
Towards Time-Series Reasoning with LLMs
Contents
-
Abstract
-
Introduction
- Related Works
- TS forecasting with LLMs
- TS QA with LLMs
- Methodology
- Architecture
- Training
0. Abstract
Multi-modal LLMs (MLLMs)
\(\rightarrow\) Understanding & Reasoning ! …. But not many in TS domain
Proposal: Novel multi-modal TS LLM approach,
- that learns generalizable information across various domains
- with powerful zero-shot performance
Procedure
- Step 1) Train lightweight TS encoder (on top of an LLM)
- Step 2) Finetune with chain-of-thought augmented TS tasks
1. Introduction
MLLMs
- Enabled numerous advances in reasonining
- Generalization ability to unseen tasks
\(\rightarrow\) But underexplored in TS!
Application of TS reasoning
- health coaching
- financial investing
- environmental monitoring
Three essential steps to achieving TS reasoning:
- (1) Perception: Understanding key characteristics in TS
- (2) Contextualization: Extracting task-relevant features
- (3) Deductive reasoning: Drawing conclusion
Issue of (1): Existing TS MLLMs suffers from perception bottleneck
- Usually convert TS into text tokens \(\rightarrow\) Loss in their ability to recognize temporal patterns
- Reasoning capabilities: can be seen on LARGE models (not on SMALL models)
To effectively recognize temporal patterns:
- Step 1) Train lightweight TS encoder (on top of an LLM)
- Encode various features (e.g., frequency, magnitude)
- To address (1)
- Step 2) Finetune with chain-of-thought augmented TS tasks
- Promotes the learning of reasoning process
- To address (2), (3)
2. Related Work
(1) TS forecasting with LLMs
Pretrained LLMs are typcally used as the backbones
- ( + modules attached to capture properties of TS & align them with LLM )
\(\rightarrow\) Do not retain the “language modeling head” & not designed to “output text”
(2) TS QA with LLMs
(Modality conversion) Representing TS as text
\(\rightarrow\) Result in a loss of information
Previous works
- [13] TS2TS > TS2Text
- [4] Develop a dataset to asses general TS reasoning
3. Methodology
(1) Architecture
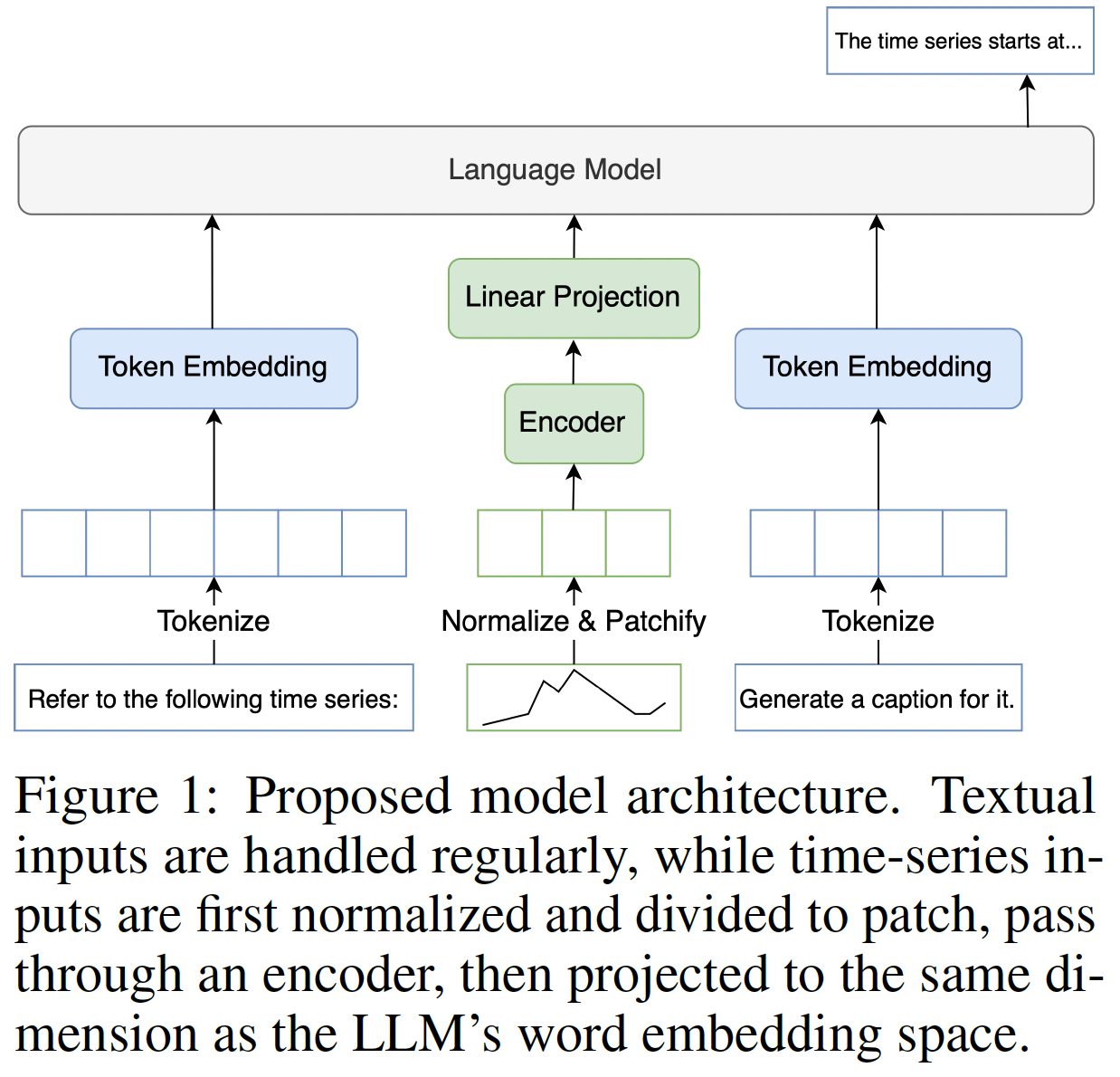
Component 1) for TS
- 1-1) Encoder: MHSA
- 1-2) Linear projection: to match dimension of LLM’s word embedding
- Etc
- Non-overlapping patch
- (Mean & Std) are prepended in front of TS token
Component 2) for Text
- Concatenate (text embedding) & (TS embedding)
- LLM backbone: Mistral-7B
The above design offers significant flexibility in handling varying input formats
- (1) Freely interleaving TS & Text
- (2) Handle multiple different TS
- e.g.) 3 channel TS: feed them sequentially & add text embedding describing the channel index
(2) Training
a) Dataset: Public TS datasets + Synthetic TS
b) Language model tasks: generated from a mix of predefined templates or via GPT-40
- each task’s instruction includes 10-20 paraphrases
c) Two-stage training approach
- Step 1) Encoder warm-up
- Stage 2) Supervised fine-tuning on reasoning task
c-1) Encoder warm-up
-
Train “encoder & projection layer” from scratch ( Freeze the LLM )
-
Task: Next token prediction
-
Employ “curriculum learning”
( As convergence is challenging when training from scratch )
- Step 1) Train on simple multiple-choice QA on synthetic TS
- Step 2) Captioning task on synthetic data
- Step 3) Captioning task on real data
c-2) Supervised fine-tuning on reasoning task
- Finetune “encoder, projection layer, LLM” end-to-end
- Use LoRA on a mixture of downstream tasks
- Augmented with GPT-generated CoT text
