CLAR: Contrastive Learning of Auditory Representations (AISTATS, 2021)
https://arxiv.org/pdf/2010.09542.pdf
Contents
- Abstract
- Methods
- Audio Pre-processing
- Training/Evaluation Protocol
- Augmentations
- Datasets
- DA for CL
- Raw Signal vs. Spectrogram
- Sup vs. Self-Sup vs. Semi-Sup
Abstract
CLAR : Expand on SimCLR to learn better auditory representations
- (1) introduce various data augmentations
- suitable for auditory data
- (2) show that training with time-frequency audio features is better compared to raw signals
- (3) demonstrate that training with both supervised and contrastive losses simultaneously is better compared to SSL followed by supervised fine-tuning.
1. Methods
(1) Audio Pre-processing
2 family of models
-
a) input = RAW audio signals
-
b) input = Spectrogram
Step 1) down-sample all audio signals to 16kHz
Step 2) signal padding (by zeros) or clipping the right side of the signal
- to ensure that all audio signals are of the same length
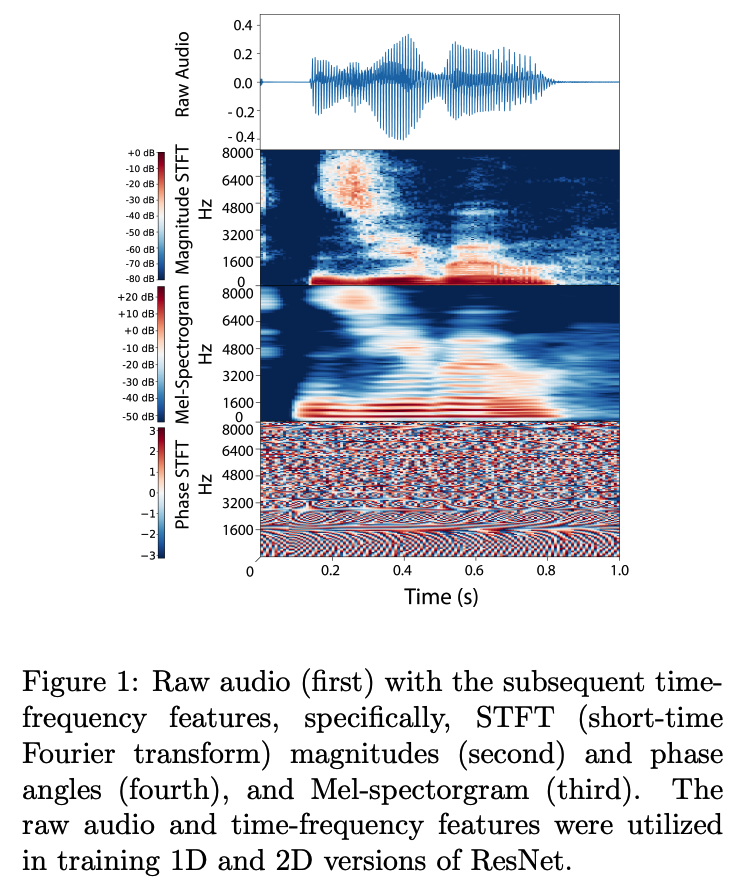
Step 3) only for model 2 [Figure 1]
- compute the STFT with 16 ms windows and 8 ms stride (Allen, 1977)
- project the STFT to 128 frequency bins equally spaced on the Mel scale (Figure 1).
- compute the log-power of magnitude STFT and Mel spectrogram
- \(f(S)=10 \log _{10} \mid S \mid^2\),
- where \(S\) = mel-spectogram (or magnitude STFT)
- \(f(S)=10 \log _{10} \mid S \mid^2\),
- stack the 3 time-frequency features in the channel dimension
- output size : \(3 \times F \times T\)
- \(F\) : # of the frequency bins
- \(T\) : # of frames in the spectrogram
- output size : \(3 \times F \times T\)
(2) Training/Evalaution Protocol
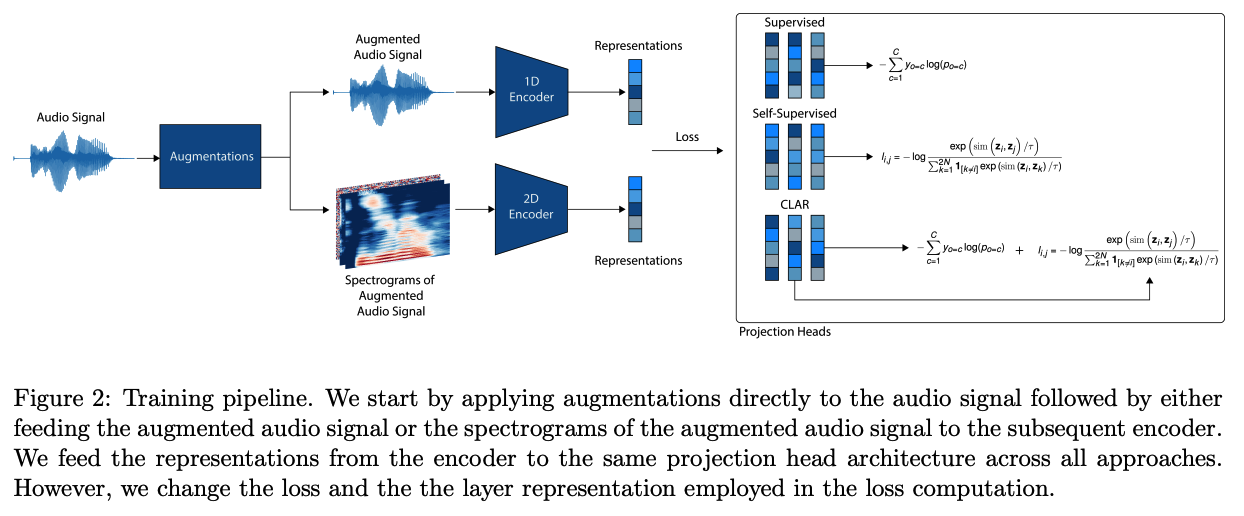
(1) Encoder : 1D & 2D CNN
- 2 outputs \(\rightarrow\) average pooling!
(2) Projection Head : 3 FC layers + ReLU
- ( solely supervised approach ) replace the vector used for contrastive loss with a vector with the same size as the number of classes to apply CE loss.
- ( proposed approach ) iincluded an additional layer that maps the 128 vector to the number of classes where the CE loss was applied
(3) Evaluation head
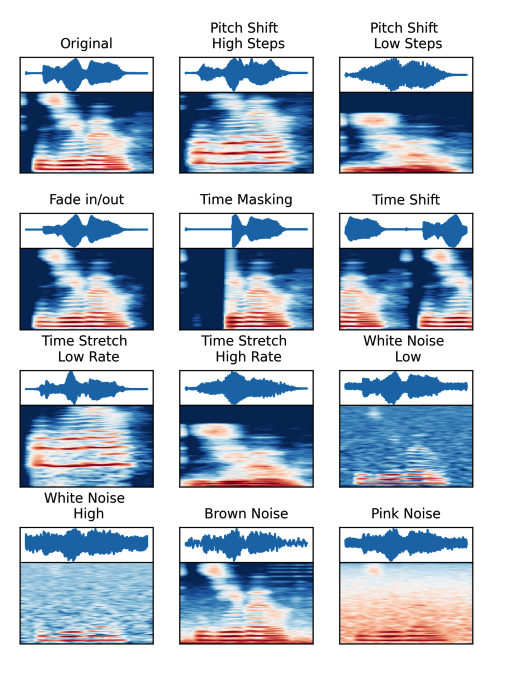
(3) Augmentations
Frequency Transformations
- Pitch Shift (PS)
- randomly raises or lowers the pitch of the audio signal
- Fade in/out (FD)
- gradually increases/decreases the intensity of the audio in the beginning/end of the audio signal
- Noise Injection
Temporal Transformations
- Time Masking (TM)
- randomly select a small segment of the full signal and set the signal values in that segment to normal noise or a constant value.
- Time Shift (TS)
- randomly shifts the audio samples forwards or backwards
- Time Stretching (TST)
- slows down or speeds up the audio sample
(4) Datasets
3 different domains : speech & music & environment sounds
- [Speech] Speech Commands
- [Music] NSynth
- [Environemnt] ESC-10 & ESC-50
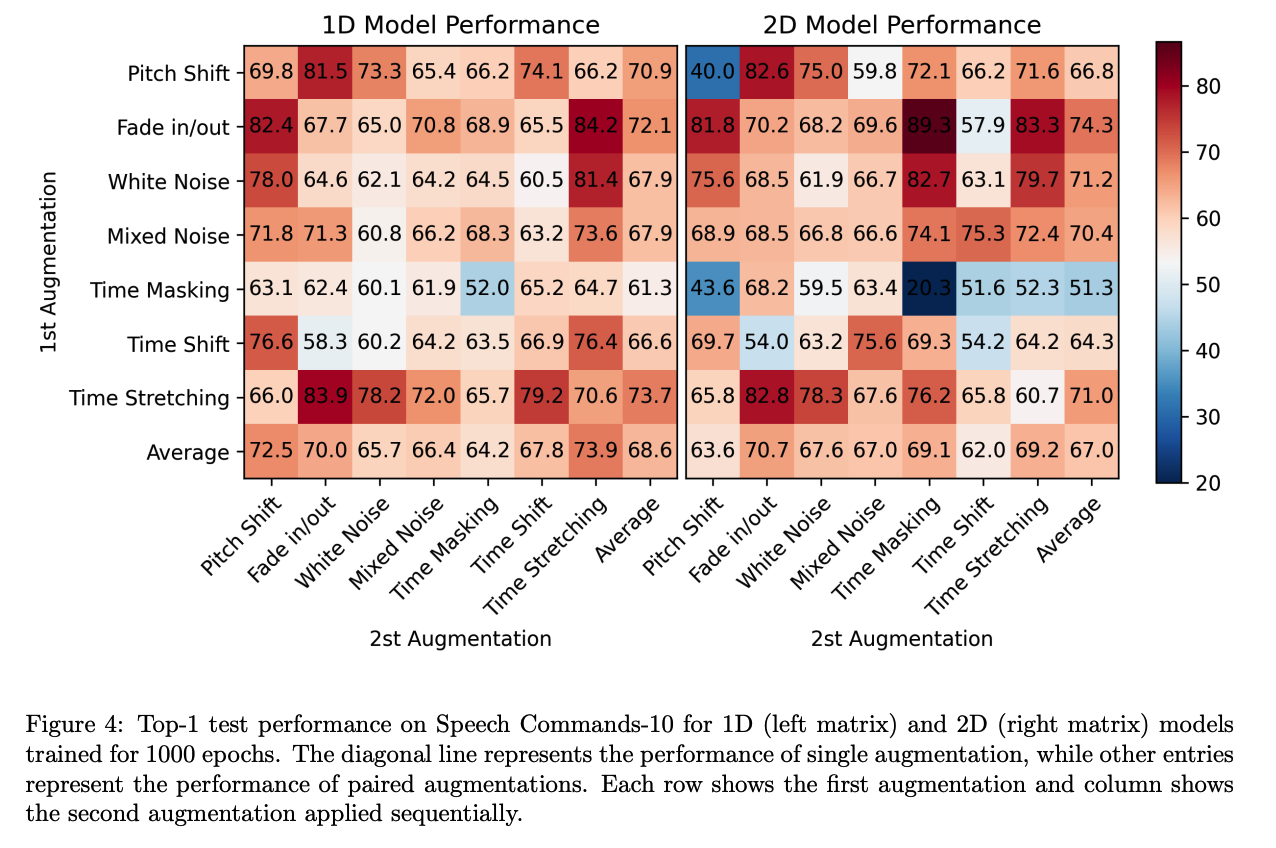
2. DA for CL
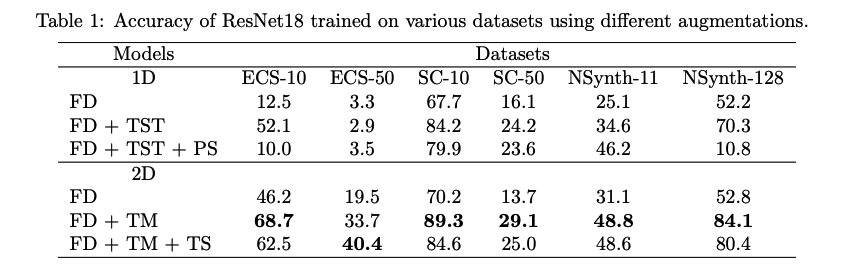
3. Raw Signal vs. Spectrogram
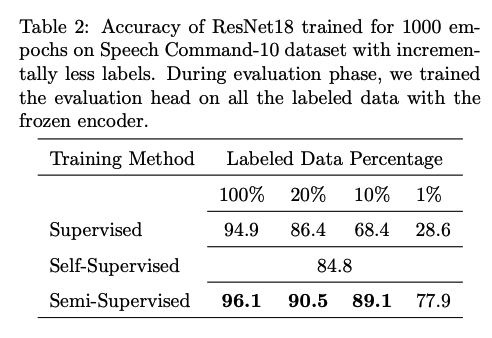
4. Sup vs. Self-Sup vs. Semi-Sup