
Selfie : Self-supervised Pretraining for Image Embedding
Contents
- Abstract
- Method
- Pretraining Details
- Attention Pooling
0. Abstract
introduce a pretraining technique called Selfie
( = SELF-supervised Image Embedding )
- generalizes the concept of masked language modeling of BERT to image
- learns to select the correct patch
1. Method
2 stage
- (1) pre-training
- (2) fine-tuning
(1) pre-training stage
-
\(P\) : patch processing network
-
produce 1 feature vector per patch ( for both ENC & DEC )
-
Encoder
-
feature vectors are pooled by attention pooling network \(A\)
\(\rightarrow\) produce a single vector \(u\)
-
-
Decoder
- no pooling
- feature vectors are sent directly to the computation loss
-
Encoder & Decoder : jointly trained
(2) fine-tuning stage
-
goal : improve ResNet-50
\(\rightarrow\) pretrain the first 3 blocks of this architecture ( = \(P\) )
(1) Pretraining Details
- use a part of the input image to predict the rest of the image
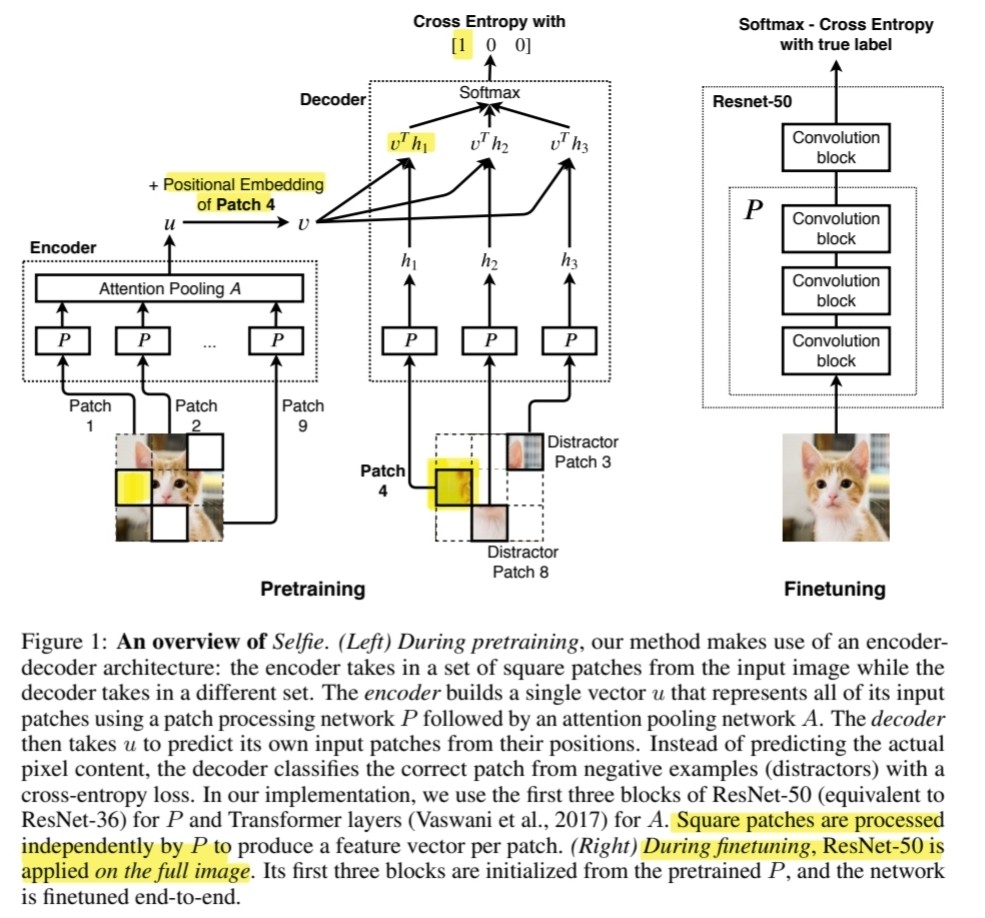
- ex) Patch 1,2,5,6,7,9 : sent to Encoder
- ex) Patch 3,4,8 : sent to Decoder
a) Patch Sampling method
image size 32x32 \(\rightarrow\) patch size = 8x8
image size 224x224 \(\rightarrow\) patch size = 32x32
b) Patch processing network
focus on improving ResNet-50
use it as the path processing network \(P\)
c) Efficient implementation of mask prediction
for efficiency… decoder is implemented to predict multiple correct patches for multiple locations at the same time
(2) Attention Pooling
attention pooling network : \(A\)
a) Transformer as pooling operation
notation
-
patching processing network : \(P\)
-
input vectors : \(\left\{h_1, h_2, \ldots, h_n\right\}\)
\(\rightarrow\) pool them to single vector \(u\)
attention pooling
-
\(u, h_1^{\text {output }}, h_2^{\text {output }}, \ldots, h_n^{\text {output }}=\operatorname{TransformerLayers}\left(u_o, h_1, h_2, \ldots, h_n\right)\).
( use only \(u\) as the pooling fresult! )
b) Positional embedding
( image size 32x32 ) : 16 patches ( of size 8x8 )
( image size 224x224 ) : 49 patches ( of size 32x32 )
\(\rightarrow\) instead of learning 49 positional embeddings … only need to learn 7+7 (=14) embeddings