Wavenet : A generative model for raw audio (2016)
Contents
- Abstract
- WaveNet
- Dilated Causal Convolutions
0. Abstract
Wavenet : DNN for generating raw audio waveforms
- fully probabilistic
- autoregressive
1. WaveNet
-
introduce new generative model
-
joint probability of waveform \(\mathbf{x}=\left\{x_{1}, \ldots, x_{T}\right\}\) :
factorized as …
\(p(\mathbf{x})=\prod_{t=1}^{T} p\left(x_{t} \mid x_{1}, \ldots, x_{t-1}\right)\).
-
similar to PixelCNNs, the conditional prob dist is modelled by a stack of CONVOLUTIONAL layers
-
outputs a categorical distn over the next \(x_t\) with softmax layer
-
optimized to maximize log likelihood
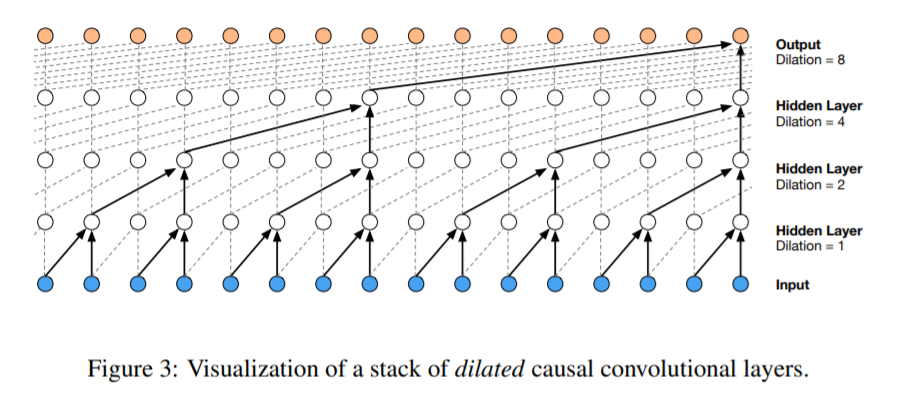
(1) Dilated Causal Convolutions
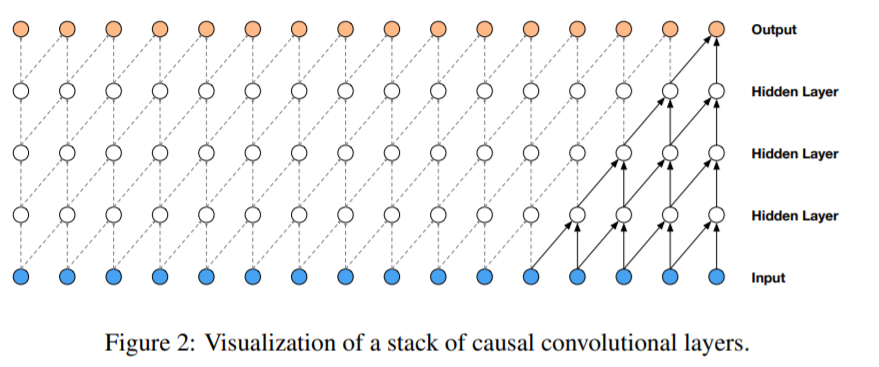
key of WaveNet : “casual convolutions”
-
ensure “time ordering” ( = no cheating )
( \(\approx\) masked convolution for CNN )
-
for 1D data (ex. audio), easy to implement
( just shift the output of normal convolution by a few timestep )
Train & Inference
-
[ Train ] : can be made in parallel ( all KNOWN )
\(\rightarrow\) faster than RNN
-
[ INFERENCE ] : made sequentially
Problem : require many layers
\(\rightarrow\) use dilated convolutions to increase receptive field! ( w.o increasing computational cost )
Dilated Convolution
-
use “skipping” for “efficieincy”
-
similar to pooling / strided convolutions
( BUT, difference : output has the SAME size as the input )