cross-entropy loss 사용
- AE : CRFs (Conditional Random Fields) 사용
Conditional Random Fields
- graphical model의 한 종류
- CV (for pixel-level labeling), NLP (sequence labeling)으로 가끔 사용됨
\(\rightarrow\) AE도 sequence labeling으로 볼 수 있기 때문에, CRFs 사용 가능!
ex) 아래 문장의 “good”라는 형용사를 통해, 그 앞/뒤로는 “형용사”가 오지 않을 것을 알 수 있음
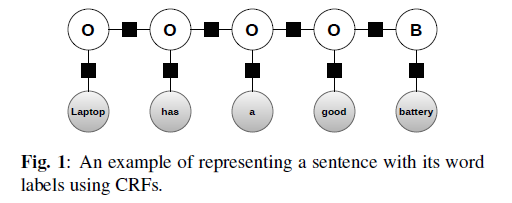
-
joint probabilities of the labels :
\(p(\mathbf{y} \mid \mathbf{x})=\frac{1}{Z(\mathbf{x})} \prod_{t=1}^{T} \exp \left\{\sum_{k=1}^{K} \theta_{k} f_{k}\left(y_{t}, y_{t-1}, \mathbf{x}_{t}\right)\right\}\).
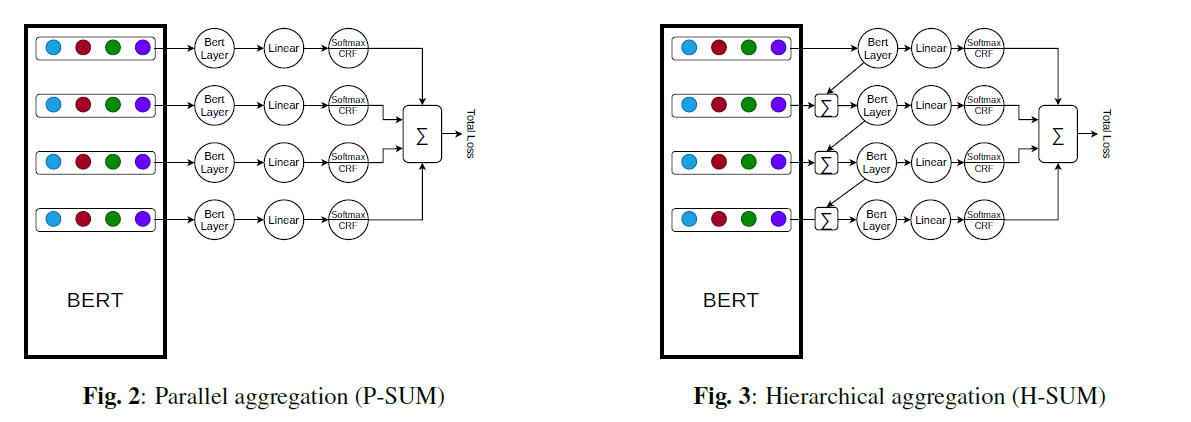
3-1) Parallel aggregation : P-SUM
-
BERT의 마지막 4개의 layer 사용
( prediction using 각각의 layer )
-
더 richer representation잡을 수 있다.
3-2) Hierarchical aggregation
-
마찬가지로 BERT의 마지막 4개의 layer 사용
-
after apply a BERT layer on each one,
they are AGGREGATED with the previous layers