Deconstructing Denoising Diffusion Models for Self-Supervised Learning
Contents
- Abstract
- Introduction
- Background
- Deconstructing DDM for SSL
- Reorienting DDM for SSL
Abstract
Representation learning abilities of Denoising Diffusion Models (DDM)
Proposal: Deconstruct a DDM
-
Gradually transforming it into a classical Denoising Autoencoder (DAE)
-
Deconstructive procedure
- allows us to explore how various components of modern DDMs influence SSL
-
Result: Only a very few modern components are critical for learning good representations
1. Introduction
Denoising Diffusion Models (DDM)
- Learn DAE that removes noise of multiple levels driven by a diffusion process
- Originally proposed for learning representations ( SSL )
Successful variants of DAEs = Masked modeling (MM)
\(\rightarrow\) However, significantly different from removing noise!
- MM: explicitly specify unknown vs. known content
- Classical DAE: no clean signal in separating additive noise
Today’s DDMs for generation are dominantly based on additive noise
= Implying that they may learn representations without explicitly marking unknown/known content
Recent works
-
Inspecting the representation learning ability of DDMs
- Directly take off-the shelf pre-trained DDMs, which are originally purposed for generation
- Evaluate their representation quality for recognition
- Results using these generation-oriented models
-
However, these pioneering studies obviously leave open questions:
-
These off the-shelf models were designed for generation, not recognition
= Unclear whether the representation capability is gained by a denoising-driven process, or a diffusion-driven process
-
Proposal
Deconstruct a DDM into a classical DAE
Understandings on what are the critical components for a DAE to learn good representations
Result
- Main critical component is a tokenizer that creates a low-dimensional latent space
- Independent of the specifics of the tokenizer
- ex) standard VAE [26], a patch-wise VAE, a patch-wise AE, and a patch-wise PCA encoder ,,,
- It is the low-dimensional latent space, rather than the tokenizer specifics, that enables a DAE to achieve good representations
- Independent of the specifics of the tokenizer
Procedures
- Step 1) Project the image onto a latent space using patch-wise PCA
- Step 2) Add noise
- Step 3) Project it back by inverse PCA
- Step 4) Train an autoencoder to predict a denoised image
\(\rightarrow\) “latent Denoising Autoencoder” ( \(l\)-DAE)
2. Background: Denoising Diffusion Models (DDM)
Diffusion proces
- \(z_t=\gamma_t z_0+\sigma_t \epsilon\).
- where \(\epsilon \sim \mathcal{N}(0, \mathbf{I})\)
- \(\gamma_t\) and \(\sigma_t\) define the scaling factors of the signal and of the noise, respectively
- Default) \(\gamma_t^2+\sigma_t^2=1\).
DDM: learned to remove the noise, conditioned on the time step \(t\).
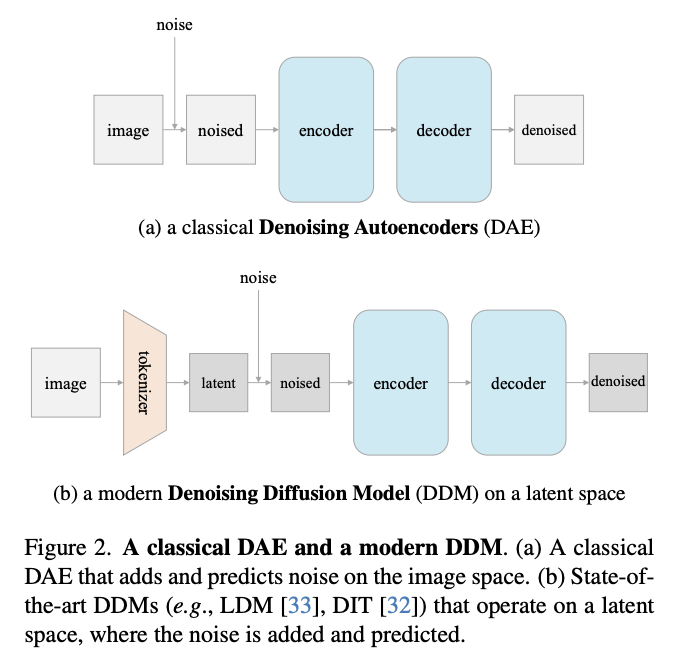
DDM vs DAE
- DAE: predicts a clean input
- DDM: predicts the noise \(\epsilon\).
- \(\mid \mid \epsilon-\operatorname{net}\left(z_t\right)\mid \mid^2\).
- Trained for multiple noise levels given a noise schedule, conditioned on the time step \(t\).
DDMs: can operate on two types of input spaces
- (1) On raw/original space
- (2) On a latent space produced by a tokenizer
Diffusion Transformer (DiT)
Choose this Transformer-based DDM for several reasons:
- (1) (Unlike other UNet-based DDMs ) Provide fairer comparisons with other SSL baselines driven by Transformers
- (2) Clearer distinction between the encoder and decoder
- UNet’s encoder and decoder are connected by skip connections and may require extra effort on network surgery when evaluating the encoder
- (3) Much faster than other UNet-based DDMs, while achieving better generation quality.
Tokenizer.
DiT: form of Latent Diffusion Models (LDM)
= Uses a VQGAN tokenizer
- Transforms the \(256 \times 256 \times 3\) input image into a \(32 \times 32 \times 4\) latent map
3. Deconstructing DDMs
Deconstruction trajectory is divided into three stages
- (3.1) Adapt the generation-focused settings in DiT to be more oriented toward SSL
- (3.2) Deconstruct and simplify the tokenizer
- (3.3) Reverse as many DDM motivated designs as possible
- Pushing the models towards a classical DAE
## (1) Reorienting DDM for SSL
DDM
-
Form of a DAE
-
But developed for the purpose of image generation
\(\rightarrow\) Oriented toward the generation task!!
( + Some designs are not legitimate for SSL (e.g., class labels are involved) )
\(\rightarrow\) Reorient our DDM baseline for the purpose of SSL
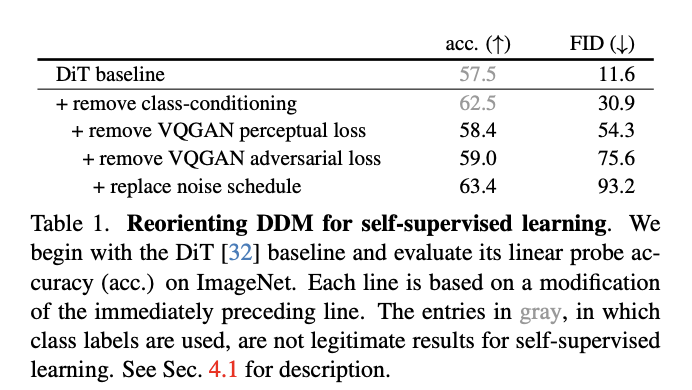
a) Remove class-conditioning.
Recent high-quality DDM
-
Often trained with conditioning on class labels
\(\rightarrow\) Largely improve the generation quality!
-
However, not legitimate in the context of SSL
\(\rightarrow\) Remove class-conditioning in our baseline
Result: Substantially improves the linear probe accuracy from \(57.5 \%\) to \(62.1 \%\)
- ( Even though the generation quality is greatly hurt as expected … feat FID )
Conclusion: Conditioning the model on class labels may reduce the model’s demands on encoding the information related to class labels.
& Removing the class-conditioning can force the model to learn more semantics
b) Deconstruct VQGAN.
VQGAN tokenizer: Trained with multiple loss terms
- (1) Autoencoding reconstruction loss
- (2) KL-divergence regularization loss
- (3) Perceptual loss based on a supervised VGG net trained for ImageNet classification
- (4) Adversarial loss with a discriminator
Removing (3) Perceptual loss
-
Involves a supervised pretrained network \(\rightarrow\) not legitimate for SSL
-
Thus, train another VQGAN tokenizer w/o loss (3)
\(\rightarrow\) Reduces the linear probe accuracy significantly from \(62.5 \%\) to \(58.4 \%\)
\(\rightarrow\) Conclusion: Tokenizer trained with the perceptual loss (with class labels) in itself provides semantic representations
Removing (4) Adversarial loss
- Slightly increases the linear probe accuracy from \(58.4 \%\) to \(59.0 \%\)
\(\rightarrow \therefore\) Removing either loss (3) & (4) harms generation quality.
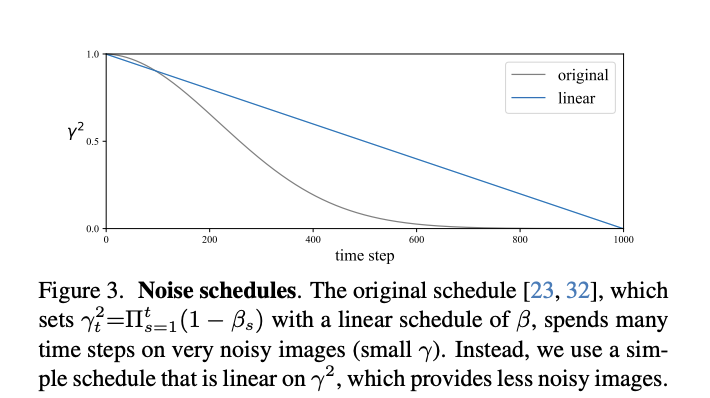
c) Replace noise schedule
Goal: Progressively turn a noise map into an image
Original noise schedule spends many time steps on very noisy images
\(\rightarrow\) Not necessary if our model is not generation-oriented
Propose a simpler noise schedule for SSL
-
Let \(\gamma_t^2\) linearly decay in the range of \(1>\gamma_t^2 \geq 0\)
\(\rightarrow\) Allows the model to spend more capacity on cleaner images
Result: Greatly improves the linear probe accuracy from \(59.0 \%\) to \(63.4 \%\)