
MOMENT: A Family of Open Time-series Foundation Models
Contents
- Abstract
- Introduction
- Related Works
- Methodology
- The Time Series Pile
- Model Architecture
- Pre-training using MTM
- Fine-tuning on Downstream Tasks
- Experimental Setup and Results
- Design choices
- RQ1: Effectiveness
- RQ2: Interpretability
- RQ3: Properties
Abstract
MOMENT = a family of open-source foundation models for general-purpose TS analysis
Challenges of pre-training LM on TS:
- (a) Absence of a large and cohesive public TS repository,
- (b) Diverse time series characteristics
- (c) Experimental benchmarks to evaluate these models are still in their nascent stages.
Solution
- (a) Dataset: Time Series Pile
- Large and diverse collection of public TS
- (b) Tackle TS-specific challenges to unlock large-scale multi-dataset pretraining
- (c) Build on recent work to design a benchmark to evaluate TS foundation models on diverse tasks and datasets in limited supervision settings.
https://huggingface.co/AutonLab.
- Pre-trained models (AutonLab/MOMENT-1-large)
- Time Series Pile (AutonLab/Timeseries-PILE)
1. Introduction
MOMENT
- The first family of open-source large pre-trained TS models
- Family of high-capacity transformer models
- Pre-trained using a MTM on TS data from diverse domains
Models in MOMENT
- (1) serve as a building block for diverse TS analysis tasks
- e.g., forecasting, classification, anomaly detection, and imputation, etc.
- (2) Effective out-of-the-box
- i.e., with no (or few) particular task-specific exemplars (enabling e.g., zero-shot forecasting, few-shot classification, etc.)
- (3) Tunable using indistribution and task-specific data to improve performance.
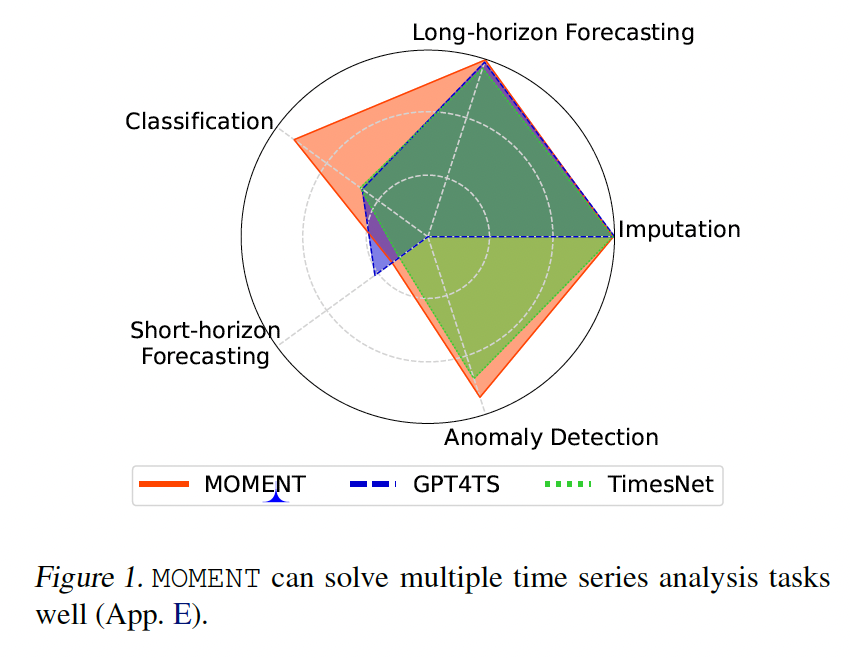
Key contributions
- (1) Pre-training data: Time series Pile
- (2) Multi-dataset pre-training : vary in characteristics
- (3) Evaluation: multi-task TS modeling benchmark along multiple dimensions
- 5 tasks: short- and long-horizon forecasting, classification, anomaly detection, and imputation
2. Related Works
(1) Transformers & Patching for TS
- pass
(2) Masked Representation Learning
- pass
(3) Cross-modal Transfer Learning using LLM
Lu et al. (2022)
- LLMs can effectively solve sequence modeling tasks in other modalities.
ORCA (Shen et al. (2023))
- a general cross-modal fine-tuning framework that extends the applicability of a single largescale pretrained model to diverse modalities by adapting to a target task via an align-then-refine workflow.
-
Step 1) Learns an embedding network that aligns the embedded feature distribution with the pretraining
- Step 2) Fine-tune on the embedded data
- exploiting the knowledge shared across modalities.
Reprogramming (Zhou et al., 2023; Gruver et al., 2023; Jin et al., 2023; Cao et al., 2023; Ekambaram et al., 2024)
- “reprogram” LLMs for TS analysis
-
using parameter efficient fine-tuning and suitable tokenization strategies
- (limitation of some) billions of parameters demand significant memory and computational resources
Three empirical observations
- (1) Transformers trained on TS can also model sequences across modalities
- (2) During pre-training, randomly initializing weights lead to lower pre-training loss, than initializing with LLM weights
- (3) Models pre-trained on TS outperform LLM-based models
(4) Unanswered Questions.
Two questions remain largely unanswered in prior work
-
(1) All existing TS models are (pre-)trained and fine-tuned on individual datasets
\(\rightarrow\) Benefits of large-scale multi-dataset pre-training remains unexplored
-
(2) Very limited work on TS modeling in limited supervision settings
- e.g. zero-shot forecasting or few-shot classification
MOMENT: consider both these questions
3. Methodology
Step 1) Collect public TS data into the Time Series Pile
Step 2) Use it to pre-train a transformer on the MTM
(1) The Time Series Pile
Collate multiple TS from 4 task specific, widely-used public repositories
-
Diverse domains, and TS characteristics
( e.g. lengths, amplitudes, and temporal resolutions )
Time Series Pile = (a) + (b) + (c) + (d)
- (a) LTSF 9 benchmarks (ETTh,ETTm,Weather,Traffic…)
- (b) Monash TS forecasting archive
- 58 short-horizon, over 100k TS, divers domain & temporal resolutions
- (c) UCR/UEA archive
- 159 TS datasets for classification
- vary in # of classes & # of TS
- (d) TSB-UAD anomaly benchmark
- 18 anomaly detection datasets
- 1980 Univariate tS with labeled anomalies
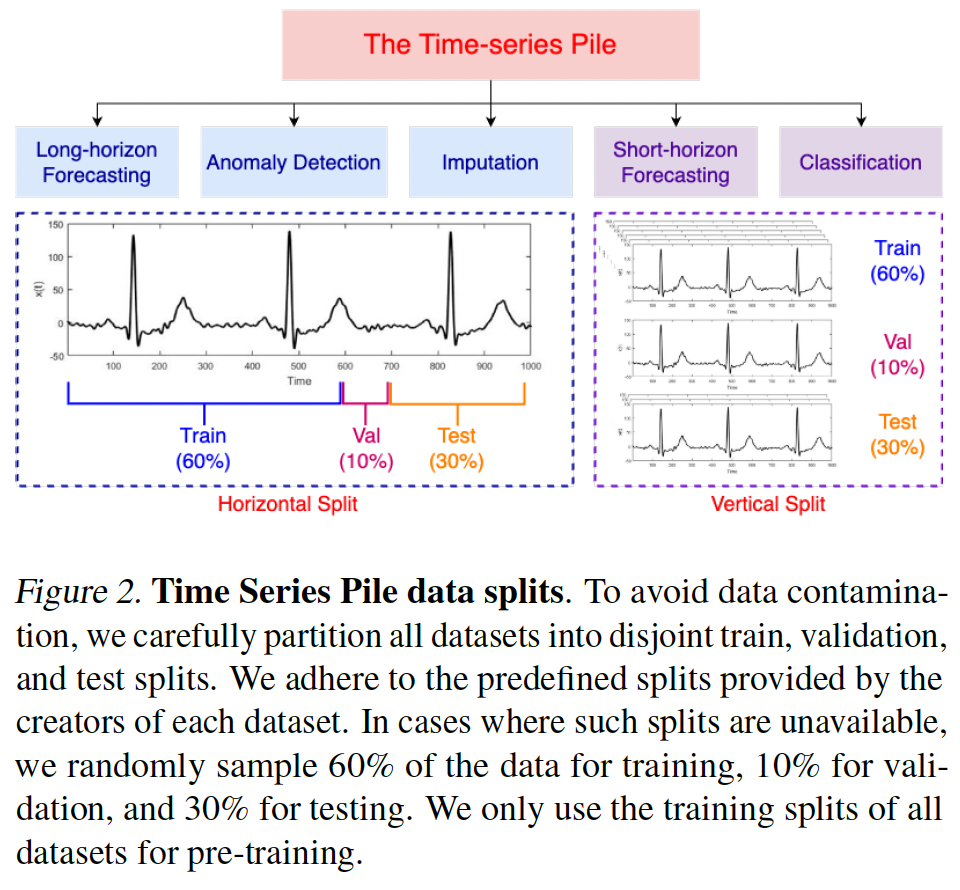
Minimizing data contamination using careful train-test splitting
- Split each dataset into disjoint training, validation, and test splits,
- If not split specified by data creators, random sample
- train 60% + valid 10% + test 305
- (a) & (d) datasets: long TS
- split horizontally
- (b) & (c) datasets: short TS
- contain multiple short TS
- complete TS is either training, validation, or testing.
- random seed = 13
(2) Model Architecture
a) Overview
Notation
-
Univariate time series \(\mathcal{T} \in \mathbb{R}^{1 \times T}\),
-
Mask \(M=\{0,1\}^{1 \times T}\) of length \(T\)
- 0 = unobserved, 1 = observed
-
Patching:
-
\(N\) disjoint patches & length \(P\)
- RevIN is applied to the observed TS before patching
- Patch is mapped to a \(D\)-dim
-
-
Designated learnable mask embedding [MASK] \(\in \mathbb{R}^{1 \times D}\)
Reconstrution
- Reconstruct both masked and unmasked patches
- Reconstruction head = lightweight prediction head

b) Handling varying TS characteristics
b-1) Restricting MOMENT’s input to a univariate TS of a fixed length \(T = 512\)
- longer sample: sub-sample
- shorter sample: left zero-padding
b-2) Patching
- quadratically reduces MOMENT’s memory footprint and computational complexity
- linearly increases the length of TS it can take as input.
b-3) Channel Independence
- handle MTS by independently operating on each channel along the batch dimension.
- have also found that modeling each channel independently is an effective strategy for modeling MTS
b-4) RevIN
- enables MOMENT to model TS with significantly different temporal distributions
b-5) Do not explicitly model the temporal resolution of TS
- ( \(\because\) this information is often unavailable outside of TS forecasting datasets )
c) Intentionally simple encoder
-
Closely following the design of transformers in the language domain
-
leverage their scalable and efficient implementations
(e.g., gradient checkpointing, mixed precision training).
d) Light-weight prediction head
( instead of decoder )
- to enable the necessary architectural modifications for task-specific fine-tuning of a limited number of trainable parameters
(3) Pre-training using MTM
a) Procedure
Step 1) Patchify
Step 2) Masking
- uniformly at random
- replace their patch embeddings with a learnable mask embedding [MASK].
Step 3) Feed to encoder
Step 4) Reconstruction using a lightweight reconstruction head
- loss function; MSE
b) Pre-training Setup.
T5-Small/Base/Large
- layers: 6/12/24
- \(D\): 512/768/1024
- # of att heads: 8/12/16
- FFNN: 2048/3072/4096
- # of params (billions): 40/125/385
Etc
- Weight = randomly initialized
- Input ts \(T=512\)
- breaking it into \(N = 64\) disjoint patches of length \(P = 8\)
- Masking ratio: 30%
(4) Fine-tuning on Downstream Tasks
a) Overview
Can be used for multiple TS tasks
5 practical TS analysis tasks
- long- and short horizon forecasting
- classification
- anomaly detection
- imputation
Forecasting tasks ( with horizon \(H\) )
- Replace the reconstruction head with a forecasting head
- step 1) Flattens all the \(N\) patches of \(D\)-dim \(\rightarrow\) \(N\times D\) dim vector
- step 2) Projects it into a \(H\)-dim TS
Other tasks
- Retain the reconstruction head
b) Fine-tuning settings
Three settings
- (1) fine-tuned end-to-end
- (2) linear probed
- (3) zero-shot (for some tasks)
- i.e. anomaly detection, unsupervised representation learning and imputation,
4. Experimental Setup and Results
(1) Design choices
Extend the experimental benchmark introduced by Wu et al. (2023) across various dimensions.
a) TS modeling with limited supervision.
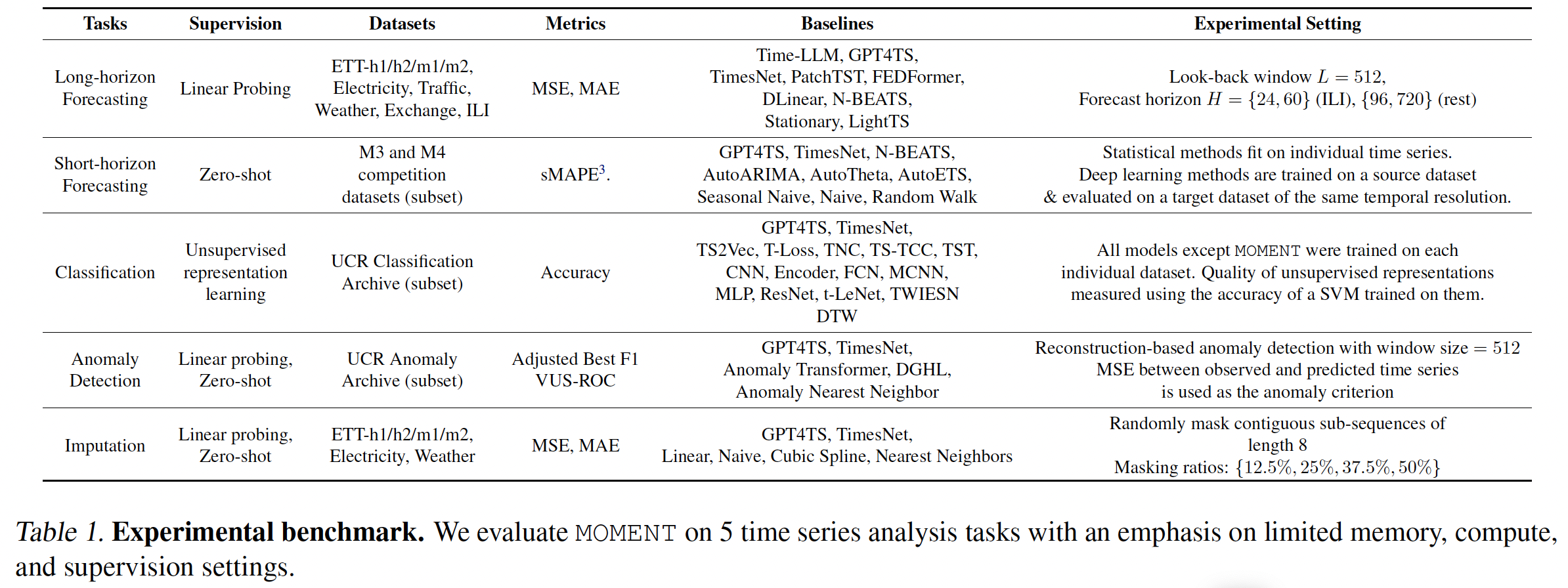
In contrast to TimesNet …
-
Exclusively consider scenarios with limited compute and supervision resources
( to mimic practical situations! )
-
Assess MOMENT in
- (whenever feasible) zero-shot settings
- (if not) Linear probing for a few epochs
Classification
- Consider the unsupervised representation learning problem (SSL)
- (prior works) measured using the accuracy of SVM
Short-horizon forecasting
-
consider the zero-shot setting (by Oreshkin et al. (2021))
- finetune MOMENT on a source dataset
- evaluate its performance on a target dataset “without any
fine-tuning”
b) Datasets
(foreccasting & imputation)
- same as TimesNet
(classification and anomaly detection)
- larger & systematically chosen subset of datasets from
- UCR classification archive (Dau et al., 2018)
- UCR anomaly archive (Wu & Keogh, 2023)
- classification)
- With 91 TS datasets with each TS shorter than 512 time steps (Tab.23)
- amomaly detection)
- while choosing the subset of TS, we prioritized coverage over different domains and data sources
c) Metrics
Multiple metrics used in task-specific benchmarks
-
(long-horizon forecasting) MSE, MAE
-
(short-horizon forecasting) sMAPE
-
(anomaly detection) adjusted best F1-score, VUS-ROC
-
TimesNet & GPT4TS: vanilla F1 score
\(\rightarrow\) Ignores the sequential nature of TS
-
d) Baselines
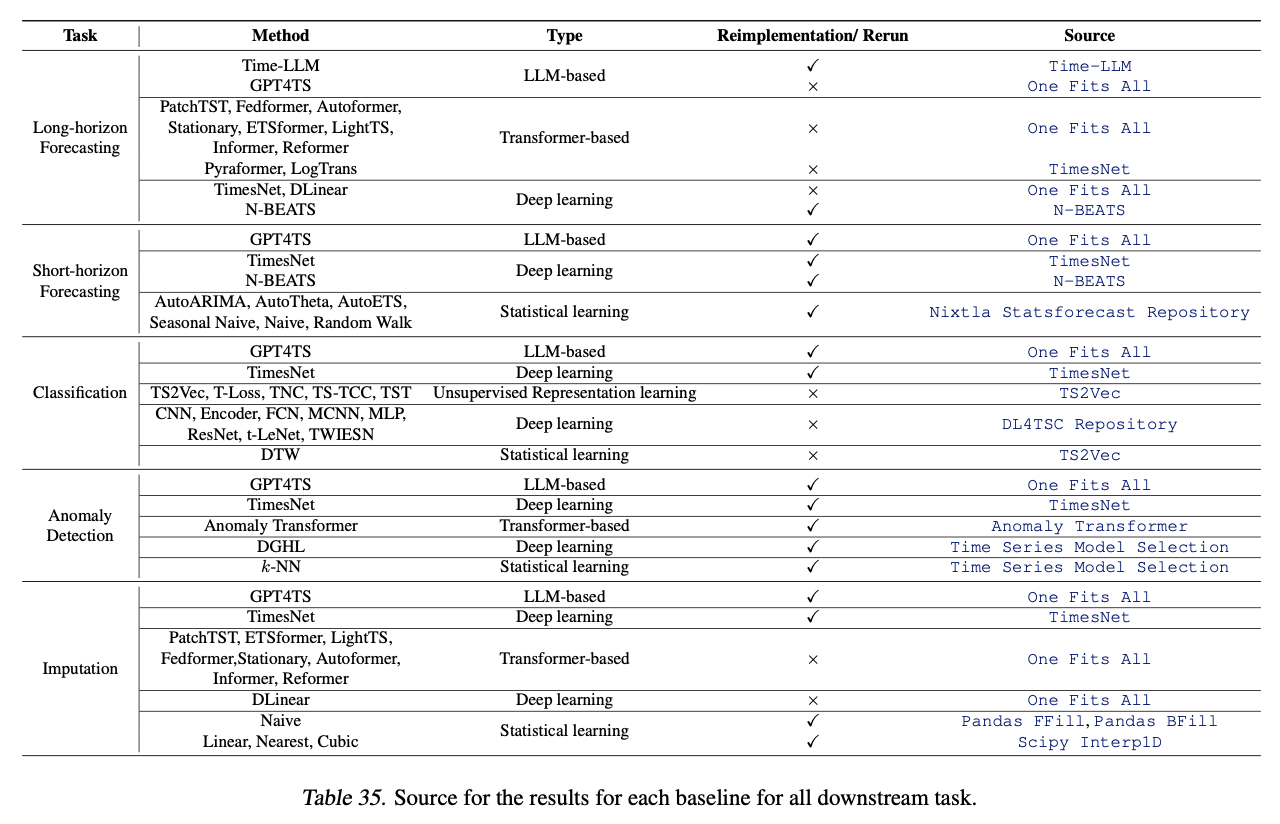
e) Hyperparameter Tuning
Do not perform hyper- parameter tuning
- (unless mentioned) fine-tune MOMENT-Large with a batch size of 64
- one cycle learning rate schedule with a peak learning rate between 5e −5 and 1e − 3
f) Research Questions
- RQ1: Effectiveness
- Is MOMENT effective for multiple tasks in limited supervision settings?
- RQ2: Interpretability
- What is MOMENT learning?
- Does it capture intuitive time series characteristics such as varying frequencies, trends, and amplitudes?
- RQ3: Properties
- What is the impact of the size of scaling model size?
- Can MOMENT, akin to LLMs, be used for cross-modal transfer learning?
(2) RQ1: Effectiveness
a) Long-horizon forecasting
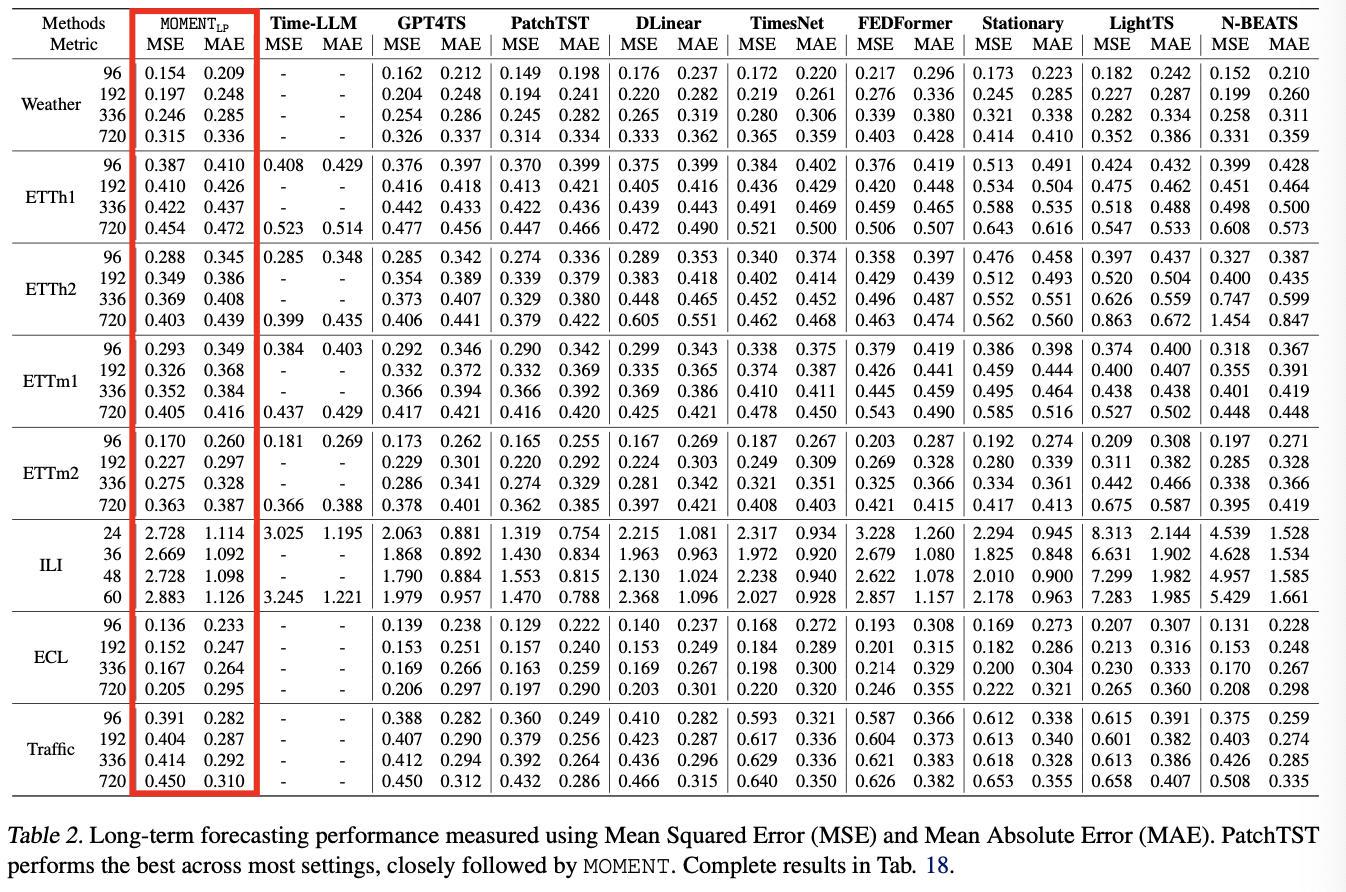
- Linearly probing MOMENT achieves near SOTA
- Second to PatchTST
- Models based on LLMs
- perform worse than MOMENT
- N- BEATS outperforms several recent methods
- emphasizing the importance of comparing forecasting performance beyond transformer-based approaches.
b) Zero-shot short-horizon forecasting.
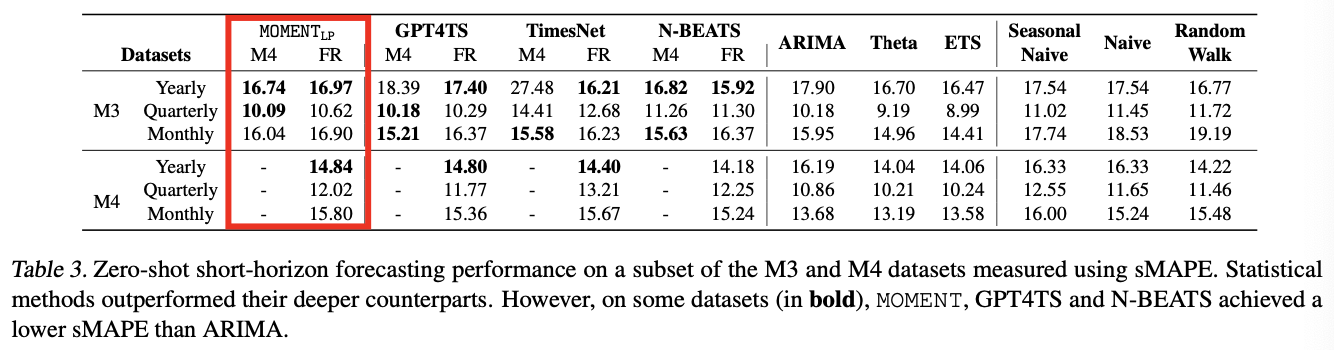
- Zero-shot short-horizon forecasting to have the largest scope for improvement
c) Classification

Representation learning
- Without any data-specific fine-tuning!
- Learn distinct representations for different classes

- GPT4TS and TimesNet : perform poorly
- despite being trained on each individual dataset with labels!!
d) Anomaly detection.
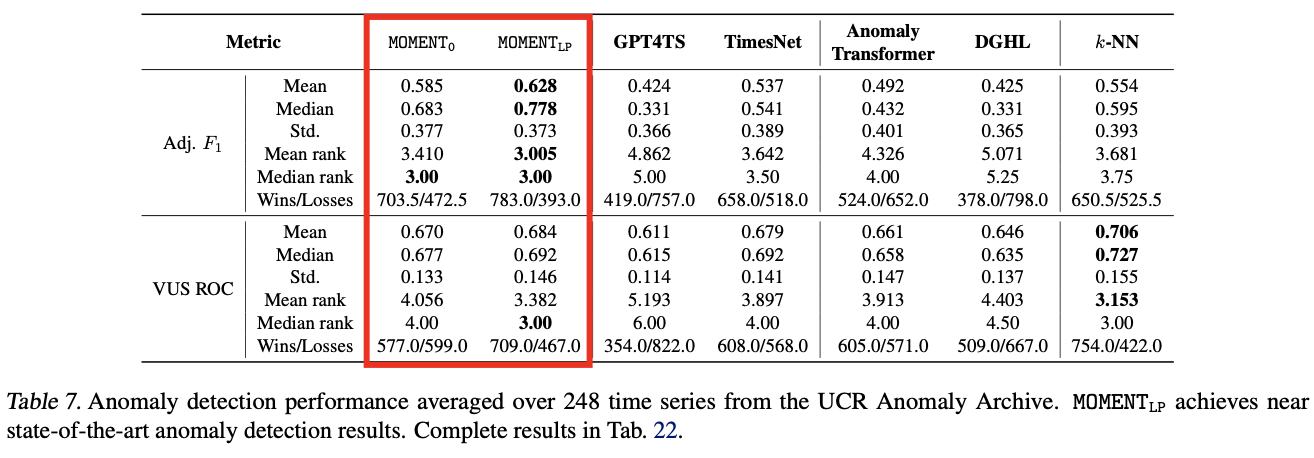
-
consistently outperforms both TimesNet and GPT4TS
( + 2 SOTA models tailored for anomaly detection )
in both zero-shot and linear probing configurations
e) Imputation.
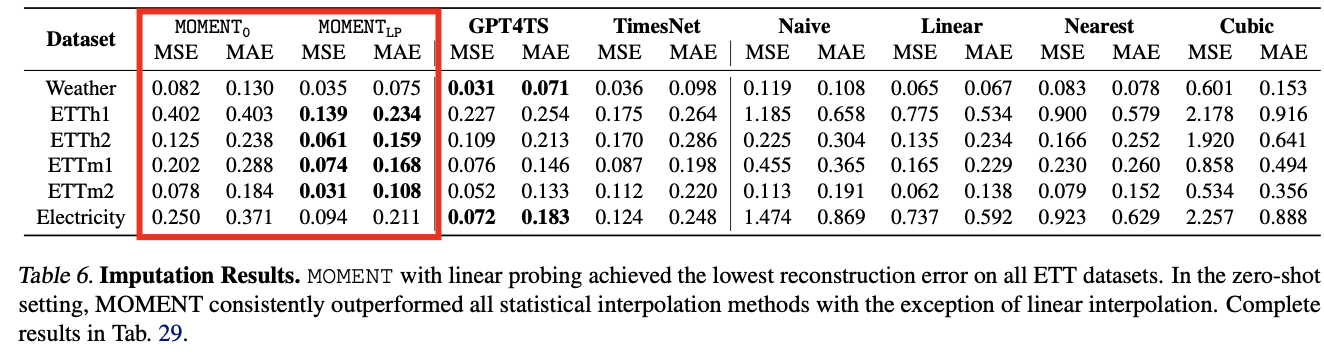
- Averaged over 4 different masking rates.
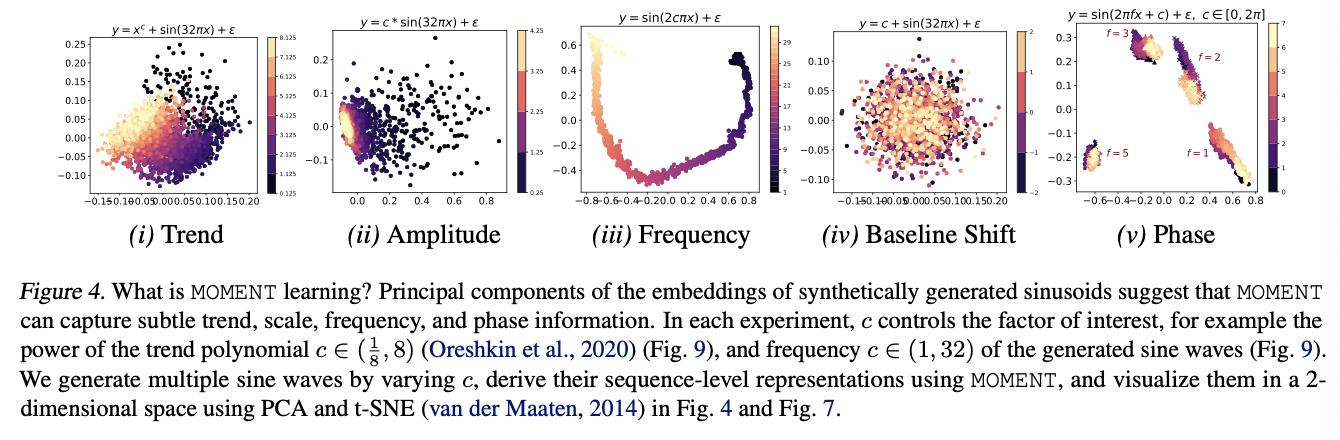
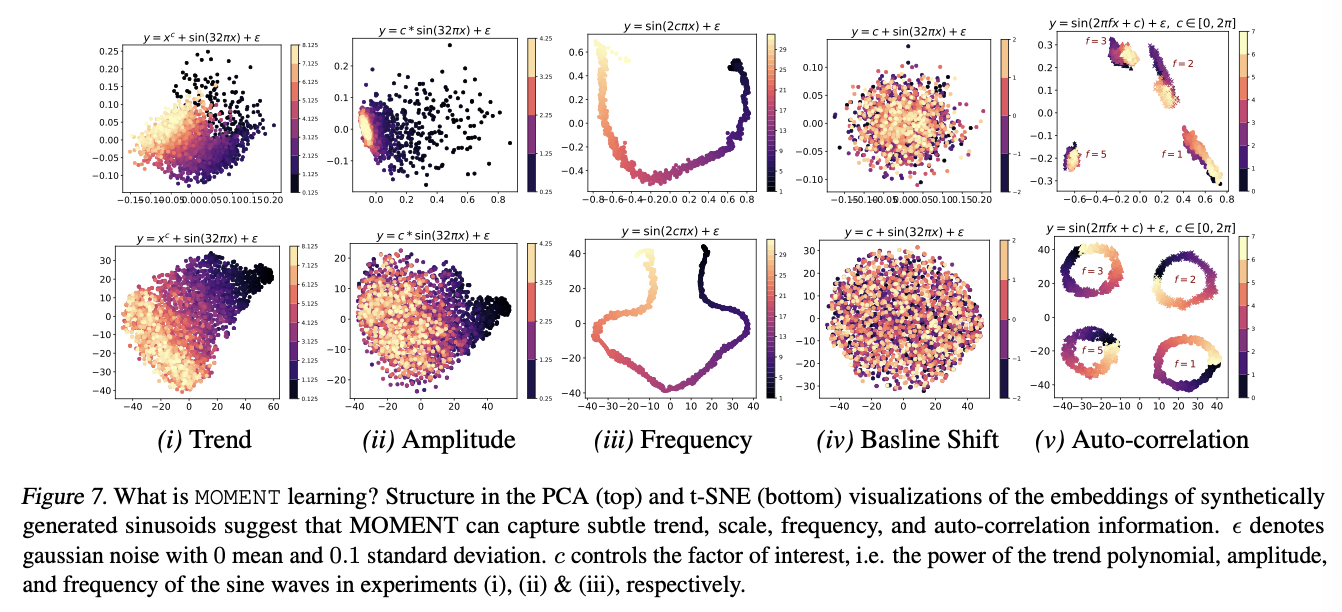
(3) RQ2: Interpretability
MOMENT can capture changes in …
- trend, amplitude, frequencies, and phases
However, it cannot differentiate between vertically shifted TS
( \(\because\) it normalizes each signal prior to modeling )
(4) RQ3: Properties
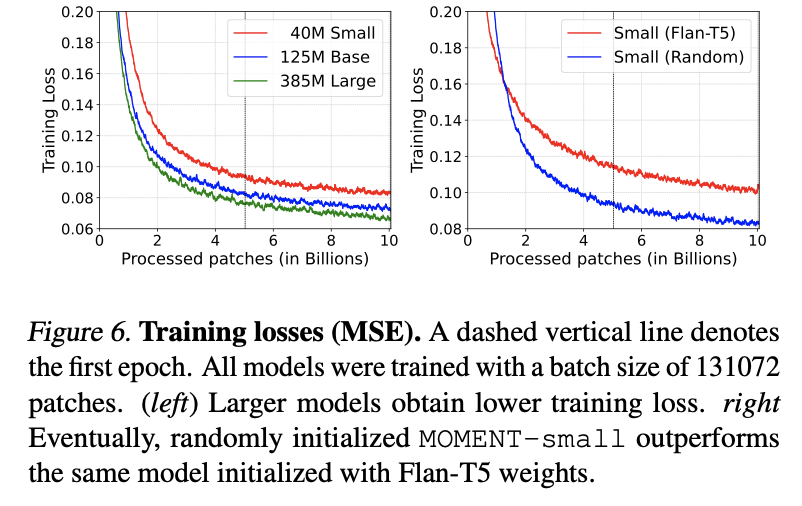
a) Model scaling improves training loss [Fig 6 left]
Increasing the size of the model \(\rightarrow\) Lower training loss
b) MOMENT can solve cross-modal sequence learning tasks
We explore whether transformers pre-trained on TS
can also be used to solve sequence classification tasks on image, text, and binary data
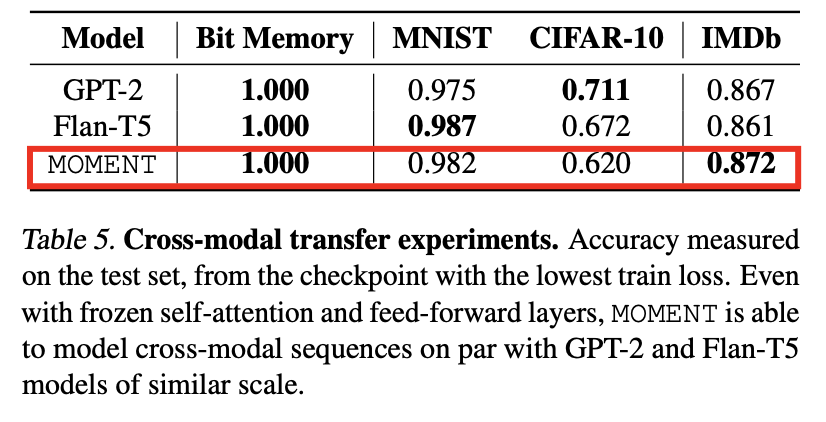
-
by freezing the self-attention and feed-forward layers,
MOMENT can model sequences comparable to GPT-2 and Flan-T5 models of similar scale
c) MOMENT with randomly initialized weights converges to a lower training loss
(With sufficient data)
Pretraining from scratch > Pretraining from LLM weight
\(\rightarrow\) underscores that there is sufficient publicly accessible pre-training data available in the Time Series Pile to facilitate pre-training time series foundation models from scratch