UniTS: Building a Unified Time Series Model
Contents
- Abstract
- Introduction
- Related Work
- Problem Formulation
- UniTS Model
- Experiments
Abstract
Foundation models: adapt a single pretrained model to many tasks
- via fewshot prompting or fine-tuning
However, not much in TS domain … Why??
-
(1) Inherent diverse and multi-domain TS
-
(2) Diverging task specifications
\(\rightarrow\) Apparent need for task-specialized models
UniTS (Unified TS model)
- Supports a universal task specification
- classification, forecasting, imputation, and anomaly detection
- Via a novel unified network backbone
- incorporates sequence and variable attention along with a dynamic linear operator
Experiments
- Dataset) 38 multi-domain datasets
- Result) superior performance compared to
- task-specific models
- repurposed natural language-based LLMs.
- etc) UniTS exhibits remarkable zero-shot, few-shot, and prompt learning capabilities when evaluated on new data domains and tasks.
Code) https://github.com/mims-harvard/UniTS.
1. Introduction
General-purpose models for TS
- have been relatively unexplored
TS datasets
- (1) abundant across many domains
- (2) used for a broad range of tasks
- ex) forecasting, classification, imputation, and anomaly detection.
Current TS models: require either
- (1) fine-tuning
- (2) specifying new task and dataset-specific modules
to transfer to new datasets and tasks
\(\rightarrow\) Lead to overfitting, hinder few- or zero-shot transfer
Challenges of building a unified TS model
-
(1) Multi-domain temporal dynamics
- (2) Diverging task specifications
- (3) Requirement for task-specific TS modules
a) Multi-domain temporal dynamics
- Unified models learn general knowledge by co-training on DIVERSE data sources,
- But TS data present wide variability in temporal dynamics across domains
- TS data may have “heterogeneous” data representations
- such as the # of variables, the definition of sensors, and length of observations
\(\rightarrow\) Therefore, a unified model must be designed and trained to capture general temporal dynamics that transfer to new downstream datasets, regardless of data representation.
b) Diverging task specifications
- Tasks on TS have fundamentally different objectives
- ex) forecasting: predicting future values in a TS
- ex) classification: discrete decision-making process made on an entire sample.
- Same task across different datasets may require different specifications
- ex) generative tasks: vary in length
- ex) recognition tasks: featuring multiple categories
\(\rightarrow\) Therefore, A unified model must be able to adapt to changing task specifications
c) Requirement for task-specific TS modules
- Unified models: employ shared weights across various tasks
- Distinct task-specific modules: require the fine-tuning of these modules.
UniTS
Unified TS model
- Various tasks with shared parameters ( task-specific modules (X) )
Addresses the following challenges:
- (1) Universal task specification with prompting
- (2) Data-domain agnostic network
- (3) Unified model with fully shared weights
(1) Universal task specification with prompting
- prompting: to convert various tasks into a unified token representation
(2) Data-domain agnostic network
- Employs self-attention
- across both “sequence” and “variable” dimensions
-
Introduce a dynamic linear operator
- to model relations between data points in sequence of any length
(3) Unified model with fully shared weights
- shared weights across tasks
- unified masked reconstruction pretraining scheme
- to handle both generative and recognition tasks
Handles 38 diverse tasks
- achieving the highest average performance
- best results on 27/38 tasks
- can perform zero-shot and prompt-based learning
- It excels in zero-shot forecasting for out-of-domain data,
- handling new forecasting horizons and numbers of variables/sensors
- It excels in zero-shot forecasting for out-of-domain data,
2. Related Work
(1) Traditional TS moeling
pass
(2) Foundation models for general TS modeling
Common self-supervised pretraining approaches include …
(1) MTM (Nie et al., 2023; Zerveas et al., 2021; Dong et al., 2023; Lee et al., 2024)
(2) CL (Luo et al., 2023; Wang et al., 2023; Xu et al., 2024; Fraikin et al., 2024)
(3) Consistency learning between different representations of TS
- (Zhang et al., 2022c; Queen et al., 2023).
Novel architectures that can capture diverse TS signals
- ex) TimesNet (Wu et al., 2023)
- uses multiple levels of frequency-based features
Reprogram LLMs to TS
- (Nate Gruver & Wilson, 2023; Chang et al., 2023; Zhou et al., 2023; Rasul et al., 2023; Jin et al., 2023; Cao et al., 2024).
- ex) GPT4TS (Zhou et al., 2023)
- layers of GPT-2 (Radford et al., 2019) is selectively tuned for various TS tasks.
- but still need task-specific modules & tuning for each task
(3) Prompt learning
Prompt learning
- Emerged as a form of **efficient task adaptation ** for large NN
- ex) constructing prompts in the **input **domain
- text prompts for language models (Arora et al., 2023)
- ex) tune soft token inputs to frozen language models (Li & Liang, 2021).
TEMPO (Cao et al., 2024)
- One of the only instances of prompt learning in TS
- introduces a learned dictionary of prompts that are retrieved at inference time.
- However, these prompts are only used in the context of forecasting.
3. Problem Formulation
(1) Notation.
[1] Multi-domain datasets \(D=\left\{D_i \mid i=1, \ldots, n\right\}\),
- where each dataset \(D_i\) can have a varying number of TS
-
can be of varying lengths & numbers of sensors/variables
- Each dataset: \(D_i=\left(\mathcal{X}_i, \mathcal{Y}_i\right)\)
[2] Four tasks
- forecasting
- classification
- anomaly detection
- imputation
[3] Models
- \(F\left(\mathcal{X}_i, \theta\right)\) : model with weights \(\theta\) trained on \(\mathcal{X}_i\)
- \(F(\mathcal{X}, \theta)\) : model trained on all datasets in \(D\),
[4] etc
-
\(\hat{\mathcal{X}}\) : out-of-domain dataset ( not included in \(\mathcal{X}\) )
-
\(\hat{\mathcal{Y}}\) : new type of tasks ( not contained in \(\mathcal{Y}\) )
- \(\mathrm{x} \in \mathbb{R}^{l_i \times v}\) : TS sample
[5] Several token types
- sequence token \(\mathbf{z}_s \in \mathbb{R}^{l_s \times v \times d}\)
- \(l_s\) : # of sequence tokens
- prompt token \(\mathbf{z}_p \in \mathbb{R}^{l_p \times v \times d}\)
- \(l_p\) : # of prompt tokens
- mask token \(\mathbf{z}_m \in \mathbb{R}^{1 \times v \times d}\)
- CLS token \(\mathbf{z}_c \in \mathbb{R}^{1 \times v \times d}\)
- category embeddings \(\mathbf{z}_e \in \mathbb{R}^{k \times v \times d}\),
- \(k\) : # of categories in a given classification task
\(\rightarrow\) \(\mathbf{z}_{\text {in }} \in \mathbb{R}^{l \times v \times d}\) : Tokens sent to the network
- where \(l\) is the sum of all tokens in the sequence dimension.
(2) Unified TS model
Desiderata for a unified TS model \(F(\mathcal{X}, \theta)\)
-
[1] Multi-domain TS
-
agnostic with any input samples \(\mathcal{X}\),
( diversity in sequence lengths \(l_{i n}\) , variable counts \(v\) )
-
-
[2] Universal task specification
-
adopt a universal task specification \(F(\mathcal{X}, \theta) \rightarrow \mathcal{Y}\)
( applicable across all type of tasks \(\mathcal{Y}\) )
-
-
[3] No task-specific modules (generalist)
-
handle multiple tasks simultaneously,
without requiring task-specific fine-tuning
-
(3) Problem Statement
Multi-task, zero-shot, few-shot, and prompt learning
a) Multi-task learning
Single model \(F(\theta)\)
-
for multiple tasks \(\mathcal{Y}\) , across diverse data sources \(\mathcal{X}\)
-
task-specific fine-tuning (X)
b) Zero-shot learning
Tested on multiple types of new tasks that are not trained for
-
\(F(\mathcal{X}, \theta) \rightarrow \hat{\mathcal{X}}, \hat{\mathcal{X}} \notin \mathcal{X}\).
-
ex) long-term forecasting with new length and
forecasting on out-of-domain datasets with a new # of variables.
c) Few-shot learning:
Can be fine-tuned on a few samples on new data \(\hat{\mathcal{X}}\) and new tasks \(\hat{\mathcal{Y}}\),
- ex) Few-Shot \(\{F(\mathcal{X}, \theta), \hat{\mathcal{X}}\}=F(\hat{\mathcal{X}}, \hat{\theta}) \rightarrow \hat{\mathcal{Y}}\)
d) Prompt learning
Handle tasks by simply using appropriate prompt tokens without any fine-tuning
- ex) Prompting \(\{F(\mathcal{X}, \theta)\), Prompt token \(\} \rightarrow \mathcal{Y}\).
4. UniTS Model

Prompting-based model with a unified network
-
Tokens: represent a variety of TS data domains and tasks
-
inspired by LLMs (Touvron et al., 2023)
-
unifies different types of tasks & data
-
Three distinct token types
- (1) Sequence tokens
- tokenize the input TS
- (2) Prompt tokens
- provide essential context about the task and data
- guiding the model to accomplish the task
- (3) Task tokens
- ex) mask and CLS tokens
- concatenated with the prompt tokens & sequence tokens
(1) Prompting tokens in UniTS
How to use prompt, sequence, and task tokens to unify different task types and conduct inference.
a) Sequence token
Step a-1) Patchify \(\mathrm{x} \in \mathcal{X}_i\)
- non-overlapping patch size of \(p\),
\(\rightarrow\) Result: \(\mathbf{z}_{\hat{s}}\) with length of \(l_s\), where \(l_s=l_i / p\).
Step a-2) Linear projection
- projects each patch in \(\mathbf{z}_{\hat{s}}\) into a fixed dimension
\(\rightarrow\) Result: \(\mathbf{z}_{s}\)
Step 3) Added with learnable positional embeddings
( Since \(v\) varies, we retain the variate dimension in tokens )
\(\rightarrow\) Solution: propose a flexible network structure capable of handling any number of variables/sensors \((v)\).
b) Prompt token
Defined as learnable embeddings
Each task has its own set of prompt tokens
- context related to the data domain and the task
\(\rightarrow\) UniTS adapts to new tasks by utilizing the appropriate prompt tokens without the need for fine-tuning
c) Task token
Two primary types
- (1) Mask token (for generative modeling)
- ex) forecasting, imputation, and anomaly detection
- (2) CLS tokens and category embeddings (for recognition tasks)
- ex) classification.
Define a general format for representing tasks
Support flexible adaptation to new tasks
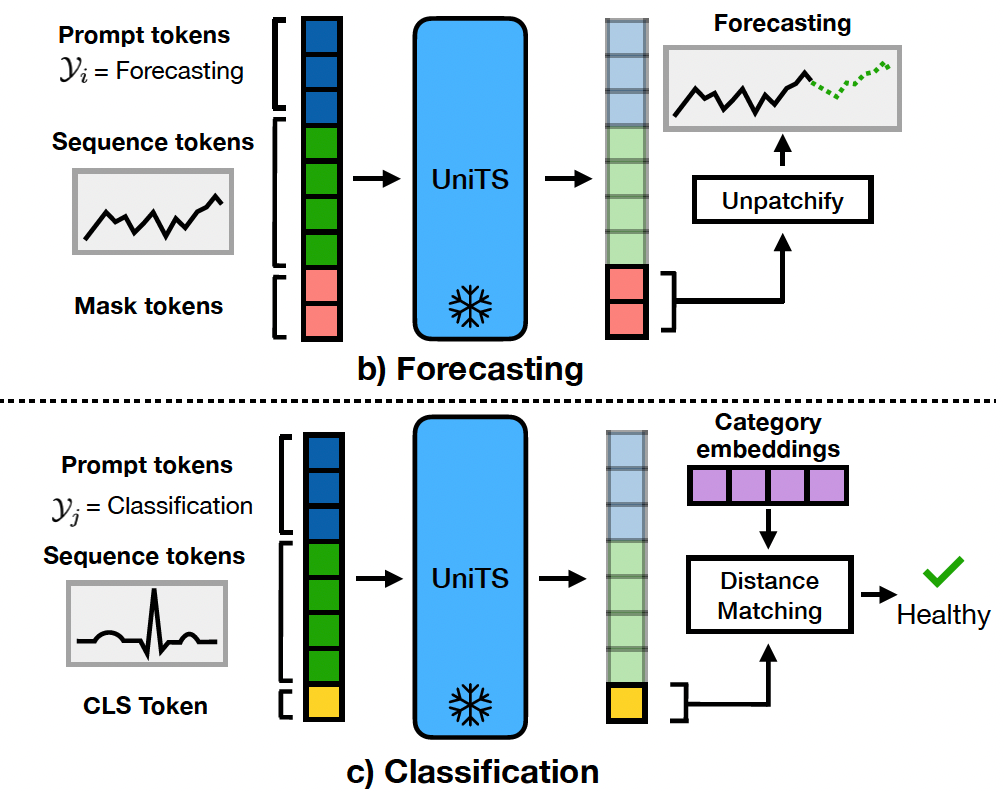
ex) Forecasting
- mask token \(\mathbf{z}_m\) is repeated in model input for any length forecasting,
- repeated mask tokens in UniTS output are transformed back to sequences.
ex) Classification
- CLS token \(\mathbf{z}_c\) is matched with category embeddings \(\mathbf{z}_e\).
ex) Imputation
- Missing parts can be filled in using mask tokens
ex) Anomaly detection
- de-noised sequence tokens returned by the model are used to identify anomalous data points.
(2) Unified Network in UniTS
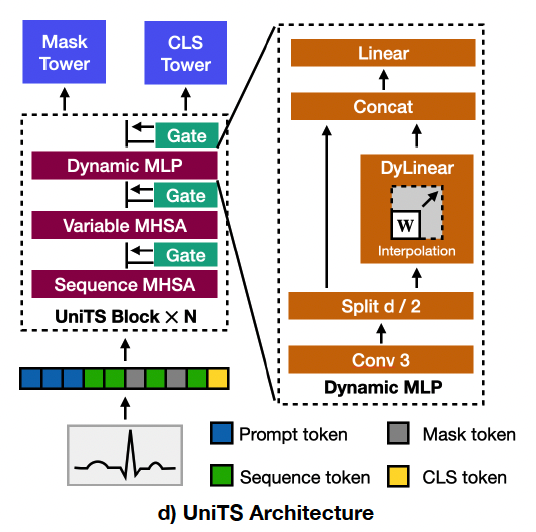
Consists of..
- (1) \(N\) repeated blocks (= UniTS blocks)
- (2) light-weight mask/CLS tower
UniTS blocks: following components
- (1) Sequence MHSA
- (2) Variable MHSA
- (3) Dynamic MLP
- (4) Gate modules.
Takes in tokens & process them with UniTS blocks
a) Sequence and Variable MHSA
(1) Sequence MHSA: standard MHSA is applied
(2) Variable MHSA: to capture global relations among variables across
- average the \(Q\) and \(K\) over the sequence dimension to get shared \(\hat{Q}\) and \(\hat{K}\)
- \(\hat{Q}, \hat{K}=\operatorname{mean}_l(Q, K)\).
- \(Q, K, V=\operatorname{Linear}\left(\mathbf{z}_{\text {in }}\right)\).
-
Output \(=\operatorname{Attn}_v V=\operatorname{Softmax}\left(\frac{\hat{Q} \hat{K}^T}{\sqrt{d}}\right) V\)
-
where \(\operatorname{Attn}_v \in \mathbb{R}^{v \times v}\) is the attention map among variables
( = shared for all sequence points )
-
b) DyLinear
Sequence MHSA: Similarity-based relation modeling
Dynamic linear operator (Dylinear)
- simple and effective
- capture relations among tokens of various sequence lengths
- Idea) weight interpolation scheme
\(\operatorname{DyLinear}\left(\mathbf{z}_s ; \mathbf{w}\right)=\mathbf{W}_{\text {Interp }} \mathbf{z}_s\).
- sequence tokens \(\mathbf{z}_s\) with length \(l_s\)
-
predefined weights \(\mathbf{w} \in \mathbb{R}^{w_i \times w_o}\)
- \(\mathbf{W}_{\text {Interp }}=\operatorname{Interp}(\mathbf{w})\).
- Interp: **bi-linear interpolation **
- Goal: resize from \(w_i \times w_o\) \(\rightarrow\) \(l_s \times l_{\text {out }}\)
- to match the input sequence and expected output length
c) Dynamic MLP
Extract both local details and global relations among the sequence.
Dynamic MLP
- 3-kernel convolution
- Applied across the sequence dimension of input \(\mathbf{z}_{\text {in }}\)
- Features within the \(d\) dimension are split into two groups
- resulting in \(\left(\mathbf{z}_{\text {mid }}^1, \mathbf{z}_{\text {mid }}^2\right) \in \mathbb{R}^{l \times v \times d / 2}\)
\(\mathbf{z}_{\text {out }}=\operatorname{Linear}\left(\operatorname{Concat}\left(\operatorname{DyLinear~}_M\left(\mathbf{z}_{\text {mid }}^1\right), \mathbf{z}_{\text {mid }}^2\right)\right)\).
-
where DyLinear \(_M\) processes the
- (1) sequence tokens
- (2) prompt tokens
in \(\mathbf{z}_{\text {mid }}^1\) with two DyLinear operators,
-
CLS token is skipped to ensure consistency for all tasks.
Separation of routes for \(\mathbf{z}_{\text {mid }}^1\) and \(\mathbf{z}_{\text {mid }}^2\)
- leads to a scale combination effect, thus enhancing multi-scale processing
(3) UniTS Model Training
a) Unified masked reconstruction pretraining
To enhance abilitiy of generative and recognition tasks,
Distinct from MTM
-
MTM) focus on predicting masked tokens
-
Proposed) utilizes the semantic content of
both (1) prompt and (2) CLS tokens
Pretraining loss:
\(L_u= \mid H_m\left(\mathbf{z}_p, \mathbf{z}_s\right)-x \mid ^2+ \mid H_m\left(\hat{\mathbf{z}}_c, \mathbf{z}_s\right)-x \mid ^2\).
- \(x\) : unmasked full sequence
- \(\hat{\mathbf{z}}_c=H_c\left(\mathbf{z}_{C L S}\right)\) : the CLS token features processed by the CLS tower \(H_c\)
- To leverage the semantics of the CLS token!
- \(H_m\) : the mask tower
b) Multi-task supervised training
Step 1) Randomly sample a batch of samples
- from one dataset at a time
Step 2) Accumulate dataset-level loss values:
- \(L_{\text {total }}=\) \(\sum_{i=1}^I \lambda_i \cdot L_i\left(D_i\right)\),
- \(L_i\) : loss for the sampled batch
- \(\lambda_i\) : weight for each loss
- \(I\) : the number of sampled batches
5. Experiments
Datasets
-
38 datasets from several sources
- span domains including human activity, healthcare, mechanical sensors, and finance domains
-
Tasks
- 20 forecasting tasks
- of varying forecast lengths ranging from 60 to 720
- 8 classification tasks
- featuring from 2 to 52 categories
- 20 forecasting tasks
-
TS length
- varying numbers of readouts (from 24 to 1152) and sensors (from 1 to 963).
Baselines
7 TS models
-
iTransformer (Liu et al., 2024), TimesNet (Nie et al., 2023), PatchTST (Nie et al., 2023),
Pyraformer (Liu et al., 2021), and Autoformer (Wu et al., 2021).
LLM based methods
- GPT4TS (Zhou et al., 2023) and LLMTime (Nate Gruver \& Wilson, 2023).
Many of these methods are designed only for one type of task
-
ex) GPT4TS, LLMTime: forecasting models
-
Add task-specific input/output modules for methods
when necessary to support multiple tasks and include them in benchmarking.
(1) Benchmarking UniTS for Multi-Task Learning
a) Setup
UniTS vs others
- UniTS) various tasks using a fully shared architecture
- others) task-specific models
To benchmark them …
- existing methods use a shared backbone for all tasks
- augmented using data-specific input modules and task-specific output modules.
Two variants of UniTS
- (1) Fully supervised model
- that uses the same training scheme as baselines,
- (2) Prompt learning model
- where a pretrained UniTS is fixed
- only prompts for all tasks are generated.
All models are co-trained with 38 datasets
b) Results: Benchmarking of UniTS
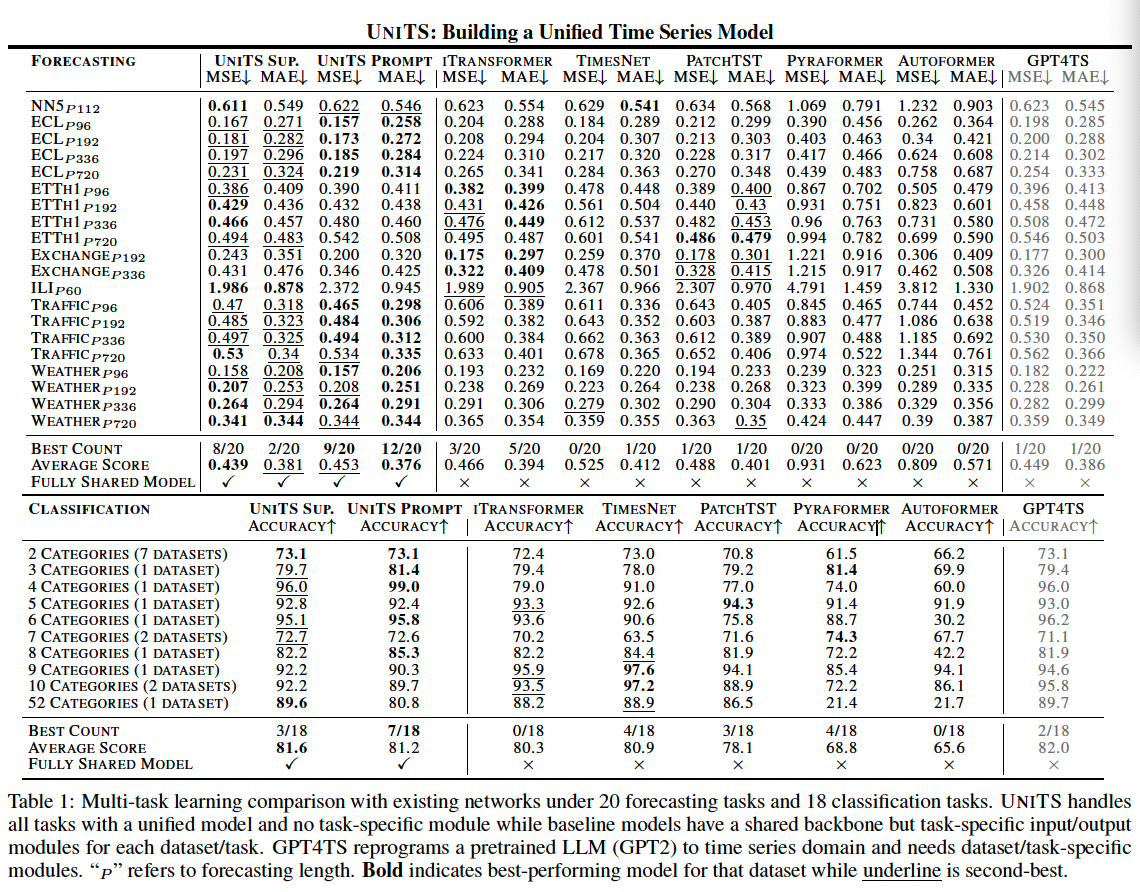
Best results in
- 17 out of 20 forecasting tasks (MSE)
- 10 out of 18 classification tasks (accuracy)
Performance gains are especially remarkable because UniTS has no task or dataset-specific modules!
Baseline methods: encounter difficulties performing well across different types of tasks.
- ex) TimesNet
- excels in classification tasks
- underperforms in forecasting tasks
- ex) iTransformer
- the top-performing forecaster
- struggles with classification tasks
Performance gain
- Forecasting: surpasses iTransformer
- by 5.8% (0.439 vs. 0.466) in MSE
- by 3.3% (0.381 vs. 0.394) in MAE
- Classification: surpasses TimesNet
- by average gain of 0.7% accuracy (81.6% vs. 80.9%)
- over the strongest baseline
\(\rightarrow\) shows promising potential to unify data and task diversity across TS domains
Pretrained NLP models to TS
- Most approaches incorporate additional task-specific modules to align the modalities of TS & NL
Compare UniTS with GPT4TS
- GPT4TS: reprograms pretrained weights of GPT-2 model
- GPT4TS is \(48 \times\) larger than UniTS (164.5M vs. 3.4M model parameters)
- UniTS still compares favorably to GPT4TS.
c) Results: Prompt learning is competitive with supervised training.
Using only tokens to prompt a fixed UniTS, SSL-pretrained UniTS achieves performance comparable to supervised trained UniTS
- [forecasting] UniTS-Prompt > UniTS-Sup
- suggesting effectiveness of prompt learning in UniTS
- UniTS-Promt: already exceeds the performance of supervised baseline methods with separate modules.
\(\rightarrow\) Conclusion:
- (1) SSL-pretrained model contains valuable features for TS tasks
- (2) Prompt learning can be an effective approach for these tasks.

- Explore the capabilities of prompt learning & model size
- As model size grows..
- UniTS-SSL) better
- UniTS-SL) soso
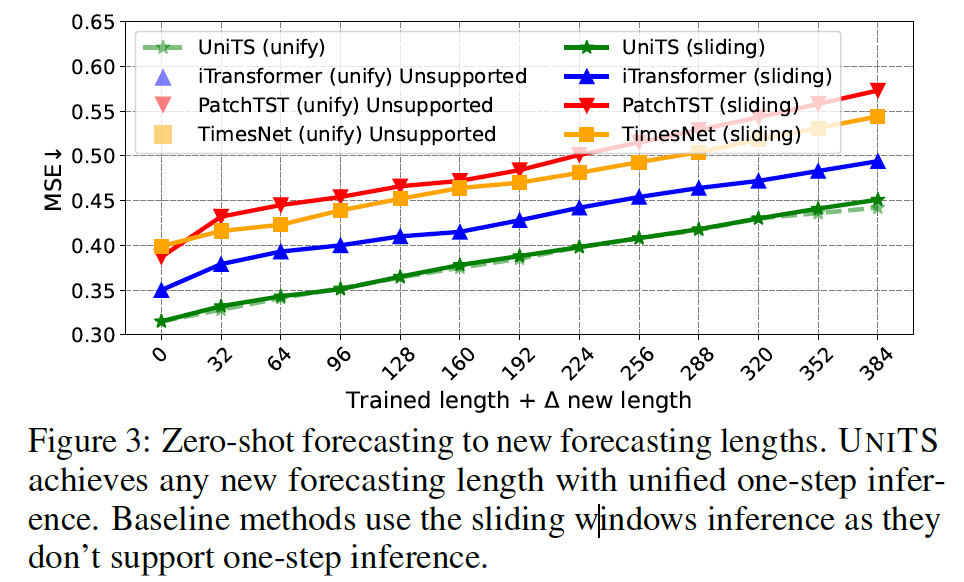
(2) UniTS for Zero-Shot New-length Forecasting
Forecasting across various lengths ??
- (previous) by training multiple predictors
- \(\rightarrow\) unavailable for new and untrained forecasting lengths
- (UniTS) can perform forecasting for new lengths by simply repeating the mask token
For comparison with baseline methods…
-
develop “sliding-window” forecasting scheme
-
enables the model to predict a fixed window size
& slide to accommodate new lengths.
-
-
exclude datasets that do not offer a wide range of lengths
(3) UniTS for Zero-Shot Forecasting on New Datasets
Five new forecasting tasks
- varying forecasting lengths and numbers of variables
Benchmark:
- LLMTime (Nate Gruver & Wilson, 2023)
- designed for zero-shot forecasting using LLMs
- Following LLMTime, we utilize one sample from each dataset to manage the extensive inference costs.
- exclude Time-LLM
- supports zero-shot learning,
- but requires that the forecasting length and the number of variables/sensors for zero-shot prediction are the same!
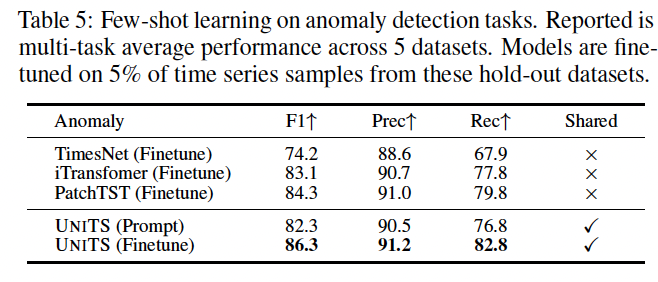
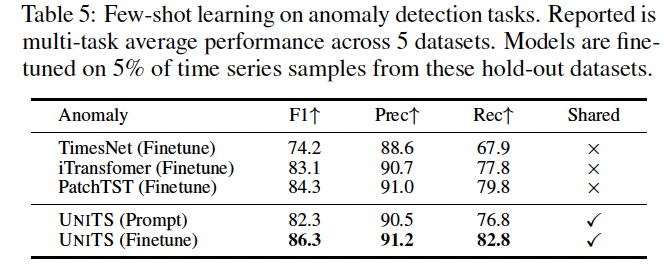
(4) UniTS for Few-Shot Classification and Forecasting
Novel dataset collection
- 6 classification tasks
- 9 forecasting tasks
Pretrained models
- undergo finetuning using 5%, 15%, and 20% of the training set.
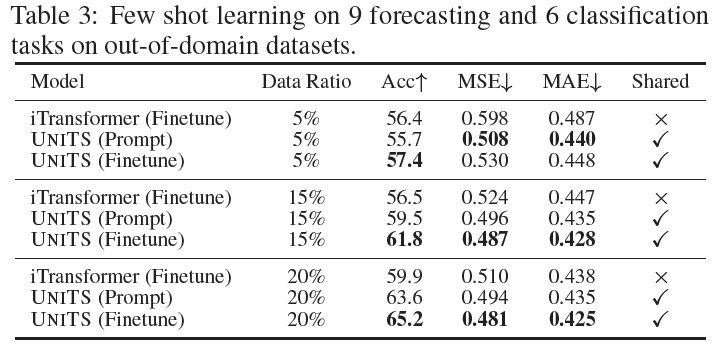
- Average performance metrics
- for both prompt learning and complete fine-tuning.
(5) UniTS for Few-Shot Imputation
Block-wise imputation task (with 6 datasets)
Models pretrained on 38 datasets are finetuned with \(10 \%\) of new training data
- asked to impute \(25 \%\) and \(50 \%\) of missing data points.
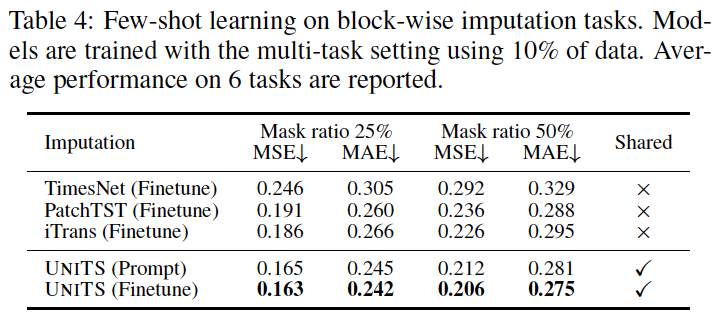
UniTS-Prompt achieves comparable results to its fully fine-tuned counterpart (UniTS-Finetune)
\(\rightarrow\) Selecting suitable prompt tokens alone can effectively adapt UniTS for the imputation task!
(6)
Average score across all datasets using a multi-task setting.
The pretrained models have been finetuned using 5% of the training data.