
Tabular Data: Deep Learning is Not All You Need (ICML 2021)
https://arxiv.org/pdf/2106.03253.pdf
Contents
-
Abstract
- Introduction
- DL for Tabular
- TabNet
- NODE
- DNF-Net
- 1D-CNN
- Ensemble of models
- Comparing the models
- Experimental Setup
- Results
Abstract
Exploere whether DL is needed in tabular!
Result
- (1) XGBoost outperforms DL models
- (2) XGBoost requires much less tunining
- (3) Ensemble of DL + XGBoost performs better than XGBoost alone
1. Introduction
DL in tabular
- usually use different datasets & no standard benchmark
\(\rightarrow\) making it difficult to compare!
Questions.
- Q1) Are the models more accuracte for the unseen datasets ( not the datasets used in their papers )?
- Q2) How long does training & hyperparameter search takes?
Result: XGBoost is better & Ensemble of XGboost and DL is even better
2. DL for Tabular
Algorithms
- TabNet
- NODE ( Neural Oblivious Decision Ensembles )
- DNF-Net
- 1D-CNN
(1) TabNet
- sequencial decision steps encode features ( using sparse learned masks )
- select relevant features using masks ( with attention )
- sparsemax layers: force to use small set of features
(2) NODE ( Neural Oblivious Decision Ensembles )
-
contains equal-depth oblivious decision trees ( ODTs )
( = ensemble of differentiable trees )
-
only one feature is chosen at each level
\(\rightarrow\) balanced ODT
(3) DNF-Net
- simulate disjunctive normal formulas (DNF) in DNns
- key = DNNF block
- (1) FC layer
- (2) DNNF layer ( formed by soft version of binary conjunctions over literals )
(4) 1D-CNN
- best single model performance in Kaggle competetion with tabular data
- CNN : no local characterictics
- thus, use FC , then 1D-conv ( with short-cut connection )
(5) Ensemble of models
includes 5 classifiers: (1)~(4) + XGbosot
- weight = normalized validation loss of each model
3. Comparing the models
Desirable properties
- perform accuractly
- efficient inference
- short optimization time
(1) Experimental Setup
a) Datasets
4 DL models
11 datasets
- 9 datasets = 3 datasets x 3 papers
- 2 new unseen datasets ( from Kaggle )
b) Optimization process
Bayesian optimization ( with HyperOpt )
Use 3 random seed initializations in the same partition & average performance
(2) Results
a) Do DL generalize well to other datasets?
-
DL models perform worse on two unseen datasets
-
XGBoost generally outperform DL
-
No DL models consistently outperform others
( 1D-CNN may seem to perform better )
-
Esnemble of DL & XGBoost outperforms others in mosts cases
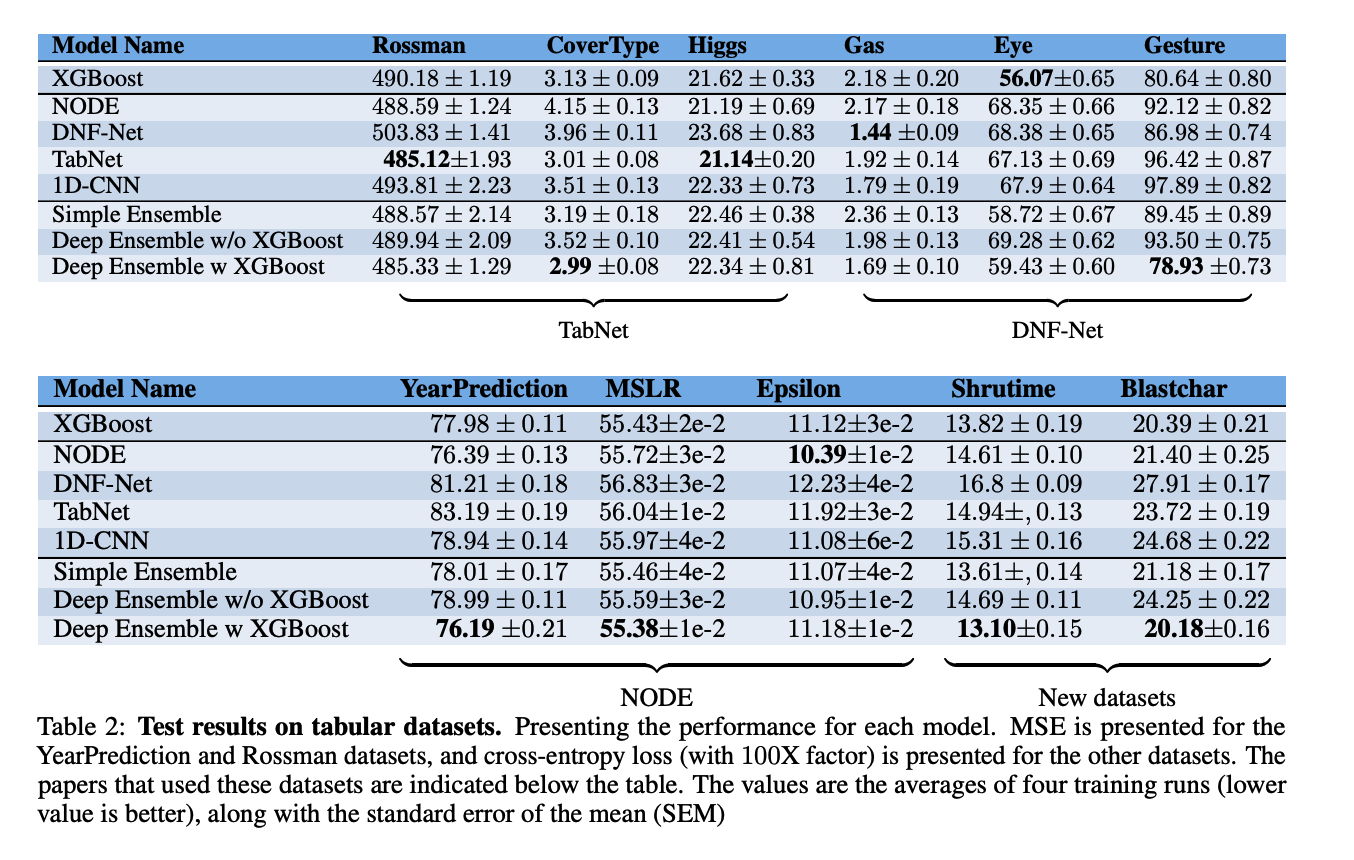
b) Do we need both XGBOost & DL?
3 types
- Simple ensemble: XGBoost + XVm + CatBoost
- Deep Ensembles w/o XGBoost: only (1) ~ (4)
- Deep Ensembles w/ XGBoost: (1) ~ (4) + XGBoost
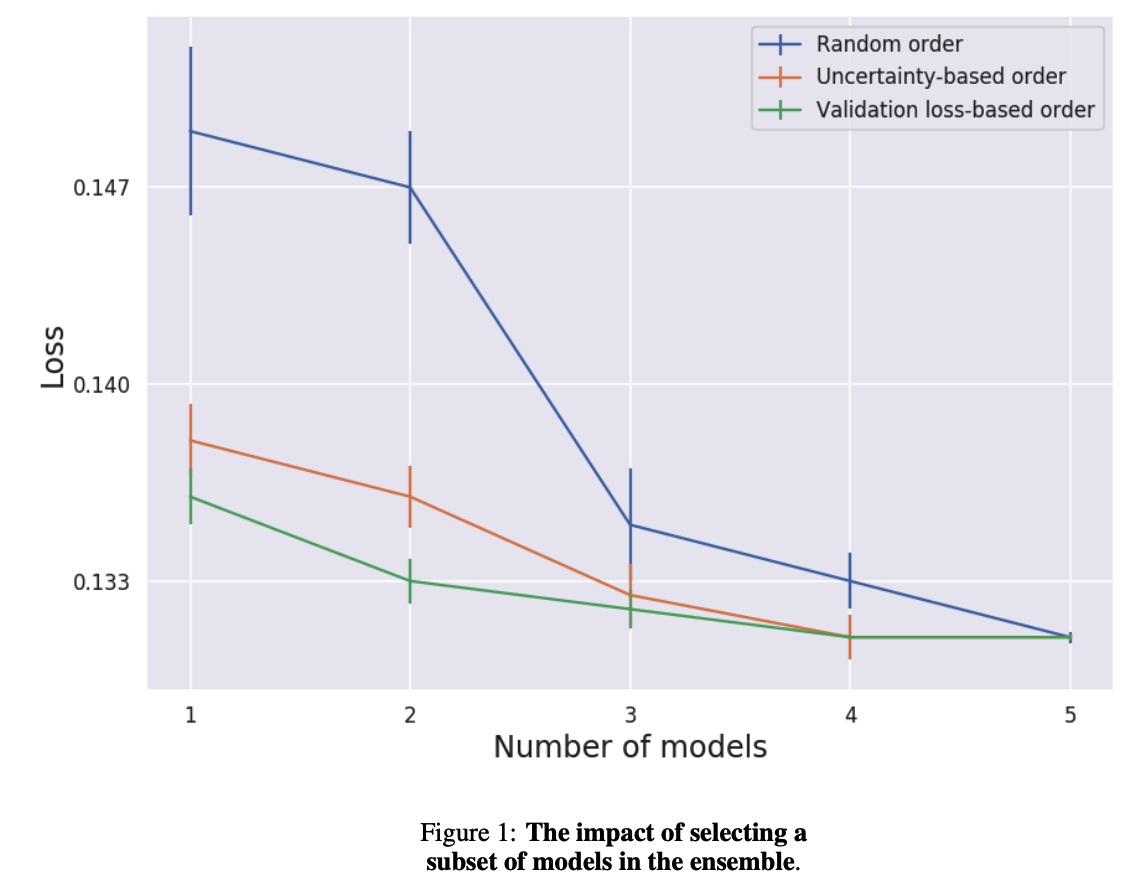
c) Subset of models
Ensemble improves accuracy!
But, additional computation…
\(\rightarrow\) consider using subsets of the models within the ensemble
Criterion
- (1) validation loss ( model with low val error first )
- (2) based on model’s uncertainty for each example
- (3) random order
d) How difficult is the optimization?
XGBoost outperformed the deep models, converging faster!
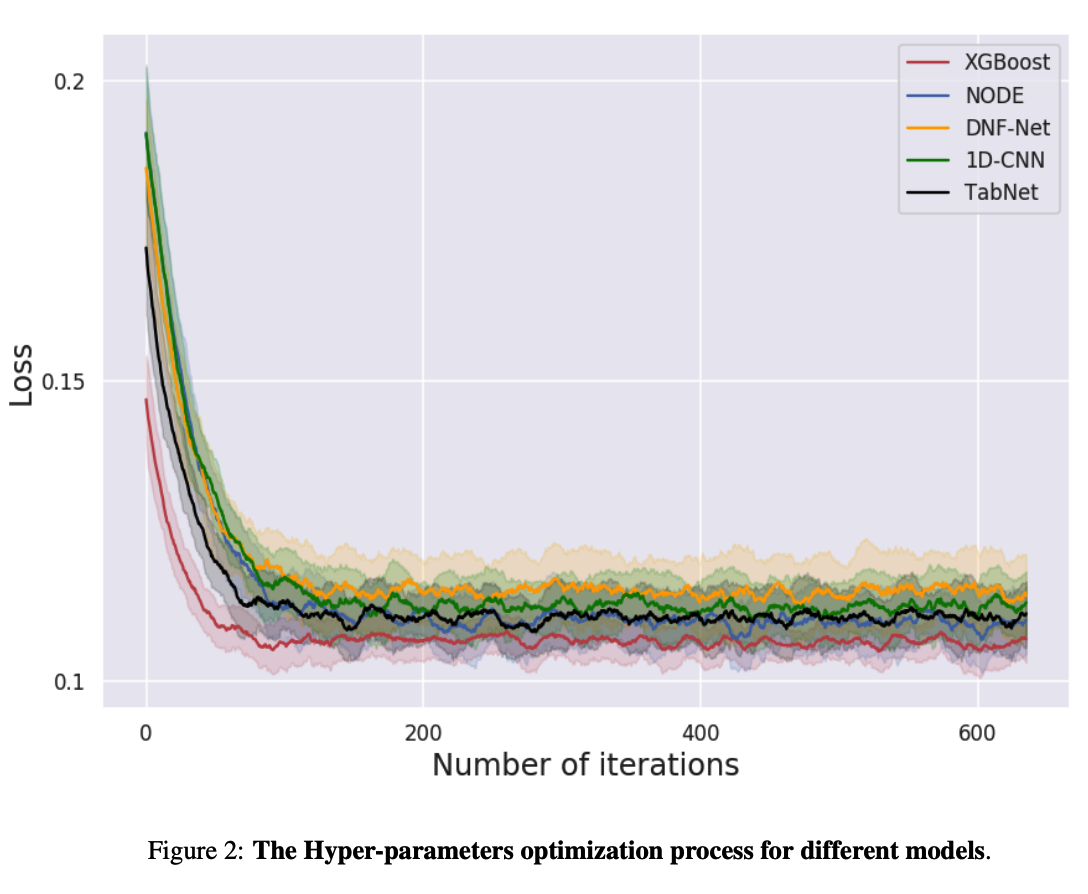
Results may be affected by several factors
1) Bayesian optimization hyperparams
2) Initial hyperparams of XGBoost may be more robust
( had previously been optimized over many datasets )
3) XGBoost’s inherent characteristics.