
( 참고 : Fastcampus 강의 )
[ 38. (paper 3) DDPG (Deep Deterministic Policy Gradient) code review ]
1. Import Packages
import sys; sys.path.append('..')
import torch
import gym
import numpy as np
from src.part3.MLP import MultiLayerPerceptron as MLP
from src.part5.DQN import prepare_training_inputs
from src.part5.DDPG import DDPG, Actor, Critic
from src.part5.DDPG import OrnsteinUhlenbeckProcess as OUProcess
from src.common.memory.memory import ReplayMemory
from src.common.train_utils import to_tensor
from src.common.target_update import soft_update
2. Environment 소개 : Pendulum
Environment for “CONTINUOUS” action space
-
Goal : Pendulum 을 최대한 “곧게 위의 방향으로” 세우는 것
- State : Pendulum 의 각도 \(\theta\)의 코사인 값 \(\cos(\theta)\), 사인 값 \(\sin(\theta)\), 그리고 각속도 \(\dot \theta\)
- Action : Pendulum의 끝에 좌/우 방향으로 최대 2.0 의 토크값 \(\mathcal{A} = [-2.0, 2.0]\)
\(\rightarrow\) 보상 \(r\) 은 \(\theta\), \(\dot \theta\), \(a\) 가 0에 가까워 질수록 높은 보상
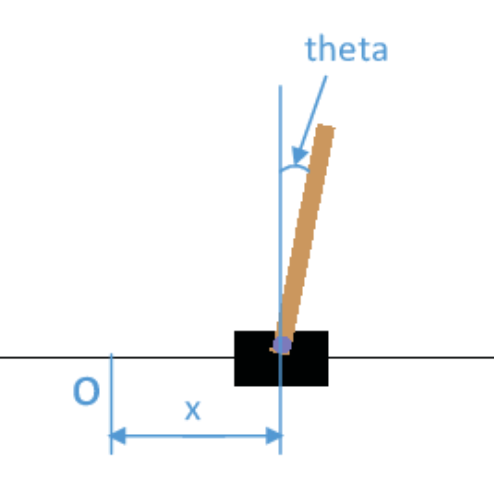
환경 만들기
env = gym.make('Pendulum-v0')
pre-trained된 거 사용할지 / CPU.GPU 사용할지
FROM_SCRATCH = False
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
3. DDPG 알고리즘 복습

Key Point
- Continuous Action space를 다룰 수 있다
- Deterministic Poily \(\rightarrow\) Off-Policy 가능!
- Actor & Critic Network ( + Target Network 쌍 ) : 총 4개의 network
- Soft update ( weighted average로 update )
4. DDPG
Input :
- 4개의 network ( Critic, Critic’s Target, Actor, Actor’s Target)
- 2개의 learning rate ( for Critic & for Actor )
- \(\gamma\) : discount rate
Optimizer :
- Critic(+Critic Network) & Actor(+Actor Network)를 위한 서로 다른 2개의 optimizer
Loss:
- L1 Smooth Loss
Critic Target : \(y_{i}=r_{i}+\gamma Q^{\prime}\left(s_{i+1}, \mu^{\prime}\left(s_{i+1} \mid \theta^{\mu^{\prime}}\right) \mid \theta^{Q^{\prime}}\right)\)
critic_target = r + self.gamma * self.critic_target(s_, self.actor_target(s_)) * (1 - d)
Critic Loss : \(L=\frac{1}{N} \sum_{i}\left(y_{i}-Q\left(s_{i}, a_{i} \mid \theta^{Q}\right)\right)^{2}\)
critic_loss = self.criteria(self.critic(s, a), critic_target)
Actor Loss 미분한거 : \(\nabla_{\theta^{\mu}} J \approx \frac{1}{N} \sum_{i} \nabla_{a} Q\left(s, a \mid \theta^{Q}\right) \mid _{s=s_{i}, a=\mu\left(s_{i}\right)} \nabla_{\theta^{\mu}} \mu\left(s \mid \theta^{\mu}\right) \mid _{s_{i}}\)
- (미분 전)
actor_loss = -self.critic(s, self.actor(s)).mean()
(1) DDPG
class DDPG(nn.Module):
def __init__(self,
critic: nn.Module,
critic_target: nn.Module,
actor: nn.Module,
actor_target: nn.Module,
lr_critic: float = 0.0005,
lr_actor: float = 0.001,
gamma: float = 0.99):
super(DDPG, self).__init__()
self.critic = critic
self.actor = actor
self.lr_critic = lr_critic
self.lr_actor = lr_actor
self.gamma = gamma
self.critic_opt = torch.optim.Adam(params=self.critic.parameters(),
lr=lr_critic)
self.actor_opt = torch.optim.Adam(params=self.actor.parameters(),
lr=lr_actor)
critic_target.load_state_dict(critic.state_dict())
self.critic_target = critic_target
actor_target.load_state_dict(actor.state_dict())
self.actor_target = actor_target
self.criteria = nn.SmoothL1Loss()
def get_action(self, state):
with torch.no_grad():
a = self.actor(state)
return a
def update(self, s, a, r, s_, d):
#---------------- Critic 관련 ------------------#
with torch.no_grad():
critic_target = r + self.gamma * self.critic_target(s_, self.actor_target(s_)) * (1 - d)
critic_loss = self.criteria(self.critic(s, a), critic_target)
self.critic_opt.zero_grad()
critic_loss.backward()
self.critic_opt.step()
#---------------- Actor 관련 ------------------#
actor_loss = -self.critic(s, self.actor(s)).mean()
self.actor_opt.zero_grad()
actor_loss.backward()
self.actor_opt.step()
(2) Soft Update
\(\begin{aligned} \theta^{Q^{\prime}} & \leftarrow \tau \theta^{Q}+(1-\tau) \theta^{Q^{\prime}} \\ \theta^{\mu^{\prime}} & \leftarrow \tau \theta^{\mu}+(1-\tau) \theta^{\mu^{\prime}} \end{aligned}\).
- Moving target 문제를 완화하기 위해 사용
- \(\tau\) & \(1-\tau\)의 비율로, OLD & NEW paramter를 섞어
def soft_update(target_net, main_net, tau):
for theta_, theta in zip(main_net.parameters(), target_net.parameters()):
theta_.data.copy_(theta_.data * (1.0 - tau) + theta.data * tau)
(3) Actor for Continuous action
Actor의 Input : ‘state’
Action space : \(\mathcal{A} = [-2.0, 2.0]\)
-
출력의 범위에 제한이 필요하다 : pytorch의
clamp( = clipping이라고 생각하면 됨 )
class Actor(nn.Module):
def __init__(self):
super(Actor, self).__init__()
# [MLP input = 3] state dimension이 3개
# [MLP output = 1] action dimension이 1개
self.mlp = MLP(3, 1,
num_neurons=[128, 64],
hidden_act='ReLU',
out_act='Identity')
def forward(self, state):
return self.mlp(state).clamp(-2.0, 2.0)
(4) Critic for Continuous action
Critic의 Input : ‘state’ & ‘action’
3개로 구성
-
state_encoder: MLP(3,x) -
action_encoder: MLP(1,y) -
q_estimator: MLP(x+y,1)(
state_encoder와action_encoder에서 인코딩 된 결과를 concatenate하여 NN 태운 뒤 결과 출력)
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.state_encoder = MLP(3, 64,num_neurons=[],out_act='ReLU')
self.action_encoder = MLP(1, 64,num_neurons=[],out_act='ReLU')
self.q_estimator = MLP(128, 1,num_neurons=[32],
hidden_act='ReLU',out_act='Identity')
def forward(self, x, a):
emb = torch.cat([self.state_encoder(x), self.action_encoder(a)], dim=-1)
Q_val = self.q_estimator(emb)
return Q_val
5. Experiment
(1) Hyperparameters
-
soft target update의 parameter 인 \(\tau\) = 0.001
( 0.001만큼은 파라미터 값, 0.999만큼은 새로운 파라미터 값)
-
Replay Buffer에 2000번 샘플링 완료되면 학습시작
lr_actor = 0.005
lr_critic = 0.001
gamma = 0.99
batch_size = 256
memory_size = 50000
tau = 0.001
sampling_only_until = 2000
total_eps = 200
print_every = 10
(2) 4개의 Network / Agent / Replay Buffer 불러오기
actor, actor_target = Actor(), Actor()
critic, critic_target = Critic(), Critic()
agent = DDPG(critic=critic,
critic_target=critic_target,
actor=actor,
actor_target=actor_target).to(DEVICE)
memory = ReplayMemory(memory_size)
(3) Run Iterations
if FROM_SCRATCH:
for n_epi in range(total_eps):
# (action 샘플링 위한) Ornstein–Uhlenbeck process
ou_noise = OUProcess(mu=np.zeros(1))
s = env.reset()
cum_r = 0 # cumulative reward
# -------------- 1번의 episode 동안 ---------------- #
while True:
s = to_tensor(s, size=(1, 3)).to(DEVICE)
a = agent.get_action(s).cpu().numpy() + ou_noise()[0]
s_, r, d, info = env.step(a)
experience = (s,
torch.tensor(a).view(1, 1),
torch.tensor(r).view(1, 1),
torch.tensor(s_).view(1, 3),
torch.tensor(d).view(1, 1))
memory.push(experience) # Replay Memory에 저장하기
s = s_
cum_r += r
#---- 2,000개 이상의 sample이 쌓이면 Train 시작 -----#
if len(memory) >= sampling_only_until:
# train agent
sampled_exps = memory.sample(batch_size)
sampled_exps = prepare_training_inputs(sampled_exps, device=DEVICE)
agent.update(*sampled_exps)
# update target networks
soft_update(agent.actor, agent.actor_target, tau)
soft_update(agent.critic, agent.critic_target, tau)
if done:
break
#-------------------------------------------------#
if n_epi % print_every == 0:
msg = (n_epi, cum_r)
print("Episode : {} | Cumulative Reward : {} |".format(*msg))
torch.save(agent.state_dict(), 'ddpg_cartpole_user_trained.ptb')
else:
agent.load_state_dict(torch.load('ddpg_cartpole.ptb'))