
Wav2Vec: Unsupervised Pre-training for Speech Recognition ( arxiv 2019 )
https://arxiv.org/pdf/1904.05862.pdf
Contents
- Abstract
- Pre-training Approach
- Model
- Objective
- Experimental Setup
- Data
Abstract
Unsupervised pre-training for speech recognition
- by learning representations of “raw audio”
Wav2vec
- trained on large amounts of unlabeled audio data
- trained representations = used to improve acoustic model training
- simple multi-layer CNN optimized via a noise contrastive binary classification task.
1. Pre-training Approach
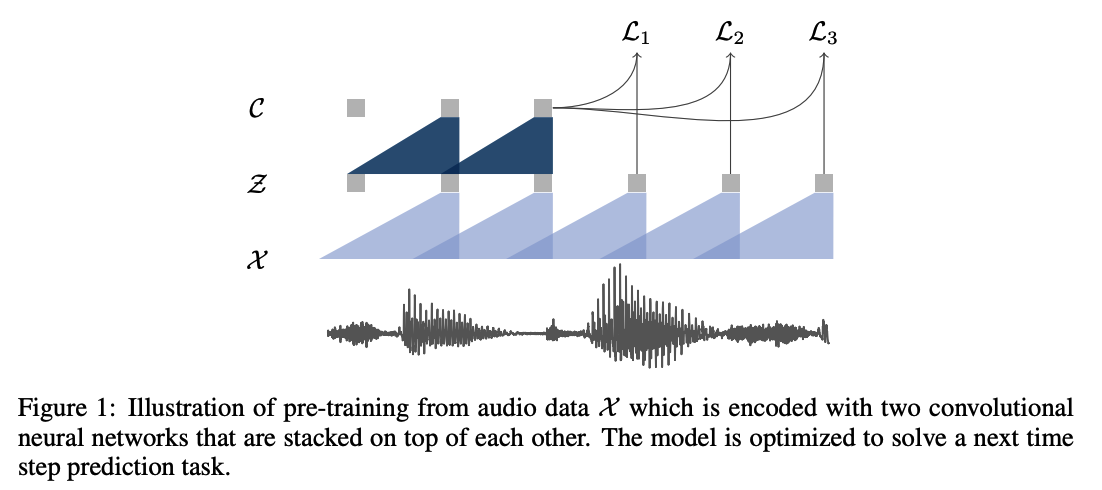
Summary
- Input = audio signal
- Goal = predict future samples from a given signal context
- Key point = accurately model the data distribution \(p(\mathbf{x})\),
- Procedure
- (1) Encode raw speech samples \(\mathbf{x}\) into \(\mathbf{z}\) at a lower temporal frequency
- (2) Implicitly model a density ratio \(\frac{p\left(\mathbf{z}_{i+k} \mid \mathbf{z}_i \ldots \mathbf{z}_{i-r}\right)}{p\left(\mathbf{z}_{i+k}\right)}\)
(1) Model
Two network
- (1) Encoder network = embeds \(x\) to \(z\)
- (2) Context network = combines multiple time-steps of the encoder to obtain contextualized representations
Notation & Settings
- (1) raw audio samples \(\mathbf{x}_i \in \mathcal{X}\)
- (2) Encoder network \(f: \mathcal{X} \mapsto \mathcal{Z}\)
- parameterized as a 5 layer CNN
- kernel sizes \((10,8,4,4,4)\) and strides \((5,4,2,2,2)\).
- output = low frequency feature representation \(\mathbf{z}_i \in \mathcal{Z}\)
- encodes about \(30 \mathrm{~ms}\) of \(16 \mathrm{kHz}\) of audio
- striding results in representations \(\mathbf{z}_i\) every \(10 \mathrm{~ms}\).
- parameterized as a 5 layer CNN
- (3) Context network \(g: \mathcal{Z} \mapsto \mathcal{C}\)
- mix multiple latent representations \(\mathbf{z}_i \ldots \mathbf{z}_{i-v}\) into a single contextualized tensor \(\mathbf{c}_i=g\left(\mathbf{z}_i \ldots \mathbf{z}_{i-v}\right)\) for a receptive field size \(v\).
- 9 layers CNN with kernel size three and stride one
- total receptive field : \(210 \mathrm{~ms}\).
Architecture details
- (1) Causal convolution
- layers in both the encoder and context networks consist of a causal convolution with 512 channels
-
(2) Group normalization layer
-
normalize both across the feature and temporal dimension for each sample
( = single normalization group )
-
important to choose a normalization scheme that is invariant to the scaling and the offset of the input
-
- (3) ReLU nonlinearity
Wav2Vec large
- two additional linear transformations in the encode
- larger context network comprised of 12 layers with increasing kernel sizes \((2,3, \ldots, 13)\).
- total receptive field = about \(810 \mathrm{~ms}\).
- introduce skip connections in the aggregator
(2) Objective
\(\mathcal{L}_k=-\sum_{i=1}^{T-k}\left(\log \sigma\left(\mathbf{z}_{i+k}^{\top} h_k\left(\mathbf{c}_i\right)\right)+\underset{\tilde{\mathbf{z}} \sim p_n}{\lambda}\left[\log \sigma\left(-\tilde{\mathbf{z}}^{\top} h_k\left(\mathbf{c}_i\right)\right)\right]\right)\).
- step-specific affine transformation \(h_k\left(\mathbf{c}_i\right)=W_k \mathbf{c}_i+\mathbf{b}_k\) for each step \(k\),
- final loss \(\mathcal{L}=\sum_{k=1}^K \mathcal{L}_k\),
- summing (1) over different step sizes.
Implementation
- approximate the expectation by sampling 10 negatives examples by uniformly choosing distractors from each audio sequence
- i.e., \(p_n(\mathbf{z})=\frac{1}{T}\), where \(T\) is the sequence length
- set \(\lambda\) to the number of negatives.
3. Experimental Setup
(1) Data
(a) Phoneme recognition on TIMIT (Garofolo et al., 1993b)
- contains just over 3 hours of audio data
- standard train, dev and test split
(b) Wall Street Journal (WSJ; Garofolo et al. (1993a); Woodland et al. (1994))
- comprises about 81 hours of transcribed audio data
- (train / val / test) = (si284 / nov93dev / nov92 )
(c) Librispeech (Panayotov et al., 2015)
- contains a total of 960 hours of clean and noisy speech for training.
For pre-training, we use either …
- a) full 81 hours of the WSJ corpus
- b) 80 hour subset of clean Librispeech
- c) full 960 hour Librispeech training set
- d) or a combination of all of them
Baseline acoustic model
- compute 80 log-mel filterbank coefficients for a \(25 \mathrm{~ms}\) sliding window with stride \(10 \mathrm{~ms}\).
Metrics
- word error rate (WER) and letter error rate (LER)