
[Deep Bayes] TEST - Bayesian Reasoning
해당 내용은 https://deepbayes.ru/ (Deep Bayes 강의)를 듣고 정리한 내용이다.
Question 1. Frequentist Framework
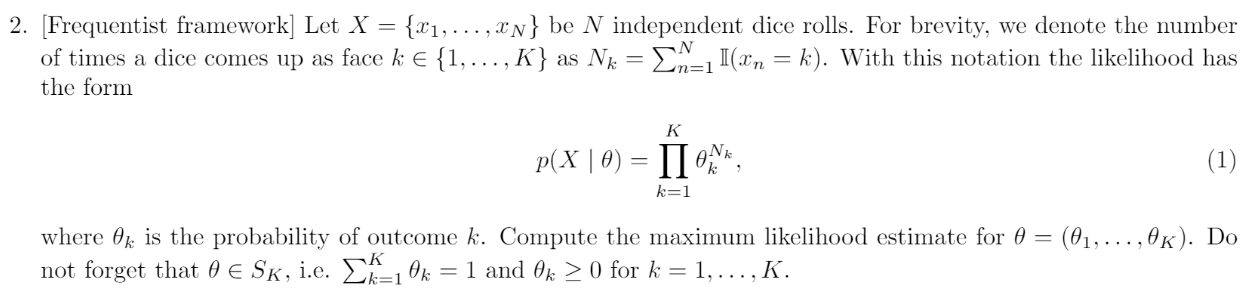
Answer
우리는 \(\theta_{ML} = \underset{\theta \in S_k}{argmax}\;logp(X\mid \theta)\) 에 대한 MLE를 구해야 한다.
그러기 위해 우선 다음과 같이 notation을 설정하자
- \(X = {x_1, ... x_N}\) : 독립적인 n번의 주사위 굴리기
- \(N_k = \sum_{n=1}^{N} (x_n = k)\) : 숫자 k가 나온 주사위 횟수
- \(p(X \mid \theta) = \prod_{k=1}^{K} \theta_k^{N_k}\) : multinomial likelihood
\(\theta_k\)를 다음과 같이 바꿔서 표현한 뒤, 라그랑즈 승수를 사용하여 풀면 다음과 같다.
\[\mu_k = log\;\theta_k\] \[\begin{align*} L(\mu,\lambda) &= log\;p(X\mid exp \mu)- \lambda(\sum_{k=1}^{K}exp\mu_k -1)\\ &= \sum_{k=1}^{K}(N_k \mu_k - \lambda\; exp \mu_k) + \lambda \end{align*}\]위 식을 각각 \(\mu_k\)와 \(\lambda\)에 대해 미분하여 0으로 만들면 , 우리는 다음과 같은 결과를 얻을 수 있다.
\[0 = \frac{\partial L(\mu, \lambda)}{\partial \mu_k} = N_k - \lambda \;exp\mu_k\] \[0 = \frac{\partial L(\mu, \lambda)}{\partial \lambda} = - \sum_{k=1}^{K}exp \mu_k +1\]따라서, \(\theta_k = \frac{N_k}{\sum_{l=1}^{K}N_l}\)이다.
Question 2. Bayesian Framework

Setting
- \(p(X \mid \theta) = \prod_{k=1}^{K}\theta_k^{N_k}\) ( multinomial likelihood )
- Dirichlet prior : \(Dir(\theta \mid \alpha) = \frac{1}{B(\alpha_1,...,\alpha_k)}\prod_{k=1}^{K}\theta_k^{\alpha_k-1}\)
(a) Check that likelihood & prior are “CONJUGATE”
우선, probablistic model \(p(X,\theta)\) 는 다음과 같이 쓸 수 있다.
\[p(X,\theta) = p(X\mid \theta)p(\theta) = Dir(\theta \mid \alpha) \prod_{k=1}^{K}p(x_k\mid \theta)\]문제에서 제시했듯, 우리의 prior는 Dirichlet Distribution을 따라서, 다음과 같이 나타낼 수 있다. ( \(\theta\) 와 관련 없는 부분들은 전부 C로 표현 )
prior : \(p(\theta) = \frac{1}{B(\alpha_1,...,\alpha_k)}\prod_{k=1}^{K}\theta_k^{\alpha_k-1} = C\prod_{k=1}^{K}\theta_k^{B}\)
또한, posterior \(p(\theta \mid X)\) 는 다음과 같이 표현할 수 있다.
\[p(\theta \mid X) \propto p(X\mid \theta)p(\theta) = \prod_{k=1}^{K}\theta_k^{N_K} \frac{1}{B(\alpha_1,...,\alpha_k)}\prod_{k=1}^{K}\theta_k^{\alpha_k-1} = C'\prod_{k=1}^{K}\theta_k^{B'}\]따라서, 우리는 \(p(\theta)\)와 \(p(\theta \mid X)\) 가 같은 모양을 띄기 때문에 서로 conjugate하다는 것을 알 수 있다.
(b) Compute the posterior \(p(\theta \mid X, \alpha)\)
\[p(\theta \mid X) \propto p(X\mid \theta)p(\theta) = \prod_{k=1}^{K}\theta_k^{N_K} \frac{1}{B(\alpha_1,...,\alpha_k)}\prod_{k=1}^{K}\theta_k^{\alpha_k-1} = \frac{1}{B(\alpha_1,...,\alpha_k)}\prod_{k=1}^{K}\theta_k^{N_k+\alpha_k-1}\]따라서, 다음과 같은 Dirichlet Distribution을 가짐을 알 수 있다.
(c) Compare \(E_{p(\theta\mid X,\alpha)}\theta\) and \(\theta_{ML}\)
Expectation of posterior ( \(E_{p(\theta\mid X,\alpha)}\theta\) ) 와, MLE ( \(\theta_{ML}\) )을 비교해보자.
우선, 앞선 문제에서 Frequentist Framework로 구한 MLE는 다음과 같았다.
\[\theta_k = \frac{N_k}{\sum_{l=1}^{K}N_l}\]그리고, Dirichlet Distribution의 Mean은 \(E[X_i] = \frac{\alpha_k}{\sum_{k=1}^{K}\alpha_k}\) 이므로, 우리가 위에서 구한 posterior의 expectation은 다음과 같다.
\(E_{p(\theta\mid X,\alpha)}\theta\) = \(\frac{\alpha_k + N_k}{\sum_{l=1}^{K}\alpha_l + N_l}\)
여기서 말하는 \(K\)는 x 데이터의 개수이다. 만약 우리가 작은 K를 가진다면, Bayesian 방법으로 구한 estimate는 주로 prior의 영향을 많이 받을 것이다. 반대로, 만약 우리가 큰 K를 가진다면, 이는 우리가 앞서 Frequentist 방법으로 구한 MLE ( \(\theta_k\) )와 매우 비슷할 것이다 ( 위 두 식을 비교해보면 알 수 있을 것이다. \(N_K\) 는 \(\alpha\) 보다 크기 때문이다 )