
( 출처 : 연세대학교 데이터베이스 시스템 수업 (CSI6541) 강의자료 )
Chapter 6. Introduction to Hadoop
(1) 3V
- Volume (크기)
- 분산 컴퓨팅을 활용
- Velocity (속도)
- 빠른 속도로 데이터가 생성됨
- 실시간 처리 기술이 요구됨
- 장기적이고 전략적인 차원에서의 데이터 접근성이 요구됨
- Variety (다양성)
- 정형(structured), 반정형(unstructured)
(2) Handling Big data
- Distributed File Systems ( ex. Hadoop )
- NoSQL ( ex. Redis, RocksDB )
(3) Apache Hadoop
Hadoop = (1) 분산 저장 + (2) 분산 처리
- (1) 분산 저장 (HDFS)
-
(2) 분산 처리 (Map Reduce)
- for 대용량 데이터 “분산 처리”
- java 기반의 open-source framework
Advantages of Hadoop
- (1) for 비정형 데이터
- 정형 데이터 : 기존 RDBMS이 good
- 비정형 데이터 : RDBMS에 저장되기엔 “저장 공간 낭비가 심함”
- (2) 오픈소스 & 경제적 효율성
- 라이선스 비용 X
- 저장공간 증대 위한 장비 필요 X
- (3) 손쉬운 데이터 복구
- 여러 개의 데이터 복제본을 저장
(4) Hadoop Ecosystem
core project : 분산 저장 (HDFS) & 분산 처리 (Map Reduce)
etc project : ….
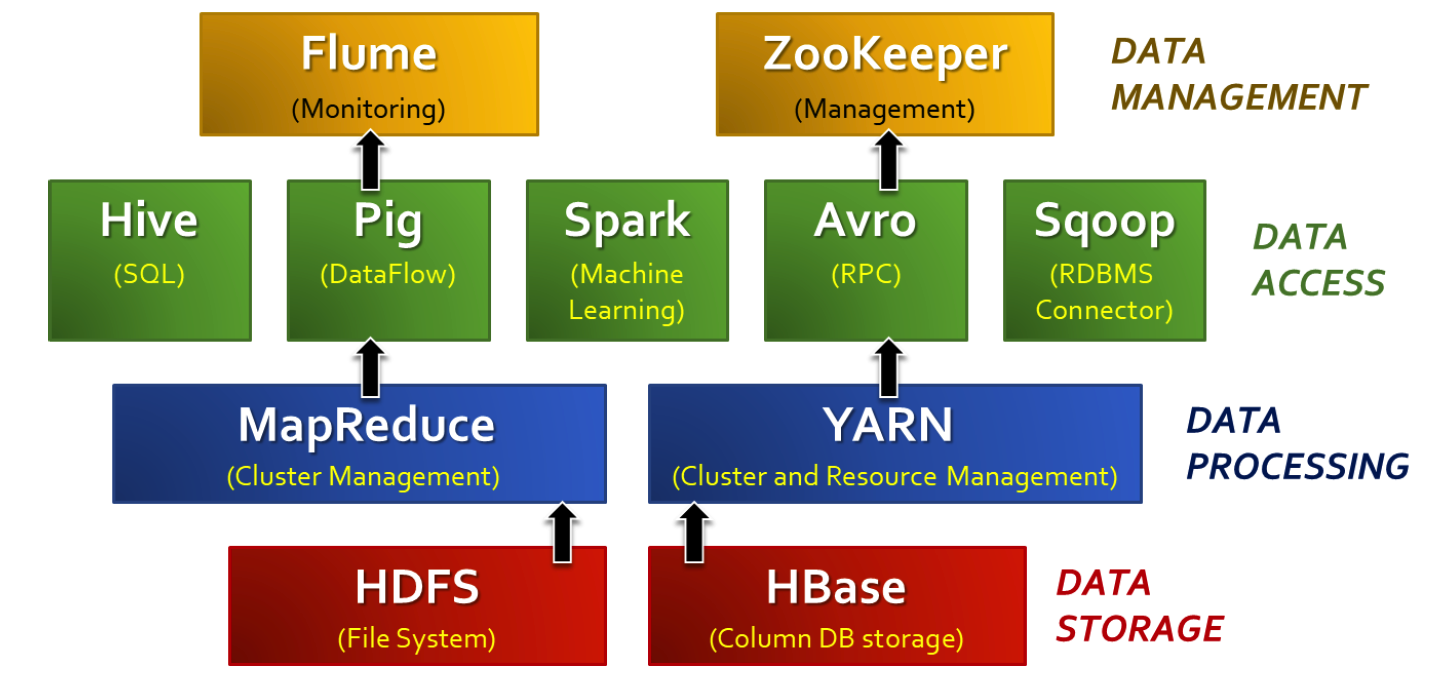
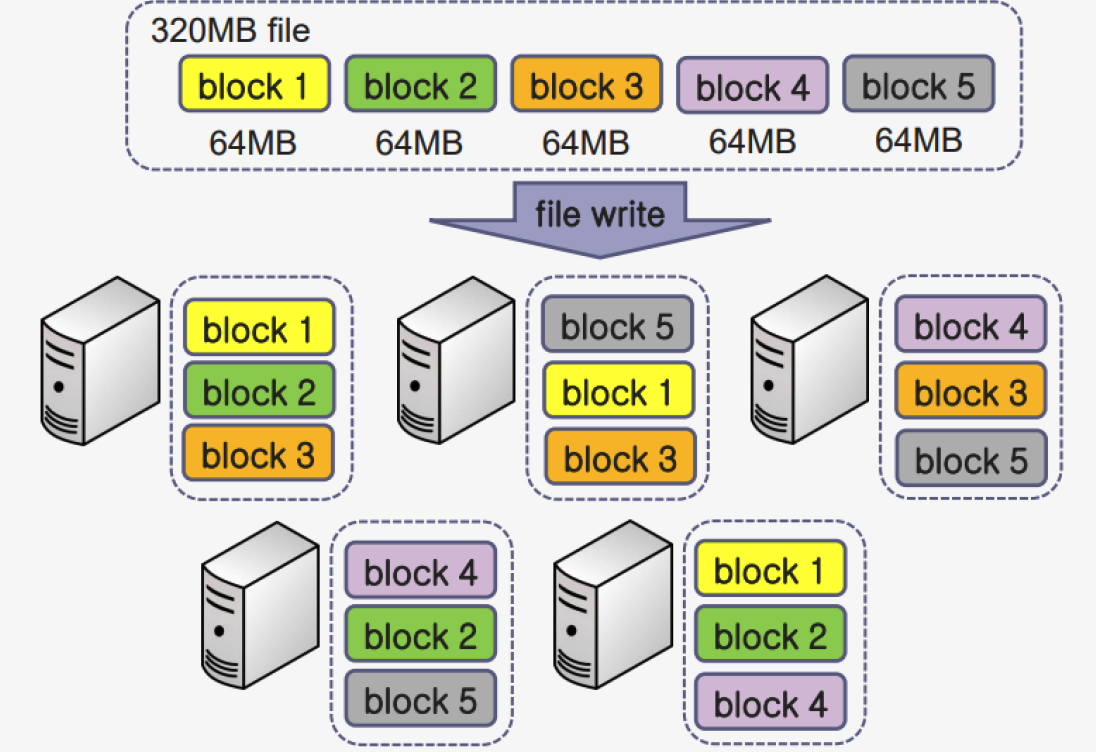
(5) HDFS
- Hadoop Distributed File Systems (HDFS)
- block-based DFS
- file stored in HDFS are divided into blocks of certain size
- these blocks are stored on distributed server
- GOOD for millions of large files
- POOR for billions of smaller files
- high scalability
- when saving blocks, stores a replica of 3 blocks (by default)
(6) HDFS block replication
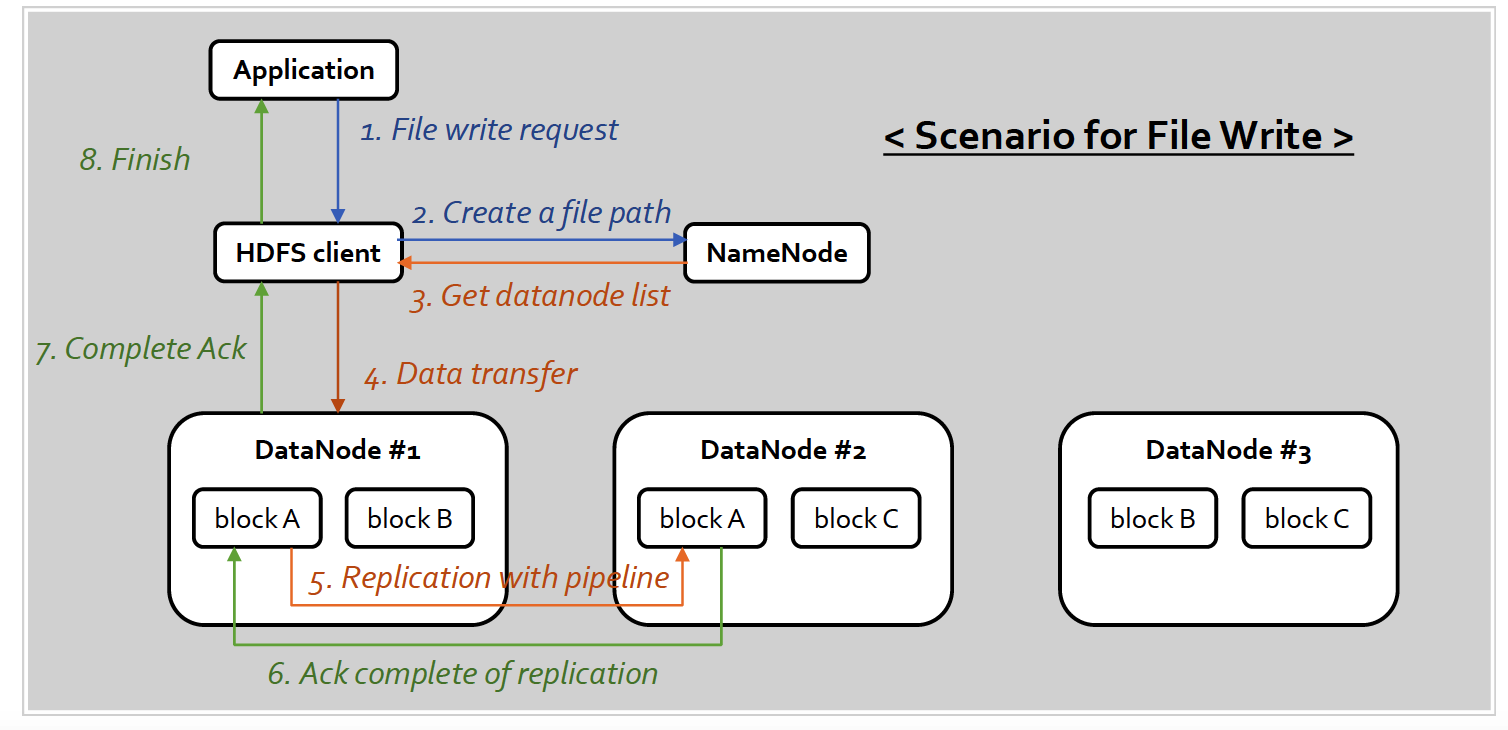
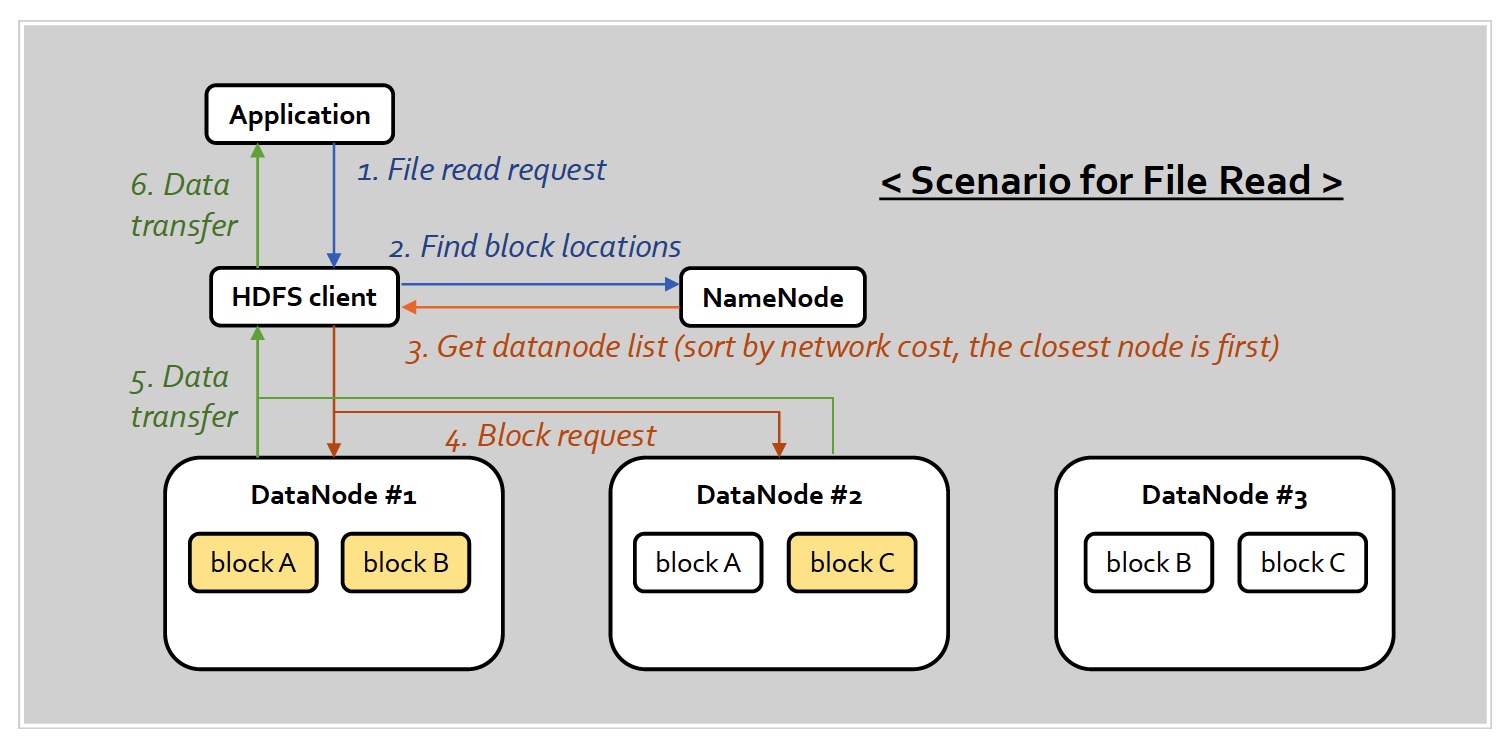
(7) HDFS architecture
Master-slave architecture
- Name node (=master)
- manages meta-data of HDFS
- allows client to access HDFS files, stored in Data Nodes
- Data nodes (=slave)
(8) Secondary NameNode
NameNode generates FsImage& EditLogto persist in-memory metadata
- EditLog
- file that records all changes to meta-data in HDFS
- stored as a file on local filesystem of primary NameNode
- FsImage
- snapshot of HDFS
- Namespace, block mapping information
\(\rightarrow\) both are stored as a file on local filesystem of primary NameNode
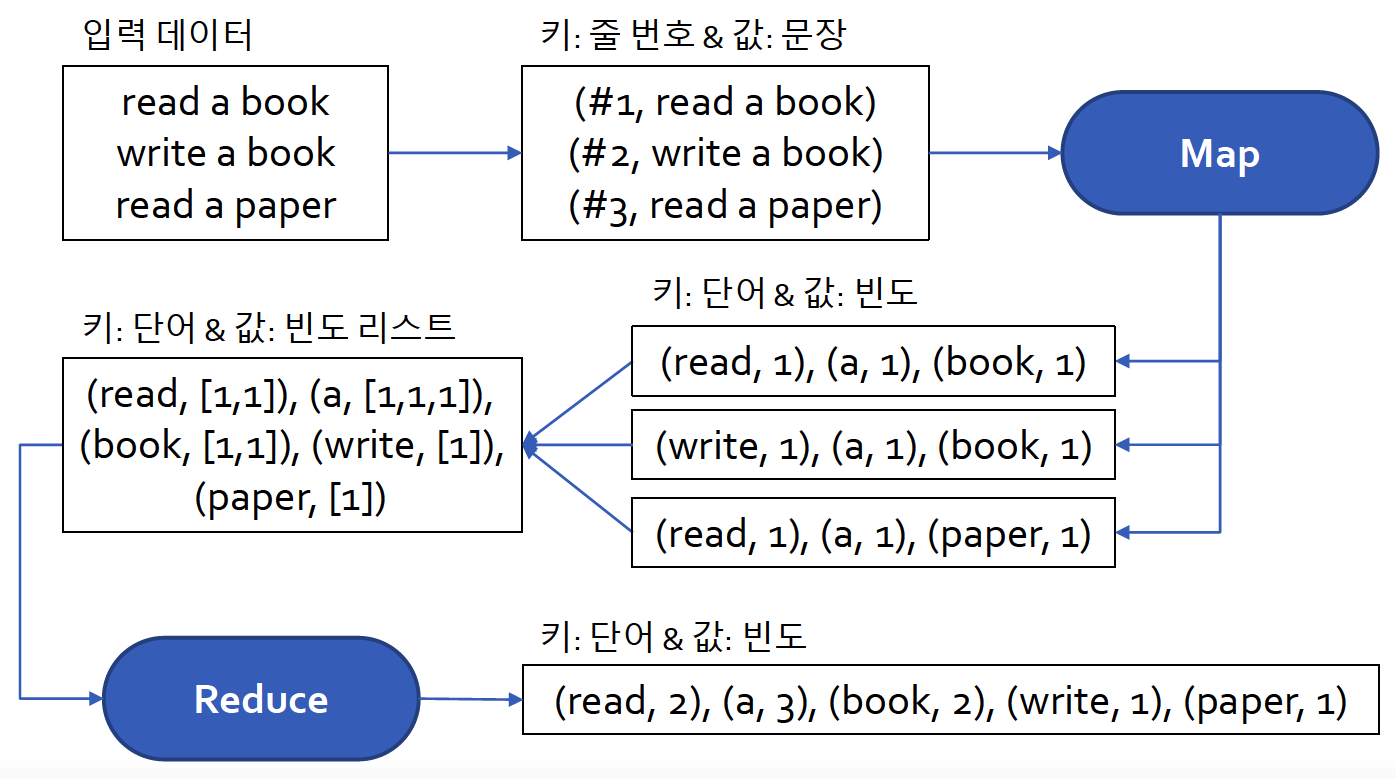
(9) MapReduce
- 대규모 분산 컴퓨팅, 혹은 단일 컴퓨팅 환경에서 대량의 데이터 분석을 병렬처리하기 위해!
- 2개의 메소드로 구성
- (1) 맵 (map)
- (2) 리듀스 (reduce)
- (1) 맵 (map)
- input : (key, value)로 구성된 리스트 1
- process : 정의된 프로세스를 처리함
- output : (key, value)로 구성된 리스트 2
- (2) 리듀스 (reduce)
- input : (key, value)로 구성된 리스트 2
- process : 집계 연산 수행
- output : (key, value)로 구성된 리스트 3
Examples :
(10) ACID theorems for RDBS
- Atomicity (원자성)
- 시스템에서 한 트랜잭션의 연산들이 모두 성공하거나, 반대로 전부 실패되는 성질
- 작업이 모두 반영되거나 모두 반영되지 않음으로서 결과를 예측할 수 있어야 한다
- Consistency (일관성)
- 하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야
- 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야
- Isolation (격리성, 고립성)
- 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다는 뜻
- 실제로 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜젝션은 고립(격리)되어 있어 연속으로 실행된 것과 동일한 결과를 나타낸다
- Durability (지속성)
- 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야하는 성질
- 런타임 오류나 시스템 오류가 발생하더라도, 해당 기록은 영구적이어야 한다는 뜻