
[ Recommender System ]
23. Image-based Recommendations on Styles and Substitutes
( 참고 : Fastcampus 추천시스템 강의 )
Abstract
보여지는 사물에 대한 “사람의 인식”을 modeling해야!
사용하는 데이터
- 유저의 기록, history (X)
- 이미 주어진 huge item 관련 dataset
데이터 속에 숨겨진 “시각적 관계” & “인간의 이해”를 모델링
어떠한 옷과 어떠한 악세사리가 어울리는지!
1. Introduction
dataset : Amazon ( 6,000,000개의 상품 & 180,000,000의 관계 )
이러한 dataset을 “Style and Substitues”라고 부름
Visual and Relational Recommender System
- 인간의 “시각적 선호도”를 modeling
- Image를 사용한다는 점이 핵심!
2. Model
\(F\)차원의 feature vector
상품 간 거리와 확률관계를 나타냄
- if \(i\)와 \(j\)가 서로 관련 있는 상품 = close
요약)
- 1) CNN으로 부터 item의 feature vector를 얻어내고
- 2) 해당 vector로부터 거리(distance) 계산
- 3) 거리를 바탕으로, 예측 정확도 최대화하도록 학습!
Personalized distance function을 정의
-
유저 별로, 각각의 item이 어떠한 관계가 있는지를 파악
-
각 관계의 존재 여부를 확률로 정의
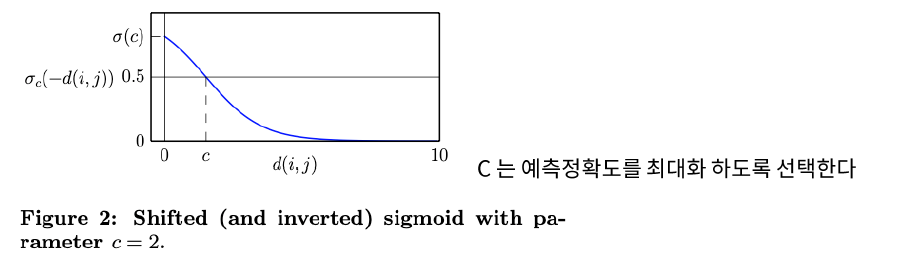
아래의 likelihood를 maximize하도록 학습!
\[\begin{aligned} l(\mathbf{Y}, c \mid \mathcal{R}, \mathcal{Q})=\sum_{r_{i j} \in \mathcal{R}} \log \left(\sigma_{c}\left(-d_{\mathbf{Y}}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)\right)\right)+\sum_{r_{i j} \in \mathcal{Q}} \log \left(1-\sigma_{c}\left(-d_{\mathbf{Y}}\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)\right)\right) \end{aligned}\]- 앞부분 : positive set
- 뒷부분 : negative set
3. Conclusion
- “시각적” 모델링
- 시각적 유사도를 바탕으로 관계를 판단