
[ Recommender System ]
22.Review data로 RS 성능 올리기
( 참고 : Fastcampus 추천시스템 강의 )
1. 데이터 소개
- 사용할 데이터 : Amazon Review data (2018) 中 ‘Software’
Software.csv&Software_5.json
import os, json
import pandas as pd
import re
2. 데이터 전처리
(1) Softward.csv
ratings_df = pd.read_csv(os.path.join(path, 'Software.csv'), header=None, names=['item','user','rating','timestamp'], encoding='utf-8')
(2) Software_5.json
data = []
with open(os.path.join(path, 'Software_5.json'), 'r', encoding='utf-8') as f:
for l in f:
data.append(json.loads(l.strip()))
all_df = pd.DataFrame.from_dict(data)
all_df = all_df[['reviewerID', 'asin', 'vote', 'reviewText', 'overall']]
아래의 전처리를 수행한다
- 1) 불필요한 문자들 제거
- 2) 리뷰는 앞에서 부터 최대 30글자만 사용
- 3) 10글자 미만의 리뷰는 사용 X
removal_list = "‘, ’, ◇, ‘, ”, ’, ', ·, \“, ·, △, ●, , ■, (, ), \", >>, `, /, -,∼,=,ㆍ<,>, .,?, !,【,】, …, ◆,%"
def preprocess_sent(sentence):
sentence = re.sub("[.,\'\"’‘”“!?]", "", sentence)
sentence = re.sub("[^0-9a-zA-Z\\s]", " ", sentence)
sentence = re.sub("\s+", " ", sentence)
sentence = sentence.translate(str.maketrans(removal_list, ' '*len(removal_list)))
sentence = sentence.strip()
return sentence
all_df = all_df[['reviewText','overall']]
all_df.dropna(how='any', inplace=True)
all_df['reviewText'] = all_df['reviewText'].apply(lambda x: preprocess_sent(str(x).replace('\t',' ').replace('\n',' ')))
all_df['reviewText'] = all_df['reviewText'].apply(lambda x: ' '.join(x.split(' ')[:30]))
all_df['num_lengths'] = all_df['reviewText'].apply(lambda x: len(x.split(' ')))
all_df = all_df[all_df.num_lengths > 10]
all_df.drop('num_lengths', axis=1, inplace=True)
최종 데이터 저장하기
all_df.to_csv(os.path.join(path, 'Software_reviewText.csv'), sep='\t', encoding='utf-8')
3. 전처리한 데이터 불러오기
Torchtext 개요 : 다음의 과정들을 손쉽게 할 수 있게 해준다
- 1) Tokenization
- 2) Build Vocabulary
- 3) Numericalize all tokens
- 4) Create Data Loader
import torch
from torchtext import data
from torchtext import datasets
import random
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
다음의 2개의 Field 객체를 만든다
함수 : data.Field, data.LabelField
- 1) TEXT : 리뷰 텍스트를 담을 field
- 2) LABEL : 리뷰의 평점을 담을 field
TEXT = data.Field(tokenize = 'spacy')
LABEL = data.LabelField()
위에서 지정한 2개의 필드를 기반으로, 데이터를 불러온다.
함수 : data.TabularDataset
fields = [(None, None), ('text', TEXT), ('label', LABEL)]
training_data = data.TabularDataset(path=os.path.join(path,'Software_reviewText.csv'),
format ='tsv', fields = fields, skip_header = True)
예시로, 하나의 sample 텍스트를 불러오면 아래와 같다.
print(vars(training_data.examples[0]))
{'text': ['I', 've', 'been', 'using', 'Dreamweaver', 'and', 'its', 'predecessor', 'Macromedias', 'UltraDev', 'for', 'many', 'years', 'For', 'someone', 'who', 'is', 'an', 'experienced', 'web', 'designer', 'this', 'course', 'is', 'a', 'high', 'level', 'review', 'of', 'the', 'CS5'], 'label': '4.0'}
단어 사전 (Vocabulary)을 만든다
함수 : TEXT.build_vocab
MAX_VOCAB_SIZE = 25000
TEXT.build_vocab(training_data,
max_size = MAX_VOCAB_SIZE)
LABEL.build_vocab(training_data)
예시로써, 각 평점(1~5점)이 어떻게 라벨링 되었는지 확인!
print(LABEL.vocab.stoi)
defaultdict(<function _default_unk_index at 0x7f33c4bac6a8>, {'5.0': 0, '4.0': 1, '3.0': 2, '1.0': 3, '2.0': 4})
Data Loader를 만들어준다.
함수 : data.BucketIterator.splits
BATCH_SIZE = 64
train_data, valid_data = training_data.split(split_ratio=0.8, random_state = random.seed(1234))
train_iterator, valid_iterator = data.BucketIterator.splits(
(train_data, valid_data),
sort_key = lambda x: len(x.text),
sort_within_batch=False,
batch_size = BATCH_SIZE
)
3. 모델 아키텍쳐
- Yoon Kim, 2014, Convolutional Neural Networks for Sentence Classification(논문 링크)
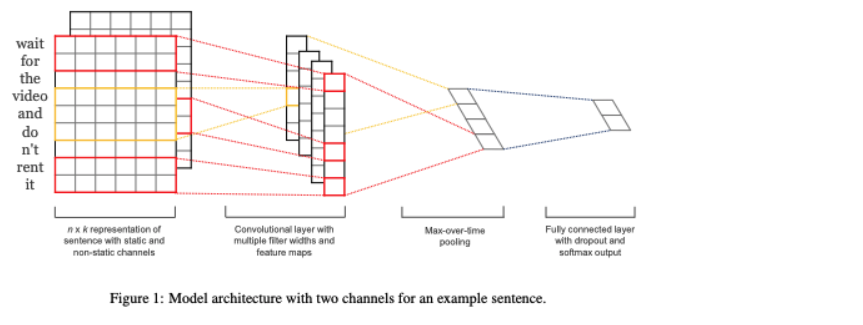
구성 :
- 1) Embedding layer
- 2) Convolutional layer
- 3) Fully Connected layer
- 4) Dropout
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
## 1) Permutation : [sent len, batch size] -> [batch size, sent len]
text = text.permute(1, 0)
## 2) Embedding : [batch size, sent len] -> [batch size, sent len, emb dim]
embedded = self.embedding(text)
## 3) Unsqueeze : [batch size, sent len, emb dim] -> [batch size, 1, sent len, emb dim]
embedded = embedded.unsqueeze(1)
## 4) Convolutional layer :
### before ) [batch size, 1, sent len, emb dim]
### after ) [batch size, n_filters, sent len - filter_sizes[n]]
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
## 5) Maxpooling 1d : [batch size, n_filters]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
## 6) Concatenate & dropout : [batch size, n_filters * len(filter_sizes)]
cat = self.dropout(torch.cat(pooled, dim = 1))
return self.fc(cat)
모델 생성하기
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
N_FILTERS = 100
FILTER_SIZES = [2,3,4]
OUTPUT_DIM = len(LABEL.vocab)
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
Unknown단어 : embedding weight 0으로!
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
4. 모델 학습하기
- Optimizer : Adam optimizer
- Loss function : Cross Entropy
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
- GPU / CPU 사용 여부
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)
- 배치(batch)별 정확도
def categorical_accuracy(preds, y):
max_preds = preds.argmax(dim = 1, keepdim = True) # get the index of the max probability
correct = max_preds.squeeze(1).eq(y)
return correct.sum() / torch.FloatTensor([y.shape[0]])
Train 함수
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text)
loss = criterion(predictions, batch.label)
acc = categorical_accuracy(predictions, batch.label
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
Evaluate 함수
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text)
loss = criterion(predictions, batch.label)
acc = categorical_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
epoch_time : 학습에 소요되는 시간을 함께 출력하기 위한 함수이다
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
< 학습 결과 >
N_EPOCHS = 10
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'cnn-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
Epoch: 01 | Epoch Time: 0m 10s
Train Loss: 1.498 | Train Acc: 39.40%
Val. Loss: 1.354 | Val. Acc: 43.87%
Epoch: 02 | Epoch Time: 0m 10s
Train Loss: 1.333 | Train Acc: 45.24%
Val. Loss: 1.285 | Val. Acc: 45.54%
Epoch: 03 | Epoch Time: 0m 11s
Train Loss: 1.254 | Train Acc: 48.85%
Val. Loss: 1.253 | Val. Acc: 46.23%
Epoch: 04 | Epoch Time: 0m 11s
Train Loss: 1.188 | Train Acc: 51.71%
Val. Loss: 1.225 | Val. Acc: 47.24%
Epoch: 05 | Epoch Time: 0m 11s
Train Loss: 1.113 | Train Acc: 55.51%
Val. Loss: 1.202 | Val. Acc: 49.88%
Epoch: 06 | Epoch Time: 0m 10s
Train Loss: 1.041 | Train Acc: 58.82%
Val. Loss: 1.208 | Val. Acc: 49.07%
Epoch: 07 | Epoch Time: 0m 10s
Train Loss: 0.963 | Train Acc: 61.46%
Val. Loss: 1.180 | Val. Acc: 51.23%
Epoch: 08 | Epoch Time: 0m 10s
Train Loss: 0.884 | Train Acc: 65.54%
Val. Loss: 1.193 | Val. Acc: 51.65%
Epoch: 09 | Epoch Time: 0m 10s
Train Loss: 0.802 | Train Acc: 69.40%
Val. Loss: 1.187 | Val. Acc: 51.83%
Epoch: 10 | Epoch Time: 0m 10s
Train Loss: 0.711 | Train Acc: 73.29%
Val. Loss: 1.186 | Val. Acc: 51.74%
5. 모델 평가하기
model.load_state_dict(torch.load('cnn-model.pt'))
import spacy
nlp = spacy.load('en')
def predict_class(model, sentence, min_len = 4):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
if len(tokenized) < min_len:
tokenized += ['<pad>'] * (min_len - len(tokenized))
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed)
tensor = tensor.unsqueeze(1)
preds = model(tensor)
max_preds = preds.argmax(dim = 1)
return max_preds.item()
예시) 긍정적인 리뷰 (“best item”)이라는 말을 남겼을 때, 5.0점의 평점으로 예측을 한다
pred_class = predict_class(model, "best item")
print(f'Predicted class is: {pred_class} = {LABEL.vocab.itos[pred_class]}')
Predicted class is: 0 = 5.0
6. BERT embedding
import nltk
nltk.download('punkt')
from nltk import tokenize
from transformers import BertModel, BertTokenizer
유명한 pre-trained된 모델인 BERT를 사용하여 임베딩한다.
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
def get_embedding(sentence):
sent_vectors = []
for sent in tokenize.sent_tokenize(sentence):
text = "[CLS] " + sent + " [SEP]"
tokenized_text = tokenizer.tokenize(text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [1] * len(tokenized_text)
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensor = torch.tensor([segments_ids])
with torch.no_grad():
outputs = model(tokens_tensor, segments_tensor)
encoded_layers = outputs[0] # last hidden state
sentence_embedding = torch.mean(encoded_layers[0], dim=0)
sent_vectors.append(sentence_embedding.detach().numpy())
return np.array(sent_vectors).mean(axis=0)
bert_embedding = get_embedding('hello, today is thursday')