
[ Recommender System ]
( 참고 : Fastcampus 추천시스템 강의 )
7. [code] TF-IDF
- Movie representation
- with Genre
- with Tag
- Genre + Tag
- Cosine Similarity
- Prediction & Evaluation
데이터 소개

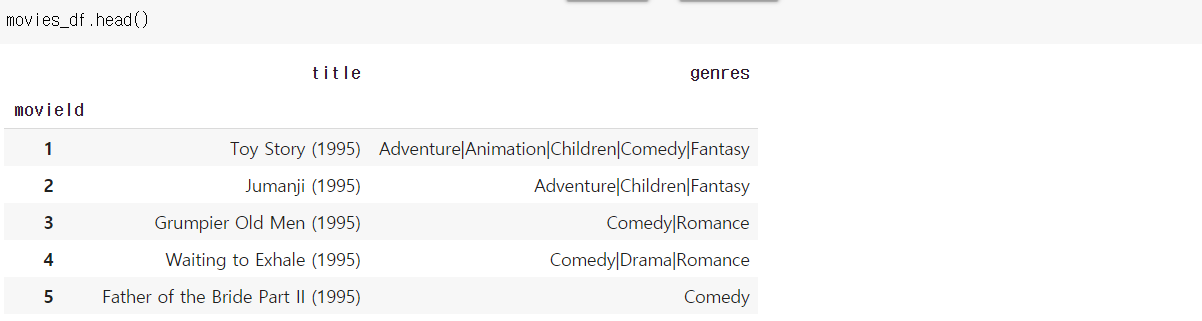

1. Movie representation
1-1. with Genre
- 총 장르의 종류 ( 20가지의 장르 )
total_genres = list(set([genre for sublist in list(map(lambda x: x.split('|'), movies_df['genres'])) for genre in sublist]))
- 장르 별 영화 수
genre_count = dict.fromkeys(total_genres)
for each_genre_list in movies_df['genres']:
for genre in each_genre_list.split('|'):
if genre_count[genre] == None:
genre_count[genre] = 1
else:
genre_count[genre] = genre_count[genre]+1
- count에 log 씌우기
for each_genre in genre_count:
genre_count[each_genre] = np.log10(total_count/genre_count[each_genre])
- Genre Representation
movies_df_temp = movies_df.copy().reset_index()
genres_df_temp = pd.concat([pd.Series(row['movieId'], row['genres'].split('|'))
for _, row in movies_df_temp.iterrows()]).reset_index()
genres_df_temp.columns=['genres','movieId']
genres_df_temp['genre_val'] = genres_df_temp['genres'].replace(genre_count)
genres_representation = genres_df_temp.pivot_table(index='movieId', columns='genres', values='genre_val')
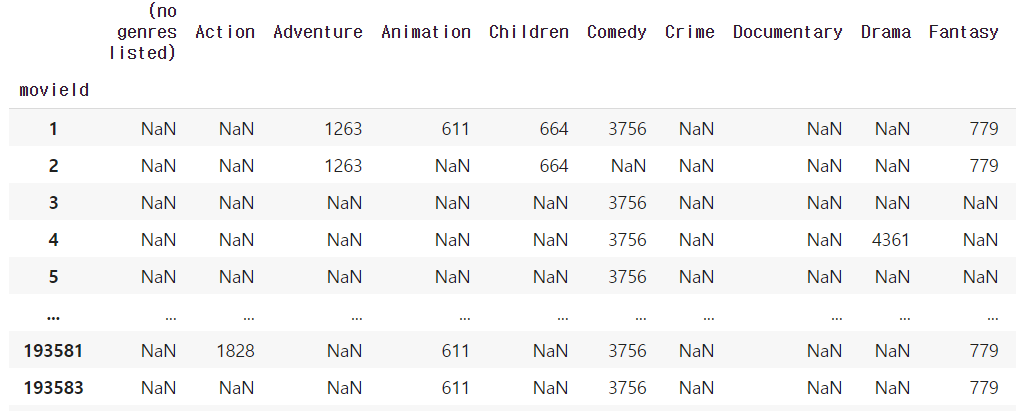
1-2. with Tag
- 총 태그의 종류
tag_column = list(map(lambda x: x.split(','), tags_df['tag']))
unique_tags = list(set(list(map(lambda x: x.strip(), list([tag for sublist in tag_column for tag in sublist])))))
IDF 계산하기
- tag별 등장 횟수
tag_count_dict = dict.fromkeys(unique_tags)
for each_movie_tag_list in tags_df['tag']:
for tag in each_movie_tag_list.split(","):
if tag_count_dict[tag.strip()] == None:
tag_count_dict[tag.strip()] = 1
else:
tag_count_dict[tag.strip()] += 1
-
tag IDF 계산하기
( 너무 자주 등장(흔한) 단어 = 덜 중요한 단어 )

tag_idf = dict()
total_movie_count = len(set(tags_df['movieId']))
for each_tag in tag_count_dict:
tag_idf[each_tag] = np.log10(total_movie_count / tag_count_dict[each_tag])

-
Tag Representation
( 영화별 Tag matrix )
tags_df_temp = tags_df.copy()
tags_df_temp['tagval'] = tags_df_temp['tag'].replace(tag_idf)
tag_representation = tags_df_temp.pivot_table(index='movieId', columns='tag', values='tagval')

1-3. Genre + Tag
movie_representation = pd.concat([genre_representation, tag_representation], axis=1).fillna(0)
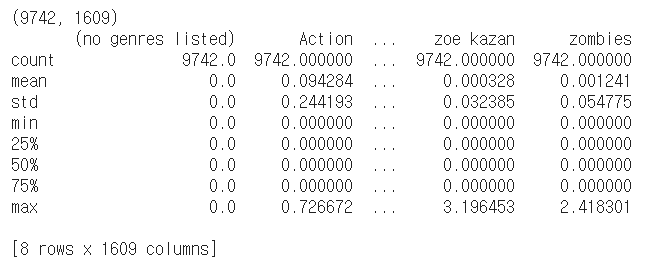
- shape과 describe를 확인한 결과
2. Cosine Similarity
from sklearn.metrics.pairwise import cosine_similarity
def cos_sim_matrix(a, b):
cos_sim = cosine_similarity(a, b)
result_df = pd.DataFrame(data=cos_sim, index=[a.index])
return result_df
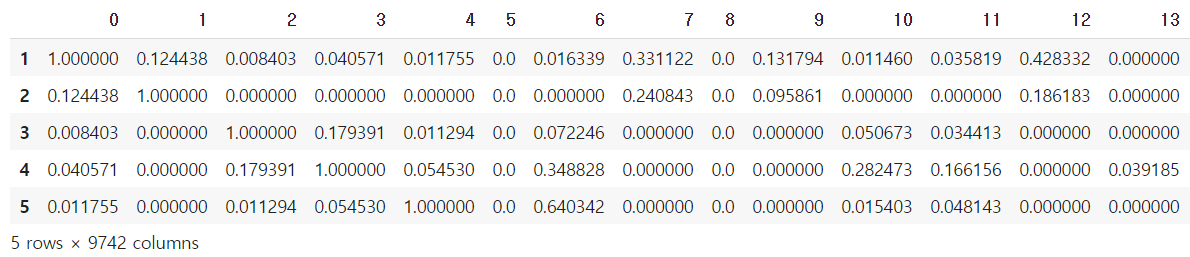
- 영화들 간의 코사인 유사도
cs_df = cos_sim_matrix(movie_representation, movie_representation)
3. Prediction & Evaluation
위에서 구한 코사인 유사도를 바탕으로, Test data 예측
train_df, test_df = train_test_split(ratings_df, test_size=0.2, random_state=1234)
test_userids = list(set(test_df.userId.values))
result_df = pd.DataFrame()
for user_id in tqdm(test_userids):
user_record_df = train_df.loc[train_df.userId == int(user_id), :]
user_sim_df = cs_df.loc[user_record_df['movieId']] # (n, 9742); n은 userId가 평점을 매긴 영화 수
user_rating_df = user_record_df[['rating']] # (n, 1)
sim_sum = np.sum(user_sim_df.T.to_numpy(), -1) # (9742, 1)
prediction = np.matmul(user_sim_df.T.to_numpy(), user_rating_df.to_numpy()).flatten() / (sim_sum+1) # (9742, 1)
prediction_df = pd.DataFrame(prediction, index=cs_df.index).reset_index()
prediction_df.columns = ['movieId', 'pred_rating']
prediction_df = prediction_df[['movieId', 'pred_rating']][prediction_df.movieId.isin(test_df[test_df.userId == user_id]['movieId'].values)]
temp_df = prediction_df.merge(test_df[test_df.userId == user_id], on='movieId')
result_df = pd.concat([result_df, temp_df], axis=0)
- 예측 결과
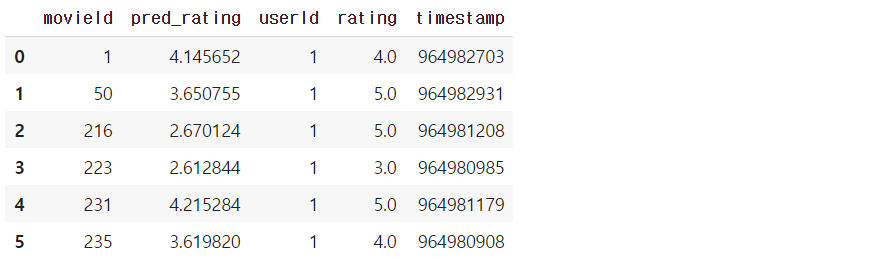
- RMSE : 약 1.586
rmse = np.sqrt(mean_squared_error(y_true=result_df['rating'].values, y_pred=result_df['pred_rating'].values))
print(rmse.round(3))