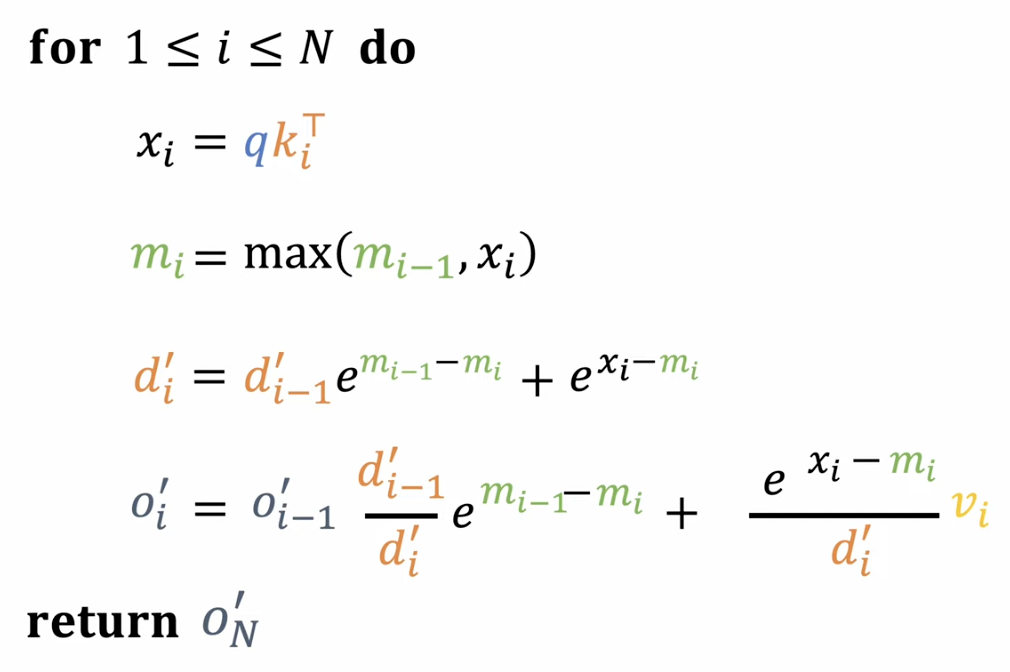[FlashAttention]
-
https://arxiv.org/pdf/2205.14135
-
https://www.youtube.com/watch?v=gBMO1JZav44
Contents
- 개요
- GPU의 구성
- SRAM (Registers, Shared Memory)
- HBM (High Bandwidth Memory, 또는 DRAM)
- 핵심 요약
- 기존의 Attention
- 계산 과정
- GPU 이동
- FlashAttention
- 계산 과정 ex
- Standard Attention vs. Flash Attention
- Appendix
1. 개요
- Attention을 속도와 메모리 효율성 면에서 최적화
- 선수 지식
- (1) Attention mechanism
- (2) GPU 구조
2. GPU의 구성
(1) SRAM (Registers, Shared Memory)
- “GPU 내” 연산 유닛 근처에 위치한 “초고속 메모리”
- 용량은 작지만, 접근 속도가 매우 빠름
- 한 워프(warp)의 쓰레드들이 공동으로 사용하는
shared memory는 FlashAttention에서 적극 활용됨
(2) HBM (High Bandwidth Memory, 또는 DRAM)
- “GPU 외부”에 위치한 “대용량 메모리” (수 GB~수십 GB)
- 속도는 SRAM보다 느리지만 용량이 큼
- 일반적으로 PyTorch 텐서 연산은 이곳에서 수행됨
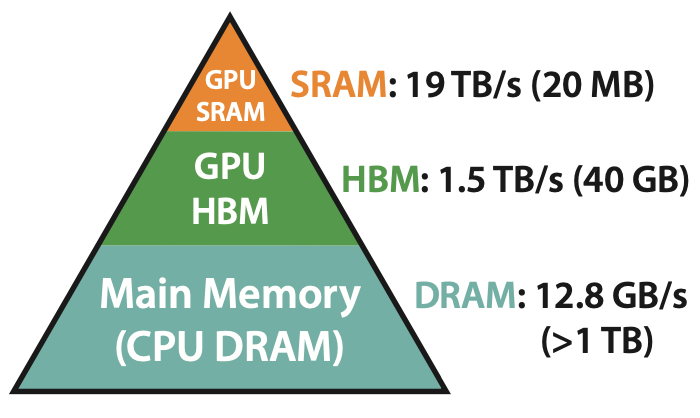
(3) 핵심 요약
GPU에서 연산의 병목은 계산 자체보다도 “데이터 이동(memory access)”!
- HBM(=GPU DRAM): 크지만 느림
- SRAM(=register/shared memory): 작지만 매우 빠름
- → DRAM ↔ 연산기 간 데이터 왕복이 많아지면 성능 급감
데이터 교환
- SRAM & HBM 간의 데이터 교환은 두 attention 방식 모두 일어남.
- But, FlashAttention은 이 교환을 횟수 면에서 압도적으로 줄이기 때문에 훨씬 효율적
3. 기존의 Attention
Attention(Q, K, V) = softmax(QK^T / √d) V
- Q: Query
- K: Key
- V: Value
- d: head dimension
(1) 계산 과정
QKᵀ 계산: (L × d) x (d × L) = L × L
→ 시퀀스 길이 L이 길어질수록 메모리 (O(L²))와 연산량 (O(L²d))이 급격히 증가
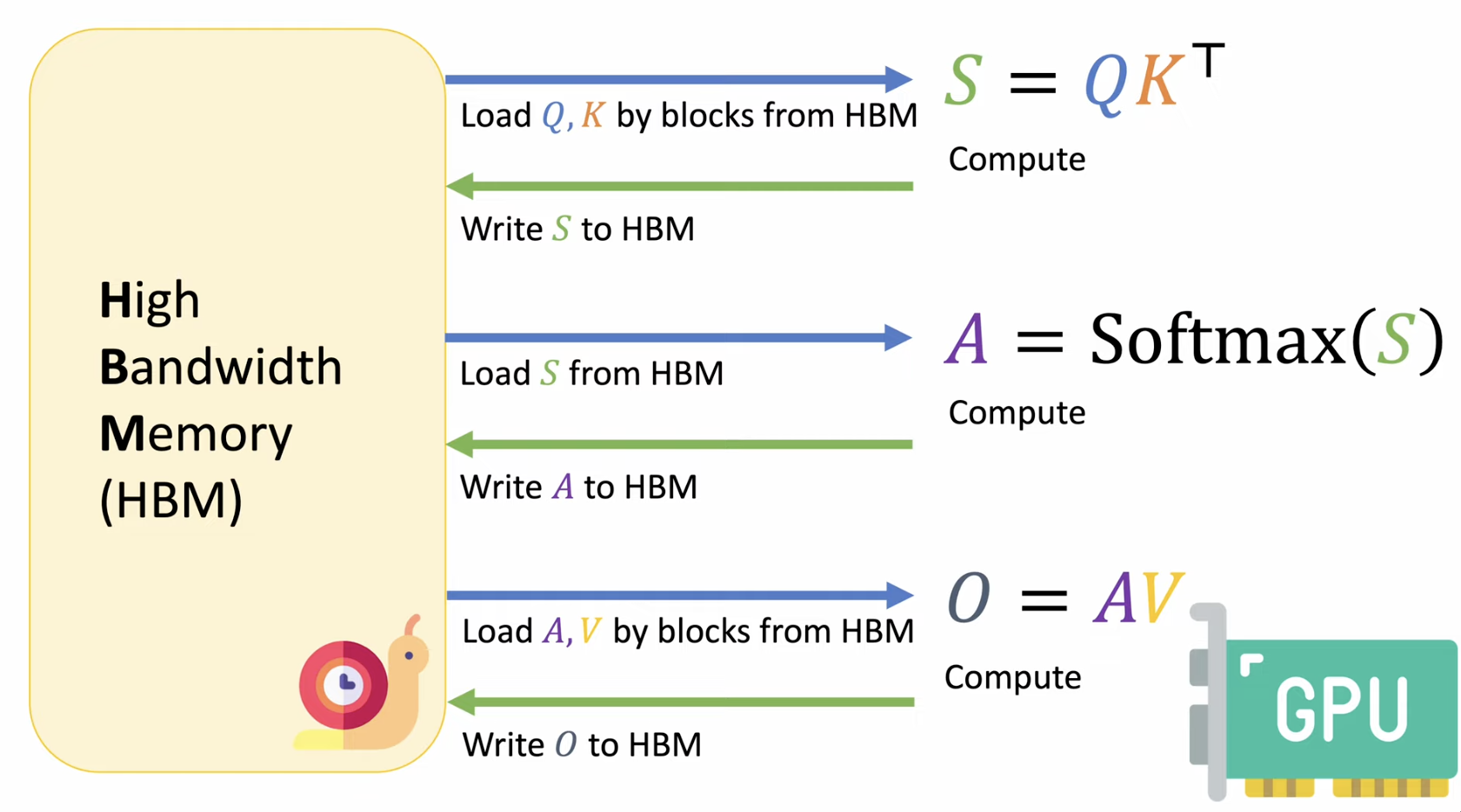
(2) GPU 이동
Ex) QKᵀ를 계산하면 L × L 크기의 행렬이 생기고, 이걸 softmax하고 다시 V와 곱해야함
과정 요약
- Step 1)
Q,K,V: HBM → SRAM- SRAM에서
QKᵀ계산이 이루어짐
- SRAM에서
- Step 2)
QKᵀ: SRAM → HBM- SRAM은 용량이 작아서, HBM에 다시 놔야함
- Step 3)
QKᵀ: HBM → SRAM- softmax 연산을 위해서 다시 SRAM에 불러와야함
- SRAM에서 softmax 연산을 수행함:
A=Softmax(QKᵀ)
- Step 4)
A: SRAM → HBM- SRAM은 용량이 작아서, HBM에 다시 놔야함
- Step 5)
A: HBM → SRAM- output 연산을 위해서 다시 SRAM에 불러와야함
- SRAM에서 output 연산을 수행함 =
O=AV
- Step 6)
O: SRAM → HBM- 최종 output을 HBM에 저장함.
두 줄 요약:
-
(1) 중간 결과가 너무 커서 계속 HBM과 왕복해야!
\(\rightarrow\) HBM read/write에 시간 대부분을 낭비함
-
(2) 연산보다, 메모리 이동에 시간이 더 걸림 (메모리 병목)
4. FlashAttention
핵심: 연산을 블록 단위로 잘게 쪼개서, 작은 부분만 SRAM에서 처리하고 중간 결과를 HBM에 저장하지 않음
(1) 계산 과정 ex
- Step 1) Q, K, V를 작은 chunk로 나눔 (예: 128개 토큰 단위)
- Step 2) 각 chunk 단위로
QKᵀ, softmax,softmax × V까지 모두 SRAM 안에서 수행 - Step 3) Softmax normalization도 누적 방식으로 처리해 정확도 손실 없음
- Step4 결과만 HBM에 한 번 저장
세 줄 요약
- (1) 필요한 데이터만 최소한으로 가져오고, 중간 결과를 저장하지 않음
- (2) HBM ↔ SRAM 교환 횟수가 훨씬 적음
- (3) 연산기 idle 시간 감소 → 전체 속도 향상
5. Standard Attention vs. Flash Attention
| 항목 | 기존 Attention | FlashAttention |
|---|---|---|
| 연산 방식 | QKᵀ 전체 계산 → softmax → 곱 | 블록별 QKᵀ → softmax → 누적 계산 |
| 중간 결과 저장 | QKᵀ 등 전체 행렬을 HBM에 저장 | 중간 결과 저장 없이 연산 |
| 메모리 사용량 | O(L²) | O(L) (linear) |
| 연산 속도 | 느림 (메모리 병목 발생) | 빠름 (SRAM 중심 계산) |
| 정확도 | 정밀도 그대로 | 동일 (정확도 손실 없음) |
| 시퀀스 길이 확장성 | 제한적 | 매우 효율적 (긴 시퀀스에서도 빠름) |
6. Appendix
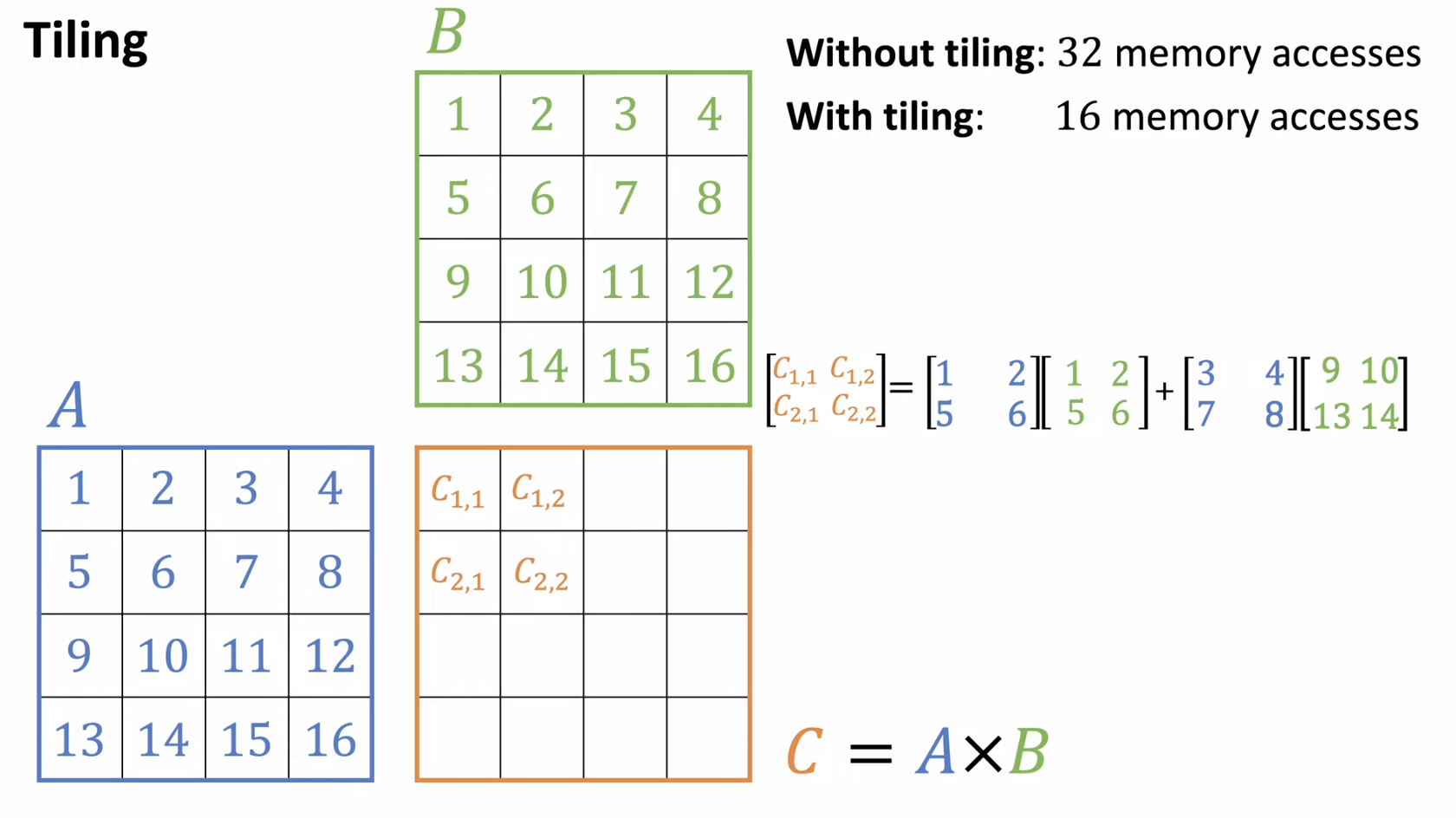
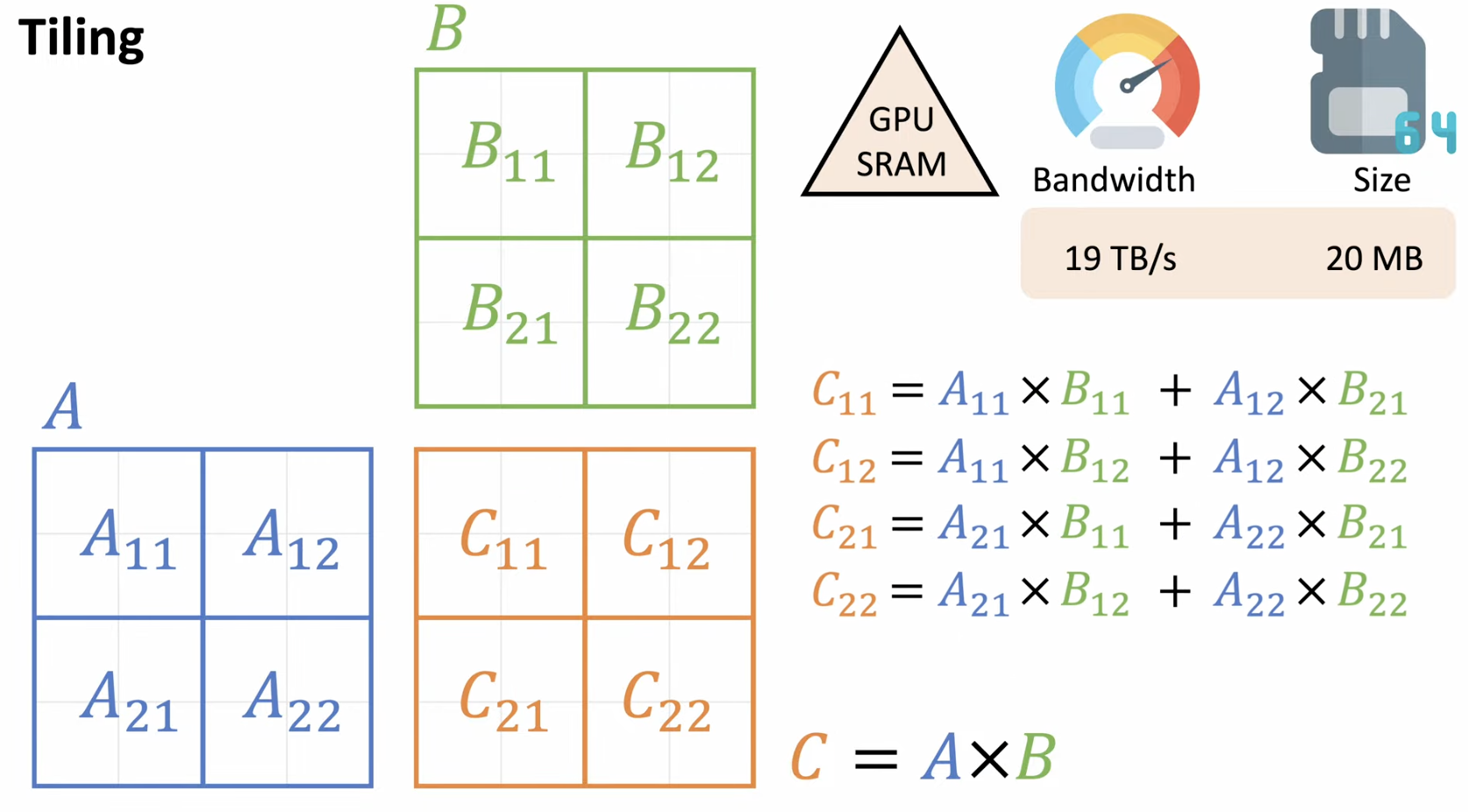
(1) w/o Tiling vs. w/ Tiling
a) w/o Tiling
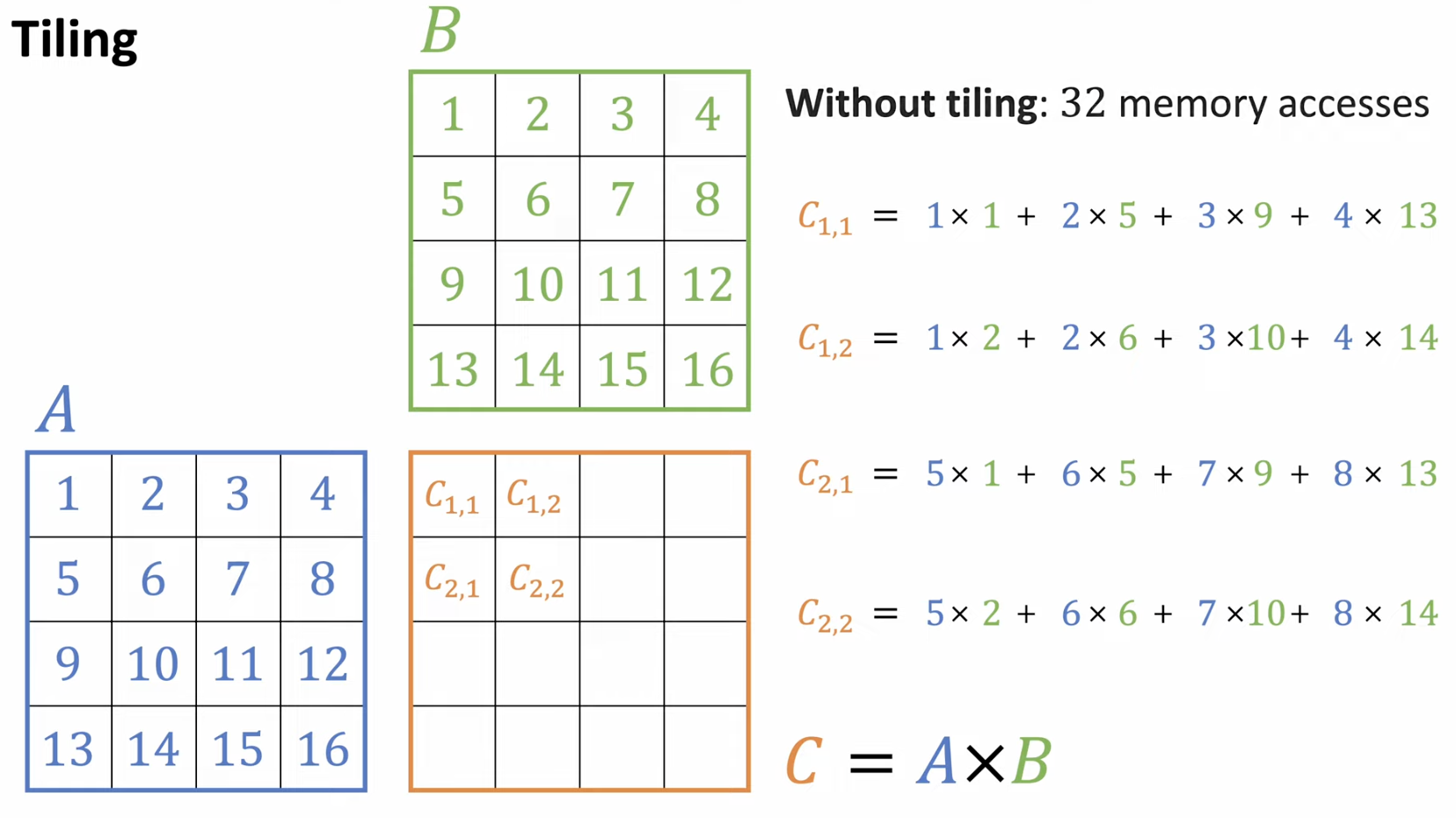
b) w/ Tiling
(2) Online softmax
a) Naive한 Online softmax

For loop을 세번이나 돌아야? 조금 더 efficient하게 할 수 없을까?
b) Efficient한 Online softmax

c) Output도 위와 같은 과정으로!