
Momentum Contrast for Unsupervised Visual Representation Learning
Contents
-
Abstract
-
Introduction
-
Related Works
- Loss Functions
- Pretext Tasks
-
Method
-
Contrastive Learning as Dictionary Look-up
-
Momentum Contrast
-
Pretext Task
-
-
Pseudocode
-
Experiment
0. Abstract
MoCo ( Momentum Contrast )
-
UNsupervised visual representation learning
-
dictionary look-up perspective
\(\rightarrow\) build a dynamic dictionary ( with a queue = FIFO )
-
moving-averaged encoder
1. Introduction
Previous works on unsupervised learning
- mostly on NLP
- CV : mostly on supervised pre-training…
Recent studies on UNSUPERVISED visual representation :
-
related to contrastive loss
( = can be thought of as building dynamic dictionaries )
- keys : sampled from data \(\rightarrow\) passed to encoder
Desirable to build dictionaries that are..
- (1) large
- (2) consistent
Propose MoCo
-
as a way to build large & consistent dictionaries
( dictionary = queue )
-
unsupervised learning with a contrastive loss
-
2 encoders
- (1) key encoder
- (2) query encoder
-
slowly progressing key encoder
-
momentum-based MA of query encoder
( to maintain consistency )
-
2. Related Works
2 aspects of un/semi-supervised learning
- (1) pretext tasks
- (2) loss functions
(1) Pretext tasks
-
task being solved is not of interest
( but is solved only for true purpose of learning a good representation )
(2) Loss functions
- can be investigated independently of pretext tasks
(1) Loss Functions
Contrastive Losses
-
measure the similarities of sample pairs
( instead of matching true & predicted )
-
core of several un/semi-supervised learning tasks
Adversarial Losses
- measures the difference between pdfs
- widely used in unsupervised data generation
(2) Pretext Tasks
examples
- recovering the input under some corrpution
- form pseudo-labels by..
- transformations of a single image
- patch orderings
- tracking
- sgementing objects in videos..
3. Method
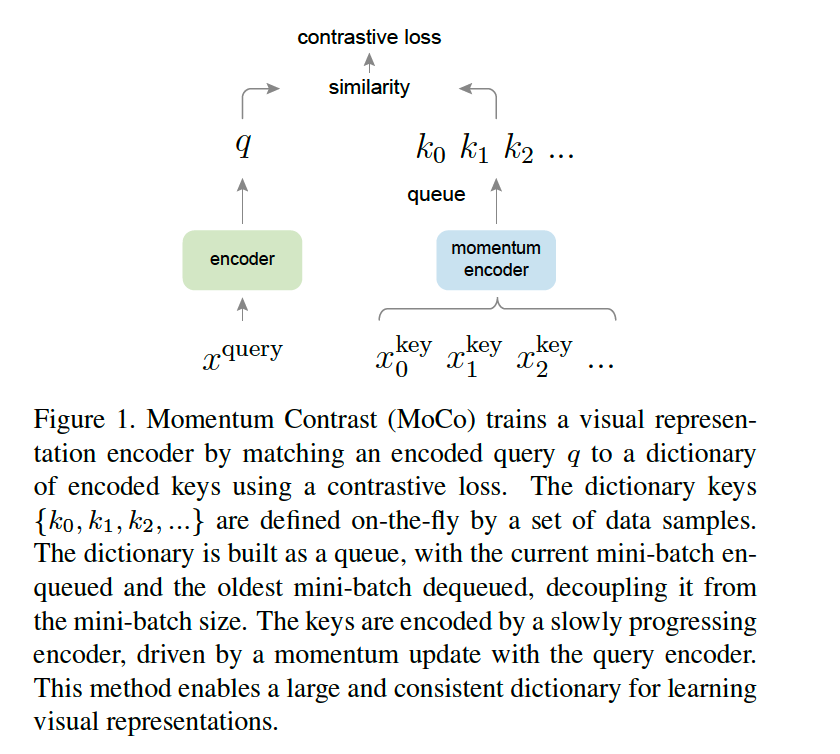
(1) Contrastive Learning as Dictionary Look-up
Contrastive Learing
- can be thought of as training an ENCODER of a DICTIONARY LOOK-UP task
Notation
-
encoded query : \(q\)
-
keys of a dictionary :
-
set of encoded samples : \(\{ k_0, k_1, k_2, \cdots \}\)
- positive key : \(k_{+}\)
- negative key : \(k_{-}\)
-
Contrastive Loss : low , when…
-
\(q\) is similar to its positive key \(k_{+}\)
-
dissimilar to other key ( = negative keys )
( similarity : measured by dot product )
\(\rightarrow\) InfoNCE
InfoNCE
\(\mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\sum_{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)}\).
- \(\tau\) : temperature
\(\rightarrow\) sum over one positive & K negatives
(= log loss of \((K+1)\) way softmax classifier , that tries to classify \(q\) as \(k_{+}\) )
Model Notation
- query : \(q=f_{\mathrm{q}}\left(x^{q}\right)\)
- \(f_q\) : encoder network
- \(x^{q}\) : query
- key : \(k=f_{\mathrm{k}}\left(x^{k}\right)\)
- \(f_k\) : encoder network
- \(x^{k}\) : key
\(\rightarrow\) networks \(f_{\mathrm{a}}\) and \(f_{\mathrm{k}}\) can be …
- (1) identical
- (2) partially shared
- (3) different
(2) Momentum Contrast
Contrastive Learning
= building a discrete dictionary on high-dim continuous inputs
DYNAMIC dictionary
= keys are RANDOMLY sampled
= key encoder evolves during training
Good features can be learend by….
-
(1) large dictionary that convers rich set of NEGATIVE samples
-
(2) key encoder is kept consistent as possible, despites its evolution
\(\rightarrow\) propose MoCo ( = Momentum Contrast )
a) Dictionary as a queue
maintain dictionary as queue ( = FIFO )
- Current minibatch : enqueued
- Oldest mini-batch : removed
b) Momentum update
-
copy the key encoder \(f_k\) from the query encoder \(f_q\)
( ignore the gradient! )
\(\rightarrow\) failure! due to rapidly changing encoder, that reduces the key representations’ consistency
\(\rightarrow\) thus, propose MOMENTUM UPDATE
\(\theta_{\mathrm{k}} \leftarrow m \theta_{\mathrm{k}}+(1-m) \theta_{\mathrm{q}}\).
- \(m \in[0,1)\) : momentum coefficient
- Only the parameters \(\theta_{\mathrm{q}}\) are updated!!
\(\rightarrow\) keys in the queue are encoded by different encoders ( with small diference )
\(\rightarrow\) large momentum (e.g., \(m=0.999\), our default) works much better than a smaller value (e.g., \(m=0.9)\)
KEY : slowly evolving key encoder
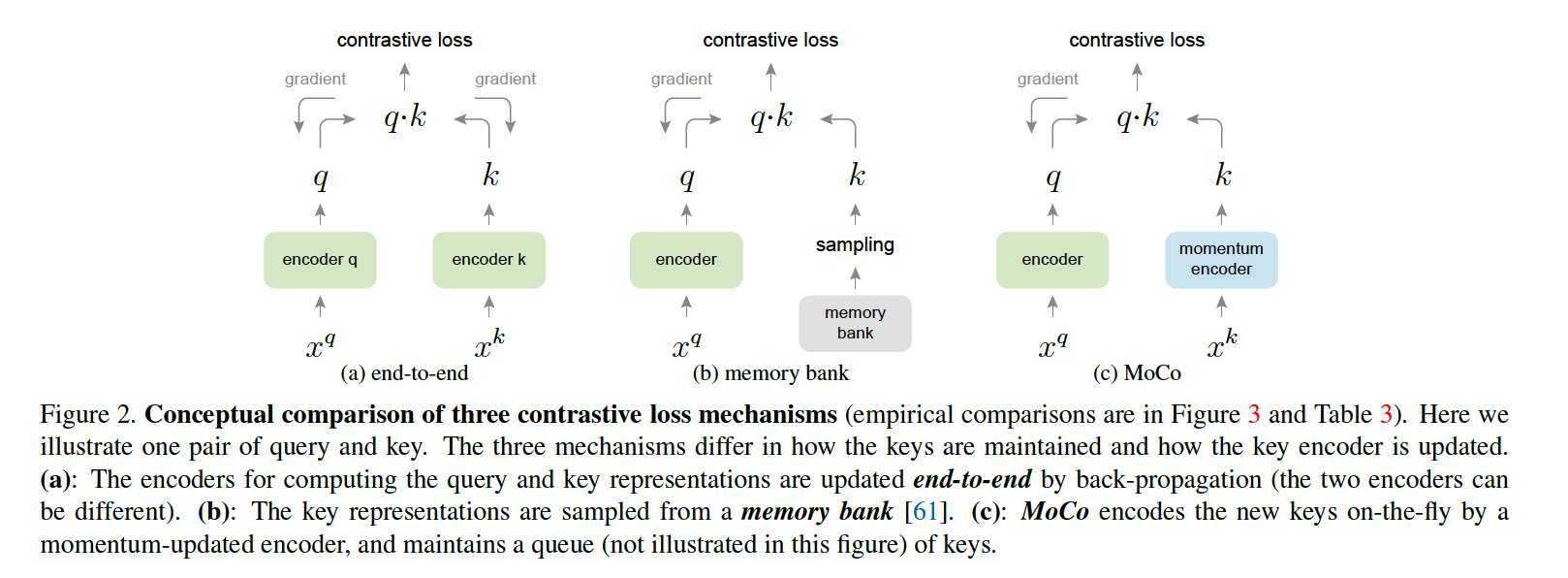
c) Relations to previous mechanisms
Moco = general mechansim for using contrastive loss
compare with 2 existing methods
- (1) end-to-end
- (2) memory bank
(3) Pretext Task
use instance discrimination task
4. Psudocode

5. Experiment
Dataset :
- ImageNet-1M (IN-1M)
-
~ 1.28 million images & 1,000 classes
( but does not use class labels )
-
characteristics
- iconic images
- Instagram-1B (IG-1B)
- ~ 1 billion images from Instagram & ~ 1,500 hastags
- characteristics
- uncurated
- long-tailed & unbalanced sitn
- iconic & scene-level image
Training
- optimizer : SGD ( w.d = 0.0001 , momentum = 0.9 )