https://www.youtube.com/watch?v=IOAdEjD72hA
1. Introduction to AD
(1) 용어
| 용어 | 기본 의미 | 사용되는 대표 문맥 | 훈련 데이터에서? | 탐지 대상 |
|---|---|---|---|---|
| Outlier | 통계적으로 특이한 점 | 통계학, 데이터 분석 | 포함되어 있음 | 훈련 데이터 내 이상 |
| Novelty | 새로운 유형 | 머신러닝, OOD 탐지 | 포함되어 있지 않음 | 훈련 데이터 외의 정상/비정상 샘플 |
| Anomaly | 이상/비정상 | 시계열, 보안 등 실용적 문맥 | 포함될 수도 있고 아닐 수도 있음 | 정상 분포에서 벗어난 비정상 |
1. Outlier
- 보통 통계학적 관점에서 많이 사용됨
- 훈련 데이터 안에서 평균/분산과 거리가 먼 점
- 예: 정규분포에서 3시그마 이상 떨어진 점
✅ 즉, 이미 수집된 데이터 내에서 이상한 샘플
2. Novelty
- 보통 머신러닝/패턴 인식에서 사용
- 훈련 데이터에는 존재하지 않았던 새로운 유형의 입력을 의미
- 예: 고양이/개로만 학습했는데, 테스트에 코끼리가 등장
✅ 즉, 모델이 처음 보는 “새로운 유형의 데이터” (꼭 이상(anomaly)은 아닐 수도 있어. 그냥 새로운 클래스일 수도 있어)
→ OOD detection!
3. Anomaly
- 보통 응용 문제 (예: 네트워크 침입, 고장 감지)에서 사용
- 일반적으로는 정상 데이터가 많고, 비정상(rare event)을 탐지하는 문제
- anomaly는 훈련 데이터에 포함되었을 수도 있고 아닐 수도 있음
✅ 즉, 정상 분포로부터 벗어난 rare하고 중요도 높은 이상 이벤트
→ Anomaly detection!
상황별 용도 예시
| 분야 | outlier | novelty | anomaly |
|---|---|---|---|
| 통계 | O | × | O |
| 이미지 분류 | × | O (OOD) | O (특이 클래스) |
| 네트워크 보안 | O | O | O |
| 시계열 이상탐지 | O | × | O |
간단 정리 문장
- Outlier: 기존 데이터 중 특이한 샘플
- Novelty: 훈련 중 보지 못했던 새로운 종류의 입력
- Anomaly: 정상과 다르게 작동하는 “의심스러운” 샘플
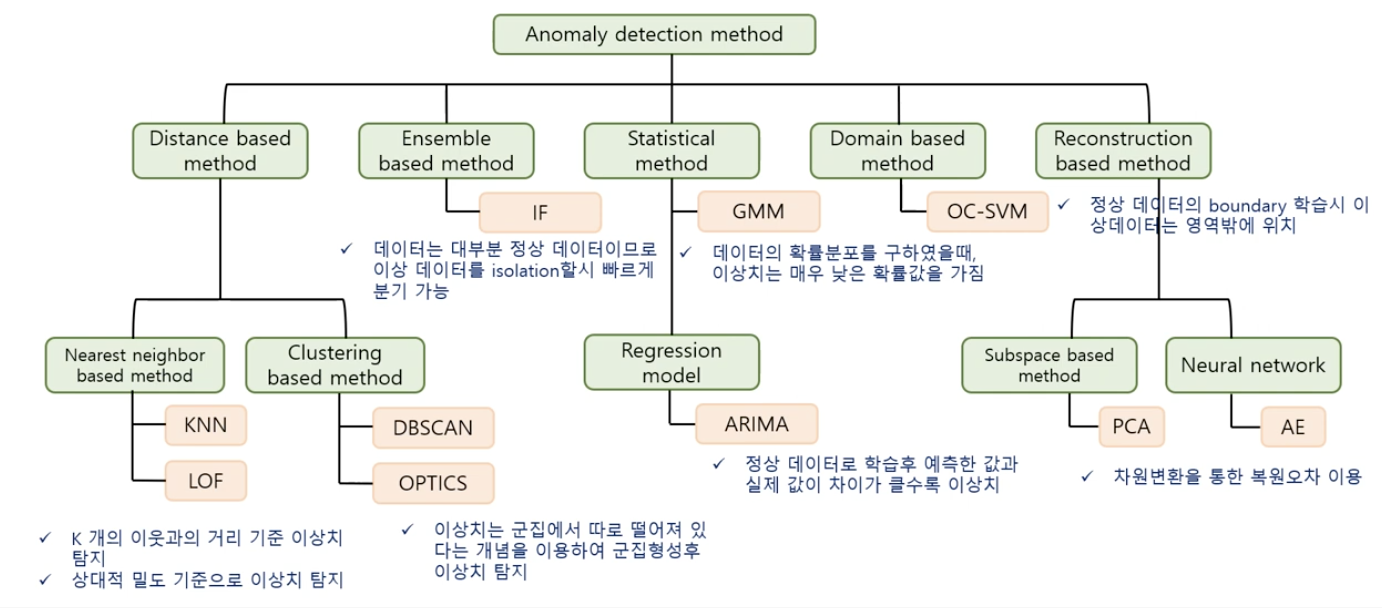
(2) 지도 & 비지도 학습
지도 학습
- Logistic regression
- Gradient boosting
비지도 학습
- Isolation Forest (IF)
- 한 줄 요약: 하나의 데이터를 구분하기 위해 필요한 split의 횟수를 이상치 점수로!
- 핵심 아이디어: 이상치는 빠르게 분리 될 것!
- Local Outlier Factor (LOF)
- 특정 관측치 주변의 밀도 (density)를 기반으로 추정
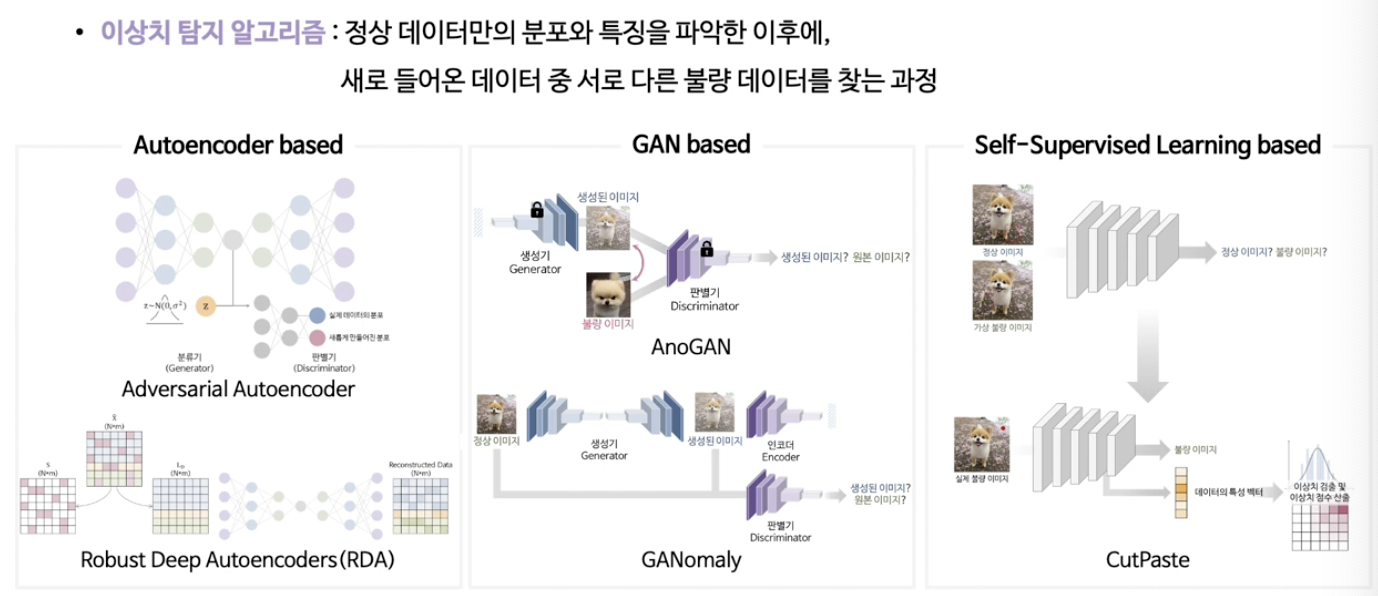
(3) DL 기반 AD 방법론의 세 종류
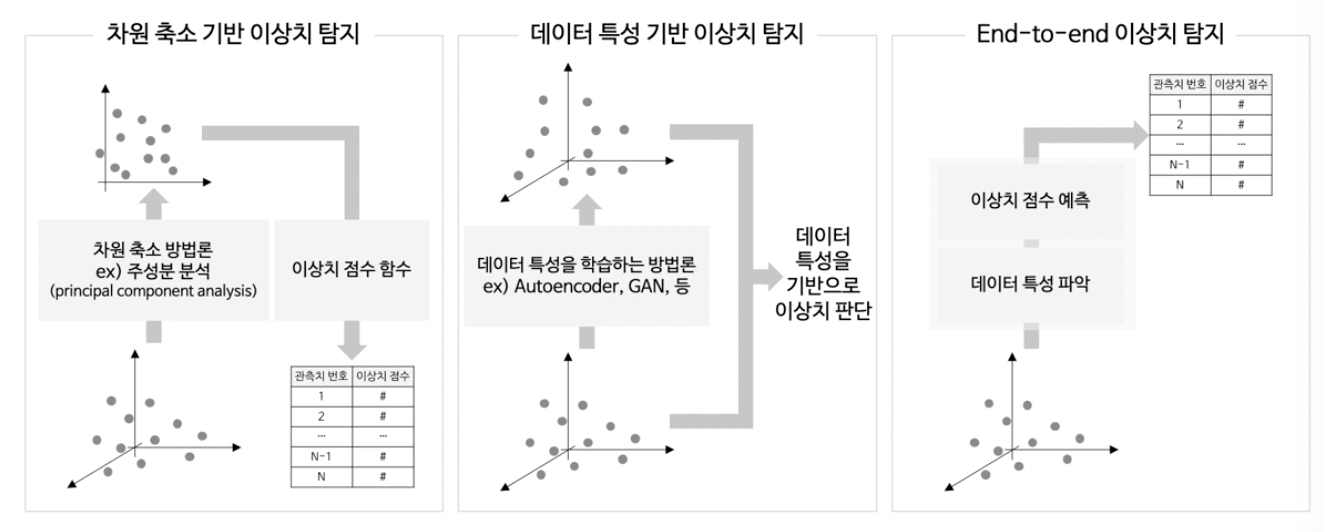
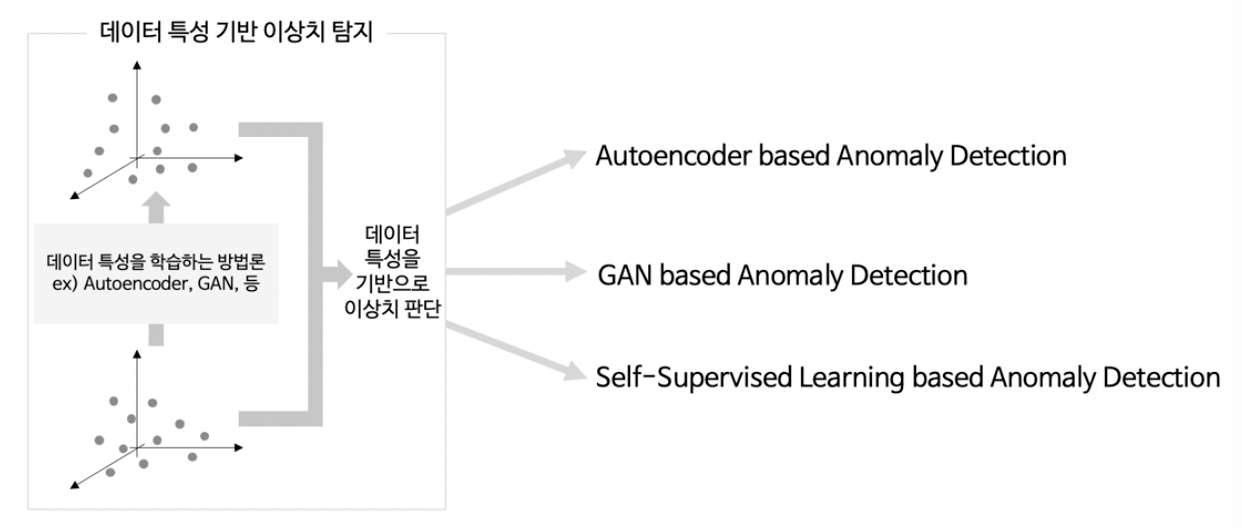
2. AE-based AD
가정: 정상 관측치는 잘 복원될 것!
$\rightarrow$ Reconstruction error를 기반으로 판단
(1) Variations
- a)VAE 기반
- b) Adversarial AE기반: 생성기 & 판별기가 존재함
- 생성기: 새로운 데이터 생성
- 판별기: 실제 데이터 / 새롭게 만들어진 분포인지 구분
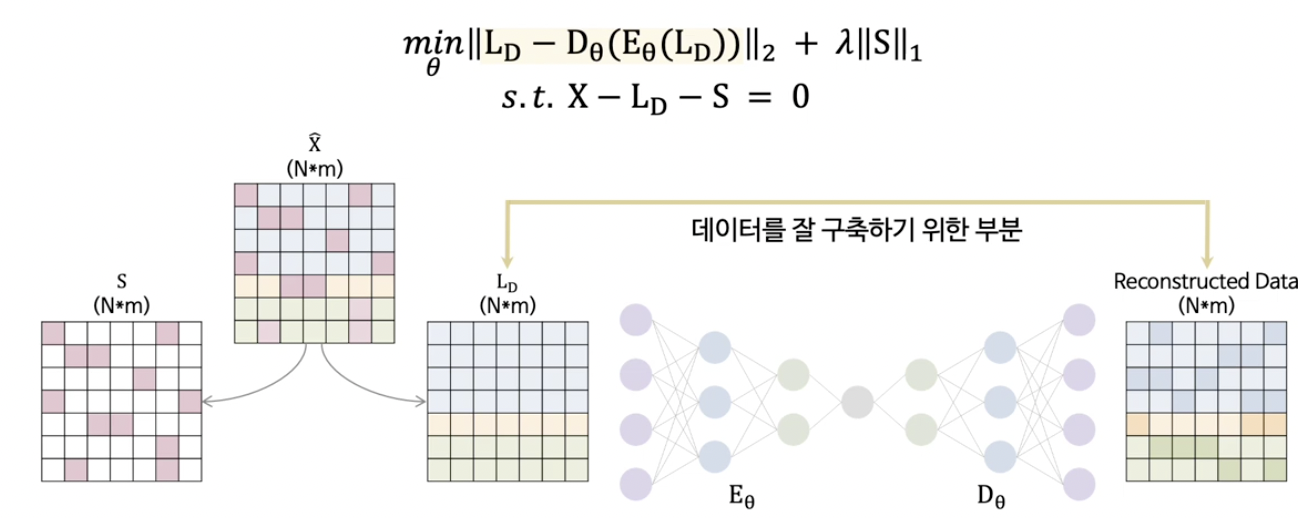
(1) Robust Deep Autoencoder
( Autoencoder Detection with Robust Deep Autoencoders )
Robust Deep Autoencoder = (1) + (2)
-
(1) Robust PCA (RPCA)
-
(2) AE
RPCA를 통하여 얻어진 깨끗한 데이터로 AE학습
3. GAN-based AD
(1) AnoGAN
( Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery )
핵심 요약
- GAN을 학습시킨 뒤, 주어진 테스트 이미지가 정상 분포에서 나왔는지 (=생성 가능한지)를 보고 이상 여부를 판단
Procedure
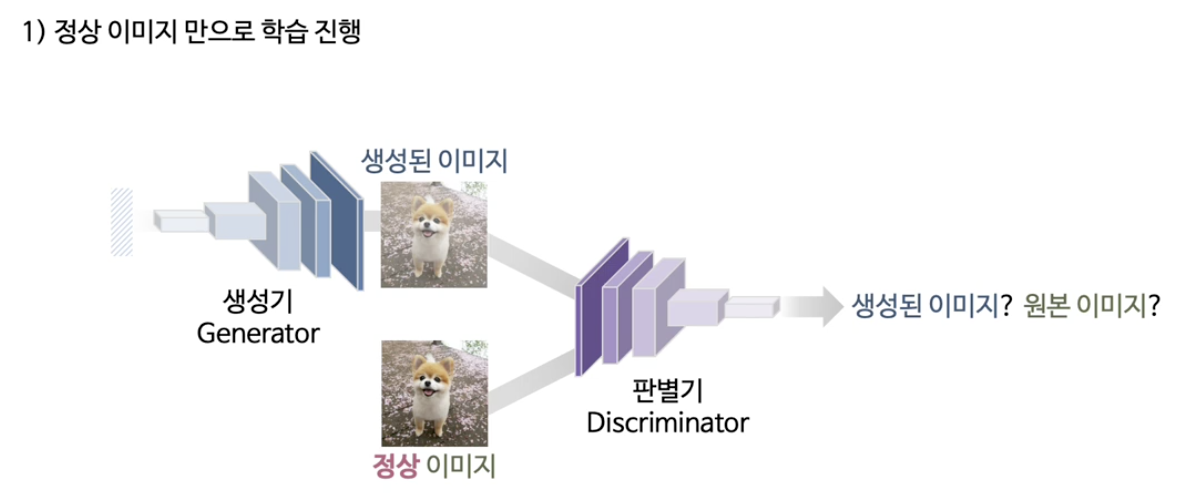
- 정상 데이터로만 GAN 학습
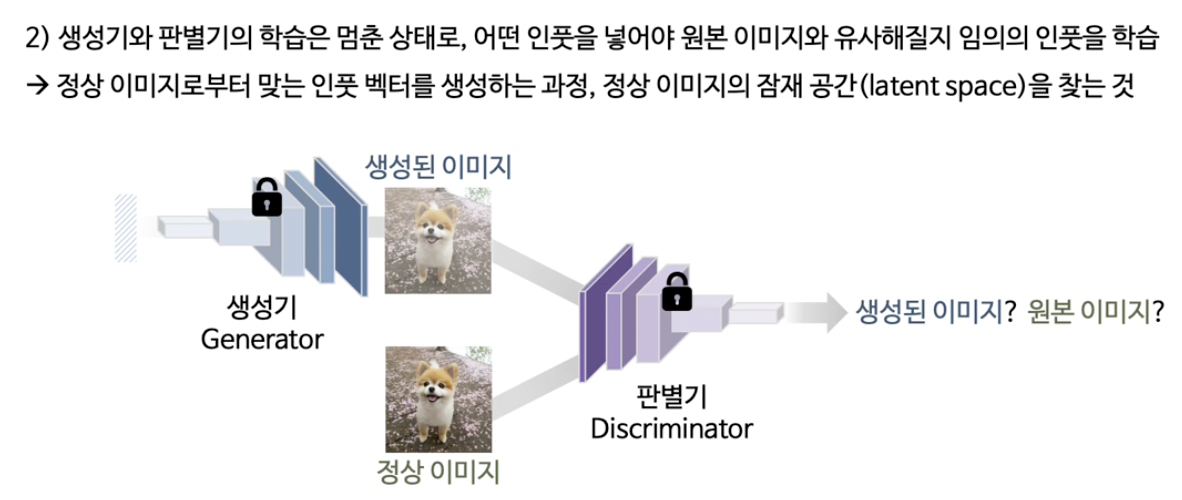
- 테스트 이미지가 주어졌을 때, 그 이미지와 가장 유사한 생성 이미지를 latent space에서 찾아냄
- $z^*=\arg \min _z(\lambda \cdot|x-G(z)|+(1-\lambda) \cdot|f(x)-f(G(z))|)$.
- 재구성 차이나 latent representation 차이로 이상 점수(anomaly score) 계산
- $x$와 $G(z^{*})$ 사이의 차이로 anomaly score 계산

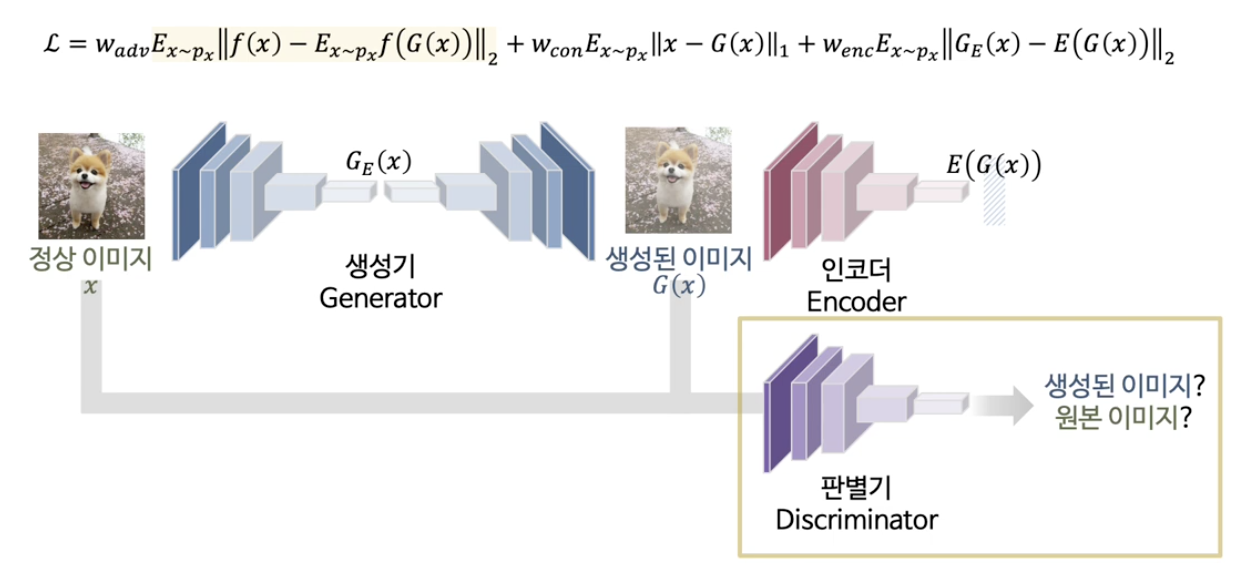
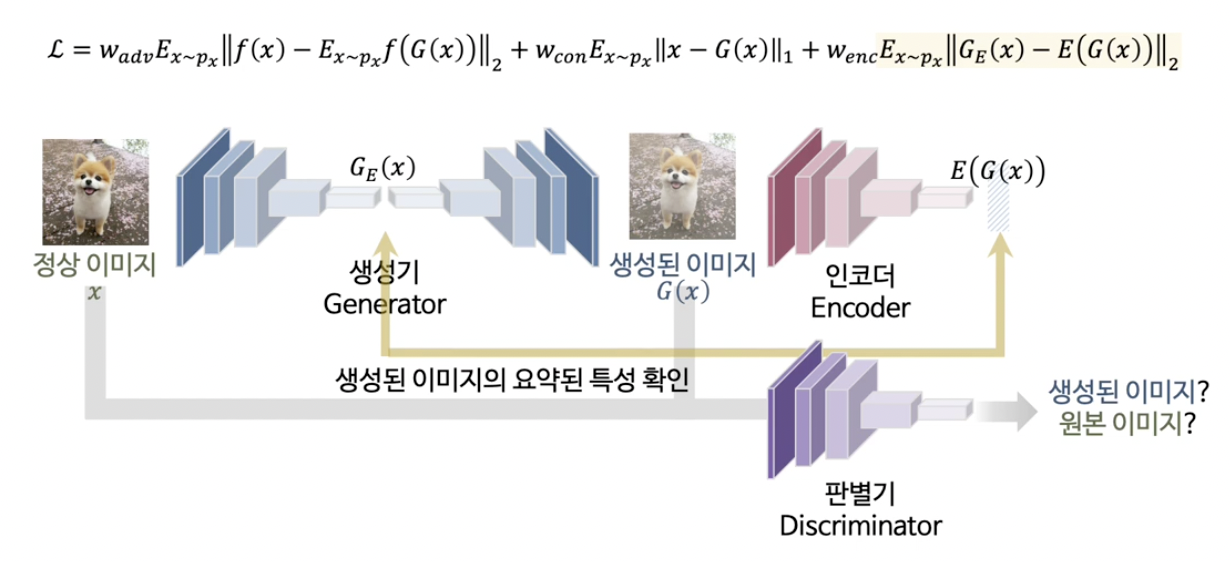
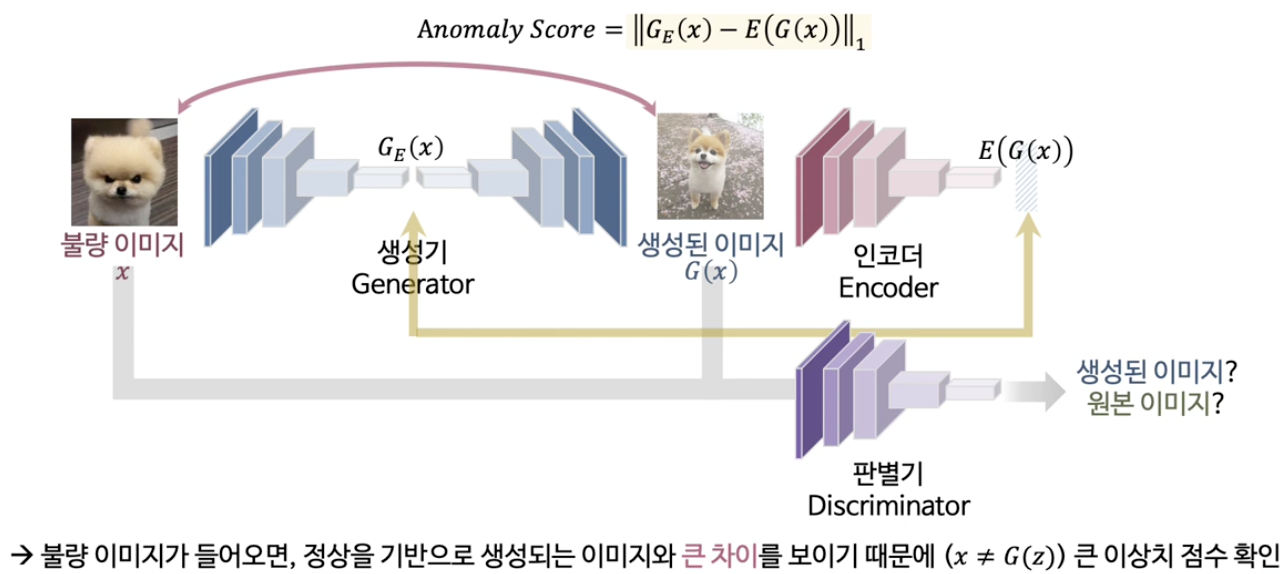
(2) GANomaly
( GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training )
이미지에 대한 학습 & 잠재공간에 대한 학습을 한번에 진행
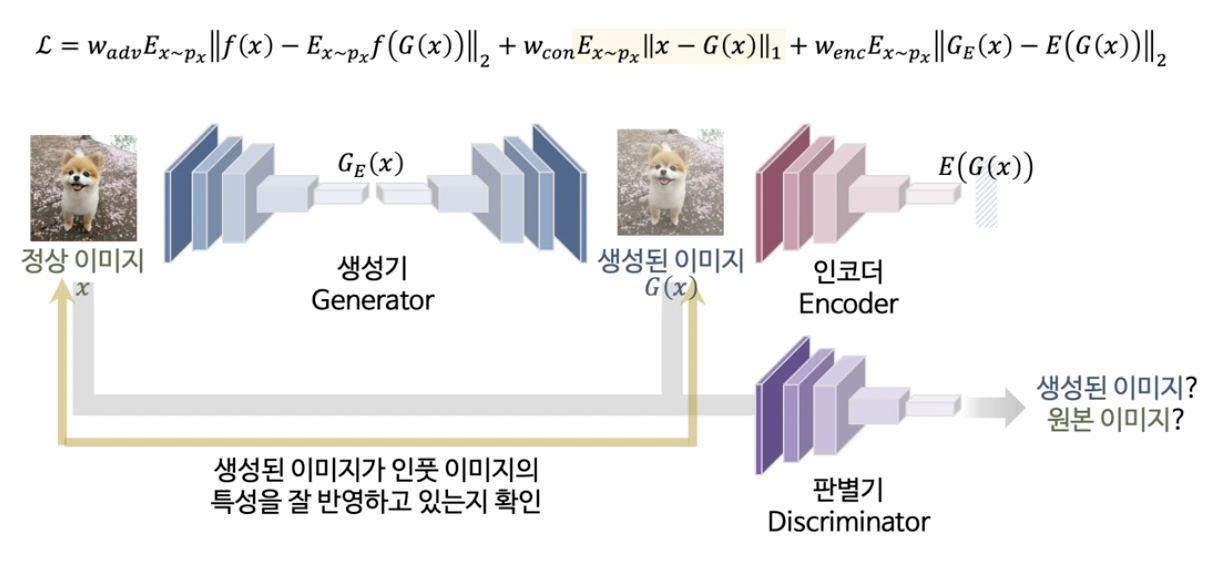
4. SSL-based AD
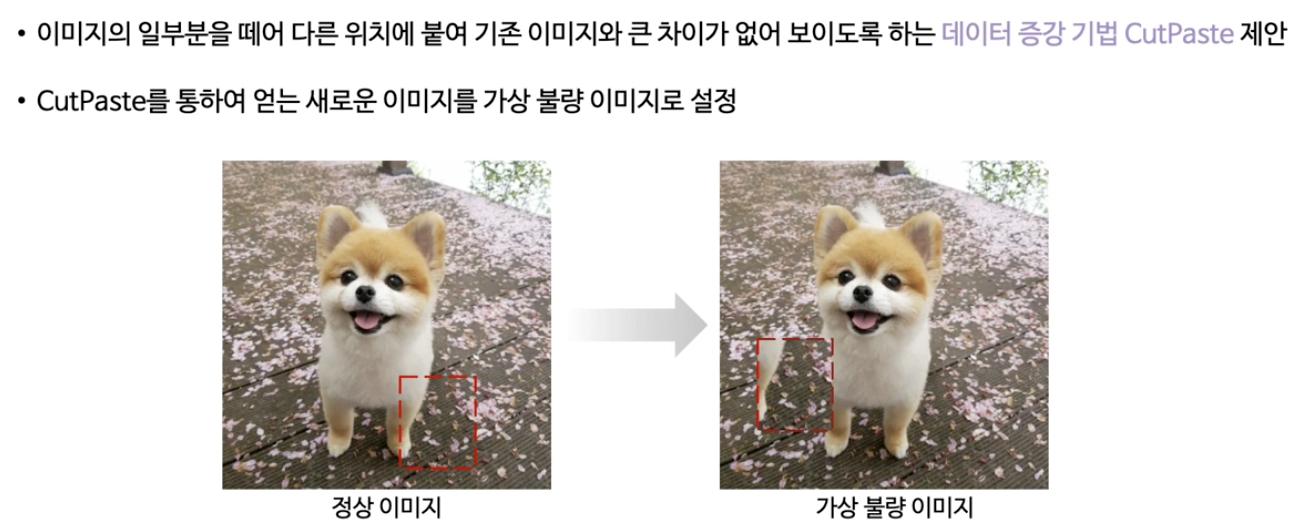
(1) CutPaste
가상 불량 이미지 만들기
Procedure
- Step 1) 정상 & 가상 불량 이미지 구분하는 분류기 학습 (Encoder + projection layer)
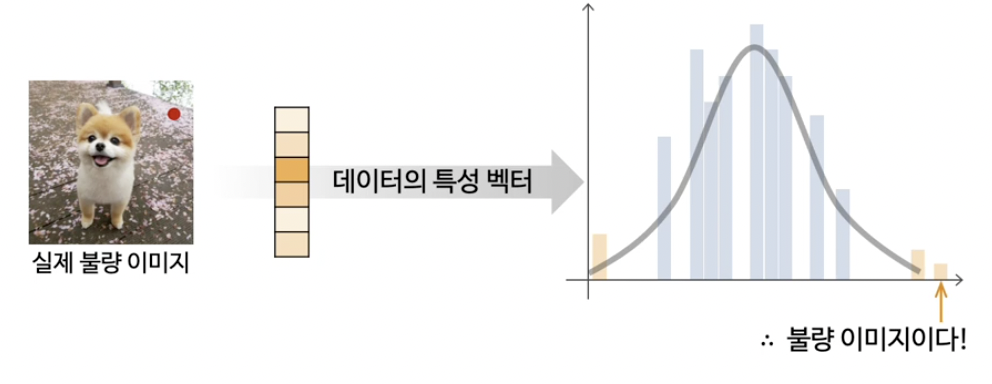
- Step 2) 새로운 데이터를 모델에 적용하여 벡터 추출 (Encoder)
- Step 3) 임베딩 벡터를, Gaussian density estimation
5. Conclusion
https://www.youtube.com/watch?v=Mj_Lapou2SE
1. 이상치의 종류
(1) Pattern 종류
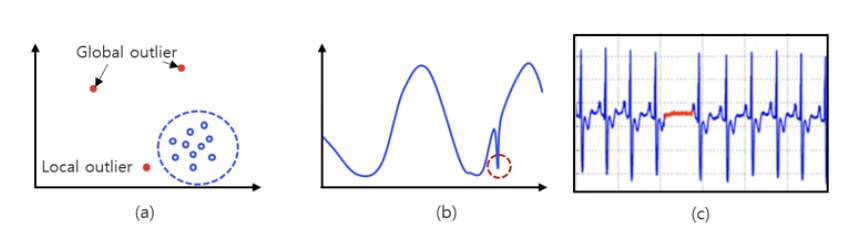
- Point
- Contextual
- Collective
(2) 비교 범위
- Local outlier (LOF)
- Global outlier
(3) Input data type
- Vector outlier: multi-dim으로 이루어진 데이터
- Graph outlier: 데이터 간의 상호의존성을 나타내는 node/edge로 이뤄진 data
2. Data Label 유무에 따른 AD 방법론 분류
- 지도학습
- 반지도 학습
- ex) One-class SVM, Deep SVDD
- 비지도학습
- ex) PCA, AE
3. 고전적인 AD 방법론