
( 참고 : Fastcampus 강의 )
[ 18. SARSA ( = TD Control ) ]
Contents
- Review
- TD Control : SARSA
- N-step SARSA
- Forward-view SARSA
- Backward-view SARSA
1. Review
지금 까지 알아본 내용들 (MC, TD)는, “어떻게 가치 함수(value-function)을 online하게 update할 수 있을 까”, 즉, evaluation에 관한 방법론들이었다.
이번에 살펴볼 SARSA는 control에 관한 방법론이다. ( = optimal policy 찾기 )
2. TD Control : SARSA
SARSA : Time Difference Learning + (1) & (2)
- (1) value function 대신 action-value function을 사용하고(model-free 해짐)
- (2) epsilon-greedy improvement를 적용한 것이다(local-optimum 문제 해결).
식으로 표현하면 다음과 같다.
1 ) Value Function을 사용한 TD
- \(V(S_t) \leftarrow V(S_t) + \alpha(R_{t+1}+\gamma\;V(S_{t+1})-V(S_t))\).
2) Action-Value Function을 사용한 TD
- \(Q(S_t,A_t) \leftarrow Q(S_t,A_t) + \alpha (R_{t+1} + \gamma \;Q(S_{t+1},A_{t+1}) - Q(S_t,A_t))\).
알고리즘명이 SARSA인 이유는,
위 식/아래 그림에서 볼 수 있듯 S(state),A(action), R(reward)가 나오고
그 이후에 다음 S(state’), A(Action’)이 나오기 때문이다.

Algorithm

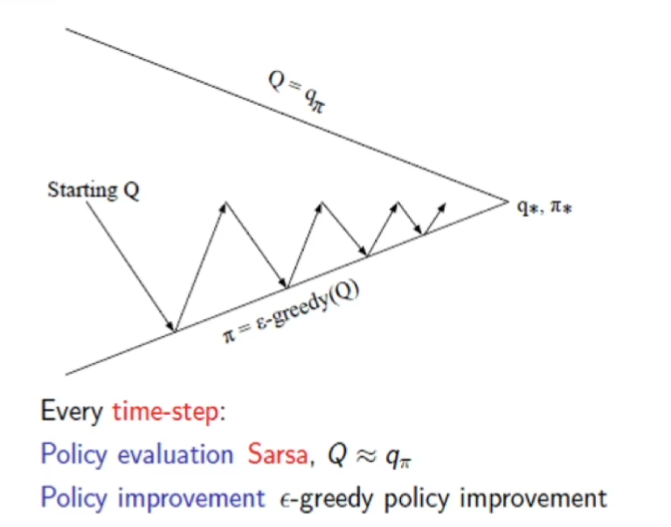
SARSA control = SARSA policy evaluation + \(\epsilon\) greedy
요약하자면, 매 time-step마다 다음과 같은 과정이 iterative하게 이루어진다
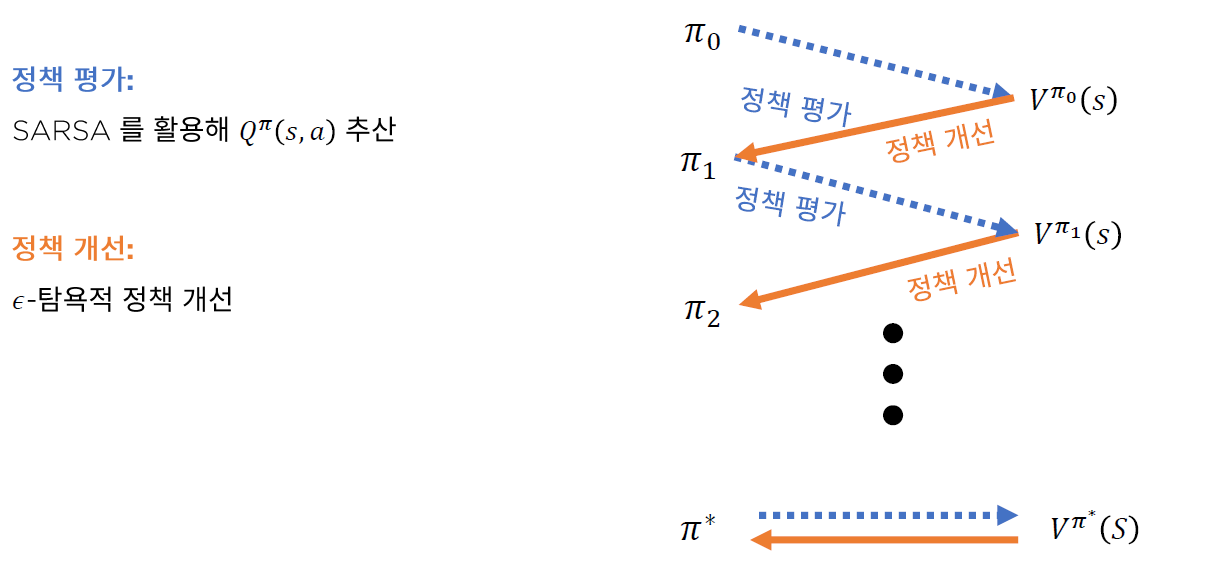
- 1 ) Policy Evaluation : SARSA
- 2 ) Policy Improvement : \(\epsilon-greedy\) policy improvement
3. N-step SARSA
N-step SARSA = N-step TD + value function 대신 action-value function (=Q function)
- \(n=1\) : (일반) SARSA
- \(q_t^{(1)} = R_{t+1} + \gamma \; Q(S_{t+1})\).
- \(n \rightarrow \infty\) : Monte Carlo Learning
- \(q_t^{(\infty)} = R_{t+1} + \gamma \; R_{t+2} + ... + \gamma^{T-1}R_T\).
- \(n=N\) : N-step SARSA
- \(q_t^{(n)} = R_{t+1} + \gamma \; R_{t+2} + ... + \gamma^{n-1}R_{t+n} + \gamma^n Q(S_{t+n})\).
updating equation
- \(Q(S_t,A_t) \leftarrow Q(S_t,A_t) + \alpha (q_t^{(n)}- Q(S_t,A_t))\).
( Forward view와 Backward view도 앞서 배운 내용과 동일하다. )
(1) Forward-view SARSA

\(\begin{aligned} &Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\alpha\left(q_{t}^{\lambda}-Q\left(S_{t}, A_{t}\right)\right) \\ &\text { where } q^{\lambda}-\text { return, } q_{t}^{\lambda}=(1-\lambda) \sum_{n=1}^{\infty} \lambda^{n-1} q_{t}^{(n)} \end{aligned}\).
(2) Backward-view SARSA
( 핵심 : Eligibility Trace 사용 )
\(E_t(s) = \left\{\begin{matrix} \gamma\;\lambda\;E_{t-1}(s,a)\;\;\;\;\;\;\;\;\;\;\;\;\;\; otherwise\\ \gamma\;\lambda\;E_{t-1}(s,a)+1\;\;\;\;\; if,\;s= s_t,a=a_t \end{matrix}\right.\).
\(Q(S_t,A_t) \leftarrow Q(S_t, A_t) + \alpha\;\delta_t\;E_t(s,a)\).
- where \(\delta_t = R_{t+1}+\gamma\;Q(S_{t+1},A_{t+1}) - Q(S_t,A_t) \;\;(= TD\; error)\).
Algorithm

4. Summary
-
Evaluation vs Control
-
Evaluation : value function을 ESTIMATE
- ex) MC Learning, TD Learning
-
Control: value function을 OPTIMIZE
( 즉, optimal policy 찾기 )
- ex) SARSA
-
-
SARSA = TD-learning + (1) & (2)
-
(1) Q-value function 사용
\(Q(S_t,A_t) \leftarrow Q(S_t,A_t) + \alpha (R_{t+1} + \gamma \;Q(S_{t+1},A_{t+1}) - Q(S_t,A_t))\).
-
(2) \(\epsilon\)-greedy improvement
-
-
N-step SARSA
- \(q_t^{(n)} = R_{t+1} + \gamma \; R_{t+2} + ... + \gamma^{n-1}R_{t+n} + \gamma^n Q(S_{t+n})\).
-
마찬가지로 forward & backward view