( 참고 : Fastcampus 강의 )
[ 6. Policy Iteration 실습 2 ]
1. 환경 설정하기
1-1. Import Packages
import sys; sys.path.append('..')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from src.part2.tensorized_dp import TensorDP
from src.common.gridworld import GridworldEnv
from src.common.grid_visualization import visualize_value_function, visualize_policy
np.random.seed(0)
1-2. Make Environment
nx = 5
ny = 5
env = GridworldEnv([ny, nx])
1-3. Environment 소개
print(env.nS) ## 25
print(env.nA) ## 4
print(env.P_tensor.shape) # 4x25x25
print(env.R_tensor.shape) # 25x4
2. Agent 초기화
dp_agent = TensorDP(gamma=1.0,error_tol=1e-5)
Agent의 input
- \(\gamma\) : 할인율 ( default = 1.0 )
- error_tol : 수렴의 기준 ( default : 1e-5 )
Agent에게 환경을 설정해주기
def set_env(self, env, policy=None):
self.env = env
# policy를 주어주지 않으면, default로 uniform하게!
if policy is None:
self.policy = np.ones([env.nS, env.nA]) / env.nA
# state 개수(25), action 개수(4), transition matrix, reward 설정
self.ns = env.nS
self.na = env.nA
self.P = env.P_tensor # [num. actions x num. states x num. states]
self.R = env.R_tensor # [num. actions x num. states]
print("Tensor DP agent initialized")
print("Environment spec: Num. state = {} | Num. actions = {} ".format(env.nS, env.nA))
dp_agent.set_env(env)
3. Policy Iteration (1) Policy Evaluation
\[T^{\pi}(V) \leftarrow R^{\pi} + \gamma P^{\pi} V\]-
\(R^{\pi}\) 의 25개의 요소는 \(R^{\pi}_s\), where \(s=1,...,25\) ( $$R^{\pi} \in \mathbb{R}^{ \cal{S} }$$ ) -
$$R^{\pi}s = \sum{a \in \cal{A}} \pi(a s) R_s^a $$.
-
-
\(P^{\pi}\) 의 25x25개의 요소는 \(P^{\pi}_{ss'}\), where \(s,s'=1,...,25\) ( $$R^{\pi} \in \mathbb{R}^{ \cal{S} \times \cal{S} }$$ ) -
$$P^{\pi}{ss’} = \sum{a \in \cal{A}} \pi(a s) P_{ss’}^a $$.
-
3-1. \(R^{\pi}\) 계산하기
Agent의 (1) Policy, (2) Return, (3) weighted Return
policy = dp_agent.policy
R = dp_agent.env.R_tensor
weigthed_R = policy * R
print(policy.shape) # 25x4
print(R.shape) # 25x4
print(weigthed_R.shape) # 25x4
3-2. \(P^{\pi}\) 계산하기
df = pd.DataFrame(dp_agent.get_p_pi(dp_agent.policy))
print(df.shape) # 25x25
3-3. Policy Evaluation 코드
policy_evaluation 함수 소개
- Goal : policy(정책) 평가하기!
- INPUT
- policy: 평가하고자 하는 policy
- v_init: initial value function
- OUTPUT
- v_pi: 해당 policy에 맞는 value function
def policy_evaluation(self, policy=None, v_init=None):
if policy is None:
policy = self.policy
r_pi = self.get_r_pi(policy) # 25(상태) x 1(보상값)
p_pi = self.get_p_pi(policy) # 25(상태) x 25(상태)
if v_init is None:
v_old = np.zeros(self.ns)
else:
v_old = v_init
while True:
v_new = r_pi + self.gamma * np.matmul(p_pi, v_old) # value function 업데이트
err = np.linalg.norm(v_new - v_old) # 수렴 여부 확인
if err <= self.error_tol:
break
else:
v_old = v_new
return v_new
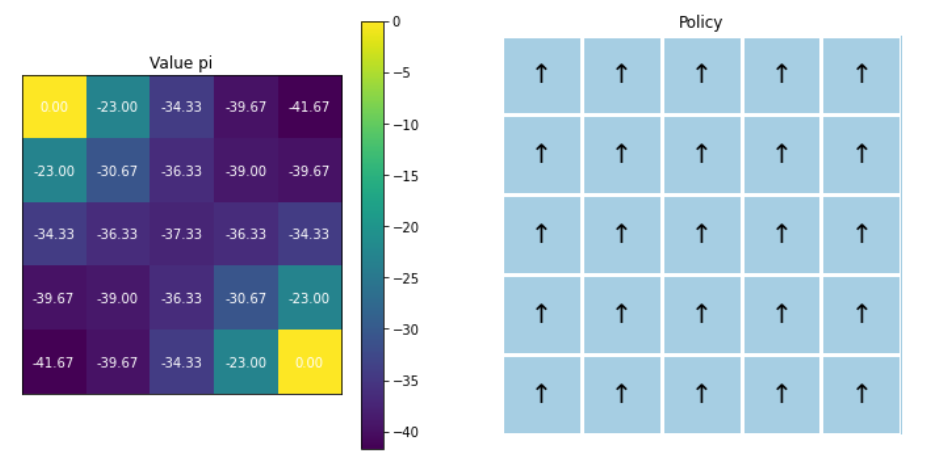
Policy evaluation 수행하기
v_pi = dp_agent.policy_evaluation()
print(v_pi.shape) # 25 ( 현재 policy하에서, 25개의 state에 대한 value값들 )
v_old = v_pi
3-4. 결과 시각화
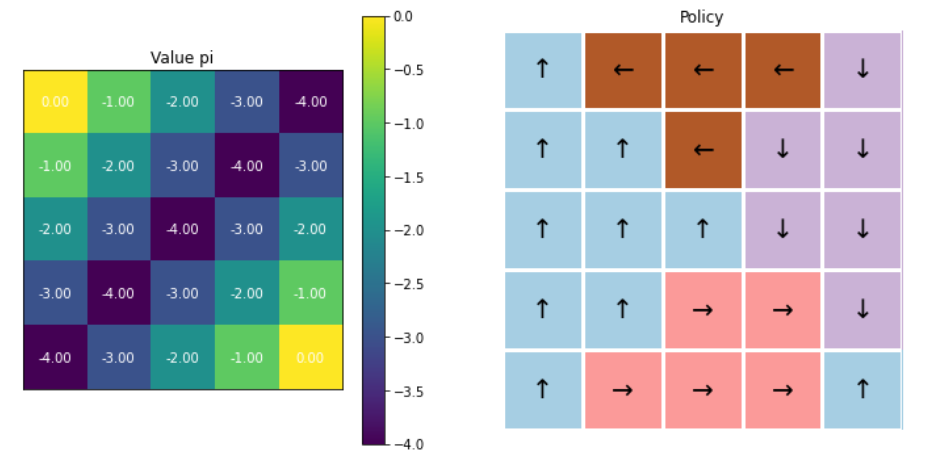
fig, ax = plt.subplots(1,2, figsize=(12,6))
visualize_value_function(ax[0], v_pi, nx, ny)
_ = ax[0].set_title("Value pi")
visualize_policy(ax[1], dp_agent.policy, nx, ny)
_ = ax[1].set_title("Policy")
- 오른쪽 그림에서도 알 수 있듯, 아직 policy가 개선된 것이 아님!
- 단지 현재 policy대로 했을 경우, 얻게 되는 value function을 계산한 것일 뿐! ( = policy EVALUATION )
4. Policy Iteration (2) Policy Improvement
[ Algorithm ]
Step 1) \(V^{\pi}(s)\) 와 \(P\), \(R\) 를 이용해 \(Q^{\pi}(s,a)\) 를 계산한다.
- \[Q^\pi(s,a) = R_s^{a} + \gamma \Sigma_{s' \in \cal{S}}P_{ss'}^aV^{\pi}(s')\]
| Step 2) 개선된 정책 $$\pi’(a | s)\(을 가장 높은\)Q^{\pi}(s,a)\(값을 주는\)a$$ 에 대해서 1로, 나머지는 0으로 |
4-1. Policy Improvement 코드
def policy_improvement(self, policy=None, v_pi=None):
if policy is None:
policy = self.policy
if v_pi is None:
v_pi = self.policy_evaluation(policy)
# (1) [Step 1] Compute Q_pi(s,a) from V_pi(s)
r_pi = self.get_r_pi(policy)
q_pi = r_pi + self.P.dot(v_pi)
# (2) [Step 2] Greedy improvement
policy_improved = np.zeros_like(policy)
policy_improved[np.arange(q_pi.shape[1]), q_pi.argmax(axis=0)] = 1
return policy_improved
Policy Improvement 수행하기
p_new = dp_agent.policy_improvement()
dp_agent.set_policy(p_new) # 정책 update하기
방금 개선한 policy에 따라 value function 계산하기
v_pi = dp_agent.policy_evaluation()
v_new = v_pi
4-2. 정책 개선 정리
BETTER policy \(\rightarrow\) HIGHER value function
\(\pi' \geq \pi\).
\(\pi' \geq \pi \leftrightarrow V_{\pi'}(s) \geq V_{\pi}(s) \forall s \in S\).
앞서서 improvement이전과 이후의 value function을 각각 v_old와 v_new에 저장하였다.
delta_v = v_new - v_old
sum(delta_v<0) # 0
모든 state에서의 value가 더 커진 것을 확인할 수 있다.
4-3. 결과 시각화
fig, ax = plt.subplots(1,2, figsize=(12,6))
visualize_value_function(ax[0], v_pi, nx, ny)
_ = ax[0].set_title("Value pi")
visualize_policy(ax[1], dp_agent.policy, nx, ny)
_ = ax[1].set_title("Policy")