
XTab: Cross-table Pretraining for Tabular Transformers
Zhu, Bingzhao, et al. "Xtab: Cross-table pretraining for tabular transformers." ICML (2023).
arxiv: https://proceedings.mlr.press/v202/zhu23k/zhu23k.pdf
Contents
- Introduction
- Related Work
- Tabular SSL
- Tabular transformers
- Cross-table transfer learning
- Methods
- Model Structure
- Federated Pretraining
Abstract
Limitation of existing works on SSL with tabular data
- (1) Fail to leverage information across multiple data tables
- (2) Cannot generalize to new tables
XTab
Framework for cross-table pretraining of tabular transformers
- Goal? Address the challenge of “inconsistent column types” and quantities among tables
- How? By utilizing “independent featurizers” and using “federated learning” to pretrain the shared component
Experiments
- Tasks: 84 tabular prediction tasks from the OpenML-AutoML Benchmark (AMLB)
- Results
- Consistently boosts the generalizability, learning speed, and performance of multiple tabular transformers
- Achieve superior performance than other SoTA Tabular DL
1. Introduction
Primary challenge of tabular DL?
\(\rightarrow\) Diversity of tabular tasks (i.e., Vary in the number and types of columns)
\(\rightarrow\) Makes it difficult for tabular DL models on transfer learning
\(\rightarrow\) Lead to poor generalization abilities
Existing SSL on Tabular DL = DATA-SPECIFIC
- Generally pretrain the tabular model on data from the “SAME domain as the downstream taskresult, the data-specific
- Cannot generalize to new tables
Tabular DL with Transformers
-
Consider the columns as tokens ( = words in NLP )
-
Thus, can process tables with variable numbers of columns
\(\rightarrow\) Enable transfer learning
Proposal: XTab
General framework for “cross-table pretraining” of tabular transformers
- a) Problem: Tables may vary in the number and types of columns
- b) Solution: Decomposed the tabular transformers to two components:
- (1) Data-specific featurization & Projection layers: Capture the characteristics of each table
- (2) Cross-table-shared block: Stores the common knowledge
- c) Dataset: Diverse collection of data tables
- d) Pretraining: via Federated learning
Contribution
-
Offers a framework to account for cross-table variations & enable cross-table knowledge transfer.
-
Pretrain on tabular datasets with federated learning
\(\rightarrow\) Enables distributed pretraining across a large collection of tables
-
Show that cross-table pretraining can boost the learning speed and performance on new tables
2. Related Work
(1) Tabular SSL
Categories
-
a) Reconstruction task
( Yoon et al. (2020); Ucar et al. (2021) )
- Auto-encoder framework
- Reconstruct the missing part of a table
-
b) Contrastive learning
( Bahri et al. (2021) )
- Extended the SimCLR framework to tabular task
-
c) Target-aware objectives
- Rubachev et al. (2022); Wang & Sun (2022): Incorporated the label columns of tabular tasks in pretraining
Limitation of a),b),c):
- Only pretrain on one table \(\rightarrow\) Lacks generalizability
- XTab: Pretrain on a large number of tables
(2) Tabular transformers
FT-Transformer
- Transformer for tabular classification/regression tasks
Saint
- Row-wise attention (= Captures the inter-sample interactions )
Fastformer
-
Additive attention on tabular tasks
( = Lightweight attention mechanism with linear complexity )
TransTab
- Features transfer learning in tabular tasks using transformers
- Also supports the cross-table transfer
TransTab vs. XTab
- TransTab: Limited ability in generalizing to tables from “NEW” domains
(3) Cross-table transfer learning
XTab: (Unlike pretrained models in NLP…)
-
Does NOT attempt to learn a universal tokenizer for all tables
( \(\because\) Context of each table varies )
-
Aim to learn a weight initialization that is generalizable to various downstream tasks
(Concurrent work) TabPFN
- Learns a prior model on synthetic tabular data
- Promising results on small numerical tabular classification tasks with ≤1000 samples
TabPFN vs. XTab
-
Inference complexity of XTab is irrelevant to the number of training samples
\(\rightarrow\) \(\therefore\) XTab also works for large tables!
3. Methods
Aims to learn the shareable knowledge that can boost the performance for
various downstream regression and classification tasks.
(1) Model Structure
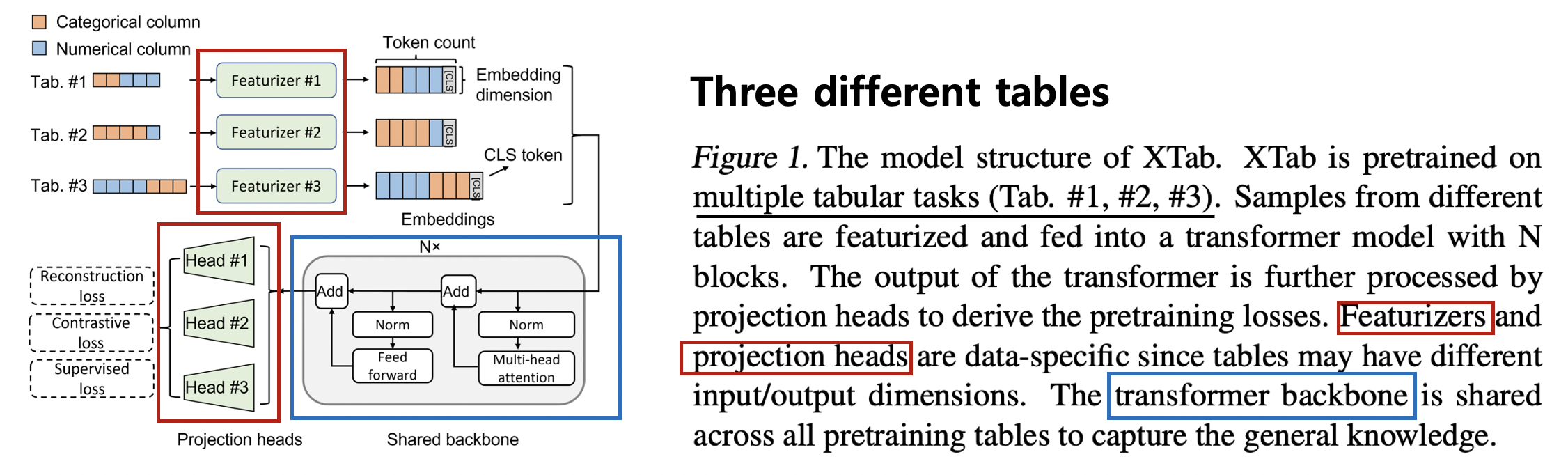
Pretraining phase
Step 1) Sampling
- Sample mini-batches of rows from different tables (one batch per table)
Step 2) Token Embedding
- Featurizers are data-specific and convert each column of the table to a token embedding
- Additional [CLS] token is appended
- For supervised prediction or CL
Step 3) Transformer
- Shared across all tabular datasets to process token embeddings
Step 4) Projection Head
- (Pretraining loss 1) Reconstruction loss (label X)
- Reconstruct the original table from a corrupted view
- (Pretraining loss 2) Contrastive loss (label X)
- Identify the positive/negative pairs of samples as in contrastive learning
- (Pretraining loss 3) Supervised loss (label O)
- Predict the values in the label column predefined by each table.
- Uses label \(\rightarrow\) referred to as “Target-aware pretraining / Pre-finetuning”
Key challenge in cross-table pretraining = Variations of input tables
Components of XTab
- (1) For data-specific information (green blocks in Figure 1)
- a) Featurizers
- b) Projection head
- (2) For common knowledge (grey blocks in Figure 1)
- c) Transformer
Freeze & Initialization
-
Only a shared backbone (=Transformer) is kept for all downstream tasks
- For each downstream task, featurizers and projection heads are randomly initialized
- Entire model is finetuned on the downstream training data until a stopping criterion is met.
a) Featurizers
Featurizer = Data-specific to handle various types and numbers of columns
Goal: Convert a sample to feature embeddings \(E \in \mathbb{R}^{c \times d}\)
- \(c\): Number of columns
- \(d\): Embedding dimension
Row & Column
- Each row = input sample
- Each column = token
[CLS] token
- Appended to the feature embedding for prediction stack
- \([E, \texttt{[CLS]}] \in \mathbb{R}^{(c+1) \times d}\).
Columns
-
(1) Numerical
- Multiply the numerical value ( \(x_k\) ) at the ( k )-th column with a trainable vector ( \(W_k \in \mathbb{R}^d\) ) and add a bias term ( \(b_k\) ).
-
(2) Categorical
( Text cells are treated as categorical attributes )
- Learns an embedding matrix ( \(\in \mathbb{R}^{N_{\mathrm{cat}} \times d}\) ) as a lookup table
- \(N_{\mathrm{cat}}\): Total number of categories of the dataset
- Learns an embedding matrix ( \(\in \mathbb{R}^{N_{\mathrm{cat}} \times d}\) ) as a lookup table
-
Allows tables to have different numbers of columns and arbitrary column types
b) Backbones
Shared backbone = Transformer
- Can handle input sequences with vari-
- \(\therefore\) Possible to pretrain a tabular transformer that can be applied to multiple tabular datasets
Three backbone variants
- (1) Feature Tokenizer Transformer (FT-Transformer)
- (2) Fastfromer
- (3) Saint-v
(1) Feature Tokenizer Transformer (FT-Transformer)
- Simple yet well-performing transformer model for tabular prediction tasks
- Component MHSA + FFN
- Beat other DL methods on tabular data
(2) Fastfromer
-
Efficient transformer architecture which uses additive attention in place of MHSA
-
Only considers the interaction between each token and the global representation
\(\rightarrow\) Achieve a linear complexity
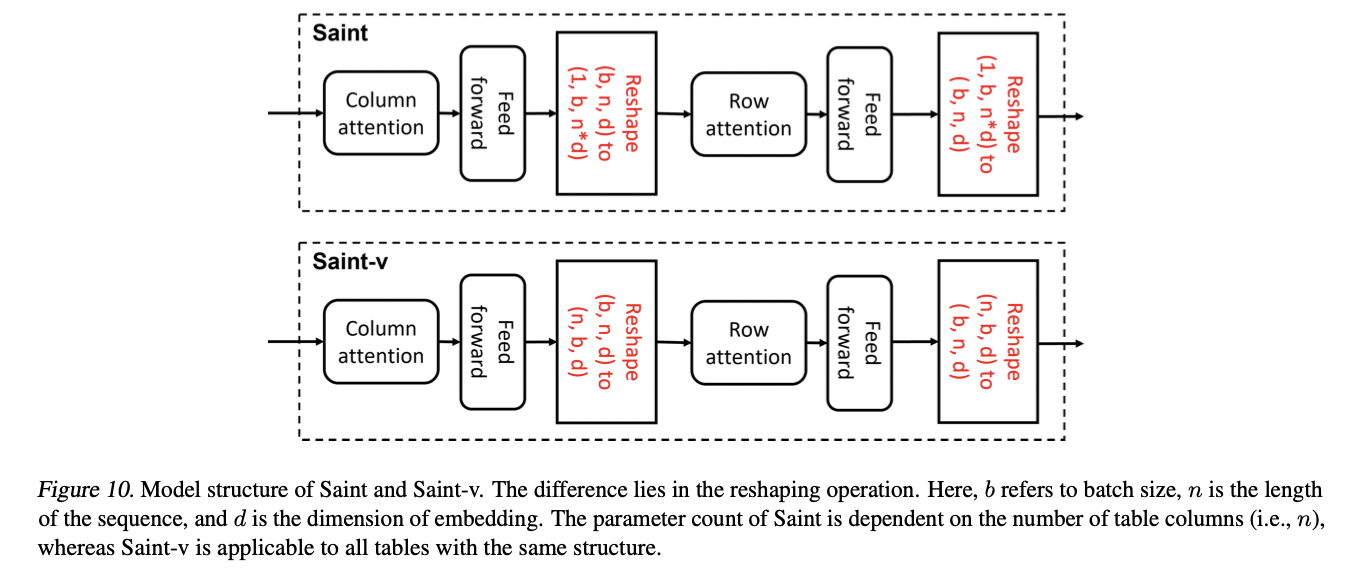
(3) Saint-v
- Row-wise attention (in addition to the column-wise attention of previous works)
- (Naive) Saint: Sensitive to the sequence length & Cann not handle variable-column tables
- Variation of Saint (Saint-v): Fit into cross-table pretraining setting
- Consists of both column- and row-wise attention blocks, and the detailed
c) Projection heads & Objectives
Various pretraining objectives for tabular predic-
- (1) Reconstruction
- (2) Contrastive learning
- (3) Pre-finetuning (feat. Supervised loss)
(1) Reconstruction loss
- Recover the original sample ( \(x\) ) from a corrupted view of the sample ( \(\tilde{x}\) )
- Takes the representation of ( \(\tilde{x}\) ) as input
- Generates an estimate of the original input ( \(\hat{x}\) )
- Loss:
- CE loss: For categorical columns
- MSE loss: For numerical columns
(2) Contrastive loss
-
Generate ( \(\tilde{x}\) ) as a corrupted sample
-
(\(x,\tilde{x}\)) = Positive pair of samples
( otherwise negative )
-
Loss: InfoNCE
(3) Supervised loss
- Directly pretrain a model using the supervised objective
- Predict the values under a certain field (or column), as predefined by each dataset
- Include regression and classification.
Diversity of pretraining objectives
\(\rightarrow\) Ensures that the shared backbone is widely adaptable to various downstream tables!
(2) Federated Pretraining
During pretraining, both the time and space complexity increase linearly as we include more tabular datasets
\(\rightarrow\) \(\therefore\) Fit XTab into the federated learning framework
Results
- Involves only marginal overhead in wall-clock time with more pretraining tasks
- Makes it feasible to pretrain XTab on a cluster of commercially available GPUs