
( 참고 : Fastcampus 강의 )
[ 10. Asynchronous(비동기적) DP ]
-
동기적 DP : 모든 state에 대해 연산 \(\rightarrow\) 높은 계산량
-
비동기적 DP : 모든 state를 다 거치지 않음 \(\rightarrow\) 하지만, 수렴성은 보장됨!
1. Inplace DP
-
\(t\), \(t-1\) 시점 두개의 \(V(s)\)를 저장하지 않고, 한개만 저장!
- 현재 알고 있는 가장 새로운 값 \(V(s)\)를 활용하여 \(V(s)\)들을 update
- 장점
- 메모리 사용량 \(\downarrow\)
- 수렴속도 빠름
- 구현하기 쉬움
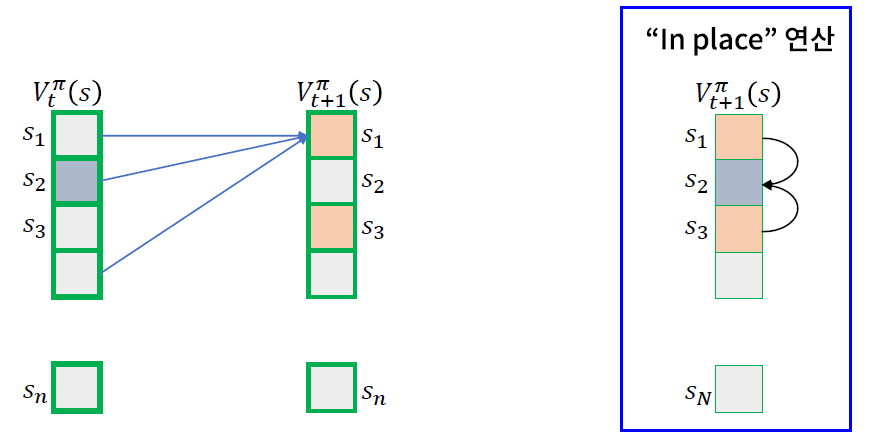

Value Iteration vs Inplace Value Iteration
- VI ) \(V_k(s)\) 와 \(V_k+1(s)\) 을 유지하고, \(V_k+1(s)\) 계산할 때 \(V_k(s)\)을 참조
- Inplace VI ) \(V(s)\)만을 유지하고, \(V(s')\) 계산할 때 \(V(s)\)을 참조
2. Prioritized DP
\[\text { Bellman error }(s)=\left|\max _{a \in \mathcal{A}}\left(R_{s}^{a}+\gamma \sum_{s^{\prime} \in \delta} P_{S s^{\prime}}^{a} V\left(s^{\prime}\right)\right)-V(s)\right|\]Bellman Error가 큰 \(s\) 부터 먼저 update하기
3. Partial Sweeping Value Iteration
update_prob 는 한번의 Value Iteration 과정에서, update_prob 만큼의 확률로 state를 업데이트 한다
4. Real Time DP
Agent가 현재 겪은 state에 대해서만 update
\(V\left(S_{t}\right)=\max _{a \in \mathcal{A}}\left(R_{S_{t}}^{a}+\gamma \sum_{S^{\prime} \in \mathcal{S}} P_{S_{t} S^{\prime}}^{a} V\left(s^{\prime}\right)\right)\).
5. DP Summary
