Timer: Transformers for Time Series Analysis at Scale
Contents
- Abstract
- Introduction
- Related Works
- Approach
- Data
- Training Strategy
- Model Design
- Experiments
- TS Forecasting
- Imputation
- Anomaly Detection
- Scalability
- Analysis
0. Abstract
Large time series models (LTSM)
- To change the current practices of training small models on specific datasets from scratch!
- (Pretraining) Dataset
- Curate large-scale datasets with up to 1 billion time points
- Unify heterogeneous TS into single-series sequence (S3) format
- Model: GPT-style architecture to-ward LTSMs.
- Task: Convert various tasks into unified “generative task”
- forecasting, imputation, and anomaly detection
Result: Time Series Transformer (Timer)
- Pretrained by autoregressive next token prediction on large multi-domain datasets
- Fine-tuned to downstream scenarios
1. Introduction
Accuracy deteriorate drastically in scenarios with limited data!
LLM
- Training on large-scale text corpora
- Remarkable few-shot and zero-shot abilities
\(\rightarrow\) Motivate to develop large time series models (LTSM) on numerous unlabeled series data
( + transfer to various downstream tasks )
Generative pre-training (GPT)
Several essential abilities that are not present in small models
- (1) Generalization ability:
- that one model fits all domains
- (2) Task generality:
- that one model copes with various tasks
- (3) Scalability:
- that the performance in- creases with the scale of parameters and pre-trained data.
Existing research has not addressed several fundamental issues for developing LTSMs.
- When is the benefit of LTSMs warranted?
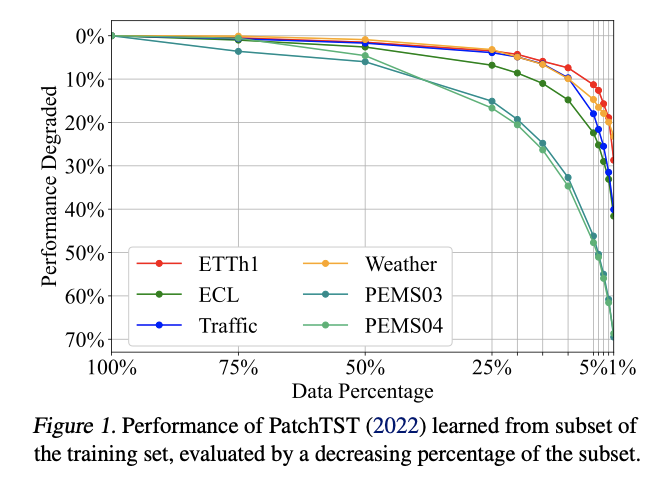
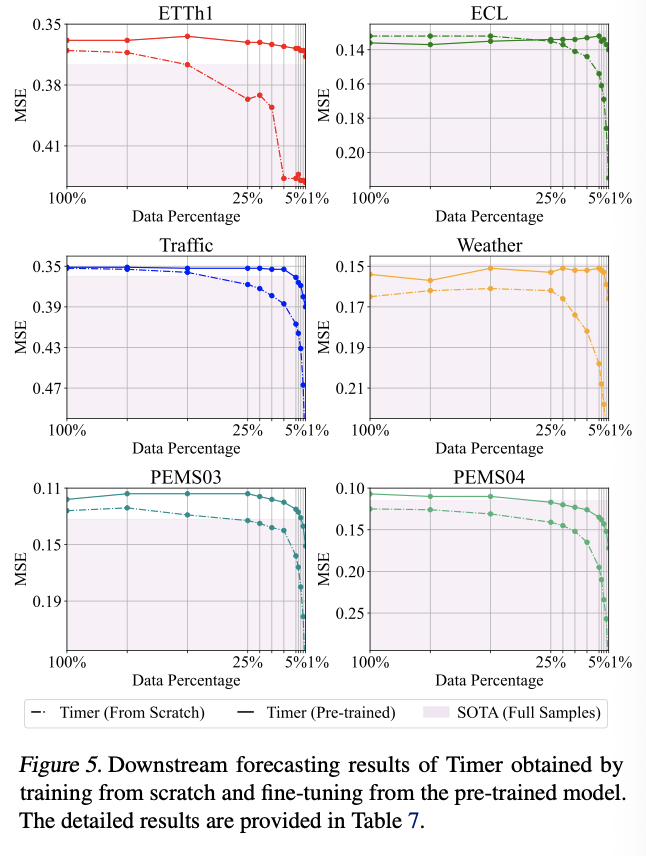
- [Figure 1] Training on 5% samples from ETTh1 only induces a 11% MSE increase.
- training oversaturation of these benchmarks can underestimate the advantages of LTSMs
- How to pretrain scalable LTSMs?
- No consensus on the LTSMs architecture!!
- Still obscure whether existing large-scale pre-trained time series models with the prevalent encoder-only structure can deliver the expected scalability
- Tokenization of heterogeneous TS for pre-training are left behind by other fields.
- Unified formulation to tackle various analysis tasks with TS of different lengths by one single pre-trained model remains underexplored
Timer
( Large-scale pre-trained Time Series Transformer)
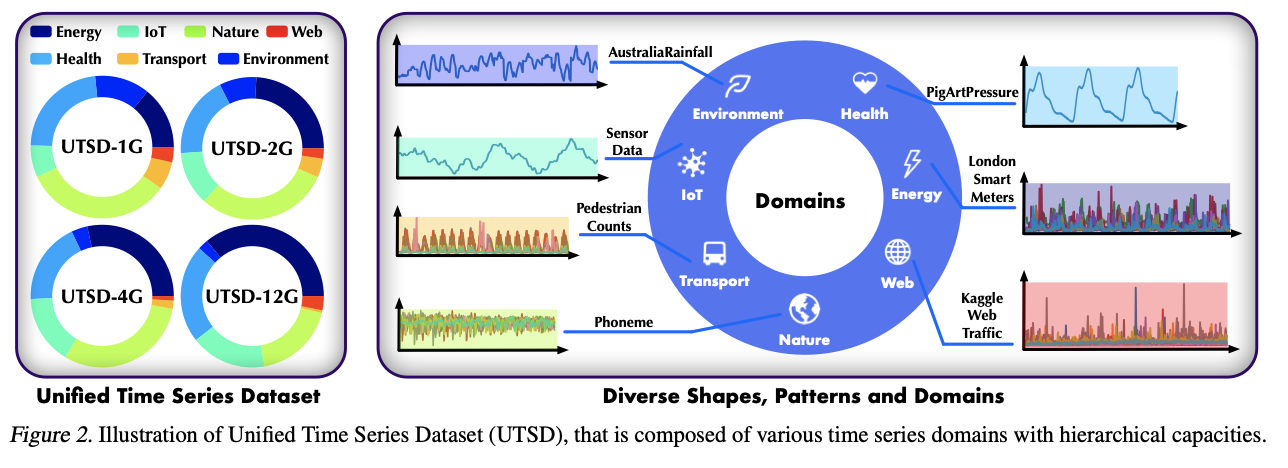
[1] Dataset: Unified Time Series Dataset (UTSD)
-
Aggregate publicly available TS datasets
& following curated data processing
[2] Pre-trained models
- Propose the single-series sequence (S3) format
- Convert heterogeneous series with reserved patterns into unified to ken sequences.
[3] Training strategies: GPT-style objective (next token prediction)
- To realize the few-shot capability and task generality toward LTSMs
Timer vs. others
- (others) Prevalent encoder-only architecture
- (Timer) aligns similar properties as LLMs
- such as the decoder-only structure trained by autoregressive generation.
- notable few-shot generalization, scalability, and feasibility for various series lengths and tasks with one model.
Contribution
-
(1) Advocate the advancement of large TS models
( for widespread data-scarce scenarios )
- (2) Timer
- [1] Curate large-scale datasets comprised of 1B time points
- [2] Propose the training strategy with the single-series sequence format
- [3] Timer: a pre-trained decoder
- (3) Apply Timer on various tasks
- realized in our unified generative approach.
2. Related Works
(1) Unsupervised Pre-training on Sequences
pass
(2) Large Time Series Models
Research on LTSM is still in the early stages!
Categorized into 2 groups
- (1) LLM based
- (2) non-LLM based
(1) LLM based
- FPT (Zhou et al., 2023): GPT-2 for TS
- LLMTime (Chang et al., 2023): encodes TS into numerical tokens for LLMs
- Time-LLM (Jin et al., 2023): prompting techniques to enhance prediction
(2) non-LLM based
-
ForecastFPN (Dooley et al., 2023)
- pretrain on synthetic time series data for zero-shot forecasting
-
CloudOps (Woo et al., 2023)
- adopts the masked encoder of Transformer
- domain-specific pre-trained forecaster.
-
Lag-Llama (Rasul et al., 2023)
- scalable univariate forecasting model
- by pre-training on existing time series benchmarks.
-
PreDcT (Das et al., 2023b)
- utilizes the decoder-only Transformer
- pre-trained on diverse time series from Google Trends
- exhibiting the zero-shot capability on forecasting benchmarks.
-
Timer (ours):
-
pre-trained natively on TS
( pre-trained extensively on 1 billion real-world time points from various domains )
-
free from modality alignment
-
conducive to downstream tasks of TS
-
capable of tackling variable series lengths
-
3. Approach
Advocate the development for LTSM
-
(1) Utilization of extensive TS corpora
-
(2) Adoption of a standardized format for diverse TS
-
(3) Pre-training objective on the decoder-only Transformer
( Autoregressively predict the next time series token )
(1) Data
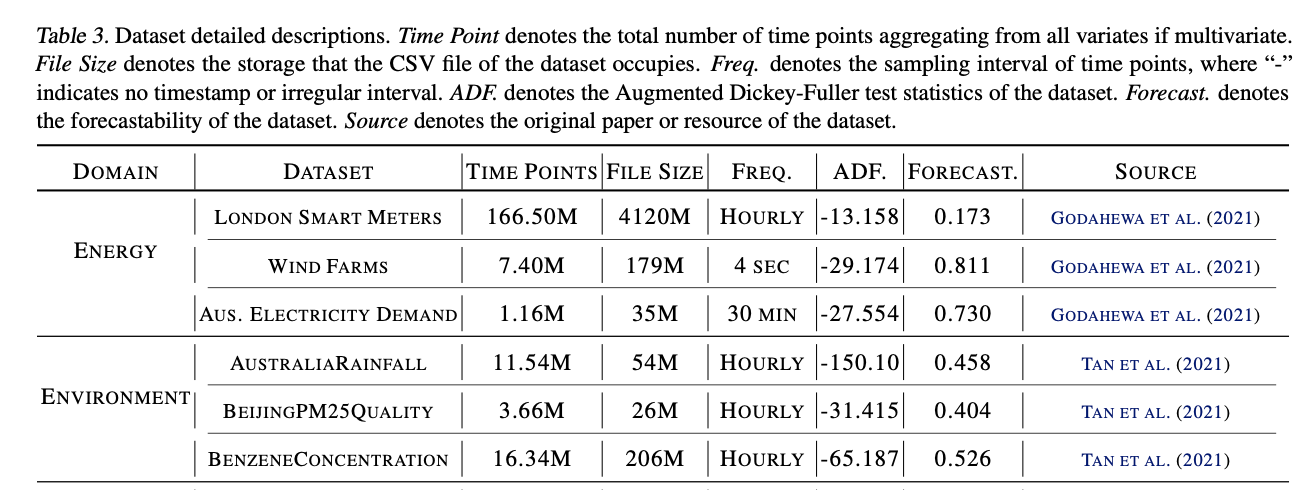
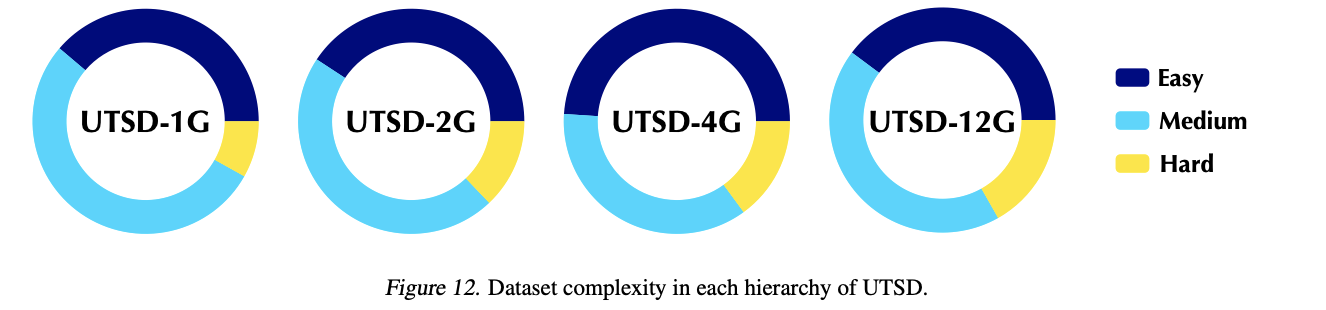
Record the statistics of each dataset, including
- (1) Basic properties
- i.e. number of time steps, variates, file size, interval granularity, etc;
- (2) TS characteristics
- i.e. period- icity, stationarity, and predictability
\(\rightarrow\) Assess the complexity of different datasets and progressively conduct scalable pre-training.
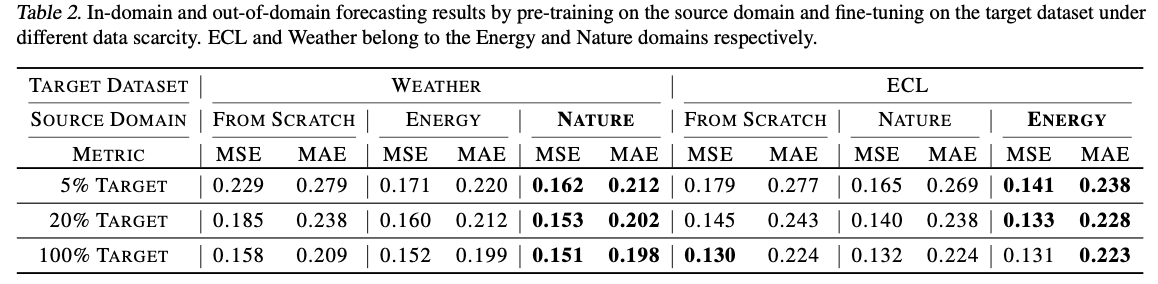
( + For domain-specific pre-trained TS models, we differentiate the datasets into typical domains )


(2) Training Strategy
Constructing unified TS sequences is not straightforward
\(\rightarrow\) Due to the heterogeneity of series
- i.e. amplitude, frequency, stationarity and disparities of the datasets in the variate number, series length
Single-series sequence (S3)
- To facilitate pre-training on extensive TS
- Convert heterogeneous TS into S3
- which reserves the patterns of series variations with the unified context length
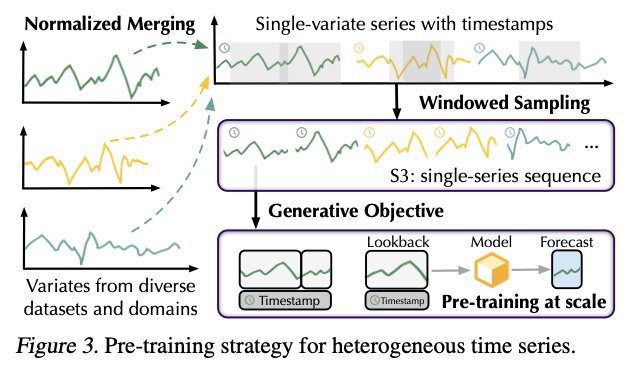
Procedures of S3
Step 1) Normalizing and merging at the level of variates
-
[Normalize]
- Split each series ( = each variate ) …. train:val = 9:1
- use statistics of the training split to normalize entire TS
-
[Merge]
-
Merged into a pool of single-variate series
-
Time points of single-variate series for training follow the normal distribution …
\(\rightarrow\) which mainly mitigates the discrepancies in the amplitude and variate numbers across multiple datasets.
-
Step 2) Sample
-
Uniformly sample sequences from the pool by a window
\(\rightarrow\) Able to obtain a single-series sequences with a fixed length ( = format of S3 )
-
Extension of Channel Independence (CI)
-
CI vs. S3
-
CI: flattens the variate dimension to the same batch,
\(\rightarrow\) Requiring the batch of series to originate from the same dataset
-
S3; model observes sequences from different periods and different datasets
\(\rightarrow\) Increasing the pre-training difficulty and directing more attention to temporal variations.
-
Summary of S3 format
- does not require time-aligned series
- applicable to univariate and irregular series
- also encourages the large model to capture multivariate correlations from the pool of single-variate series.
Task
Pre-training objective: Generative modeling
(3) Model Design
a) Next token prediction
\(P(\mathcal{U})=\prod_{i=1}^N p\left(u_i \mid u_{<i}\right)\).
- on the token sequence \(\mathcal{U}=\left\{u_1, \ldots, u_N\right\}\),
b) Tokenization
Tokenization of the given S3 \(\mathbf{X}=\left\{x_1, \ldots, x_{N S}\right\}\)
- with the unified context length \(N S\)
- TS token = time segment of length \(S\)
- \(\mathbf{s}_i=\left\{x_{(i-1) S+1}, \ldots, x_{i S}\right\} \in \mathbb{R}^S\).
c) Decoder-only Transformer*
with dimension \(D\) and \(L\) layers for GPT on the \(N\) tokens from a single-series sequence:
\(\begin{aligned} \mathbf{h}_i^0 & =\mathbf{W}_e \mathbf{s}_i+\mathbf{T E}_i, i=1, \ldots, N, \\ \mathbf{H}^l & =\operatorname{TrmBlock}\left(\mathbf{H}^{l-1}\right), l=1, \ldots, L, \\ \left\{\hat{\mathbf{s}}_{i+1}\right\} & =\mathbf{H}^L \mathbf{W}_d, i=1, \ldots, N, \end{aligned}\).
- \(\mathbf{W}_e, \mathbf{W}_d \in \mathbb{R}^{D \times S}\) : encode and decode token embeddings \(\mathbf{H}=\left\{\mathbf{h}_i\right\} \in \mathbb{R}^{N \times D}\)
- \(\mathbf{T E}_i\) : corresponding (optional) timestamp embedding.
Causal attention of the decoder-only Transformer
- autoregressively generated \(\hat{\mathbf{s}}_{i+1}\)
Pretraining objective
- \(\mathcal{L}_{\mathrm{MSE}}=\frac{1}{N S} \sum \mid \mid \mathbf{s}_i-\hat{\mathbf{s}}_i \mid \mid _2^2, i=2, \ldots, N+1\).
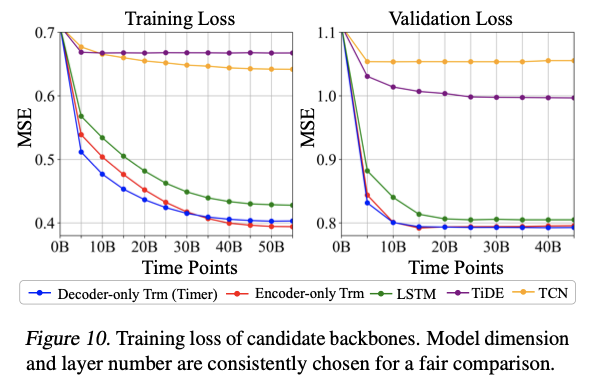
Why Tranasformer?
- predominant scalable choice in other fields
- evaluate backbone alternatives on TS
d) Architecture comparison
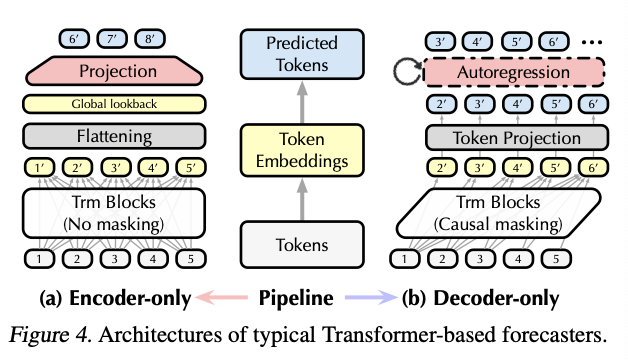
(1) Encoder-only structure
-
prevalent deep forecasters
-
obtain the predicted tokens through flattening and projection.
-
pros & cons
-
(pros) may benefit from end-to-end supervision
-
(cons) flattening can also wipe out token dependencies modeled by attention
\(\rightarrow\) Weaken Transformer layers to reveal the patterns of temporal variations
-
(2) Decoder-only structure
- substantial progress of LLM
- token-wise supervising signals
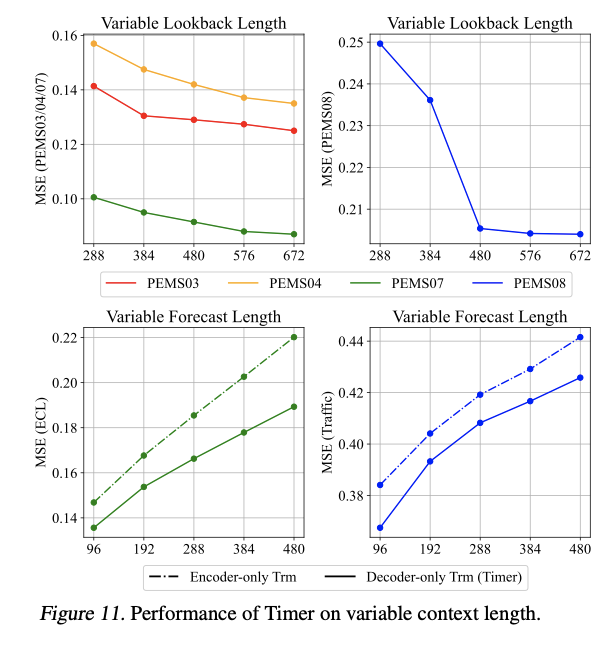
- including additional utilization of the lookback series.
- provides the flexibility to address variable context length
- by simply sliding the series at inference
\(\rightarrow\) Summary: establish LLM-style decoder-only Timer
- with autoregressive generation pre-training
4. Experiments
TS forecasting, imputation, and anomaly detection
\(\rightarrow\) unified generative scheme
Compare with baselines in terms of ..
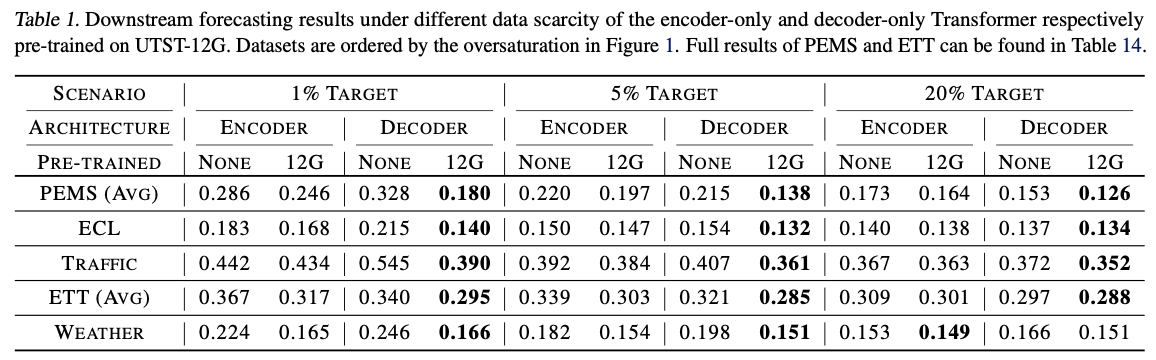
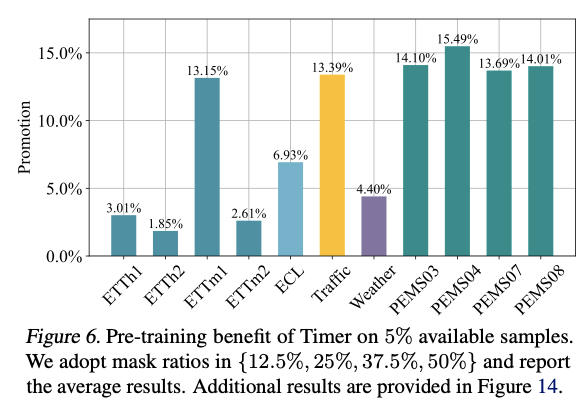
- (1) Few-shot ability
- pre-training benefits on data-scarce scenarios
- (2) Scalability
- model size & data size
Analysis
- (1) Candidate backbones and architectures
- effectiveness of our architectural option
(1) TS Forecasting
a) Setup
-
Dataset: ETT, ECL, Traffic, Weather, and PEMS
-
Lookback length = 672
-
Forecast length = 96
-
Pre-train Timer on UTSD-12G
-
segment length \(S = 96\)
-
number of tokens \(N = 15\)
( = context length up to 1440 )
-
-
Downstream forecasting task = next token prediction
b) Results
SOTA baselines:
- PatchTST (Nie et al., 2022) on ETTh1 and Weather
- iTransformer (Liu et al., 2023) on other datasets
(2) Imputation
a) Setups
Imputation
- Conduct the segment-level imputation
- TS is divided into 8 segments
- segment length S = 24 and the token number N = 15
b) Results
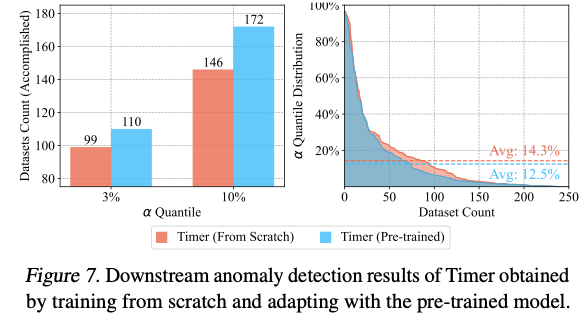
(3) Anomaly Detection
pass
(4) Scalability
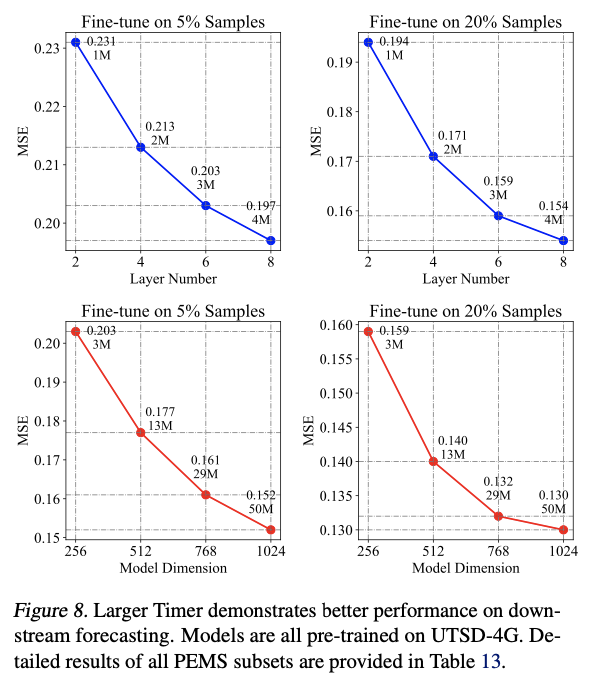
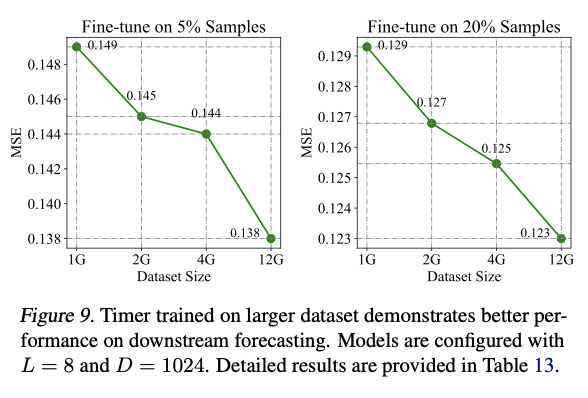
(5) Analysis