[ Recommender System ]
2. Contents-based Recommender System
( 참고 : Fastcampus 추천시스템 강의 )
1. Main Idea
“서로 비슷한 성질의 Item을 추천해준다”
Steps for Contents-based Rec Sys
- 1) User가 과거에 구매한 Item 확인
- 2) 해당 Item과 유사한 다른 Item 선정
- 3) 새로운 Item을 유저에게 추천
2. Pros & Cons
장점
- 1) 다른 User의 정보는 필요 X ( 오직 제품에 관한 정보만 필요 )
- 2) 추천 가능한 Item의 범위가 넓음 ( 꼭 잘 팔리는 제품만 계속 추천해주게 되는 문제 X )
- 3) 추천의 근거 제시 가능 ( A와 B제품의 ~라는 유사한 특성에 의해 추천했습니다! )
단점
- 1) 적절한 feature를 찾기 어렵다 ( 비슷한 성질(feature)의 제품을 추천해준다고 했는데, 성질(feature)란 어떻게 정의? )
- 2) 새로운 User에게 추천이 어려움 ( 과거에 구매한 경험이 있어야, 이를 바탕으로 추천을 해줄텐데… )
- 3) 선호하는 특성의 Item만을 반복 추천 ( 새로운 취향/선호의 발굴을 해주기는 어려울텐데.. )
3. Architecture of Rec Sys
1) 정보 (User, Item) 제공
2) Item 분석
-
Item으로부터 feature extraction
( Item = set of features )
-
Item 파악하기 = Item의 vector representation 구하기
3) User분석
- User의 취향을 파악 & 선호할만한 Item 파악
- Explicit & Implicit Info
4) 유사 Item 선정
5) 추천 List 생성
4. 대표적 모델
( KNN, Naive Bayes, TF-IDF )
TF-IDF ( Term Frequency - Inverse Document Frequency )
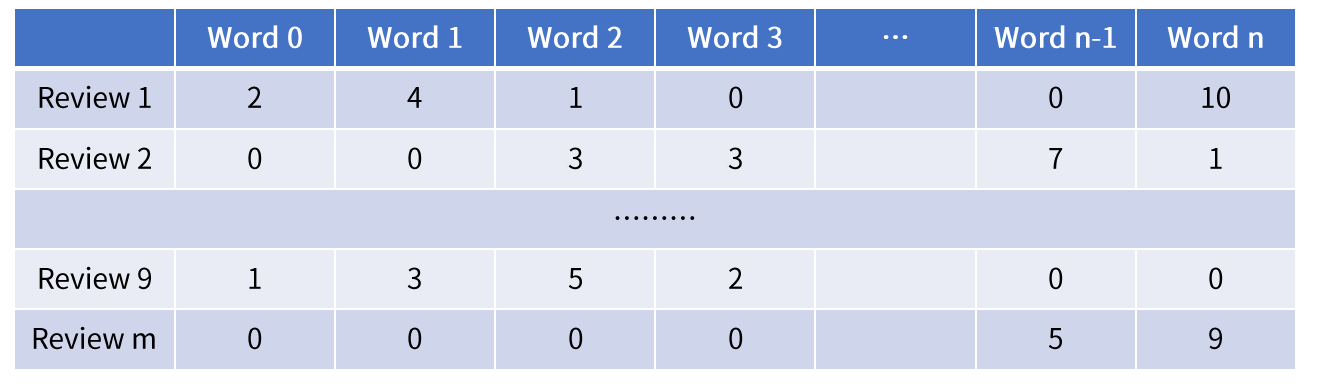
review-word frequency matrix
-
총 \(m\)개의 review 문서
-
총 \(n\)개의 단어 사전 (vocab)
Notation
-
TF (Term Frequency) : 단어 \(w\) 가 문서 \(d\)에 등장한 빈도 수
-
DF (Document Frequency) : 단어 \(w\)가 등장한 문서의 개수
-
N : 전체 문서의 개수
( 기본 idea : 자주 등장하는 단어는 중요하지 않은 단어 )