
4.LDA (Latent Dirichlet Allocation) Intro
1) Introduction
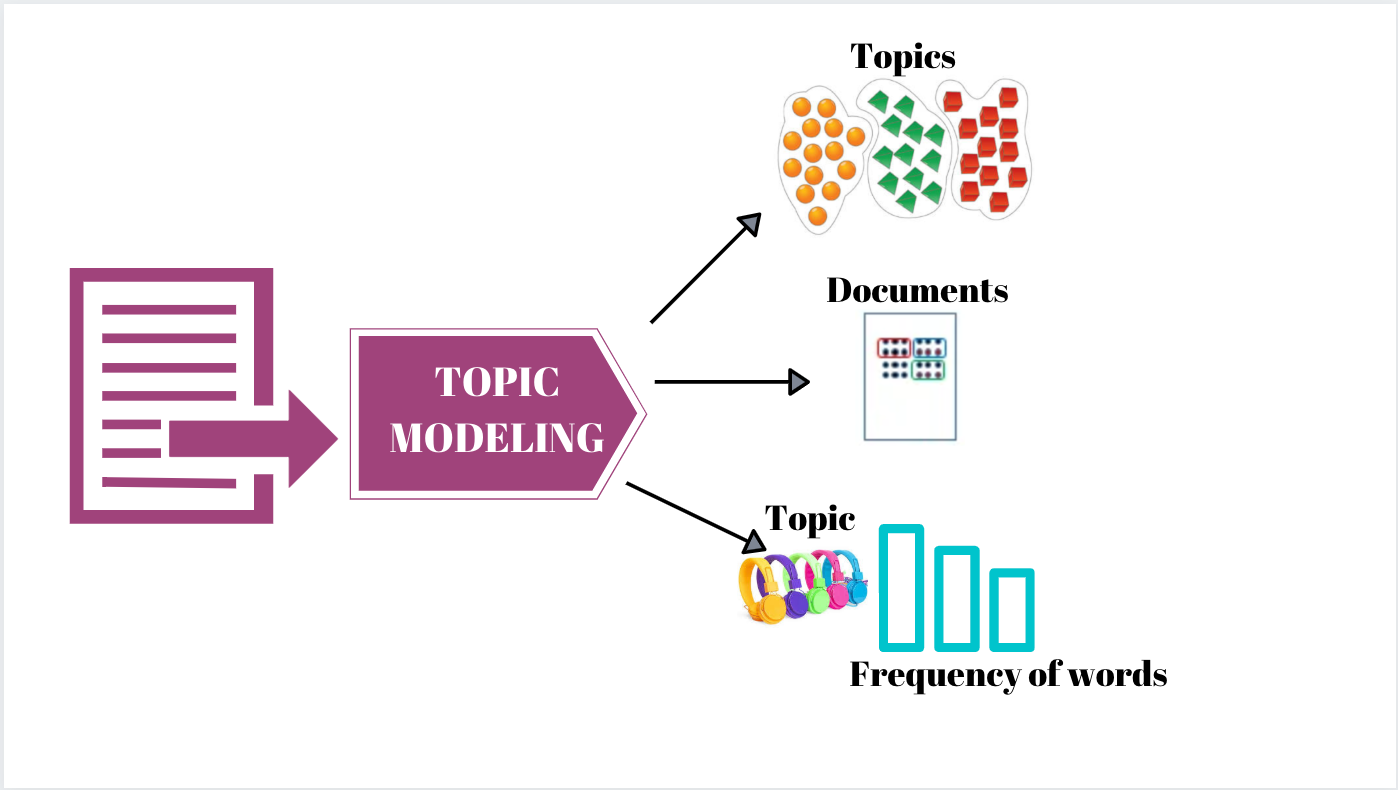
a. Topic Modeling
https://miro.medium.com/max/2796/1*jpytbqadO3FtdIyOjx2_yg.png
A topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents.
Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body. (wikipedia)
Topic modeling treats document as a ‘distribution’ of topics. For example, let’s take a famous book ‘The Adventures of Sherlock Homes’. We can say
that this book is composed of three topics, (60%)detective + (30%)adventure + (10%)horror. We can make this as a vector form like (0.6, 0.3, 0.1).
Then if an another book called “Sherlock Homes and his friends” has a vector form (0.5,0.2,0.3),
it means that this book is composed of (50%)detective + (20%)adventure + (30%)horror.
b. Similarity & Distance
After we have found the distribution of topic for some books or documnets (as a vector form), we can measure how those two books are similar or different in the aspect of topic.
The commonly used measures for similarity & distance are ‘Euclidean distance’ and ‘Cosine similarity’. I will not cover about them, as you might all know.
[ Euclidean Distance ]

[ Cosine Similarity ]
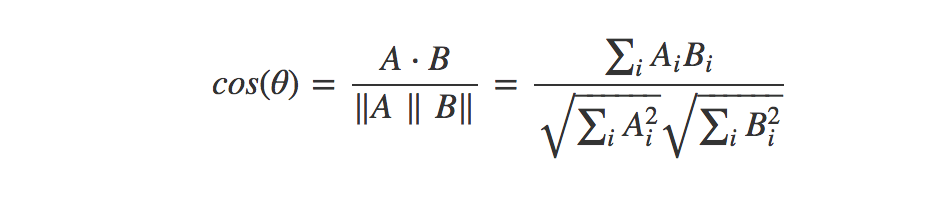
c. Dirichlet Distribution
[ Intro ]
It is a distribution over vector theta, and is parameterized by parameter alpha (which is also a vector). It has a form like this.
The constraints are as below
One easy way to interpert this is a traingle like below. (in the case of 3-dim vector )

https://miro.medium.com/max/1163/1*Pepqn_v-WZC9iJXtyA-tQQ.png
[ Statistics ]
-
Mean
where -
Covariance
-
note! when k=2, it is same as ‘beta distribution’
-
Dirichlet prior is a conjugate to the ‘multinomial likelihood’