
[ 1. Reinforcement Learning Intro ]
Contents
- What is Reinforcement Learning?
- Reinforcement Learning Components
- RL의 구성요소 & 용어
- Summary
- Algorithm
- Value function & Q-Value function
- Value function
- Q-value function
- Kinds of Reinforcement Learning
1. What is Reinforcement Learning?
한 줄 요약 : 주어진 상황이 있을 때, 가장 좋은 행동은?
( RL = “가장 좋은 행동” 찾기 위한 학습 )
-
1 ) Supervised Learning : Labeled data -> prediction & classification
-
2 ) Unsupervised Learning : Unlabeled data -> clustering, generative model
-
3 ) REINFORCEMENT LEARNING : Decision process, Reward System
\(\rightarrow\) “주어진 상황(State)에서, 받을 수 있는 보상(Reward)를 극대화 하는 행동(Action)을 선택하도록!”
RL의 key idea
- 인간의 심리와 매우 유사! ( 세계를 경험하면서 학습을 한다 )
- 잘하면 (+) 보상, 못하면 (-) 벌점
- DRL (Deep Reinforcement Learning, 심층 강화학습) = RL + DL
Properties of RL
- 1) 정답을 모른다! (Unsupervsied)
- 대신, 특정 행동에 대한 reward & 다음 state가 주어짐
- 2) 현재의 의사결정이, 미래의 의사결정에 영향을 미친다!
- 3) 문제의 구조를 모른다
- 처음부터 행동에 대한 모든 보상들을 알고 시작하는 것이 아니다.
- 4) Delayed Reward
- 받게되는 reward의 가치는 시간에 따라 다를 수 있다.
RL이 다른 ML 기법들과 다른 점은?
-
1 ) No Supervisor ! ( Loss Function이 없다 )
\(\rightarrow\) 오직 “Reward의 크기”에 따라 선택의 옳고 그름이 판단된다
-
2 ) Delayed Feedback !
\(\rightarrow\) 해당 선택이 옳은지는 바로 판단이 내려지지 않는다!
( 지금 한 순간이 아니라, 보다 “장기적인 관점에서 reward를 판단”하기 때문에 )
2. Reinforcement Learning Components
(1) RL의 구성요소 & 용어

- 1 ) Agent (에이전트) : 상태를 관찰, 행동을 선택하는 주체
- agent의 3요소 : 정책/가치/모델
- 2 ) Environment (환경) : Agent가 속해 있는 상황
( 단지 현재 속해있는 시점의 상황 뿐만 아니라, 전체적인 상황을 의미한다 )
-
3 ) State (상태) : 현재 Agent가 속해 있는 상태의 정보
-
4 ) Action (행동, \(A\)) : 현재 state에서 Agent가 하는 행동
-
5 ) Reward (보상, \(R\) ) : Agent가 action을 했을 때 받게 되는 보상 (장기적인 관점)
-
6 ) Policy (정책, \(\pi\) ) : 주어진 환경에서 어떠한 action을 해야한다는 행동 요령
(2) Summary
- Agent(에이전트)가 Environment(환경)에서 자신의 state(상태)를 관찰하고, 특정 기준(“가치 함수”)에 따라 행동을 선택한다.
- 여기서 “가치 함수”는, 현재 상태에서 미래에 받을 것으로 기대되는 Reward의 (discounted) 합을 의미한다
- 그리고 선택한 행동을 수행하면, 다음 state으로 넘어감과 함께 Reward를 받는다.
- 여기서 받는 Reward를 통해, Agent는 가지고 있는 정보를 update한다”
(3) Algorithm
매 time step \(t\) 마다,
- 1 ) agent는 액션 (action)을 한다 (\(A_t\) )
- 2 ) 행동에 따른 결과를 확인 (observation)한다
- 3 ) 이 행동에 따른 보상 (reward)을 받는다 ( \(R_t\) )
3. Value function & Q-Value function
Value function vs Q-value function?
-
Value function : 액션(action) 고려 X
-
Q-value function : 액션(action) 고려 O
(1) Value function ( 액션 고려 X )
여기서의 ‘value’는, 단기적인 보상(Reward)만을 이야기하는 것이 아니다.
“장기적인 관점”에서, 미래에 받게 될 보상까지 고려한 reward를 의미한다.
여기서, 미래에 받을 reward를 할인율(\(\gamma\))를 통해 discount한다.
이를 식으로 나타내면 다음과 같다.
- \(V_{\pi}(s) = E[R(s_0)+\gamma\;R(s_1)+ \gamma^2\;R(s_2)+... \mid s_0=s, \pi]\).
- 해석 : “현재 상태 \(s\)에서 정책 \(\pi\) 에 따라 행동 했을 때 기대되는 보상”
(2) Q-Value function ( 액션 고려 O )
Value function이 “(1) 현재의 상태과 (2) 정책”이 주어졌을 때의 Reward 관련 함수라면,
Q-value function은 “(1) 현재의 상태, (2) 정책 그리고 (3) 현재의 상태에서 취할 행동”이 주어졌을 때의 Reward 관련된 함수이다.
이를 식으로 나타내면 다음과 같다.
- \(Q_\pi (s,a) = E[R(s_0,a_0)+\gamma R(s_1,a_1) +\gamma^2 R(s_2,a_2)+....\mid s_0=s,a_0=a,\pi ]\).
4. Kinds of Reinforcement Learning
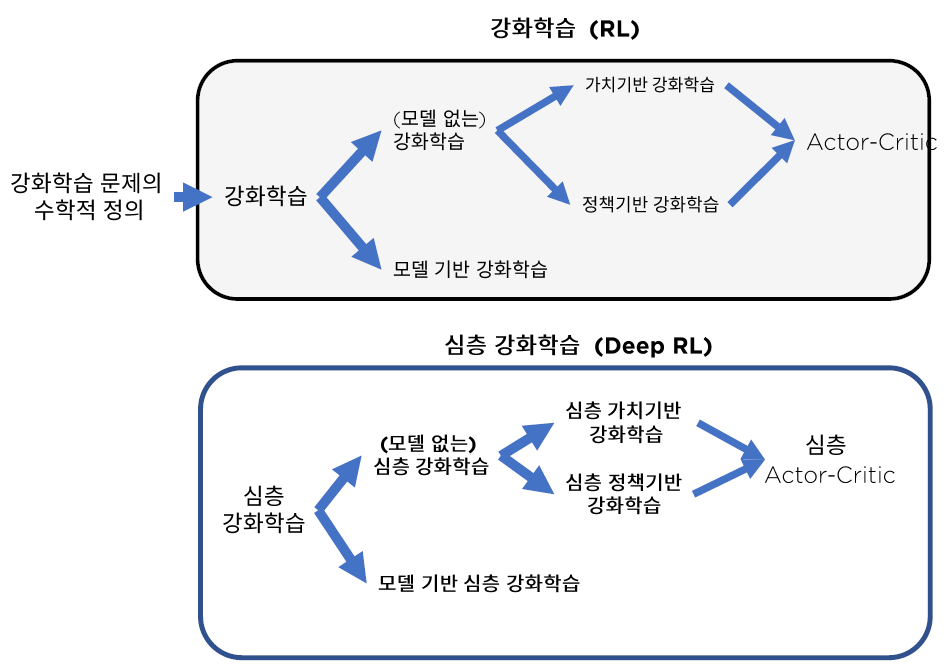
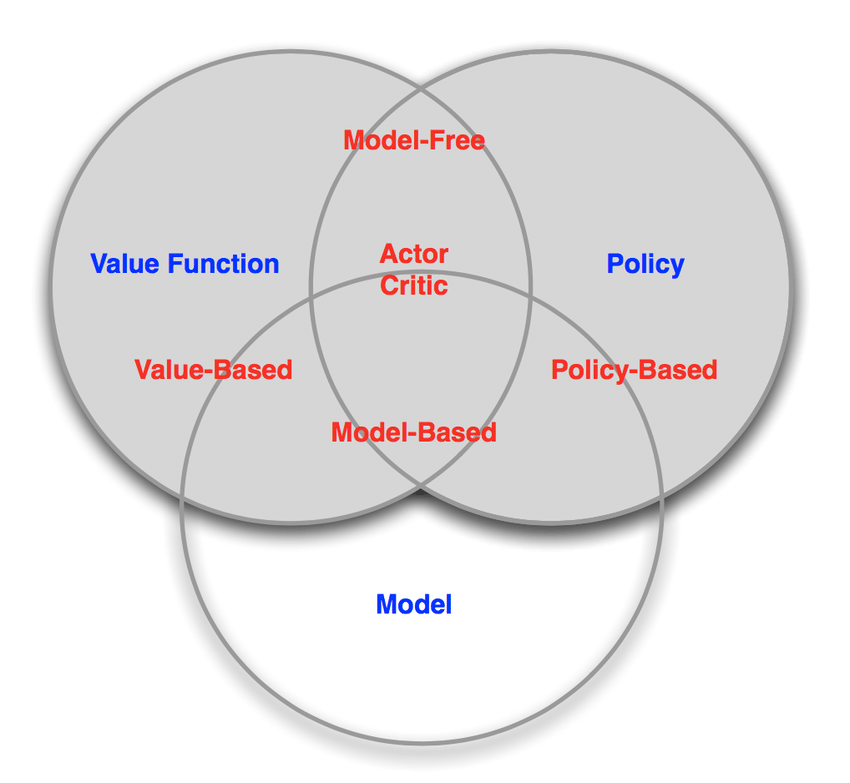 .
.
- 1 ) Model based :
- agent가 존재하는 environment를 modeling한 것
- 2 ) Policy based agent :
- value function 없이, 오직 policy와 model만으로 구성
- 3 ) Value based agent :
- policy 없이, 오직 value function과 model만으로 구성
- 4 ) Model based agent & Model Free agent :
- model에 대한 정보가 곧 state transition의 정보
- 5 ) Actor Critic :
- policy + value function + model 모두 사용
5. Summary
-
RL = 미래까지 고려한 reward 극대화하는 policy 찾기
-
RL의 구성 요소 : agent, environment, state, action, reward, policy
-
Agent의 행동 순서 :
- (1) 행동 - (2) 상태 확인 - (3) 보상 받기
-
Value function vs Q-value function
-
Value ) 액션 고려 X ( state + policy )
\(V_{\pi}(s) = E[R(s_0)+\gamma\;R(s_1)+ \gamma^2\;R(s_2)+... \mid s_0=s, \pi]\).
-
Q-value ) 액션 고려 O ( state + policy + action )
\(Q_\pi (s,a) = E[R(s_0,a_0)+\gamma R(s_1,a_1) +....\mid s_0=s,a_0=a,\pi ]\).
-