
Foundation Models for Time Series; A Survey
https://arxiv.org/pdf/2504.04011
Kottapalli, Siva Rama Krishna, et al. “Foundation Models for Time Series: A Survey.” arXiv 2025
Abstract
Foundation models for TS
-
Architecture design
- Patch-based vs. Directly on raw TS
- Probabilistic vs. Deterministic
- Univariate TS vs. Multivariate TS
-
Lightweight vs. Large-scale
- Type of objective function
1. Introduction
(1) NN for TS Analysis
(2) Transformer Paradigm
(3) Transformer: Foundation Models for TS
2. Background
(1) Unique Characteristics of TS
- Sequential Nature
- Temporal Dependencies
- Multivariate Complexities
- Irregular Sampling & Missing Data
- Noise & Non-Stationarity
- High Dimensionality in Long Sequences
(2) Key Innovations of Transformers
a) Attention mechanism & its role in Sequential data
Attention mechanisms provide the following advantages:
- (1) Long-range dependency modeling
- (2) Dynamic weighting
- (3) Context-aware representations
b) Scalability & Parallelism
- (1) Non-sequential processing
- (2) Efficient handling of long-sequences
- But \(O(n^2)\) complexity \(\rightarrow\) Sparse atetntion, linear Transformer ..
c) Implication for TS modeling
The attention mechanism enables models to …
- (1) Capture complex temporal dynamics
- e.g., seasonality and long-term dependencies
- (2) Scalability ensures that these models remain practical for large-scale datasets
(3) TS Applications

a) TS Forecasting
b) TS Imputation
- Transformer: Excel in learning contextual relationships to infer missing values
- e.g., bidirectional attention, and encoder-decoder frameworks
- TimeTransformer [80]
- Utilize self-attention mechanisms to predict missing data points in multidimensional datasets.
c) Anomaly Detection
-
Transformer: Powerful framework for anomaly detection due to their capacity for learning contextual representations
-
Pretrained models
- Fine-tuned for anomaly detection tasks
- By leveraging embeddings that capture normal behavior patterns
-
Transformer + VAE [84]
-
Transformer + GAN [85]
\(\rightarrow\) Further enhance AD by enabling unsupervised or semi-supervised learning
d) TS Classification
e) Change Point Detection
Task = Identifies moments when the statistical properties of a TS shift
- E.g., Detecting financial market shifts, climate pattern changes, and network traffic anomalies.
f) TS Clustering
(4) FMs for TS
a) Characteristics of FMs
Universal backbone for diverse downstream tasks
[Two-stage process]
- (1) Pretraining
- (2) Fine-tuning
The ability of foundation models to generalize stems from several key properties:
- (1) Task-agnostic pretraining objectives (SSL)
- NSP, MTM, CL ..
- (2) Scalability across domains
- Trained on heterogeneous datasets spanning multiple domains
- Enhances their robustness and transferability to unseen tasks
- (3) Adaptability through fine-tuning
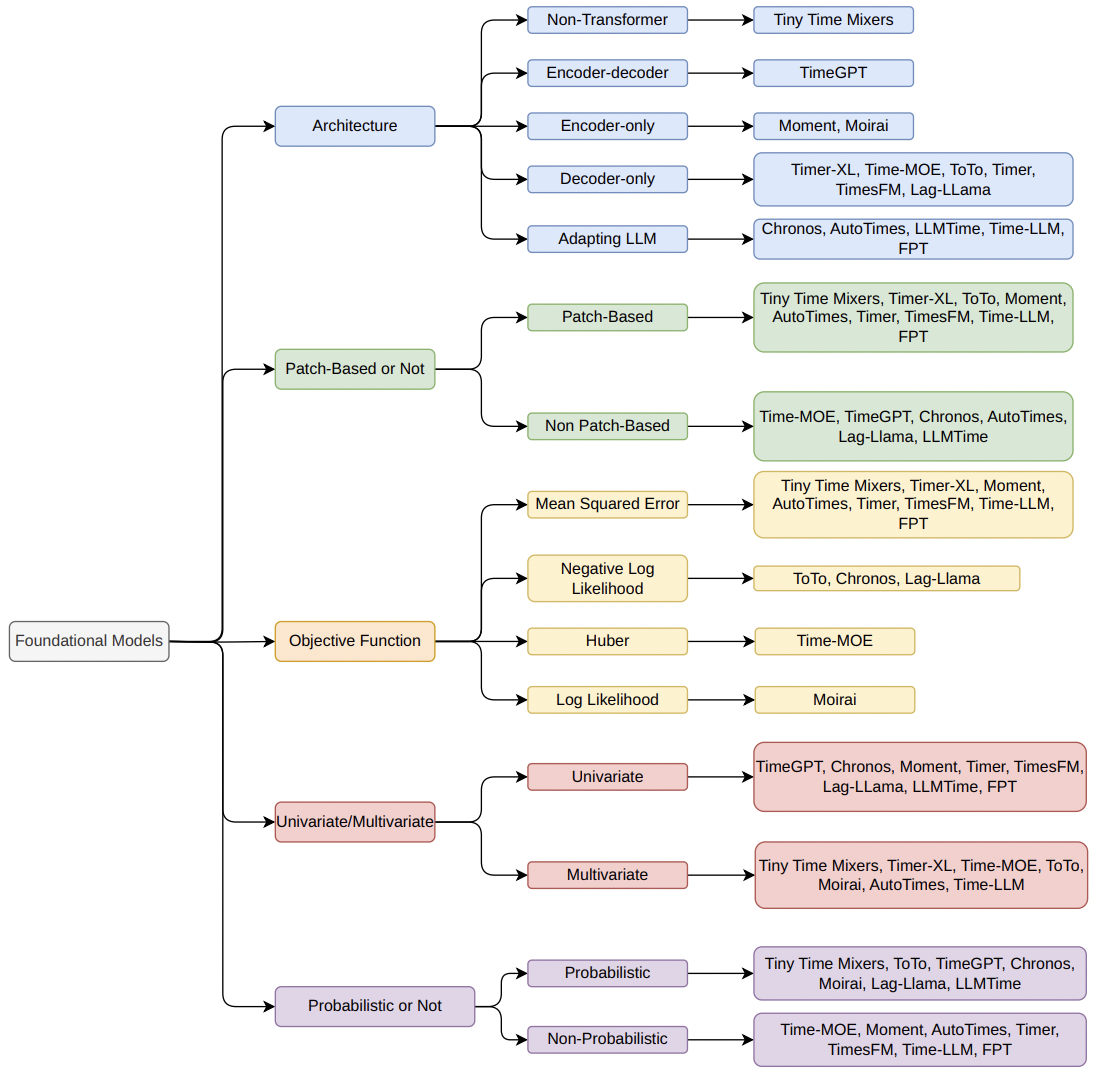
3. Taxonomy
(1) Challenges in analyzing the field
(2) Lack of Detailed Taxonomy
Key dimensions include …
- Model Architecture
- (Transformer) Encoder-only, Decoder-only, Encoder-decoder
- (Non-Transformer) e.g., Tiny Time Mixers (TTM)
- Patch vs. Non-Patch
- (Patch) Capture local temporal patterns before learning global dependencies
- (Non-patch) Capture both short-and long-term dependencies across the full sequence
- Objective Functions
- (MSE) Regression tasks
- (NLL) Probabilistic estimates that improve uncertainty modeling
- UTS vs. MTS
- Probabilistic vs. Non-probabilistic
- Model scale & complexity
4. Methodology
(1) Model Architecture
a) Non-Transformer
Tiny Time Mixers (TTM) (NeurIPS 2024)
(https://arxiv.org/pdf/2401.03955)
Vijay Ekambaram, and others, Tiny Time Mixers (TTMs): Fast Pre-Trained Models
for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series, NeurIPS 2024.
- Based on TSMixer
- Details
- a) Adaptive patching: To handle multi-resolution
- Different layers of the backbone operate at varying patch lengths
- b) Diverse resolution sampling: To augment data to improve coverage across varying temporal resolutions
- c) Resolution prefix tuning: To handle pretraining on varied dataset resolutions with minimal model capacity
- d) Multi-level modeling: Capture channel correlations and infuse exogenous signals during fine-tuning.
- e) Supports channel correlations and exogenous signals
- a) Adaptive patching: To handle multi-resolution
b) Encoder-decoder
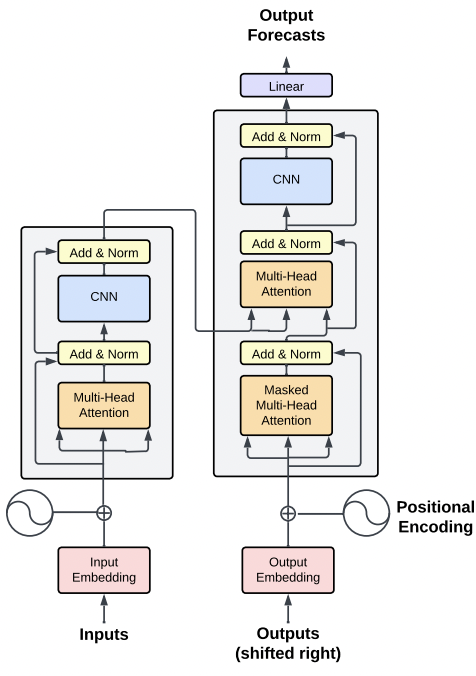
TimeGPT (arxiv 2023)
(https://arxiv.org/pdf/2310.03589)
Azul Garza, Cristian Challu, and Max Mergenthaler-Canseco, TimeGPT-1, arXiv
preprint arXiv, 2023.
- For TS forecasting
- Components from LLMs + CNN
- Details
- [Transformer] Positional encoding & Multi-head attention
- + Residual connections + LN
- [CNN] For learning complex temporal patterns
- [Dataset] Large, diverse time-series datasets
- [Transformer] Positional encoding & Multi-head attention
- Fine-tuned for specific forecasting tasks
- Using zero-shot or few-shot learning methods
c) Encoder-only
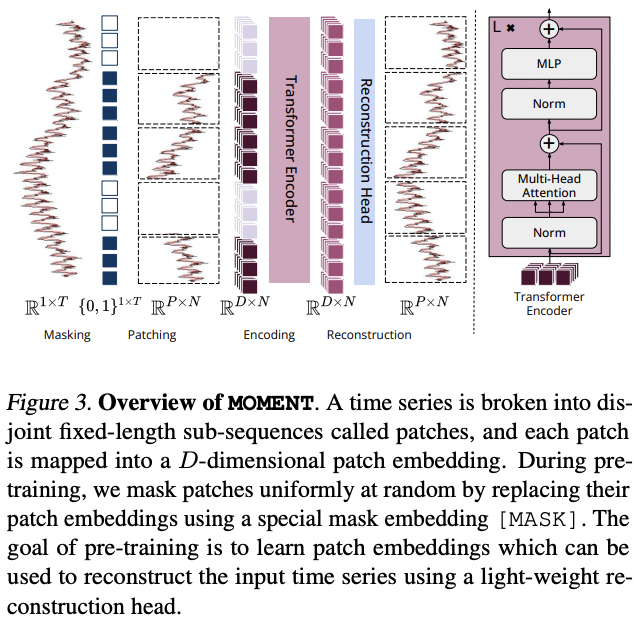
MOMENT (ICML 2024)
(https://arxiv.org/pdf/2402.03885)
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and
Artur Dubrawski, MOMENT: A Family of Open Time-series Foundation Models,
ICML, 2024.
- Details
- [Arch] Patching + Transformer + Relative PE + Instance norm
- [SSL] MTM
- [Dataset] Pretrained on a diverse collection of datasets ( Time Series Pile )
- [Task] Forecasting, anomaly detection, and classification …
- Key features
- Handling variable-length TS
- Scalability through a simple encoder and minimal parameters
- Channel independence
MOIRAI (ICML 2024)
(https://arxiv.org/pdf/2402.02592)
Jacek Cyranka, and Szymon Haponiuk, Unified Long-Term Time-Series Forecasting Benchmark, arXiv preprint arXiv:2309.15946, 2023, https://arxiv.org/abs/2309.
15946
-
Probabilistic MTS forecasting
-
Handle data with varying frequencies and domains
-
Details
-
[Arch] Patching + Transformer
- Pre-normalization, RMSNorm, query-key normalization, and SwiGLU ..
-
[SSL] MTM
-
Trained with a CE loss
\(\rightarrow\) Treating the forecasting task as a regression via classification
-
Dataset: LOTSA
-
-
-
Key features
- Output = Mixture distribution
- Capturing predictive uncertainty
- Including Student’s t-distribution, negative binomial, log-normal, and low-variance normal distributions
- Flexible patch size: To handle different frequencies (based on predefined size)
- Larger patches for high-frequency data
- Smaller ones for low-frequency data.
- Any-variate Attention mechanism
- Flattens MTS into a single sequence
- Output = Mixture distribution
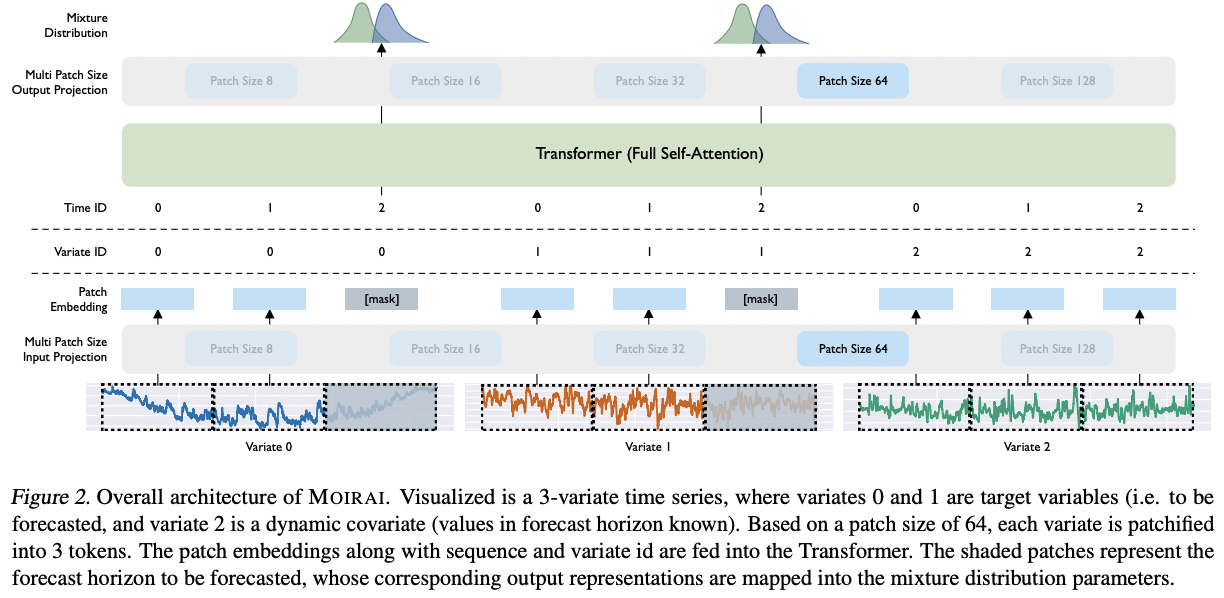
d) Decoder-only
Timer-XL (ICLR 2025)
(https://arxiv.org/pdf/2410.04803)
Yuxuan Liu, Ganqu Qin, Xiangyang Huang, Jiang Wang, and Mingsheng Long,
Timer-XL: Long-Context Transformers for Unified Time Series Forecasting, arXiv
preprint arXiv:2410.04803, 2024.
- Key innovation: TimeAttention mechanism
- Capture complex dependencies within and across TS
- Incorporates both TD& CD via a Kronecker product approach
- Details
- [SSL] NTP
- [UTS & MTS]
- For UTS
- For MTS extends this approach by defining tokens for each variable and learning dependencies between them
- Rotary Position Embeddings (RoPE)
- Capable of handling additional covariates
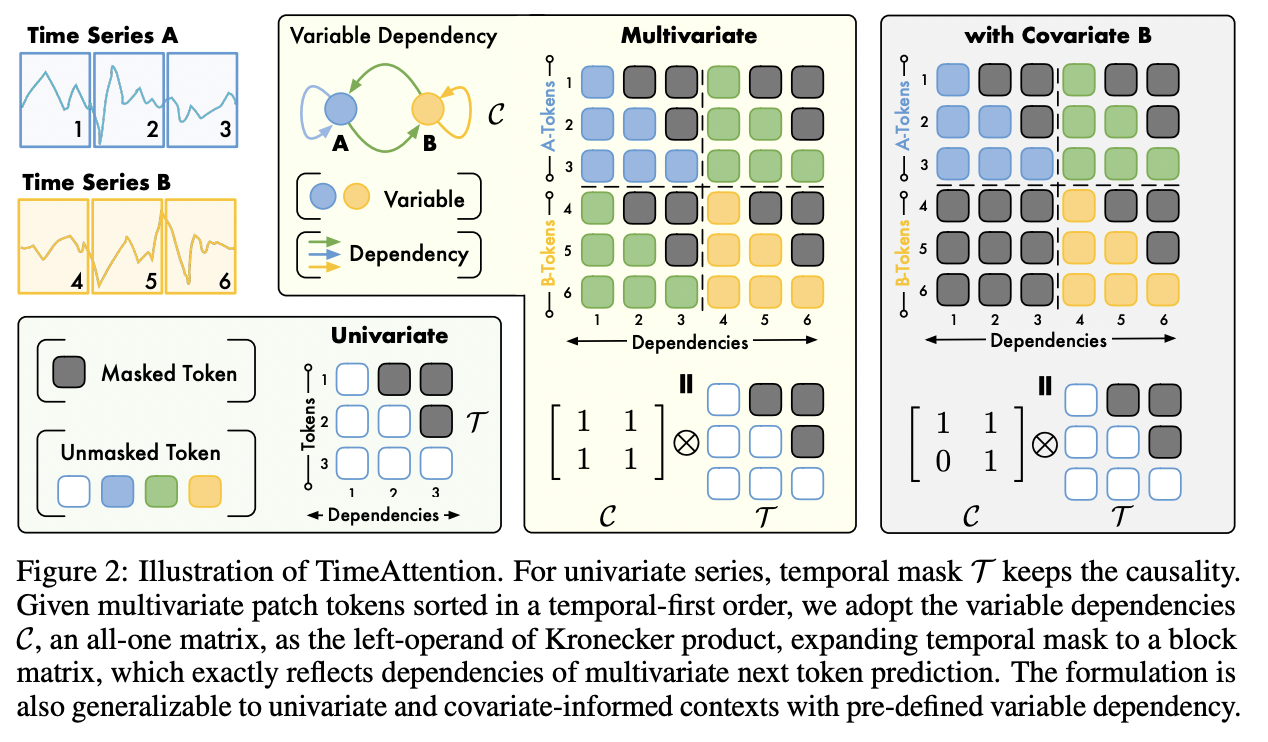
Time-MOE (ICLR 2025)
(https://arxiv.org/pdf/2409.16040)
Xiang Shi, and others, Time-MoE: Billion-Scale Time Series Foundation Models
with Mixture of Experts, ICLR, 2025.
- MoE + Decoder-only
- MoE: Replace FFN with MoE layer
- Details
- Point-wise tokenization: For efficient handling of variable-length sequences
- + SwiGLU gating to embed time series points.
- Multi-resolution forecasting
- Allowing predictions at multiple time scales (different forecasting horizons)
- Point-wise tokenization: For efficient handling of variable-length sequences
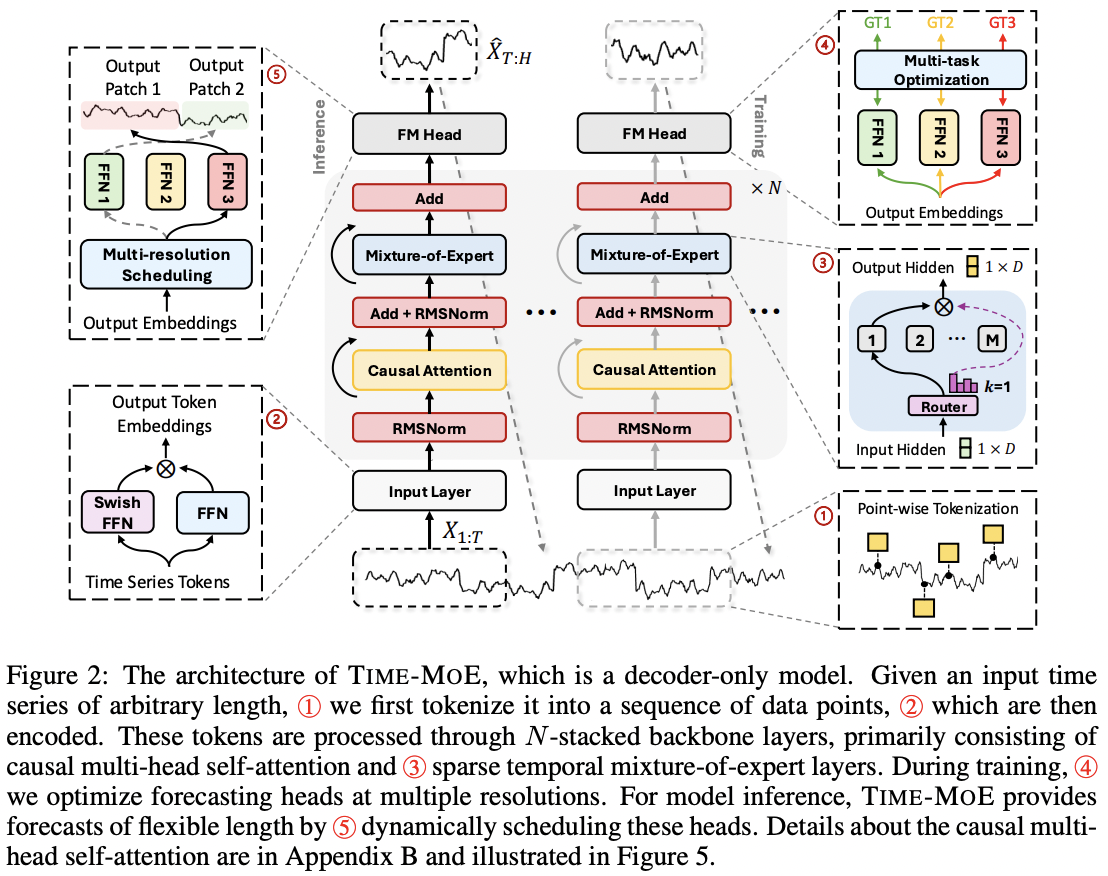
Toto
(https://arxiv.org/pdf/2407.07874)
Ben Cohen, Emaad Khwaja, Kan Wang, Charles Masson, Elise Ramé, Youssef
Doubli, and Othmane Abou-Amal, Toto: Time Series Optimized Transformer for
Observability, arXiv preprint arXiv:2407.07874, 2024, https://arxiv.org/abs/2407.
07874.
- For MTS forecasting \(\rightarrow\) Handle both TD & CD
- Decoder-only model
- Details
- [SSL] NTP
- Probabilistic prediction head: Student-T Mixture Model (SMM)
- Handle heavy-tailed distributions and outliers
- Quantify uncertainty through Monte Carlo sampling
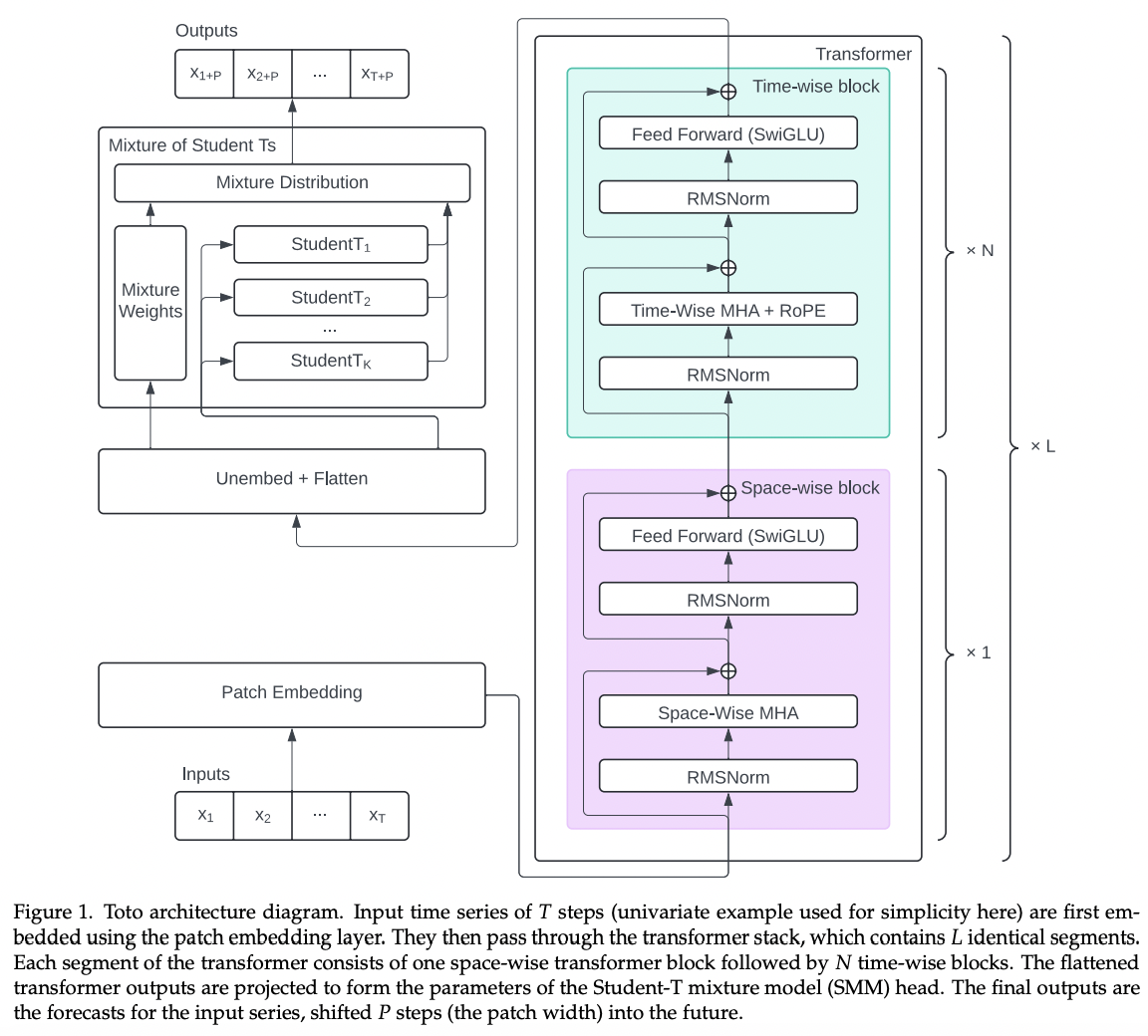
Timer (ICML 2024)
(https://arxiv.org/pdf/2402.02368)
Yuxuan Liu, Hao Zhang, Chenhan Li, Xiangyang Huang, Jiang Wang, and
Mingsheng Long, Timer: Generative Pre-Trained Transformers Are Large Time
Series Models, ICML, 2024.
- Decoder-only model
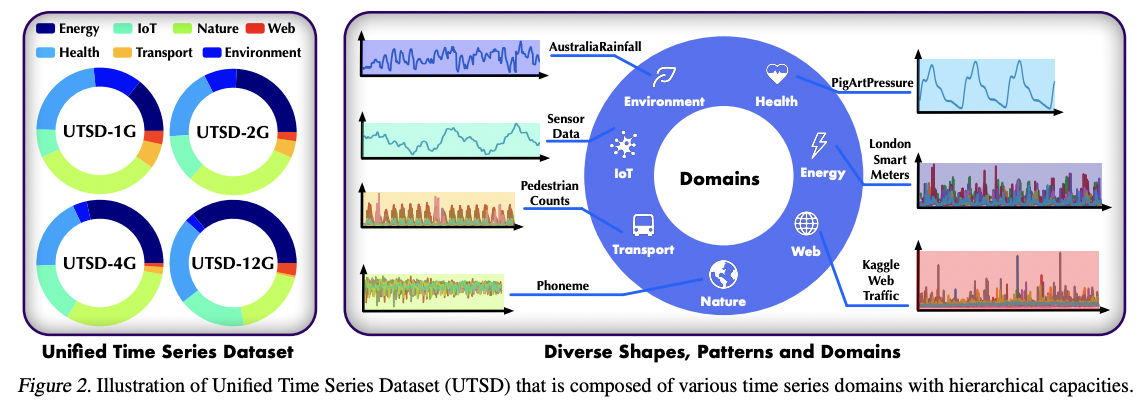
- Dataset 1: Unified Time Series Dataset (UTSD)
- Up to 1 billion time points across seven domains
- Dataset 2: Large-scale Open Time Series Archive (LOTSA)
- Over 27B observations across nine domains
- For zero-shot forecasting
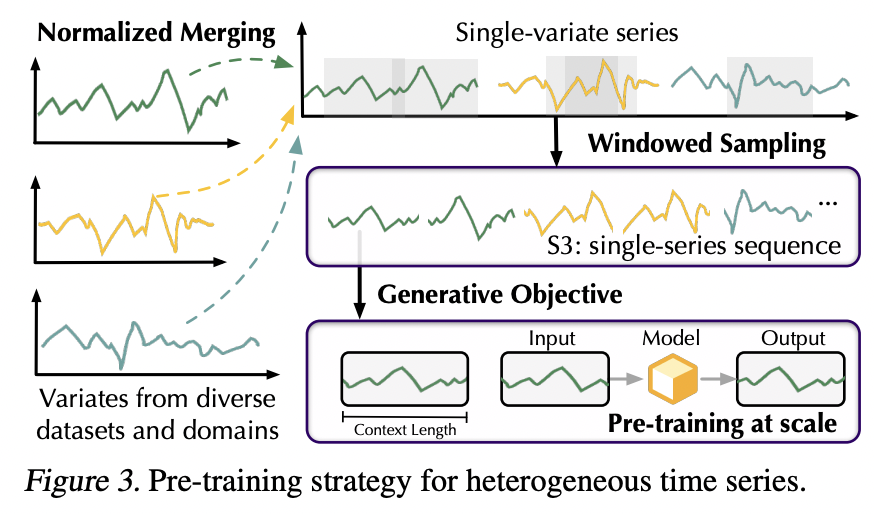
- Single-series sequence (S3)
- Unified format to handle diverse time series data
- For easier preprocessing and normalization w/o the need for alignment across domains
- Pretraining task
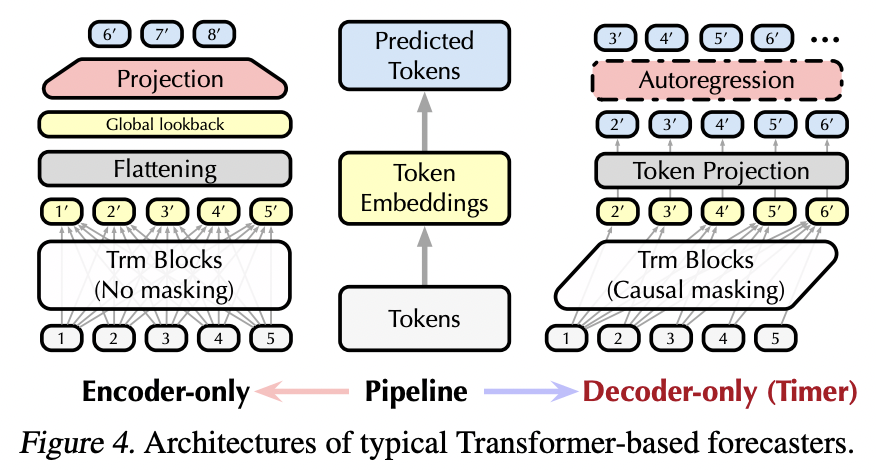
- Decoder-only \(\rightarrow\) Autoregressive Generative pre-training
Timer
UTSD
S3
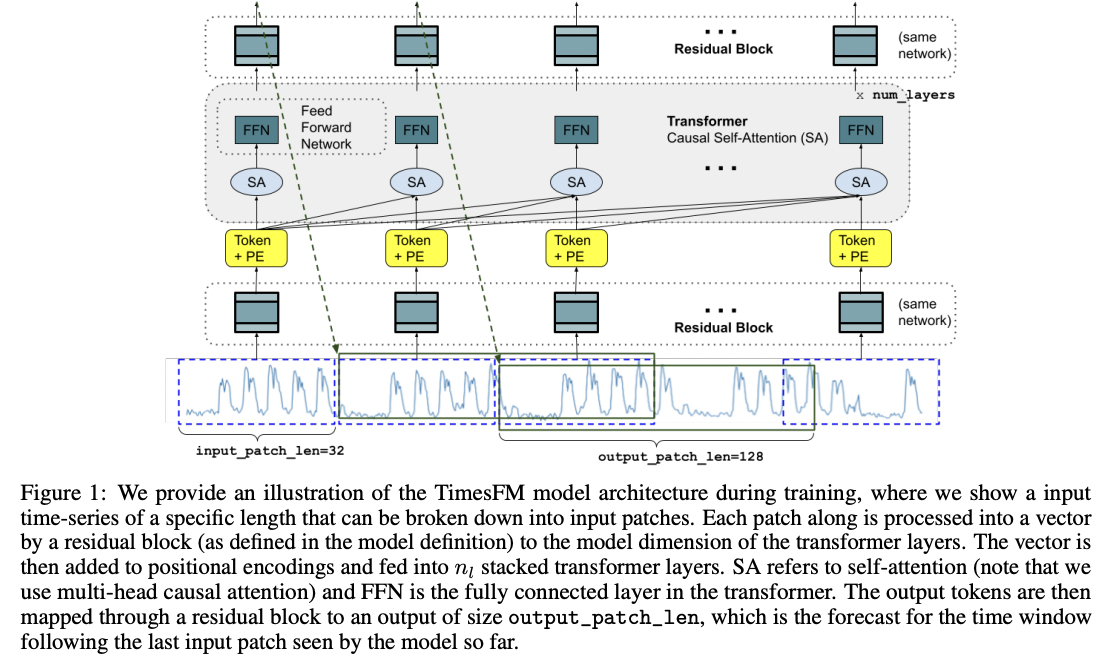
TimesFM (ICML 2024)
(https://arxiv.org/pdf/2310.10688)
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou, A decoder-only
foundation model for time-series forecasting, ICML, 2024.
- Patchify TS
- Decoder-only architecture
- [SSL] Next Patch Prediction
- Random masking strategy
- To handle variable context (input) lengths
- Summary: Flexibility in forecast horizons and context lengths
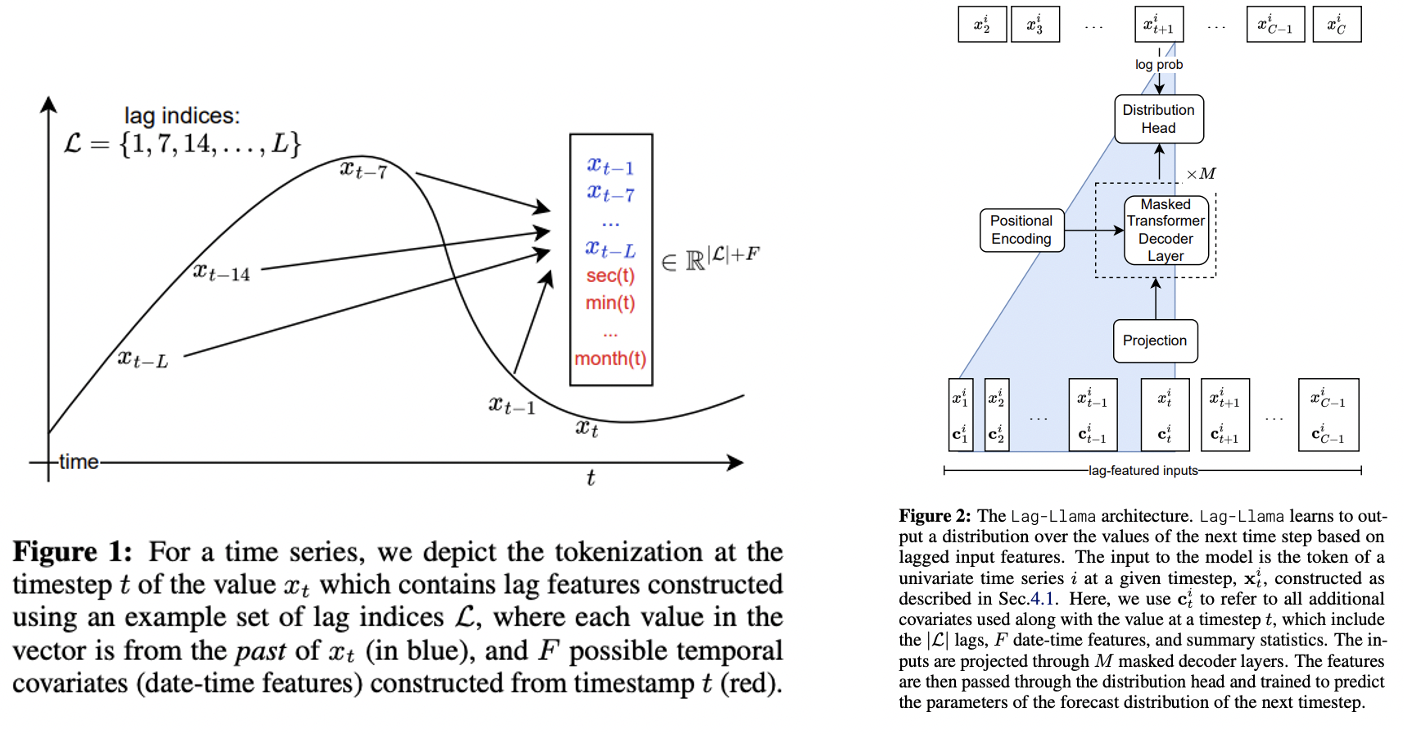
Lag-LLaMA
(https://arxiv.org/pdf/2310.08278)
Kashif Rasul, and others, Lag-Llama: Towards Foundation Models for Time Series
Forecasting, R0-FoMo:Robustness of Few-shot and Zero-shot Learning in Large
Foundation Models, 2023, https://openreview.net/forum?id=jYluzCLFDM.
-
Univariate probabilistic TS forecasting
-
Based on LLaMA
- Decoder-only Transformer with causal masking
- Rotary Positional Encoding (RoPE)
-
Specialized tokenization scheme: Includes ..
- (1) Lagged features (past values at specified lags)
- (2) Temporal covariates (e.g., day-of-week, hour-of-day)
\(\rightarrow\) Handle varying frequencies
-
Probabilsitic forecasting
-
Output is passed through a distribution head
( Predicts the parameters of a probability distribution )
-
- Loss function: NLL
- Inference: Multiple forecast trajectories through autoregressive decoding
e) Adapting LLM
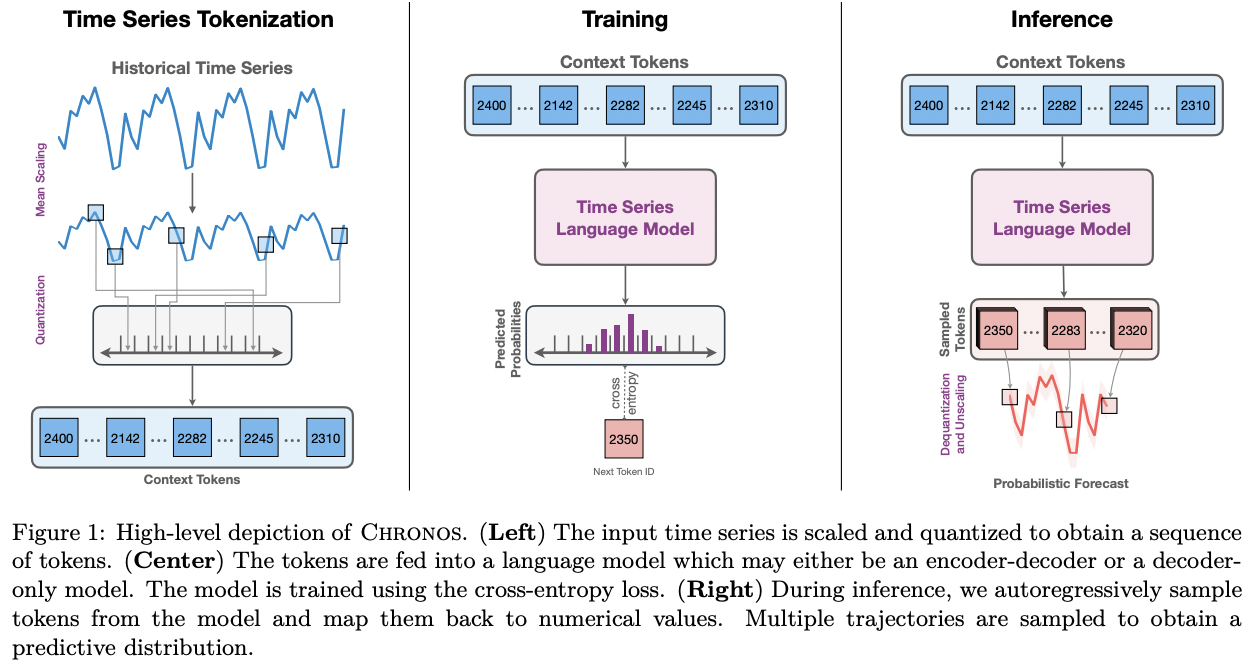
Chronos
(https://arxiv.org/pdf/2403.07815)
Ahmed F. Ansari, and others, Chronos: Learning the Language of Time Series,
arXiv preprint, 2024, https://arxiv.org/abs/2403.07815.
- Adapts LLM for probabilistic TS forecasting
- Novel tokenization approach
- Continuous TS \(\rightarrow\) Discrete tokens
- Step 1) Scaling the data (using mean normalization)
- Step 2) Quantizing it through a binning process
- Values are assigned to predefined bins
- Loss function: CE loss \(\rightarrow\) Learn multimodal distributions
- Base model:
- T5 (encoder-decoder model)
- (But can also be adapted to decoder-only models )
- Architecture remains largely unchanged from standard language models
- Minor adjustmnets
- Vocabulary size to account for the quantization bins
- Pretraining task: Autoregressive probabilistic predictions
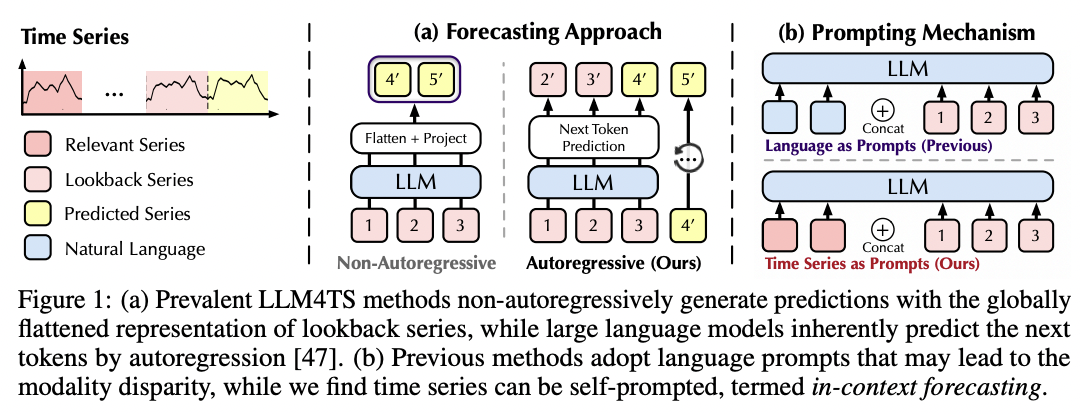
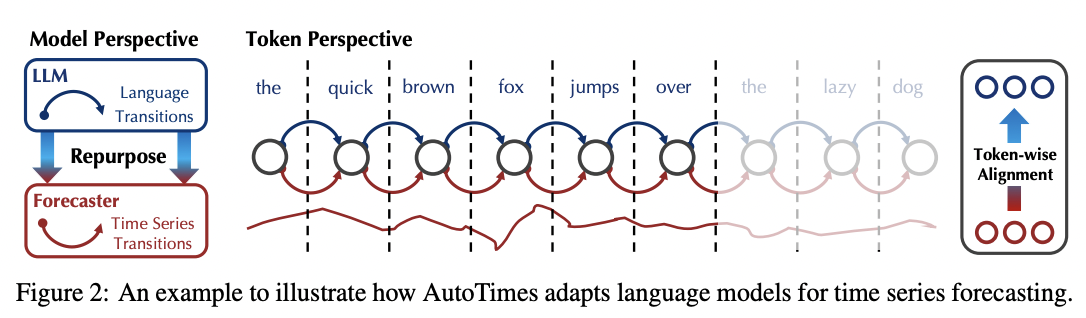
AutoTimes
(https://arxiv.org/pdf/2402.02370)
Yuxuan Liu, Ganqu Qin, Xiangyang Huang, Jiang Wang, and Mingsheng Long,
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models,
arXiv preprint arXiv:2402.02370, 2024.
- Adapts LLMs for MTS forecasting
- Patchify TS
- Each segment = Single variate (treated independently)
- Timestamp position embeddings
- Pretraining task: Next token prediction
- Handle varying lookback & forecast lengths
- (Summary) Key innovations
- Segment-wise tokenization
- Timestamp embeddings for temporal context
- Autoregressive multi-step forecasting

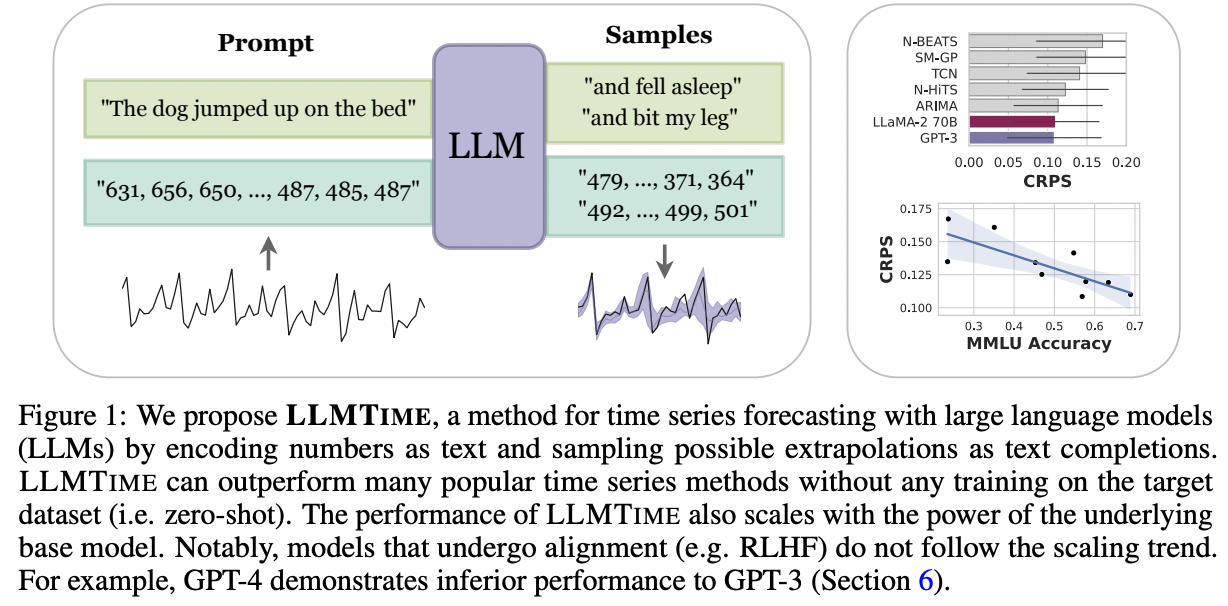
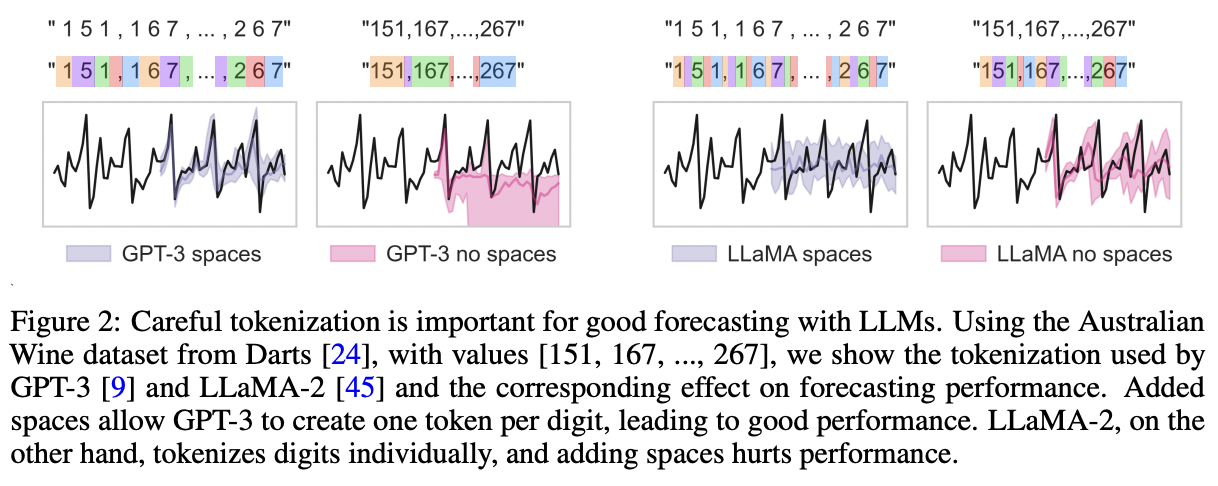
LLMTime
(https://arxiv.org/abs/2310.07820)
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew Gordon Wilson, Large
Language Models Are Zero-Shot Time Series Forecasters, NeurIPS 2023.
- Pretraining task: Next-token prediction
- TS = String of numerical digits
- Each time step = Individual digits separated by spaces
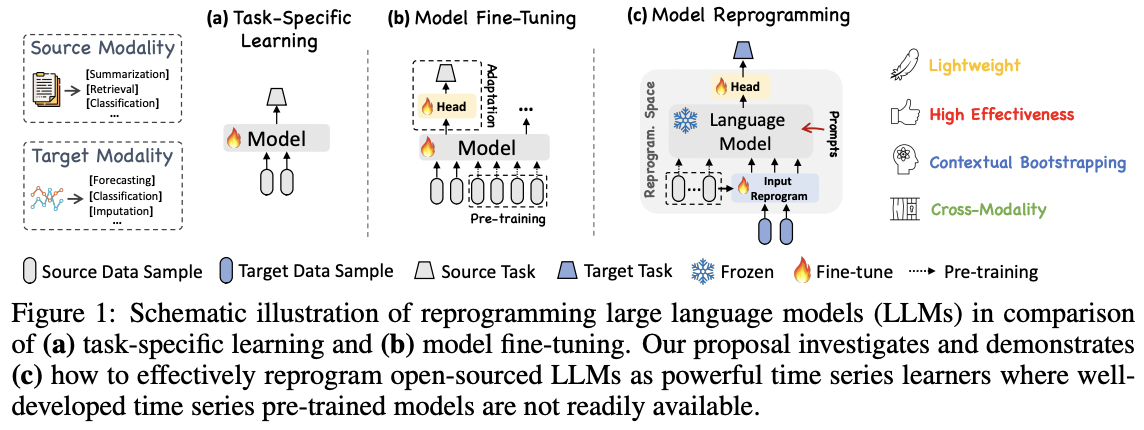
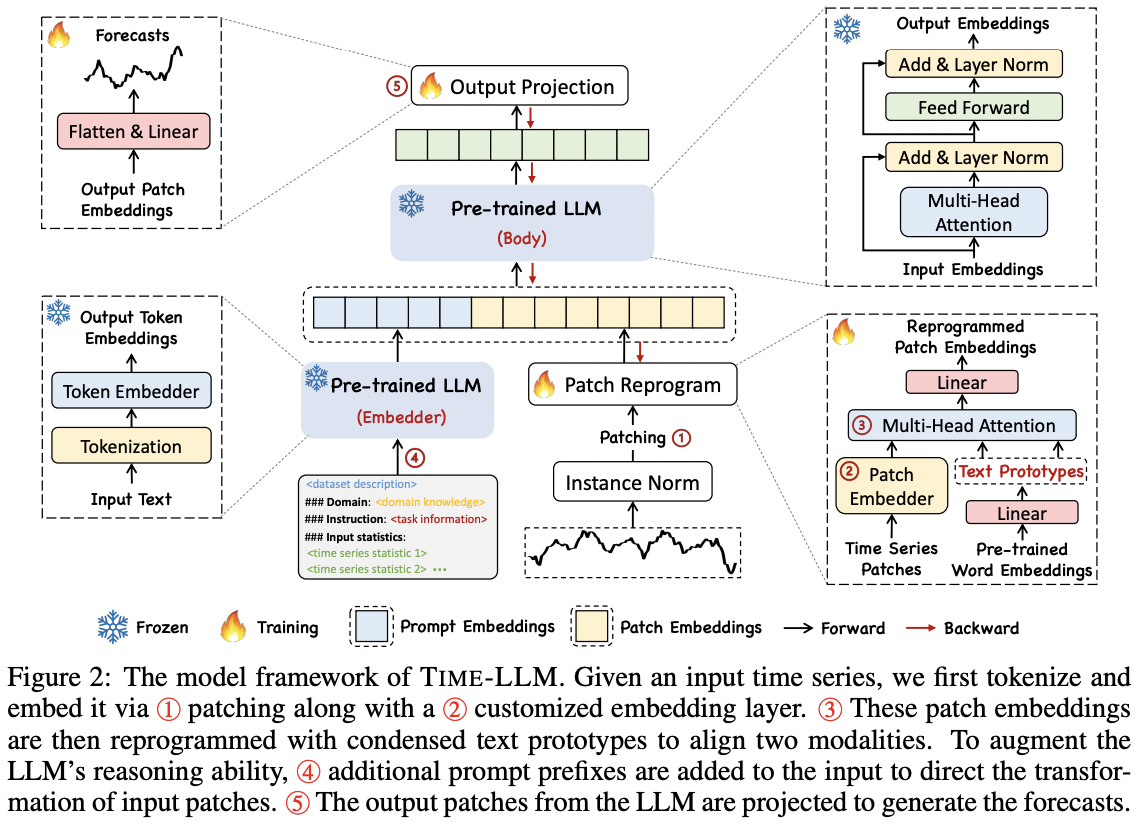
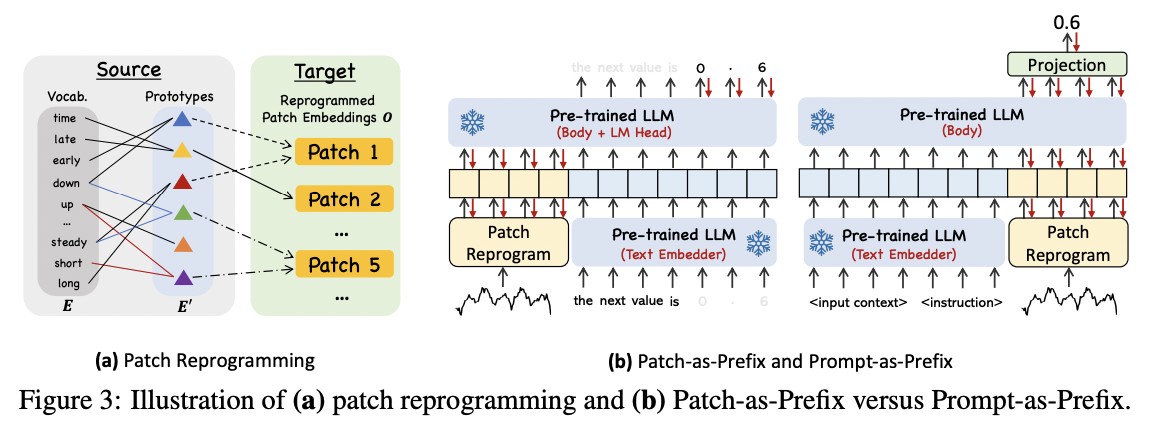
TIME-LLM
(https://arxiv.org/pdf/2310.01728)
Mingyu Jin, and others, Time-LLM: Time Series Forecasting by Reprogramming
Large Language Models, ICLR 2024.
-
Reprogramming framework
- Adapts LLM to TS forecasting, w/o fine-tuning the backbone
-
Transforming TS into text prototype representations
-
Input TS : Before being reporgrammed with learned text prototypes…
- Univarate TS + normalized, patched, embedded
-
Prompts: Augmented with domain-specific prompts
-
Architecture
- Frozen LLM
- Only the input transformation and output projection parameters updated
\(\rightarrow\) Allow for efficient few-shot and zero-shot forecasting

Frozen Pretrained Transformer (FPT)
(https://arxiv.org/pdf/2103.05247)
Kevin Lu, Aditya Grover, Pieter Abbeel, and Igor Mordatch, Frozen Pretrained
Transformers as Universal Computation Engines, AAAI 2022
- Leverages pre-trained language or vision models
- e.g., GPT [58], BERT [96], and BEiT [138]
- Freeze vs. Fine-tuning
- [Freeze] Self-attention and FFN
- [Fine-tune] Positional embedding, layer normalization, output layers
- Redesigned input embedding layer to project TS data into the required dimensions, employing linear probing to reduce training parameters

(2) Patch vs. Non-Patch
a) Patch-based
-
Tiny Time Mixers
- Non overlapping windows as patches during pre-training phase
-
Timer-XL
- Patch-level generation based on long-context sequences for MTS forecasting
-
Toto
- Pre-trained on the next patch prediction
-
MOMENT
- Dividing TS into fixed-length segments, embedding each segment
- Pretrain with MTM
-
MOIRAI
- Patch-based approach to modeling time series with a masked encoder architecture
-
AutoTimes
- Each segment representing a single variate ( = Treated as individual tokens )
- Capture inter-variate correlations while simplifying the temporal structure for the LLM
-
Timer
-
TS is processed as single-series sequences (S3)
= Each TS as a sequence of tokens
-
- TimesFM
- Input TS is split into non-overlapping patches
- TIME-LLM
- Divite MTS into univariate patches
- Reprogrammed with learned text prototypes
- Frozen Pretrained Transformer (FPT)
- Patching
b) Non Patch-based
Time-MOE
- Point-wise tokenization
TimeGPT
Chronos
- Discretizing the TS values into bins rather than splitting the data into fixed-size patches
Lag-LLaMA
- Does not use patching or segmentation
- Rather, tokenizes TS data by incorporating lagged features and temporal covariates
- Each token = Past values at specified lag indices + Additional time-based features
LLMTime
-
TS as a string of numerical digits
( = Treating each time step as a sequence of tokens )
(3) Objective Functions
a) MSE
- Tiny Time Mixers
- Timer-XL
- MOMENT
- AutoTimes
- Timer
- TimesFM
- TIME-LLM
- Frozen Pretrained Transformer (FPT)
b) Huber Loss
( by Time-MOE )
Combines the advantages of MSE & MAE
\(L_{\delta}(r) = \begin{cases} \frac{1}{2} r^2 & \text{if} \ \mid r \mid \leq \delta \\ \delta ( \mid r \mid - \frac{1}{2} \delta) & \text{if} \ \mid r \mid > \delta \end{cases}\).
where:
- \(\delta > 0\) is a user-defined threshold.
- If the residual is small (\(\mid r \mid \leq \delta\)), it behaves like MSE.
- If the residual is large (\(\mid r \mid > \delta\)), it behaves like MAE but transitions smoothly.
Summary
- For small errors, it uses the squared error (sensitive to small deviations).
-
For large errors, it switches to absolute error (robust to outliers).
- Improve robustness to outliers and ensure stability during training
c) LL & NLL
- Toto
- Chronos
- Lag-LLaMA
- MOIRAI
- LLMTime (only training, no pretraining in LLMTime)
(4) UTS vs. MTS
a) Univariate
TimeGPT & Chronos & MOMENT & Lag-LLaMA
- Only UTS
b) Multivariate
MOMENT & MOIRAI & Frozen Pretrained Transformer (FPT) & Tiny Time Mixers & Time-XL & Time-MOE & Toto & AutoTimes
- Both UTS & MTS
Timer
- Primarily supports UTS
- But can treat MTS by flattening into single sequence! (feat. S3)
TimesFM
- Appears to focus on UTS (no support for MTS)
- But still could theoretically accommodate MTS